一种生产业务噪声数据检测和分离方法与流程
本发明涉及信息处理技术领域,特别是涉及到一种生产业务噪声数据检测和分离方法。
背景技术:
数据质量的提高有利于对数据价值信息的挖掘,并构建新的知识模型支持生产决策和预判,能够提升设备的安全性,降低设备的故障,减少由于缺陷和故障导致的经济损失,同时提升设备的利用效率,减少重复投资和浪费,延长设备使用寿命,降低资产的报废净值率。
在生产过程中不可避免会引进一些生产业务噪声数据,这些噪声数据的存在,大大降低了数据的质量。因此,有必要对这种生产业务噪声数据进行检测并剔除。
技术实现要素:
为了克服现有技术中的不足,本发明提出了一种生产业务噪声数据检测和分离方法,目的在于识别并剔除生产业务噪声数据,提高数据质量。本发明采用的技术方案为:
一种生产业务噪声数据检测和分离方法,包括以下步骤:
s1:利用数据自身分布特征检测出单维度数据集中的噪声数据,形成新数据组;
s2:利用箱型图方法在所述新数据组中识别并剔除离群值和异常值,得到目标数据;
s3:利用基于欧几里德距离的聚类方法来识别并分离多维数据集中的噪声数据,得到目标数据。
优选的,所述步骤s1的具体方法为:
假设有一组数据如下:
序号1234…n
数据e_1e_2e_3e_4…e_n
(1)将数据集切等分成αn个区间(α可取1,10,100,1000),区间大小为
θ=(max{e_1,e_2,…,e_n}-min{e_1,e_2,…,e_n})/αn;
(2)截取数据分布集中的区间作为数据集中域,找到数据集中域形成新数据组e。
优选的,所述步骤s2的具体方法为:
利用箱型图方法,对所述新数据组剔除离群值,得到非离群数据组[q_1-3iqr,q_3+3iqr],再取非异常数据组[q_1-1.5iqr,q_3+1.5iqr],得到目标数据;
其中:q_1为第一分位数,q_3为第三分位数,iqr为四分位间距iqr=q_3-q_1。
优选的,所述步骤s3的具体方法为:
(1)利用基于欧几里德距离的聚类方法将数据集分为多个簇;
(2)识别不能归并到任何一簇中的数据,这些数据即为孤立点或奇异点;
(3)将所述孤立点或奇异点进行剔除处理。
优选的,所述步骤s3中的聚类方法为回归分析方法。
本发明的有益效果是:使用本发明的方法可以有效识别并剔除生产业务噪声数据,从而在提高数据质量的同时,也减少后期数据质量治理的工作量和难度,提升数据的利用效率。
附图说明
图1是本发明的流程图。
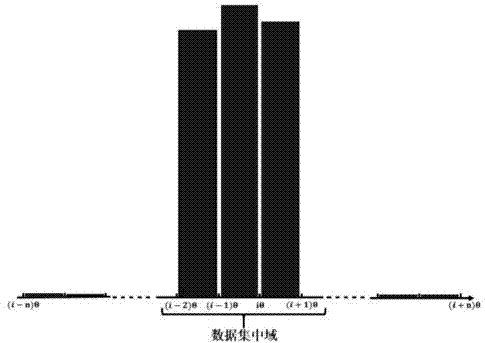
图2是本发明利用数据分布特征检测单维度数据集中噪声数据的示意图。
图3是本发明利用箱型图识别并剔除离群值和异常值的示意图,其中:1为异常值,2为上边缘,3为上四分位数,4为中位数,5为下四分位数,6为下边缘。
图4是本发明利用回归方法识别多维数据集中噪声数据的示意图,其中:1为类别1,2为类别2,3为孤立点。
具体实施方式
一种生产业务噪声数据检测和分离方法,如图1所示,包括以下步骤:
s1:利用数据自身分布特征检测出单维度数据集中的噪声数据,形成新数据组,如图2所示。噪声是指被测变量的一个随机错误和变化。一般情况下,对于离散程度并非非常大的数据源来说,数据自身分布将会集中在某一区域之内,所以利用数据自身分布特征来识别噪声数据,再根据箱型图的方法在数据集中域中识别离群值及异常值。其具体方法为:
假设有一组数据如下:
序号1234…n
数据e_1e_2e_3e_4…e_n
(1)将数据集切等分成αn个区间(α可取1,10,100,1000),区间大小为
θ=(max{e_1,e_2,…,e_n}-min{e_1,e_2,…,e_n})/αn;
(2)截取数据分布集中的区间作为数据集中域,找到数据集中域形成新数据组e。
s2:利用箱型图方法在所述新数据组中识别并剔除离群值和异常值,得到目标数据。如图3所示,其具体方法为:
利用箱型图方法,对所述新数据组剔除离群值1,得到非离群数据组[q_1-3iqr,q_3+3iqr],再取非异常数据组[q_1-1.5iqr,q_3+1.5iqr],得到目标数据;
其中:q_1为第一分位数,q_3为第三分位数,iqr为四分位间距iqr=q_3-q_1。
s3:利用基于欧几里德距离的聚类方法来识别并分离多维数据集中的噪声数据,得到目标数据。
一般情况下,利用数据分布特征或业务理解来识别单维数据集中噪声数据是快捷有效的,但对于聚合程度高,彼此相关的多维数据而言,通过数据分布特征或业务理解来识别异常的方法便显得无能为力。面对这种窘迫的情况,聚类方法提供了识别多维数据集中噪声数据的方法。
在很多情况下,把整个记录空间聚类,能发现在字段级检查未被发现的孤立点。聚类就是将数据集分组为多个类或簇,如图4中的1、2所示。在同一个簇中的数据对象(记录)之间具有较高的相似度,而不同簇中的对象的差别就比较大。散落在外,不能归并到任何一类中的数据称为孤立点3或奇异点。对于孤立或是奇异的噪声数据(异常值)进行剔除处理,如图4所示。
可以利用拟合函数对数据进行平滑。比如借助线性回归方法,包括多变量回归方法,就可以获得的多个变量之间的中个数属性值一个拟合关系,从而达到利用一个(或一组)变量值来帮助预测另一个变量取值的目的。利用回归分析方法所获得的拟合函数,能够帮助平滑数据及除去其中的噪声。
技术特征:
技术总结
本发明公开了一种生产业务噪声数据检测和分离方法,包括以下步骤:(1)利用数据自身分布特征检测出单维度数据集中的噪声数据,形成新数据组;(2)利用箱型图的方法在所述新数据组中识别并剔除离群值和异常值,得到目标数据;(3)利用基于欧几里德距离的聚类方法来识别并分离多维数据集中的噪声数据,得到目标数据。使用本发明的方法可以有效识别并剔除生产业务噪声数据,从而在提高数据质量的同时,也减少后期数据质量治理的工作量和难度,提升数据的利用效率。
技术研发人员:邬蓉蓉;张炜;蒲金雨;赵坚;张玉波;王乐;张磊
受保护的技术使用者:广西电网有限责任公司电力科学研究院
技术研发日:2017.07.04
技术公布日:2017.11.07
- 还没有人留言评论。精彩留言会获得点赞!