一种大数据的管理方法与流程
本发明涉及大数据技术领域,特别是涉及一种大数据的管理方法。
背景技术:
随着对技术的发展,在经济生活或者工业生产中产生的数据量也越来越大。为了充分利用这些数据,以进一步加快技术的进步或者更好的服务于人们的生活,催生了大数据系统。
目前,互联网公司通常会将各条数据直接存储到存储服务器中,比如,将第一条数据存储在存储服务器a上,将第二条数据也存储在存储服务器a上,直至存储服务器a存储空间用完,然后再依次存储在存储服务器b、存储服务器c上,在需要使用这些数据时,根据用户需求,从各个存储服务器中检索对应的数据,然后再使用这些数据。
但是,应用现有技术存储各条数据,在数据量及其庞大时,用户搜索这些数据需要检索所有的服务器,导致检索数据的耗时较长。
技术实现要素:
本发明实施例的目的在于提供一种大数据的管理方法,以实现降低检索耗时的目的。具体技术方案如下:
一种大数据的管理方法,应用于大数据平台的控制中心,所述方法包括:
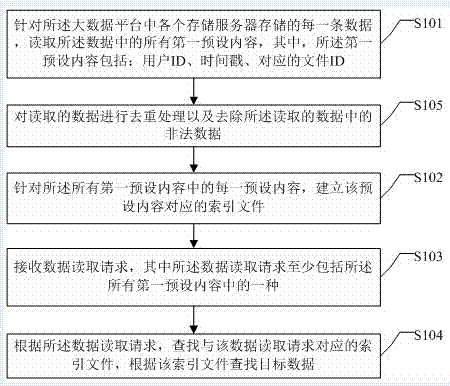
针对所述大数据平台中各个存储服务器存储的每一条数据,读取所述数据中的所有预设内容,其中,所述预设内容包括:用户id、时间戳、对应的文件id;
针对所述所有预设内容中的每一预设内容,建立该预设内容对应的索引文件,其中,所述索引文件包括:该预设内容、包含该预设内容的数据的存储位置以及所述该预设内容与所述包含该预设内容的数据的存储位置的对应关系;
接收数据读取请求,其中所述数据读取请求至少包括所述所有预设内容中的一种;
根据所述数据读取请求,查找与该数据读取请求对应的索引文件,根据该索引文件查找目标数据。
可选的,所述针对所述大数据平台中各个存储服务器存储的每一条数据,读取所述数据中的所有预设内容,包括:
针对所有大数据平台中各个存储服务器存储的每一条数据,读取所述数据中的所有预设内容;
所述索引文件包括:该预设内容、该预设内容存储的大数据平台的标识信息、包含该预设内容的数据的存储位置以及所述该预设内容与所述包含该预设内容的数据的存储位置的对应关系。
可选的,所述针对所述所有预设内容中的每一预设内容,建立该预设内容对应的索引文件,包括:
针对所述所有预设内容中的每一预设内容,建立该预设内容对应的索引文件,并将所有索引文件存储在专用的索引存储服务器中。
可选的,在针对所述所有预设内容中的每一预设内容,建立该预设内容对应的索引文件之前,所述方法还包括:
对读取的数据进行去重处理以及去除所述读取的数据中的非法数据。
可选的,所述方法还包括:
将所有存储服务器中存储的、被访问频率低于第一预设阈值的索引文件删除,并删除该索引文件对应的数据。
可选的,所述方法还包括:
将所有存储服务器中存储的、被访问频率低于第二预设阈值的索引文件对应的数据进行压缩处理。
本发明实施例提供了一种大数据的管理方法,应用于大数据平台的控制中心,所述方法包括:针对所述大数据平台中各个存储服务器存储的每一条数据,读取所述数据中的所有预设内容,其中,所述预设内容包括:用户id、时间戳、对应的文件id;针对所述所有预设内容中的每一预设内容,建立该预设内容对应的索引文件,其中,所述索引文件包括:该预设内容、包含该预设内容的数据的存储位置以及所述该预设内容与所述包含该预设内容的数据的存储位置的对应关系;接收数据读取请求,其中所述数据读取请求至少包括所述所有预设内容中的一种;根据所述数据读取请求,查找与该数据读取请求对应的索引文件,根据该索引文件查找目标数据。
本发明实施例提供的一种大数据的管理方法,用户的数据读取请求被接收时,服务器可以根据该数据读取请求先找到与该数据请求对应的索引文件,然后,再根据该索引文件找到目标数据,相对于现有技术需要检索所有的存储服务器,本发明实施例可以减少检索数据的时间。当然,实施本发明的任一产品或方法必不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的第一种大数据的管理方法。
图2为本发明实施例提供的第二种大数据的管理方法。
图3为本发明实施例提供的第三种大数据的管理方法。
图4为本发明实施例提供的第四种大数据的管理方法。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为解决现有技术问题,本发明实施例提供了一种大数据的管理方法。
需要说明的是,本发明实施例优选应用于大数据平台的控制中心。
图1为本发明实施例提供的第一种大数据的管理方法,如图1所示,该方法包括:
s101:针对所述大数据平台中各个存储服务器存储的每一条数据,读取所述数据中的所有预设内容,其中,所述预设内容包括:用户id、时间戳、对应的文件id;
具体的,可以针对所有大数据平台中各个存储服务器存储的每一条数据,读取所述数据中的所有预设内容。
