一种基于GPS轨迹数据的出行段识别方法与流程
本发明涉及计算机识别技术,尤其涉及一种基于gps轨迹数据的出行段识别方法。
背景技术:
传统居民出行调查一般采用面对面访谈、纸质问卷、邮件和电话等形式,这些方法需要受访者填写详细的出行特征,并且是在一天或者更长时间段内出行结束后进行回忆填写,受访者的负担较大,填写的数据存在较大误差。比如,1)出行者通常将出行时间近似为相近的5分钟、10分钟甚至15分钟等,也不提供实际的出行路径等信息;2)出行调查的漏报、误报比例较高,通常处于20%-30%之间,这些都限制了出行数据的精度。
近些年,随着智能手机的快速普及,gps定位技术的发展完善,使得基于手机gps轨迹数据的出行调查成为可能。
现有的基于gps轨迹数据的出行段识别方法主要存在以下不足:
1)由于gps信号可能存在误差,现有方法直接使用gps记录数据中的速度值进行相关计算就会出现较大偏差;
2)缺乏完善的原始数据清洗与预处理方法,如信号漂移点的识别与去除;
3)在识别得到出行端点后,缺乏进一步的判定与去除伪端点的方法;
4)没有按照传统的出行定义去合并出行段。
因此,识别得到的出行段与真实的出行之间存在较大偏差,方法实用性不强。
技术实现要素:
为解决上述技术问题,本发明的目的在于提供一种基于gps轨迹数据的出行段识别方法。
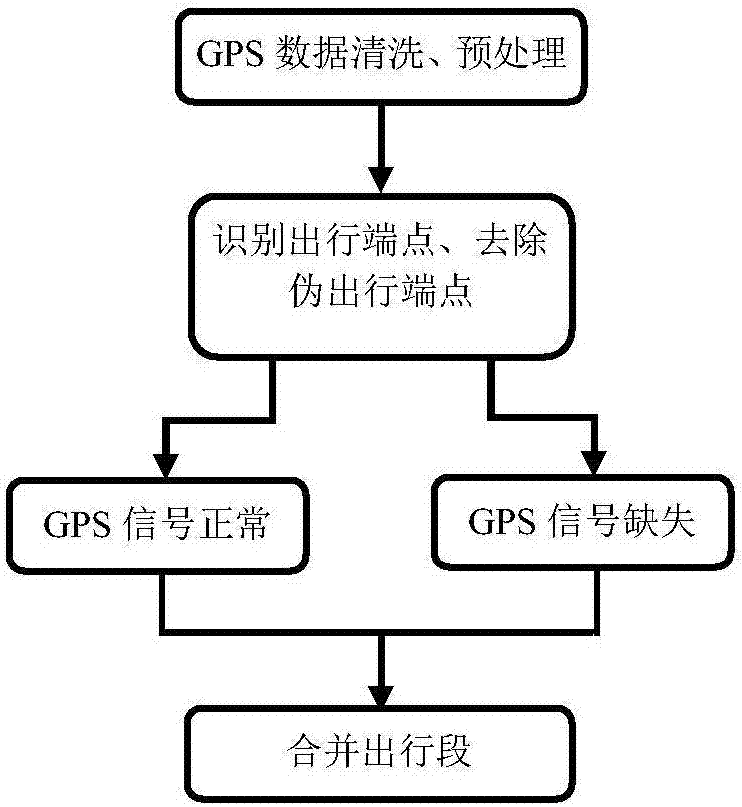
本发明是通过以下技术方案实现的:主要包括数据清洗与预处理、识别出行端点并去除伪出行端点、合并出行段。该方法在综合基于规则法和聚类法优点的基础上,提出了数据清洗与预处理流程,有效剔除了出行端点识别与出行段合并中的噪声。用轨迹点相邻区间的距离与时间差计算该点瞬时速度,运用速度对时间的积分来计算出行距离。适用于基于gps轨迹数据的出行段识别,丰富gps轨迹数据挖掘算法体系,为大规模基于智能手机的出行调查推广提供理论支撑。
一种基于gps轨迹数据的出行段识别方法,其特征在于:包括以下步骤:
第一步、数据清洗与预处理;
1)去除定位卫星数少于4颗的轨迹点;
2)去除海拔高度大于当地最高海拔的轨迹点;
3)信号漂移点识别与剔除:该点与之前5个点的中心距离超过200米,同时与之后5个点的中心距离超过200米;
4)去除瞬时速度超过地面交通工具最大速度的轨迹点;
第二步、识别出行端点并去除伪端点;
根据gps信号记录情况分两种情形识别出行端点,
1)gps信号正常记录:出行端点处的轨迹点有点聚集的特征,用k均值聚类法识别此类端点;还有一种端点发生在短暂的接送人情形下,通过计算轨迹点的方向变化以及路段重复长度识别,方向发生180度的改变,且重复路段长度超过50米,即识别为接送人的出行端点;
2)gps信号缺失:缺失段时间差超过2分钟,且缺失段平均速度(缺失段长度与时间差的比值)小于步行速度最小值0.5m/s,即识别为出行端点;
第三步、合并出行段;
第二步得到的出行端点即活动发生点,去除活动范围小于50米的出行端点,得到所有的出行端点,合并各出行端点之间的出行段。
进一步的,第二步所述的k均值聚类法识别可能的出行端点,定义一个簇并给定簇内最少的点数m=5个和聚类半径d=10米,判断该簇中位点和簇外下一点之间的距离,如果小于d/2,则将该点加入簇中,否则结束该簇,直到所有的点都被遍历到,最终建立的各簇即为可能的出行端点,每一个簇的时间差至少为2分钟,否则作为伪端点并去除。
进一步的,第三步所述的出行段,各出行段需满足:出行段长度大于400米,出行时间超过5分钟,否则该出行段并入上一出行段。
相比现有技术,本发明具有如下有益效果:
