基于个体用户特征的信息传播方法与流程
本发明属于在线社交网络信息传播技术领域,特别涉及基于个体用户特征的信息传播方法。
背景技术:
随着互联网快速的发展和在线社交平台的普及,信息的传播方式发生了根本的变化。四通八达的网络将人们无时无刻地联系在一起,打破了传统的通过熟人社交网络和中心节点进行信息传播。截止2016年6月中国网民数量已经高达7.10亿,2017年新浪的月活跃用户达到4亿,同比增长了46%。网络社交平台有助于国家政策的普及、商品的推广、新闻的传播等。微博作为web2.0应用的代表,其对社会的影响备受关注。微博社交平台为人们提供了一个信息传播平台和言论自由的空间,然而在社交平台给大家带来诸多便利的同时,也有一些不法分子在网络上散布谣言以及制造舆论来破坏社会治安。因此如何有效的预测信息的传播成为亟待解决的难题。
国内外都对微博的信息传播模型展开了相关的研究,各有所侧重,总体上分为两种:一种是从宏观上入手,这类模型一般是基于仓室模型,侧重于信息传播时,不同人群总人数随时间变化的特征,例如:转发人数占总人数的比例,接收到信息的人数占总人数的比例等。另一种是从微观上入手,随着无标度网络、小世界网络等复杂网络的兴起,信息传播与在线社交网络的结合使信息传播模型的研究深入到了个人层面,所建立的信息传播模型通常会以复杂网络或者在线社交网络为基础,并考虑信息在传播时所涉及到的用户个体特征、用户在整个关系网络中的特征、用户之间的关系特征等。
经典的仓室模型是sir模型,由kermack等人在1927年提出,该模型将人群分为三类(即三个仓室):易感染者(s)、感染者(i)、移出者(r),不同类别的人群根据现实条件在三个仓室间迁移。张彦超等人建立的信息传播模型以sir模型为基础,首先将社交网络中的节点状态划分为三种,可以传播信息的节点,可以接收信息的节点,已经接受但不传播信息的节点,并且节点间的状态可以相互转化。同时考虑了网络中节点度的相关性,以此制定相关的信息传播规则,并根据规则建立了信息传播的动力学演化方程组,从宏观的角度预测信息的传播趋势。但是这类信息传播模型反映的是全局的信息传播趋势,无法反映出每个用户在信息传播时所起到的作用,无法确定信息传播网络中的关键用户和影响信息传播的关键因素,因此目前大部分的研究主要从微观角度入手。王振飞等人提出的基于逻辑回归模型的微博转发预测方法,从微观角度入手,提取了用户和微博两者的特征,并结合逻辑回归算法实现了对微博的预测,并与传统方法进行对比实验验证了文本方法的正确性与有效性。马晓峰等人提出的基于混合特征学习的微博转发预测方法,在考虑用户与微博特征的同时,并对预测微博进行了分类,实验对比了不同主题类别微博的转发预测效果。zhang等人提出的基于lda的内容转发预测模型较基于词频的内容转发预测模型起到较好的预测结果。刘清提出的融合兴趣和行为的用户转发行为预测方法,在预测用户的转发行为时融合了用户的兴趣和历史行为特征。马莹莹提出的微博用户转发行为及情感预测研究重点考虑了情感因素对用户转发行为的影响。
