一种垃圾网页识别方法与流程
本发明涉及网络信息智能处理技术领域,特别涉及一种垃圾网页识别方法。
背景技术:
随着互联网的高速发展,搜索引擎是人们利用互联网获取信息的重要的手段,人们在这种以搜索引擎为互联网主要入口的信息获取方式下,高搜索排名带来的高流量和高收益诱使不少网络内容提供者使用作弊方式对搜索引擎算法进行欺诈,以获取较有利的结果排名,而这种使用作弊方式基于欺诈获利的网页就是垃圾网页。垃圾网页的定义为:利用搜索引擎运行算法的缺陷,采取针对搜索引擎的作弊手段,使其获得高于其网络信息质量排名效果以谋求直接或间接利益的网页。随着网络中网页数量的迅速增长,过滤垃圾网页成为一件急需解决的工作。
垃圾网页的产生有一定的规律,比如垃圾网页会链接于垃圾网页,非垃圾网页多链接于非垃圾网页,所以可以根据垃圾网页与其他网页形成的结构和非垃圾网页与其他的网页形成的结构的不同来识别垃圾网页。现有的基于链接的垃圾页面分类,多为基于一层链接数目及其衍生值,垃圾页面过滤准确性有待提高。现有的垃圾网页识别算法往往只针对某些特定类型的垃圾网页,缺乏识别的鲁棒性。
技术实现要素:
本发明所要解决的技术问题是针对上述现有技术提供一种能够提高垃圾网页识别准确率的垃圾网页识别方法。
本发明解决上述技术问题所采用的技术方案为:一种垃圾网页识别方法,其特征在于:包括以下步骤:
步骤(1)、从已识别的网页中随机选取数目相同的已被标记的垃圾网页和已被标记的非垃圾网页构建训练集,训练集中包括已识别网页中的链接特征、链接组合特征和网页标签特征,其中网页标签特征包含垃圾网页特征和非垃圾网页特征;
步骤(2)、统计训练集中每个训练网页对应的有向图三角的数目,将每个训练网页对应的有向图三角的数目作为该训练网页的有向图三角特征;
步骤(3)、将步骤(2)中得到的训练网页的有向图三角特征与训练集中对应训练网页的链接特征、链接组合特征、对应网页标签特征进行组合,得到训练网页的包含链接特征和网页标签特征的第一组合特征集,包含链接特征、有向图三角特征和网页标签特征的第二组合特征集,包含链接组合特征和网页标签特征的第三组合特征集,包含链接组合特征、有向图三角特征和网页标签特征的第四组合特征集;使用随机森林模型对上述得到的四组组合特征集分别进行训练,分别得到训练网页的第一训练模型、第二训练模型、第三训练模型和第四训练模型;
步骤(4)、提取未识别网页的链接特征和链接组合特征;
步骤(5)、统计未识别网页对应的有向图三角的数目,将未识别网页对应的有向图三角的数目作为该未识别网页的有向图三角特征;
