基于多智能体增强学习算法的Walker星座轨道摄动补偿方法与流程
本发明涉及walker星座轨道摄动补偿技术,尤其涉及一种基于多智能体增强学习算法的walker星座轨道摄动补偿方法。
背景技术:
walker星座各轨道面平均分布,轨道面内的卫星也是均匀分布,卫星轨道是圆形轨道,walker星座通常用n/f/p来表示。其中n代表星座中的卫星总数,f代表星座中的轨道面,p代表调相因子,即每个轨道面的卫星个数为:m=n/f。衡量星座的性能的参数为几何精度因子(gdop)。星座的gdop值越大表示地面接收机至空间卫星的角度十分相似,即星座在摄动的影响下性能下降,gdop值越小表示卫星在不同区域均匀分布,即摄动对星座影响较小。
卫星星座要保持长期稳定性必须要解决主要摄动力的影响问题,对于轨道高度高于800km的卫星来说其主要摄动因素为:地球非球形摄动、日月三体引力摄动和太阳辐射压力摄动。其中,太阳辐射压力摄动对于卫星轨道的影响远远小于地球非球形摄动和日月三体引力摄动。摄动对卫星轨道的影响主要在于升交点赤经和沿迹角的漂移,卫星星座内所有卫星都会因为升交点赤经和沿迹角漂移导致卫星星座性能产生下降。
因此有必要寻求一种可靠的、低耗能的轨道摄动补偿方法解决卫星星座性能下降问题,实现卫星星座的长期在轨服役。
技术实现要素:
有鉴于此,本发明的主要目的在于提供一种基于多智能体增强学习算法的walker星座轨道摄动补偿方法,通过多智能体增强学习算法选择星座内不同卫星合适的轨道参数偏置,以补偿长期摄动力对卫星轨道的影响,提高卫星星座稳定性和长期可用性。
为达到上述目的,本发明的技术方案是这样实现的:
一种基于多智能体增强学习算法的walker星座轨道摄动补偿方法,包括如下步骤:
a、初始化增强学习算法的状态集s、动作集a和q值表;
b、根据当前状态和共享策略即共享q值表设计动作a,根据动作a得到当前回报r和q值表,并更新q值表;
c、判断当前q值是否符合同轨道面的共享策略,即共享q值表,若不符合,则执行步骤d;
d、判断当前几何精度因子gdop值是否满足设计要求,如果否,则执行步骤e;
e、循环执行步骤b~步骤d,直至gdop评价模型满足卫星星座长期稳定运行条件。
其中,所述步骤a之前进一步包括:
通过标称轨道和星座摄动模型计算出整个星座在标称轨道下的升交点赤经漂移δω和沿迹角漂移δλ:
步骤a还包括:将初始轨道偏置量,即轨道半长轴δa0和倾角偏置δi0作为多智能体增强学习算法的初始动作输入;其中:
式(3)中j代表第j个轨道面,每个轨道面均有m颗卫星;所述动作是指摄动偏置补偿。
步骤b所述根据动作a得到当前回报r和q值表,具体包括:
b1、根据星座摄动模型和gdop评价模型得到当前每颗卫星的环境回报
b2、各智能体独立选择动作集a中的动作a进行学习,并得到每颗卫星环境回报
步骤b2所述得到每颗卫星环境回报
步骤c所述判断当前q值是否符合同轨道面的共享策略,即共享q值表,具体为:判断同轨道面内的卫星是否满足共享q值表的条件。