在本发明之前,这些文章都从微观角度入手并考虑了一些用户的个体特征,但是仍然存在一下几方面的不足之处:(1)对用户的个体特征考虑不够全面,仅仅考虑用户兴趣与微博内容特征或者网络特征,并未考虑用户间关系的特征,例如两者是否互相提及过对方,这种关系往往比相互关注更加紧密。(2)所有的用户使用同一个预测模型,这样必然会使不同用户的预测结果出现同质性。
技术实现要素:
本发明的目的在于克服上述缺陷,提供基于个体用户特征的信息传播方法。
本发明的技术方案为:
基于个体用户特征的信息传播方法,其主要技术特征在于,包括如下步骤:
(10)转发特征提取:提取影响用户转发行为的相关特征;
(20)历史数据提取:从社交网络中提取出用户的转发微博和未转发微博;
(30)为每个用户生成预测模型:通过每个用户的历史数据为每个用户生成一个预测模型;
(40)生成参考好友选择模型:首先确定参考好友的相关特征,然后建立参考好友选择模型,最后对参考好友模型进行求解;
(50)转发预测:当用户接受到一条新的微博时,首先判断该用户是否拥有自己的转发预测模型,如果有则使用该用户自己的转发模型进行预测,如果没有则使用参考好友选择模型选择一个参考好友,通过该参考好友的转发预测模型进行预测。
本发明与现有技术相比,其显著优点和效果为:可以更有效的预测每一个用户的转发行为,避免对不同用户转发预测时出现同质性,同时对于缺乏历史数据的新用户也有一定的预测能力。
下面结合附图和具体实施方式对本发明作进一步的详细描述。
附图说明
图1——本发明主框架示意图。
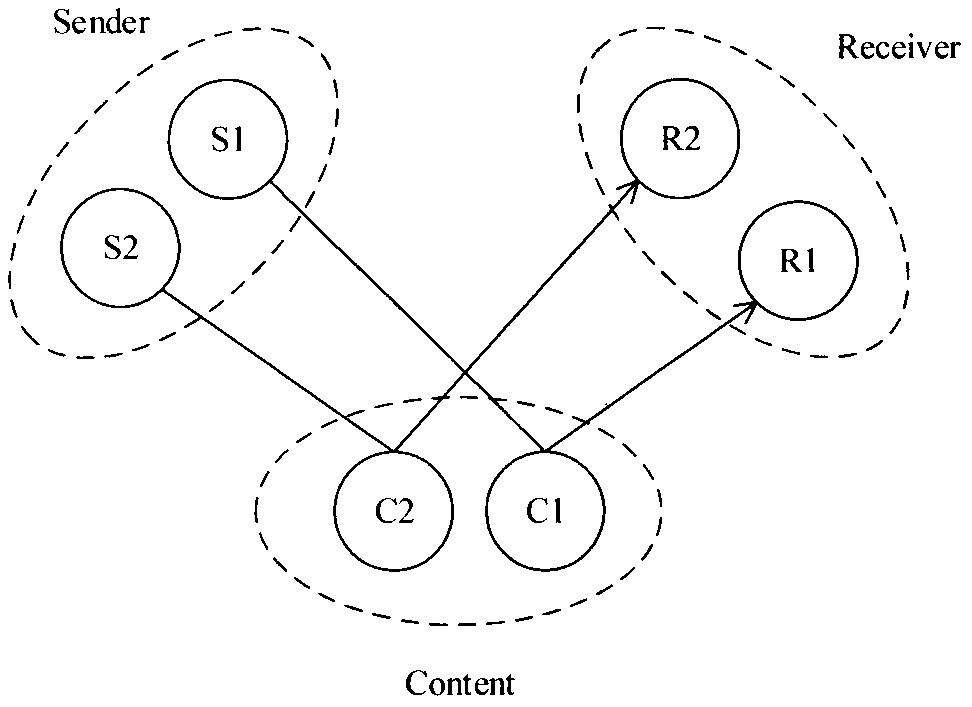
图2——本发明实体间的关系示意图。
图3——本发明逻辑回归算法、朴素贝叶斯算法、实验结果对比示意图。
图4——本发明特征箱线示意图,其中a为发送者权威箱线图,b为接收者对微博的兴趣箱线图,c为发送者意愿箱线图,d为发送者影响力箱线图。
具体实施方式
本发明的技术思路是基于如下问题而设计的:
研究信息的传播模型有利于预测信息传播的趋势和范围,可以反映出相关事件的发展趋势,有助于政策普及,使商业营销做出正确的决策并杜绝谣言、虚假信息、淫秽暴力信息的传播。但是信息在网络中传播时会受到不同因素的影响,如果仅仅考虑微博内容和用户兴趣对转发行为的影响并且所有用户共享一个预测模型,这样会导致预测模型不够精确。因此提出一个基于个体用户特征的信息传播方法来准确模拟信息在社交网络传播过程,有着重要的意义。
下面具体说明本发明。
如图1、2所示,本发明基于个体用户特征的信息传播方法,包括如下步骤:
(10)转发特征提取:提取影响用户转发行为的相关特征;
所述(10)转发特提取步骤具体为:
信息在社交网络中的传播可以划分为点到点的传播,每一个传播实例都会涉及到三个实体:信息发送者、信息接收者、传播的信息,实体间的关系如图2所示。影响用户转发行为的特征包括:信息发送者和信息接收者的属性特征、传播信息的特征、实体之间关系的特征。
转发特征表示如下:
1)节点的影响力:用户所有微博的转发量(ar),微博的数量为(an)。
2)节点的权威度:m(ui)是关注ui的用户集合,uj是ui的一个粉丝,l(uj)是uj关注的数量,n是网络中总的用户数量。
3)节点是否认证:1表示认证,0表示未认证。
