基于标记样本位置的高光谱图像进化分类方法与流程
本发明属于图像处理技术领域,主要涉及高光谱图像分类,具体是一种基于标记样本位置的高光谱图像进化分类方法。应用领域为高光谱图像分类。
背景技术:
高光谱图像分类问题在遥感图像处理中,由于高光谱图像存在波段数大,而标记样本难以获取以及光谱混杂等问题,许多学者针对此问题进行了很多研究。
在论文“semisupervisedsubspace-baseddnaencodingandmatchingclassifierforhyperspectralremotesensingimagery”(ieeetransactionsongeoscienceandremotesensing,2016,54(8):4402-4418.)中,maa,zhongy,zhaob等人提出了一种基于子空间的dna编码匹配分类算法。
该方法首先将高光谱图像的各个像素点进行编码表示,并将像素点集合分为三份——标记样本集dt1,无标记样本集dt2以及测试样本集dt3。原算法中dt1集合的样本数较少,dt2作为候选集合用来扩充样本量,在进化的步骤中使用虚拟类标作为真实类标。
进入进化算法步骤后,初始化每一类的代表样本,其创新点在于考虑到每一大类中有子类的存在,所以将每一类的代表个体初始化为多个。而在进化操作时,该文根据标记样本的类标以及为无标记样本分配的类标来选择局部子空间以及全局子空间,目的是去掉无用的信息。再通过适应度计算与随机算子完成一次迭代。随着迭代的进行,保留的代表集合就能越来越好地解决分类问题。
但是该方法也存在一些缺点,比如它没有利用空间信息,过多地依赖光谱特征;进化算法中缺少精英保留策略等。
技术实现要素:
为了克服上述技术的不足,本发明提出了一种提高分类精度的基于标记样本点位置信息的进化高光谱图像分类方法。
本发明是一种基于标记样本位置的高光谱图像进化分类方法,其特征在于,包括有如下步骤:
(1)输入数据:输入高光谱图像数据,即原始数据,高光谱图像数据中包含光谱特征;并用主成份分析(pca)对图像数据降维后得到数个基图像;
(2)在各个基图像上提取差分形态学特征dmp,即一种空间特征;
(3)编码光谱和空间特征,分割数据集,记录位置信息:将差分形态学特征与完整的光谱特征结合,共同编码,并将高光谱图像数据集分割为有标记样本集dt1,无标记样本集dt2以及测试样本集dt3,对于每一类地物,随机选择部分有标记样本点并记录保存其位置信息;
(4)初始化代表点集合dnac:在有标记样本集dt1中随机选择部分样本组成代表点集合dnac,完成初始化;
(5)进入迭代:设置当前迭代为第1代,并限制最大迭代次数为500;对各类地物的代表样本点进行优化;
(6)判断停止条件:判断当前迭代是否达到最大次数或进化算法是否收敛,若未达到最大次数或未收敛则继续,否则跳至步骤9;
(7)构建遗传算子:在进化算法中设计复制、交叉遗传算子,并加入精英保留策略;
(8)选择策略:选择一个合适的适应度函数,利用遗传算子对当前的代表点集合dnac进行进化操作,从中仅选择适应度函数值最大的dnac集合进入下一代优化,即迭代次数加1后返回第6步;
(9)获得中间结果:使用优化结束的代表点集合dnac分别对无标记样本集dt2及测试样本集dt3分类,得到一个分类图像;
(10)最终优化:将分类结果进行基于区域的分割,并与保存的标记样本点位置信息相结合,得到最终的分类结果。
本发明不仅克服了传统高光谱图像分类问题中对于标记样本数需求大的问题,还针对光谱混杂难分的问题进行研究,应用了图像的空间特征,在减少了运算代价之余,还提高了分类的精度。
本发明与现有技术相比有以下优点:
第一,由于本发明采用了半监督学习以及进化算法,使得本方法对于有标记样本点的数目要求并不高,可以在相对较低的获取标记样本代价下较好地完成高光谱图像分类问题。而且进化算法的随机性可以避免陷入局部最优,其适应度函数策略同时具有选择性,加上精英保留策略之后,可以保证每一代的优化能够顺利进行。