本发明有效剔除了出行端点识别与出行段合并中的噪声,算法简易、高效、识别结果精准、可靠。本发明可以丰富gps轨迹数据挖掘算法体系,为大规模基于智能手机的出行调查推广提供理论支撑。
附图说明
图1一种基于gps轨迹数据的出行段识别流程图
图2信号漂移点识别与删除
图3轨迹点速度计算示意图
图4出行段距离计算
具体实施方式
下面对本发明的实施例作详细说明,本实施例以本发明的技术方案为依据开展,给出了详细的实施方式和具体的操作过程。
一、数据清洗与预处理
采集的gps轨迹数据一般包括:用户编号、定位时间、经度、纬度、海拔、速度、方向和定位卫星数。
根据用户编号,gps数据按照时间顺序分配到每个人每天的出行。
根据以下规则进行数据清洗与预处理:
1、去除定位卫星数少于4颗的轨迹点;
2、去除海拔高度大于200米(上海地区)的轨迹点;
3、信号漂移点识别与剔除:该点与之前5个点的中心距离超过200米,同时与之后5个点的中心距离超过200米;详细图例见图2。
4、去除瞬时速度超过150km/h的轨迹点。
注:
1)轨迹点瞬时速度的计算:vi=(disi-1,i+disi,i+1)/(timei+1-timei-1)其中,disi-1,i表示第i-1个轨迹点与第i个轨迹点之间的距离,timei-1表示第i-1个轨迹点的时刻。详细图例见图3。
2)出行段距离计算:计算出行段距离时,与以往直接累加所有轨迹点间直线距离不同,本方法提出通过轨迹点速度对时间的积分得到出行距离:
如图4所示,速度折线与横轴围成的面积即是该段出行距离。
二、识别出行端点并去除伪端点
根据gps信号记录情况分两种情形识别出行端点。在gps信号记录正常时,出行端点处的轨迹点会有点聚集的特征,使用k均值聚类法识别此类端点;还有一种端点发生在短暂的接送人情形下,可以通过计算轨迹点的方向变化以及路段重复长度识别。
gps信号正常记录:
1)运用k均值聚类法识别可能的出行端点。定义一个簇并给定簇内最少的点数m=5个和聚类半径d=10米,判断该簇中位点和簇外下一点之间的距离,如果小于d/2,则将该点加入簇中,否则结束该簇,直到所有的点都被遍历到,最终建立的各簇即为可能的出行端点。每一个簇的时间差至少为2分钟,否则作为伪端点并去除;
2)方向发生180度的改变,且重复路段长度超过50米,即识别为接送人的出行端点。
gps信号缺失:缺失段时间差超过2分钟,且缺失段平均速度(缺失段长度与时间差的比值)小于步行速度最小值0.5m/s,即识别为出行端点。三、合并出行段
第二步得到的出行端点即活动发生点,去除活动范围小于50米的出行端点,得到所有的出行端点,合并各出行端点之间的出行段;
根据传统交通意义上出行的定义,各出行段须满足:出行段长度大于400米,出行时间超过5分钟,否则该出行段并入上一出行段。
实例验证:
实验共搜集到125名上海地区用户上传的有效gps轨迹数据,包括841人·天的2793492个gps轨迹点。其中,共有7.4%的无效gps轨迹点在数据清洗和预处理中被剔除,识别的整体正确率达到98.08%,错误率仅为3.22%;共有89个出行段被合并。出行段属性方面,识别的平均出行时长比真实值少88秒(4.3%);对应地,平均出行距离比真实出行距离少336米(3.0%)。由此可见,利用本发明所述方法基于gps轨迹数据可以实现出行段的精准识别。
表1
表2
以上实施例为本申请的优选实施例,本领域的普通技术人员还可以在此基础上进行各种变换或改进,在不脱离本申请总的构思的前提下,这些变换或改进都应当属于本申请要求保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!