4)节点的活跃度:posts为发送微博的总数量,days为天数。
5)转发者转发微博的意愿:用户转发微博量retweet_post,关注数量fellowings_num。
6)是否包含url:1未包含,0为未包含。
7)是否包含标签:1未包含,0为未包含。
8)是否为好友。相互关注的用户互称为好友。双边关系的好友相对于单边关系更加的紧密,因此有较大的概率会影响微博的转发。该特征的表示形式如公式(8)。
9)是否提及过对方:1表示提及,0表示未提及。
10)信息发送者和信息转发者的兴趣相似度:公式(11)为改进后的kl公式。p和q分别表示两个用户的兴趣向量。
11)信息接收者对信息感兴趣的程度:其中p代表用户的兴趣向量,q代表微博主题向量。
(20)历史数据提取:从社交网络中提取出用户的转发微博和未转发微博;所述(20)转发特提取步骤具体为:
(21)提取用户转发的微博:可以直接提取,用户ui的转发微博集合表示为
(22)提取用户未转发的微博:用户ui关注的用户集合为
(30)为每个用户生成预测模型:为每个用户生成预测模型:通过每个用户的历史数据为每个用户生成一个预测模型;
所述(30)转发特提取步骤具体为:
首先判断用户历史转发微博数据是否大于100条。如果小于100条,则结束;如果大于100条,进行如下步骤:
1)按照步骤10所提取的特征,对步骤20所提取的数据进行处理,将用户数据表示成向量的形式。
2)使用处理后的向量,生成svm预测模型。
(40)生成参考好友选择模型:首先确定参考好友的相关特征,然后建立参考好友选择模型,最后对参考好友模型进行求解;
所述(40)转发特提取步骤具体为:
(41)参考好友特征选择,选择如下特征:
1)性别是否相同:gender1,gender2分别代表两个用户的性别。
2)年龄的相似度:age1,age2分别表示两个用户的年龄,年龄越相近,相似度越高值越接近1。
3)兴趣相似度:ins1,ins2分别表示两个用户的兴趣向量。
4)关注相同微博的用户数目。其中seti(fellows),setj(fellows)分别表示用户i和用户j关注微博的集合,||seti(fellows)∪setj(fellows)||表示用户i和用户j关注微博的总数目,||seti(fellows)∩setj(fellows)||表示用户i和用户j关注相同微博的数量。
5)用户的权威相似度:authority(ai),authority(aj)分别表示两个用户的权威值。
(42)模型建立:步骤如下:
1)首先用所选取的特征建立一个特征向量,如公式(3-23)。
2)建立基础函数公式(27),其中u和v表示互相关注的两个微博用户,φ为这两个用户间的关系特征,α0是常量,α1是好友特征的权重
fα(u,v)=α0+α1tφ(19)
3)使用贝叶斯逻辑斯蒂函数表示,两个用户对同一微博都转发的概率为p(u,v),如公式(28)。
4)g(v,e)为微博构成的网络,v是所有用户的集合,e是所有用户间的关注关系。对于用户集合中任意一个用户u,其好友集合为fri(u),相互关注的用户互称为好友。用户u的好友集合中和用户u转发过相同微博的好友集合为sf(u)∈fri(u),两个好友转发的相同微博的集合为swei(u,v),||swei(u,v)||表示集合swei(u,v)中元素的数量。一个u用户和其中一个好友v转发过相同微博的概率为:。