第二,由于本发明同时利用了高光谱图像基图像的差分形态学特征、原始光谱特征以及部分标记样本点的位置信息,可以较好地解决由于高光谱图像中光谱混杂造成的难以分类的问题。
附图说明
图1:本发明的流程图;
图2:本发明中设计的交叉模版、复制、变异等进化操作的示意图;
图3:本发明与其他现有技术在indianpines数据集上的对比图,其中图3(a)是真实的地物,图3(b)是实验中记录的标记样本点的位置图,图3(c)是用svm分类器得到的结果,图3(d)是用omp算法得到的结果,图3(e)是ssdna算法得到的结果,图3(f)是本发明的结果图;
图4:本发明与其他现有技术在paviauniversity数据集上的对比图,其中图4(a)是真实的地物,图4(b)是实验中记录的标记样本点的位置图,图4(c)是用svm分类器得到的结果,图4(d)是用omp算法得到的结果,图4(e)是ssdna算法得到的结果,图4(f)是本发明的结果图。
具体实施方式
下面结合附图1对本发明做详细描述。
实施例1
现有高光谱图像进化分类方法存在一些缺点,比如没有利用空间信息,过多地依赖光谱特征,进化算法中缺少精英保留策略等。而空间信息可以为周围样本的分类提供一个较为可靠的依据,一般有pca降维方法后提取差分形态学特征等方法提取空间信息等。而精英保留策略可以保证进化算法每一代迭代的有效性,在经过多次迭代后能够找到近似最优解。
由于高光谱图像波段多,人工获取标记样本代价大,而使用较少的标记样本会出现欠拟合现象,为了解决以上难点,本发明提出一种基于标记样本位置的高光谱图像进化分类方法,参见图1,包括有如下步骤:
(1)输入数据:输入高光谱图像数据,即原始数据,高光谱图像数据中包含光谱特征;并用pca数据降维后得到数个基图像,将基图像输入到下一步中。
(2)在各个基图像上利用基本的膨胀腐蚀操作来提取差分形态学特征dmp,即一种特定的空间特征,这一步中将基图像变化为形态差分学特征,而原始数据中的光谱特征不变,与差分形态学dmp特征一同输入到下一步的编码光谱和空间特征,分割数据集,记录位置信息。
(3)编码光谱和空间特征,分割数据集,记录位置信息:将差分形态学特征与完整的光谱特征结合,共同编码,由于单纯的光谱特征有光谱混杂的现象,所以加入的空间特征能够能够更好地完成分类任务,本发明使用现有方法中将光谱特征编码为3d-2维的向量,其中d表示高光谱数据的波段数目,而对于差分形态学特征这一种空间特征,本发明将其编码为7npc维的向量,其中npc表示保留的基图像个数,与前者拼接之后完成编码,长度为7npc+3d-2。再将高光谱图像数据集分割为有标记样本集dt1,无标记样本集dt2以及测试样本集dt3,每一类样本中随机选择10个加入到dt1中,剩余的20%加入到dt2中,80%加入到dt3中;对于每一类地物,都要随机选择部分有标记样本点并记录保存其位置信息。而记录的位置信息可以表示为一副图片,其中空间信息,即坐标(x,y)处的值为标记样本的类标,其余没有记录的坐标处的值为0,可以参见附图3(b),附图4(b)。
(4)初始化代表点集合dnac:在有标记样本集dt1中随机选择部分样本组成代表点集合dnac,完成初始化,dnac集合中的样本就是各类地物的代表样本点。
(5)进入迭代:设置当前迭代为第1代,并限制最大迭代次数;用以对各类地物的代表样本点进行优化。
(6)判断停止条件:判断当前迭代是否达到最大次数或进化算法是否收敛,这里的收敛是指保留的代表点集合dnac的适应度函数值在多次迭代中都未提高。若未达到最大次数或未收敛则继续执行步骤7,否则跳至步骤9。
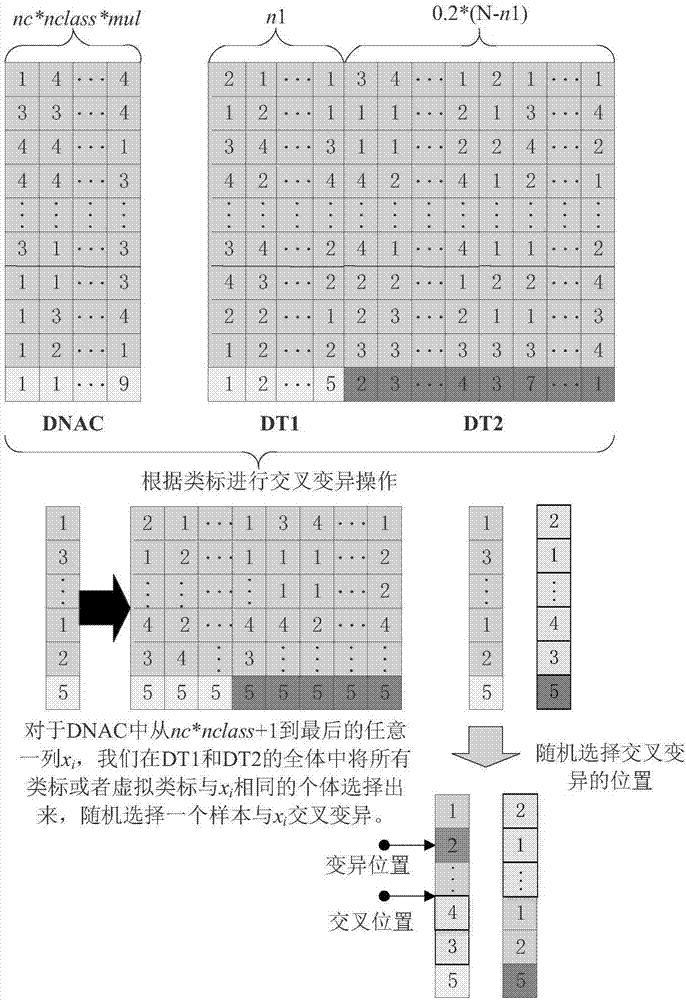