步骤c还包括:
若符合,则同轨道面共享该q值表,然后执行步骤d。
所述同轨道面共享该q值表的过程为:
同轨道面内的卫星满足共享q值表的条件,则同轨道面内卫星共享q值表,该共享过程可表示为:
上式(4)代表第j个轨道面中的所有卫星在状态si下执行动作ai得到的回报值,然后从同一轨道面q值中选出最大的共享给轨道面内的其他卫星。
所述步骤c进一步包括:
在基于多智能体增强学习算法中,包括最优学习策略和标准q学习策略,均采用贪婪策略,即选择的动作能够产生最大的q值,可表示为:
所述q值的迭代过程与标准q学习方法保持一致,学习过程中q值的迭代公式可表示为:
所述步骤d还包括:若当前gdop值满足设计要求,则退出当前程序。
本发明的基于多智能体增强学习算法的walker星座轨道摄动补偿方法,具有如下有益效果:
1)本发明的walker星座轨道摄动补偿方法,通过采用多智能体增强学习算法为walker星座里的所有单个卫星选择合适的半长轴和轨道倾角偏差,消除长期摄动带来的升交点赤经漂移和沿迹角漂移,使得卫星星座gdop值处于较小范围,即实现摄动对卫星星座性能影响最小化,从而保证了卫星星座的稳定性和长期可用性。
2)本发明的walker星座轨道摄动补偿方法通过对标称轨道的半长轴和倾角的摄动补偿,可以降低卫星星座用于轨道保持的燃料消耗,延长卫星的使用寿命。
3)本发明的walker星座轨道摄动补偿方法具备较高的实时性,可以广泛运用于卫星星座轨道保持时的星上自主控制,通用性强。
4)本发明的walker星座轨道摄动补偿方法具备较高的安全性,可以降低不同轨道面间卫星碰撞的可能性。
5)本发明的walker星座轨道摄动补偿方法,具有结构清晰、层次分明、实时性高的特点,具有较好的理论价值和应用价值。
附图说明
图1为本发明实施例基于多智能体增强学习算法的walker星座轨道摄动补偿方法的流程示意图;
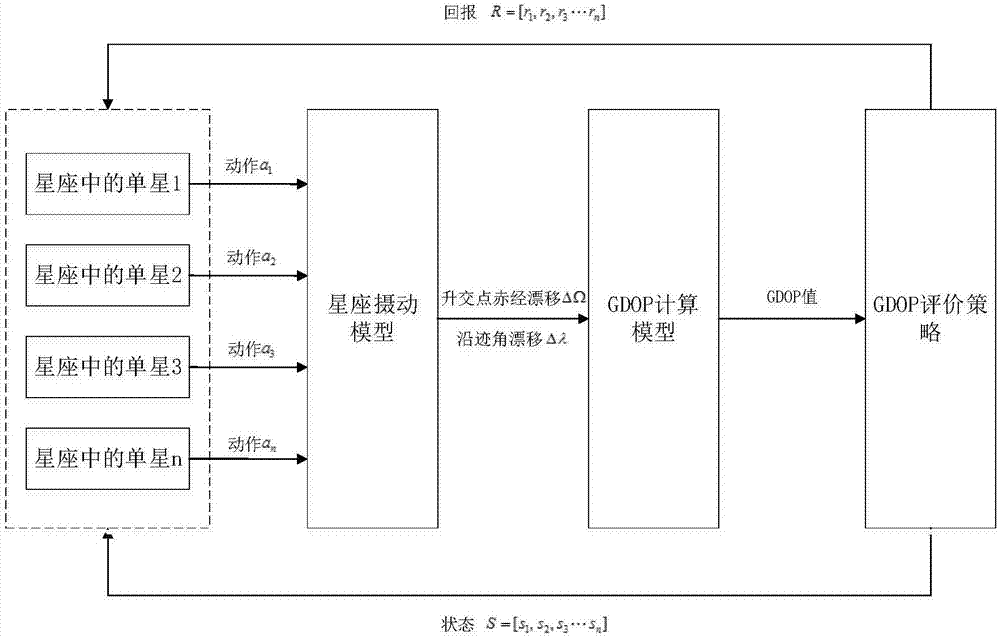
图2为本发明实施例基于多智能体增强学习算法的walker星座轨道摄动补偿过程中的数据流和控制回路示意图。
具体实施方式
下面结合附图及本发明的实施例对本发明的基于多智能体增强学习算法的walker星座轨道摄动补偿方法作进一步详细的说明。
对于卫星来说,卫星的标称轨道参数a和i是确定的。其中,a代表轨道半长轴,i代表轨道倾角,实际上通过推算圆轨道卫星轨道半长轴a和轨道倾角i的初始偏差与升交点赤经变化率(即漂移)δω和沿迹角变化率(即漂移)δλ成线性关系,用矩阵表示如下:
其中:参数a为卫星轨道半长轴和倾角偏差在地球非球形摄动和日月三体引力摄动影响下的变化矩阵,δt为时间变量。
通过定性分析可知,地球非球形摄动和日月三体引力摄动的直接后果是造成卫星轨道升交点赤经和沿迹角的漂移,而升交点赤经漂移和沿迹角漂移可以通过调整卫星轨道的初始偏差来克服,因此我们要实现卫星星座性能的优化,可以通过增强学习算法调整卫星轨道初始偏差的算法来实现。