5)sf(u)为用户u的好友集合中和用户u转发过相同微博的好友集合,用户u和所有好友转发过相同微博的概率为:
6)在整个数据集中好友间转发过相同微博的概率为:
7)最终形式为式:
8)满足全局似然概率f(g(v,e),α)最大的参数估计α即为该模型的解。计算出参数后将参数的值带入到公式(19),当选择一个用户参考好友时,将该用户与相邻好友的关系特征向量分别带入到公式(19),选择值最大的好友作为参考好友。
(43)好友模型求解
1)求上式(24)的解,等价于式(25)取得最小值时,α的值即为所求的解。
2)设参数α,目标函数l(α)=-lgf(g(v,e),α),该式的求解可以通过随机梯度下降算法来求解。首先初始化α(0)的值,然后根据要学习的数据集合,每次沿着目标函数的下降方向前进一小步,步伐的大小为δ,经过若干次迭代和对α值的更新,可以使目标函数收敛到全局或者局部的最优值。为了防止目标函数收敛的值是局部最优值,尝试不同的初始值,然后比较目标函数收敛后的值。
(50)转发预测:当用户接受到一条新的微博时,首先判断该用户是否拥有自己的转发预测模型,如果有则使用该用户自己的转发模型进行预测,如果没有则使用参考好友选择模型选择一个参考好友,通过该参考好友的转发预测模型进行预测。
所述(50)转发预测步骤包括:
(51)当一个用户接受到一个新的微博时,按照步骤(10)所提取的特征,对这条微博处理,将微博表示成特征向量;
(52)判断该用户是否拥有转发预测模型,如果有,使用自己的转发预测模型进行预测;如果没有,使用步骤(40)的参考好友选择模型从相邻的好友中选择出一位参考好友,通过该参考好友的转发预测模型进行预测。
为了验证本发明方法的有效性,对本发明方法进行下述实验分析。
硬件环境:英特尔第二代酷睿i5-2430m@2.40ghz双核
软件环境:windows7旗舰版64位
(61)图4为所选择的部分特征的箱线示意图,图4中a为发送者权威箱线图,b为接收者对微博的兴趣箱线图,c为发送者意愿箱线图,d为发送者影响力箱线图,以图4中a进行说明,可以看出相同特征在转发微博和未转发微博中的中位值和值域相差较大,因此这些特征具有良好的区分转发微博与未转发微博的能力。
(62)通过将基于个体用户特征的信息传播方法和逻辑回归算法(lr)、朴素贝叶斯算法(nb)进行对比,验证本方法的有效性。
在不同的数据量的情况下,使用f值来衡量本方法、逻辑回归算法(lr)、朴素贝叶斯算法(nb)的预测效果,结果都显示本方法都具有更好的效果,如图3所示。当用户数据量达到100-200的时候,逻辑回归算法和朴素贝叶斯算法迅速发挥作用,准确率迅速提高,但是其f值和本算法仍相差10%左右。
从图3中可以看出当用户的历史数据量不足100时,本方法通过相邻好友进行预测,准确率在接近40%,而朴素贝叶斯算法和逻辑回归算法由于历史数据的缺乏甚至没法进行预测。
- 还没有人留言评论。精彩留言会获得点赞!