(7)构建遗传算子:在进化算法中设计复制、交叉遗传算子,在复制10次之后加入精英保留策略,即第一份代表点集合不发生变化,而从第2份开始到第10份的代表点集合中的所有样本都要进行基于小交叉模版的交叉操作以及普通的变异操作,这样可以保证每一次迭代的效果不会出现退化,即随着迭代的进行,代表点集合dnac总是能够更好地分类,同时也保证了进化算法搜索最优解的随机性,避免陷入局部最优。而本发明的交叉算子的主要创新之处在于设计了一个小交叉模版,可以利用到更多的与类别相关的信息,能够使得进化操作更具有目的性。
(8)选择策略:首先选择一个合适的适应度函数,对当前所有的10份代表点集合dnac进行适应度评价,并认为适应度越大的代表点集合能够更准确地分类,从中仅选择适应度函数值最大的dnac集合进入下一代优化,即迭代次数加1后返回第6步,继续判断是否达到最大迭代次数或是否收敛。
(9)获得中间结果:使用优化结束的代表点集合dnac对无标记样本集dt2及测试样本集dt3两者并集中的样本分类,得到分类的中间结果图。
(10)最终优化:将分类结果进行基于区域的分割,这里分割的方法具体是:对于任意一个像素点,如果在其8邻域中有与之分类相同的像素点,则将两者看为是一个区域的并为两者分配同一个区域,不断地遍历所有没有分配区域的样本点,使得每个区域尽可能增长覆盖更多的面积,直到所有样本点的区域归属全部确定,即完成分割。分割之后的分类结果图与前面保存的标记样本点位置信息图相结合,得到最终的分类结果,完成高光谱图像的进化分类。
本发明是针对高光谱图像分类问题的一种基于样本空间信息的进化算法,实现思路为:首先将高光谱图像数据进行pca降维处理,选出数个基图像并进行差分形态学特征dmp的提取,将其与原始的光谱数据进行结合之后进行编码表示;并将样本集随机分为三份:标记样本集dt1,无标记样本集dt2以及测试集dt3;并且记录dt1中的部分样本的位置信息;初始化各类的代表点集合dnac,并设置复制规模,变异、交叉的概率以及小交叉模版,设计小交叉模版时需要利用dnac集合来为无标记样本分配虚拟类标,加入精英保留策略,即仅仅对于第二份及之后的dnac集合做进化操作,进化后计算每一份dnac在dt1集合上的整体正确率,作为适应度函数,选取拥有最高适应度的dnac作为下一次迭代的输入,迭代次数加1并重新进行复制、基于小交叉模版的交叉,普通变异等进化操作;当迭代次数达到上限或者算法收敛时停止优化,并将此时的代表集合作为分类依据,对dt2以及dt3的所有样本进行分类。最后将分类的结果进行基于区域的分割,形成多个连通集,再与标记样本的位置图共同优化,得到最终的分类结果。本发明解决了高光谱图像分类中空间信息的利用问题。
实施例2
基于标记样本位置的高光谱图像进化分类方法同实施例1,步骤3中的对空间和光谱特征进行编码,分割数据集,记录位置信息,具体包括有以下步骤:
3.1.对于差分形态学特征dmp的编码如下表示:
其中,
3.2.在编码结束之后对于每一类地物的样本集合,随机选择10个加入有标记样本集合dt1,剩余的20%加入无标记样本集合dt2,80%加入测试集合dt3,将dt2和dt3中的类标信息全部丢掉不用;
3.3.对于dt1中的每一类地物样本,随机选择部分样本,保留记录其位置信息,即先产生一个大小同高光谱图像数据空间分辨率相同的全零矩阵,当随机选择到一个标记样本时,将它对应的坐标位置上的值改为它的类标值,这样,就可以得到一个较为稀疏的矩阵,非零位置代表标记样本的位置,参见附图3(b)以及附图4(b)。
光谱特征的编码在现有方法中已经很成熟,并且在后面的实施例中也有详细介绍,所以这里仅仅介绍了差分形态学特征的编码。而这一步中加入的空间特征的编码,可以弥补单纯的光谱特征表示力有限、光谱混杂等缺点,为每个样本点的分类提供了更多的参考信息。
实施例3
基于标记样本位置的高光谱图像进化分类方法同实施例1-2,步骤7中的构建遗传算子具体是加入精英保留策略以及设计交叉模版,包括有如下步骤:
7.1.加入精英保留策略:在每次迭代中将当前的代表点集合dnac整体复制数份,本例中在进入当前一代的迭代优化后,首先将代表点集合复制mul份,实验中取值为10,将第一份当作精英保留,即不做任何变化,从第二份开始对于每一个集合进行如下所述的进化操作。
7.2.设置交叉模版:进化操作包括有交叉与变异,由于进化算法是模拟自然的算法,因此其中较为重要的也就是更为常见的是交叉操作,而不是发生概率极小的变异操作。本发明在进行普通的交叉之前,需要确定一个小交叉模版,具体步骤如下:
7.2.a.首先根据有标记样本集dt1和无标记样本集dt2的并集产生一个完整的交叉模版;其中无标记样本集合dt2的样本,由于没有明确的类标,需要用当前最优的代表点集合dnac,即第一份dnac来为其分配的虚拟类标。用dnac为dt2集合分配类标的具体策略可以通过度量两个个体的相似性来实现,如下式所示:
式中∩表示两个向量之间的逻辑与操作:如果两个向量某一维度上的值不同,则结果的那一维度上值为0,否则为1;而||·||表示计算向量中非零元素的个数,dnacj表示dnac集合中第j个样本,而dnai这里表示dt2集合中第i个样本,label(dnac,dnai)表示用dnac为dt2中第i个样本分配的虚拟类标,即选择dnac的所有样本中与dnai最相似样本的类标作为其虚拟类标。
7.2.b.产生完整的交叉模版之后,需要将第二份及之后的dnac中所有样本作为待交叉样本进行基于小交叉模版的交叉操作以及普通的变异。针对每一个待交叉样本,都有一个明确的类标;因此,在交叉操作之前,需要从完整的交叉模版中选择出与待交叉样本类标相同的样本集合,组成与这个类标所对应的小交叉模版,再在这个小交叉模版中与待交叉样本进行普通的交叉操作;
7.2.c.普通的交叉、变异操作与现有技术的实现相同。即普通的交叉是随机交叉,在待交叉样本和其他任意一个样本这两个编码向量中随机确定一个交叉点,交换两个向量交叉点之后的所有数值即可,而本发明的基于小交叉模版的交叉是指待交叉样本交叉的对象必须是从与它类标相同的样本中选取;而普通的变异操作,可以在一个编码向量中随机选择一个变异点,将其数值随机变为其他允许的数值即可。经过对第二份及以后的代表样本点集合dnac进行进化操作之后,可以得到很多代表样本点集合,输入到下一步中。
本发明的遗传算子主要不同点在于将交叉样本的选择范围限定在一个模版内,可以利用到更多与类别相关的信息,由于模版是与类标一一对应,即模版中的样本的类标都相同,则可以认为这些样本包含了与类别相关的信息,再通过随机交叉与待交叉样本之间的交流,能够更有指导地找到最优解。其次,加入精英保留策略,也可以使得进化算法的迭代中不会出现退化等现象,保证在每次迭代后选出的结果不会差于上一代的最优结果。
实施例4
基于标记样本位置的高光谱图像进化分类方法同实施例1-3,步骤10中所述的最终优化,具体包括有如下步骤:
10.1.将中间结果,记为mo,进行分割,这样就会形成多个连通集。并做出假设:在一个连通集中的像素点都属于同一类;分割的方法是基于区域的:如果在任意像素点的8邻域中有与之分类相同的像素点,则可以将两者合并为一个区域的。不断地迭代遍历所有样本点,使得每个区域尽可能覆盖更多的面积,直到所有样本点的区域归属全部确定,每一个区域就是一个连通集。
10.2.搜索每一个连通集:在每个连通集覆盖的空间中,对比记录位置信息的标记样本,看多数为哪一类,就将这个连通集中所有像素点都分为那一类;如果连通集中不存在记录位置信息的标记样本,则不改变中间结果mo的分类;
10.3.将连通集搜索完毕之后,方法结束,得到最终的分类结果。