利用增强学习算法通过与环境交互,反复学习来达到预期目标,其基本原理是:智能体执行某个行为策略所得到的奖惩为正奖惩,那么智能体在后续的动作序列中采取该策略的趋势会得到加强。这里,所述智能体代表单星,所述多智能体代表多星。
本发明采用增强学习算法模拟高等动物的学习心理,反复尝试不断与环境交互,在交互过程中获得知识,不断改进行动策略,最终适应环境完成学习任务。由于卫星星座包含较多的卫星单体,每颗星的轨道设计都直接影响星座整体性能因此也需要对增强学习算法进行改进,以适应多智能体的协同优化。
图1为本发明实施例基于多智能体增强学习算法的walker星座轨道摄动补偿方法的流程示意图。通过预置轨道半长轴偏差和轨道倾角偏差实现星座长期稳定运行,所述偏差的计算过程可以通过多智能体增强学习算法来获得。
如图1所示,该walker星座轨道摄动补偿方法包括如下步骤:
步骤10:通过标称轨道和星座摄动模型计算出整个星座在标称轨道下的升交点赤经漂移δω和沿迹角漂移δλ。所述星座摄动模型,是指标准日月三体引力及地球非球形的摄动模型。
这里,所述标称轨道是指轨道半长轴a和轨道倾角为i的情况下,无偏置。
根据上式(1)可得到消除整个星座升交点赤经和沿迹角漂移的轨道半长轴δa1和倾角偏置δi1:
步骤11:初始化增强学习算法的状态集s、动作集a和q值表q(st,at),将初始轨道偏置量,即轨道半长轴δa0和倾角偏置δi0作为多智能体增强学习算法的初始动作输入。
其中:
上式(3)中j代表第j个轨道面,每个轨道面均有m颗卫星。
这里,所述动作是指摄动偏置补偿。
步骤12:根据当前状态和共享策略设计动作a,根据动作a得到当前回报r和q值表,并更新q值表。这里,所述动作a为摄动偏置补偿。
具体过程如下:
步骤121:根据星座摄动模型和几何精度因子(geometricdilutionprecision,gdop)评价模型得到当前每颗卫星的环境回报
其中,所述的gdop评价模型,是以gdop值大小作为评价指标,值越小效果越好。
步骤122:各智能体独立选择动作集a中的动作a进行学习,并得到每颗卫星环境回报rijk和q值表
这里,所述得到每颗卫星环境回报rijk是通过比较gdop值是增大还是减小得到。具体为:gdop增大环境回报rijk为-1,减小rijk为1,相等则为0。所述q值表更新公式如下:
上式中各个参数的物理意义同前式(3),这里不再赘述。
步骤13:判断当前q值是否符合同轨道面的共享策略,即共享q值表,如果符合,则同轨道面共享该q值表,然后执行步骤14;如果不符合,则直接执行步骤14。
具体过程为:判断同轨道面内的卫星是否满足共享q值表的条件,如果满足则同轨道面内卫星共享q值表,该共享过程可表示为:
上式(4)代表第j个轨道面中的所有卫星在状态si下执行动作ai得到的回报值,从同一轨道面q值中选出最大的共享给轨道面内的其他卫星。
通过轨道面内学习过程中的q值共享,使得轨道面内学习快的卫星带动学习慢的卫星,提高整个轨道面内卫星的学习效率,f个不同轨道面之间均采用此策略。