在实际应用中,如果大数据平台a具有存储服务器a-1、存储服务器a-2、存储服务器a-3;如果大数据平台b具有存储服务器b-1、存储服务器b-2、存储服务器b-3;如果大数据平台c具有存储服务器c-1、存储服务器c-2、存储服务器c-3。读取各个存储服务器中存储的每一条数据,以存储服务器a-1为例,如果存储服务器a-1中存储有数据如下:
userid=12/time=22s/documented=10087;
userid=12/time=12s/documented=13378;
userid=123/time=34s/documented=13378。
上述的各条数据的中预设内容为:userid=12、time=22s、documented=10087;userid=12、time=12s、documented=13378;userid=123、time=34s、documented=13378。
s102:针对所述所有预设内容中的每一预设内容,建立该预设内容对应的索引文件,其中,所述索引文件包括:该预设内容、包含该预设内容的数据的存储位置以及所述该预设内容与所述包含该预设内容的数据的存储位置的对应关系;
具体的,可以针对所述所有预设内容中的每一预设内容,建立该预设内容对应的索引文件,并将所有索引文件存储在专用的索引存储服务器中。所述索引文件包括:该预设内容、该预设内容存储的大数据平台的标识信息、包含该预设内容的数据的存储位置以及所述该预设内容与所述包含该预设内容的数据的存储位置的对应关系。
在实际应用中,以用户id为例,建立针对用户id为12的索引文件m,该索引文件包括:userid=12、server=a-1、disknumber=23.454,其中,在该索引文件中,上述数据是一一对应的。
针对用户id=12的索引文件m,涵盖了所有包含用户id=12信息的数据。
同样的可以建立documented=13378的索引文件。
s103:接收数据读取请求,其中所述数据读取请求至少包括所述所有预设内容中的一种;
在实际应用中,读取用户客户端发送的数据读取请求,该数据读取请求中包含用户id=12的信息。
s104:根据所述数据读取请求,查找与该数据读取请求对应的索引文件,根据该索引文件查找目标数据。
在实际应用中,用户id=12的信息查找到针对用户id=12的索引文件m,根据该索引文件查找对应的目标数据。
得到的目标数据如下:
userid=12/time=22s/documented=10087;
userid=12/time=12s/documented=13378。
需要强调是的,检索也可以被称为查找、查询、寻找或者访问。
应用本发明图1所示实施例提供的一种大数据的管理方法,用户的数据读取请求被接收时,服务器可以根据该数据读取请求先找到与该数据请求对应的索引文件,然后,再根据该索引文件找到目标数据,相对于现有技术需要检索所有的存储服务器,本发明实施例可以减少检索数据的时间。
图2为本发明实施例提供的第二种大数据的管理方法,如图2所示,本发明图2所示实施例在本发明图1所示实施例的基础上,在s102之前增加了s105:对读取的数据进行去重处理以及去除所述读取的数据中的非法数据。
在实际应用中,假设两条数据一样,相同的数据存储两份,将其中的一个删除。
应用本发明图2所示实施例,去除存储服务器中重复的数据可以提高检索效率,而且还能减少索引文件的数据量的大小,进而对存储内存的占用。
例如,id=12为非法id,将包含有id=12的数据全部删除。
去除存储服务器中的非法数据,可以避免非法数据对检索结果的干扰。
图3为本发明实施例提供的第三种大数据的管理方法,如图3所示,本发明图3所示实施例在本发明图1所示实施例的基础上,增加了s106:将所有存储服务器中存储的、被访问频率低于第一预设阈值的索引文件删除,并删除该索引文件对应的数据。
在实际应用中,假设索引文件n在一年内被访问的次数为1次,被访问的频率为1次/年,若第一预设阈值为1次/月,则索引文件n被访问的频率低于第一预设阈值,删除索引文件n对应的各条数据,通常情况下,还会删除索引文件n。
被访问的频率过低,说明该数据已经过时,因此,应用本发明图3所示实施例,可以删除时效性较差的数据。
图4为本发明实施例提供的第四种大数据的管理方法,如图4所示,本发明图4所示实施例在本发明图1所示实施例的基础上,增加了s107:将所有存储服务器中存储的、被访问频率低于第二预设阈值的索引文件对应的数据进行压缩处理。
在实际应用中,假设索引文件n在一年内被访问的次数为1次,被访问的频率为1次/年,若第一预设阈值为1次/月,则索引文件n被访问的频率低于第一预设阈值,将索引文件n进行压缩。
被访问的频率过低,说明该数据已经过时,因此,应用本发明图4所示实施例,将时效性较差的数据进行压缩,可以节省存储服务器的存储空间。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!