步骤(6)、将步骤(5)中得到的未识别网页的有向图三角特征与未识别网页的链接特征、链接组合特征进行组合,得到未识别网页的包含链接特征的第一测试组合特征集,包含链接特征和有向图三角特征的第二测试组合特征集,包含链接组合特征的第三测试组合特征集,包含链接组合特征和有向图三角特征的第四测试组合特征集;将得到的四组未识别网页的测试组合特征集分别对应输入到步骤(3)得到的四个训练模型中进行测试,分别得到4个网页标签特征测试结果,如果四个网页标签特征测试结果中有一半以上的结果为垃圾网页特征,则将该未识别网页的网页标签特征赋值为垃圾网页特征。
与现有技术相比,本发明的优点在于:不论是网页的链接特征还是组合链接特征,当与有向图三角特征组合成特征集进行随机森林训练时,经过随机森林训练后的模型的分类未识别网页时,准确率比无此有向图三角特征时有所提升,使用有向图三角特征提高了垃圾网页识别准确率。
附图说明
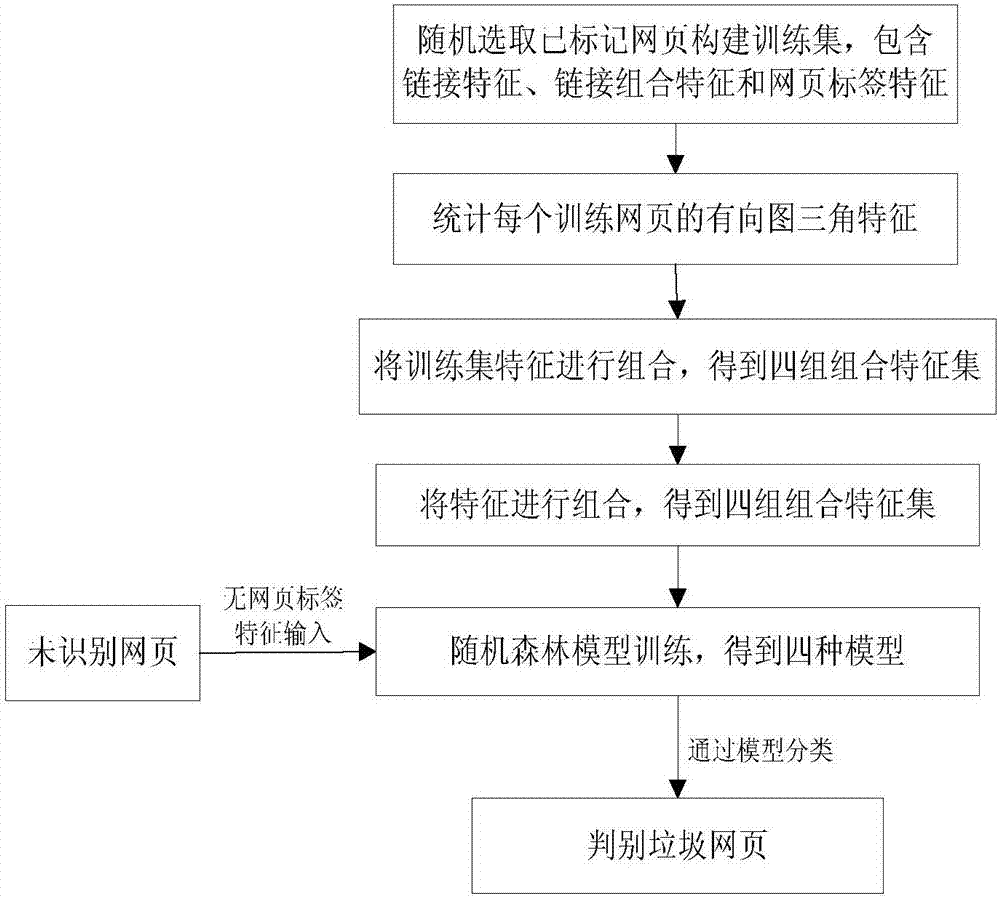
图1为本发明实施例中的总体实现框图;
图2为本发明实施例中的网页间的链接关系图;
图3为本发明实施例中的缺边有向图的结构图;
图4为本发明实施例中统计有向图三角时视为相同情况的两种有向图三角。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提供的垃圾网页识别方法。其总体框图如图1所示,包括以下步骤:
步骤(1)、从已识别的网页中随机选取数目相同的已被标记的垃圾网页和已被标记的非垃圾网页构建训练集,训练集中包括已识别网页中的链接特征、链接组合特征和网页标签特征,其中网页标签特征包含垃圾网页特征和非垃圾网页特征;在本实施例中,训练集是从专门应用于垃圾网页检测研究的webspam-uk2007数据集中随机选取的,该数据集中保存着每个网页的41个链接特征和138个链接组合特征;
步骤(2)、统计训练集中每个训练网页对应的有向图三角的数目,将每个训练网页对应的有向图三角的数目作为该训练网页的有向图三角特征;对于网络中的网页,将该网页本身的链接以及将该网页中指向的链接和被指向的链接的关系可以看作有向图形式,这种有向图所指的方向为网页间的链接指向,对于每个网页,找出所有它指向的链接以及指向它的链接,形成一个具有指向的有向图,然后对该有向图中的具有不同形式的有向图三角的数量进行统计;有向图三角统计的方法使用常规方法;例如具有图2所示的有向图,其中节点n是需要识别的网页,其他节点中带加号的节点是已经被标记的非垃圾网页,带减号的节点是已被标记的垃圾网页,有向边所指的方向为网页间的链接指向。