较佳地,在基于多智能体增强学习算法的walker星座轨道摄动补偿方法中,最优学习策略与标准q学习策略一致,都采用贪婪策略,即选择的动作能够产生最大的q值,所述π*(si)代表采用贪婪策略,得到最大的q值。即:
所述q值的迭代过程与标准q学习方法保持一致,学习过程中q值的迭代公式可表示为:
其中,αi(si,ai)为控制收敛的学习因子,γ为延迟回报和立即回报的控制因子,ri+1为回报函数,取值为0,1或者-1。
步骤14:判断当前gdop值是否满足设计要求,如果是,则退出程序;如果不满足,则执行步骤15。
这里,所述判断当前gdop值是否满足设计要求,具体为判断给定的gdop阈值是否小于阈值,如果该gdop阈值小于所述阈值,则满足要求。
步骤15:循环执行步骤12~步骤14,直至gdop评价模型满足卫星星座长期稳定运行条件,即低于实际需要的gdop值。
这里,所述gdop评价模型满足卫星星座长期稳定运行条件,具体可以是所述gdop值低于预设值。
上述步骤10~步骤15中,该实施例基于多智能体增强学习算法的walker星座轨道摄动补偿过程的数据流和控制回路,如图2所示,具体包括如下步骤:
步骤21:令星座中的单星,如星座中的单星1、2、3或4,选择一个初始动作,如动作a1、动作a2、动作a3或动作a4,即轨道半长轴和轨道倾角的偏置补偿,统一输入预设的星座摄动模型。
步骤22:通过所述星座摄动模型计算出升交点赤经漂移δω和沿迹角漂移δλ。
步骤23:将通过上述漂移量,即将升交点赤经漂移δω和沿迹角漂移δλ输入到gdop模型中,计算出当前星座的gdop值。
步骤24:通过gdop策略判断所述gdop值是否满足实际需要,并生成每个星座中单星的动作回报和当前状态;然后再由所述的单星根据动作回报和当前状态选择下一步动作。
这里,所述的下一步动作,是指将轨道半长轴和轨道倾角的偏置补偿,输入当前的星座摄动模型。
本发明主要围绕两个技术创新点进行设计,即实时性和可靠性。其中:
所述实时性主要体现在随着星座卫星个数和动作空间的增加,增强学习算法的状态空间并没有出现指数增加,即没有出现“维数灾难”。
设卫星星座的状态空间集个数为ns,动作空间个数为na,星座中卫星总数为n,如果采用现有的类似单智能体增强学习算法,那么总的搜索空间为:
所述可靠性主要体现在通过对星座标称轨道的偏置,不同轨道面之间卫星的半长轴不一样,在长期运行过程中不容易出现不同轨道面卫星之间碰撞的风险,通过对标称轨道的偏置补偿,可以保证卫星星座长期的服务性能。
现有的卫星星座解决不同轨道面间卫星的碰撞问题主要是通过调整不同轨道面内卫星的半长轴和偏心率,半长轴不同代表卫星运行高度也不一样,因此可以减少不同轨道面内的碰撞。在本发明中通过多智能体增强学习算法获得的半长轴和倾角偏置,不仅可以避免不同轨道面间碰撞,而且可以保证星座性能在摄动力的作用下长期稳定。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!