对于有向图三角,根据顶点的类别和箭头的方向有不同的形式,不同形式的图三角代表着不同的含义。对于二分类来说,将需要分类的顶点作为主顶点,其余顶点作为次顶点。如图3所示,对于主顶点,其中圈内无加减号的顶点表示主顶点。将主顶点编号为m,正类顶点编号为r,负类顶点编号为b,有箭头用y表示,无箭头用n表示,有向图三角的每个边至少有一个箭头,所以连续的箭头表示只有三种:ny,yn,yy。其中连续的顶点编号有4种:rr,rb,br,bb。通过顶点和边的排列与组合,其中从主顶点顺时针编号和逆时针编号相同的情况,视为重复的有向图三角,在统计有向图三角时视为相同的情况,如附图4所示。
从主顶点顺时针对图4中第一个图编号,顶点和边连在一起的编号如:mnyrnyrnym,从主顶点逆时针对附图4中第二个图编号,顶点和边连在一起的编号如:mnyrnyrnym,可知次顶点都是正类顶点的情况,一共有15种,都是负类顶点的情况,同样是15种。一个正类顶点、一个负类顶点一共有27种。因此共有57种不重复的非缺边有向图三角结构。
由于在实际网络中,存在缺边有向图三角,也需要一起计算,缺边有向图三角的双向箭头对结果没有大的影响,在统计缺边有向图三角忽略不计,如图3所示,一共有12种缺边图三角。
对于每个网页在统计有向图三角的数目时,需要统计57种不同形式非缺边有向图三角和12种不同形式缺边图三角的数目。
步骤(3)、将步骤(2)中得到的训练网页的有向图三角特征与训练集中对应训练网页的链接特征、链接组合特征、对应网页标签特征进行组合,得到训练网页的包含链接特征和网页标签特征的第一组合特征集,包含链接特征、有向图三角特征和网页标签特征的第二组合特征集,包含链接组合特征和网页标签特征的第三组合特征集,包含链接组合特征、有向图三角特征和网页标签特征的第四组合特征集;使用随机森林模型对上述得到的四组组合特征集分别进行训练,分别得到训练网页的第一训练模型、第二训练模型、第三训练模型和第四训练模型;
步骤(4)、提取未识别网页的链接特征和链接组合特征;
步骤(5)、统计未识别网页对应的有向图三角的数目,将未识别网页对应的有向图三角的数目作为该未识别网页的有向图三角特征;
步骤(6)、将步骤(5)中得到的未识别网页的有向图三角特征与未识别网页的链接特征、链接组合特征进行组合,得到未识别网页的包含链接特征的第一测试组合特征集,包含链接特征和有向图三角特征的第二测试组合特征集,包含链接组合特征的第三测试组合特征集,包含链接组合特征和有向图三角特征的第四测试组合特征集;将得到的四组未识别网页的测试组合特征集分别对应输入到步骤(3)得到的四个训练模型中进行测试,分别得到4个网页标签特征测试结果,如果四个网页标签特征测试结果中有一半以上的结果为垃圾网页特征,则将该未识别网页的网页标签特征赋值为垃圾网页特征。
- 还没有人留言评论。精彩留言会获得点赞!