高光谱图像波段多,人工获取标记样本代价大,而使用较少的标记样本会出现欠拟合现象。本发明提出的基于标记样本位置的高光谱图像进化分类方法,可以有效解决对标记样本量需求大,以及单纯的光谱特征混杂难以分类等问题,利用相对较少的标记样本实现对于分类精度的提高。本发明还考虑到高光谱图像的某一类地物几乎是成块分布的,所以像素点的空间信息可以为周围像素点提供很重要的分类信息,在加入标记样本的位置信息后,根据这些位置周围的分类情况来调整局部的误分点的个数,达到更好的分类效果。
实施例5
基于标记样本位置的高光谱图像进化分类方法同实施例1-4,其中步骤10中所述的优化中间结果也可以表述为如下形式:
本发明加入了空间特征编码,相比于单纯的光谱特征,可以较好地解决光谱混杂的现象,更好地分类。而在进化算法中加入了精英保留策略以及不同的交叉算子,提高了分类精度,在随机搜索的基础上加入了限制,小交叉模版可以保证信息的有效性;以及在最后对于分类图的优化步骤,也用到了标记样本的空间信息,实现了更高的分类精度。
下面给出一个更加详尽完整的例子,对本发明进一步说明:
实施例6
基于标记样本位置的高光谱图像进化分类方法同实施例1-5,本发明是针对高光谱图像(hyperspectralimagery)分类问题的一种基于样本空间信息的进化算法。参见图1,其实现包括有如下步骤:
1.输入数据:
将输入的高光谱图像进行pca降维,选择数个基图像。在本发明的实验中,选择的数据集有两个:indianpines以及paviauniversity数据集。根据降维后的数据,选择不同比例的主成份进行保留。为了使不同的数据集降维后能得到合理的基图像个数,实验中对于indianpines数据集,保留前95%的特征值;而对于paviauniversity数据集,保留前99%的特征值。
2.在各个基图像上提取差分形态学特征dmp,差分形态学特征的基础操作是膨胀腐蚀操作:
erode(i,b)λ=min{f(x+x',y+y')|(x',y')∈db}
dilate(i,b)λ=max{f(x-x',y-y')|(x',y')∈db}
式中i表示一幅灰度图像,b表示半径为λ的结构元素,结构元素的各个位置取值只能取0或1,可以随机生成,而min{f(x+x',y+y')|(x',y')∈db}以及max{f(x+x',y+y')|(x',y')∈db}表示在原图像的(x,y)处的半径为λ的邻域db中对应为1的位置上的所有数据中取最小或最大,作为f(x,y)处的值,而erode(i,b)λ与dilate(i,b)λ分别表示用半径为λ的结构元素进行腐蚀以及膨胀操作。当结构元素的半径发生变化的时候就可以根据下式得到差分形态学特征dmp:
其中·λ表示对于某图像进行的半径为λ的膨胀腐蚀操作,|a-b|表示两幅图像的差分并取绝对值操作,即对应位置取差的绝对值,dmpop与dmpcl就分别表示dmp的开闭特征,将两者再与原始的基图像直接并联即可形成七幅图像,即每一幅基图像中的任意一个像素点可以编码为7维的向量。而mp定义为:
其中opλ(i)表示形态学开操作,即先对图像i使用半径为λ的结构元素进行先腐蚀后膨胀的结果;而clλ(i)表示形态学闭操作,即先对图像i使用半径为λ的结构元素进行先膨胀后腐蚀的结果。
3.编码空间和光谱特征,分割数据集,记录位置信息:
首先将高光谱图像同样是按列优先转换成一个二维矩阵d={x1,x2,...,xn}。记xi∈rd,i=1,2,...,n,其中d是高光谱图像的波段数,n是像素点数目。对数据的编码方式可以表现为以下四部分。
a.形状特征,其编码长度为d:对于任意一个像素点xi,将其谱值按升序排列,得到xi∈rd,
b.斜率特征:将相邻谱值之间所有不同的变化方式编码,其编码长度为d-2。若记δ为期望的光谱值公差,即:
式中θ是一个常数,实验中取值为0.5,
c.振幅特征:振幅特征是一个累加特征,其编码长度为d。具体表述如下,对于所有像素点的第j个波段xj,所有光谱值可以形成一副灰度图像,将所有灰度值累加,得到最大值g,最小值就是
no=mapping(g)
再有(0.75n)=mapping(tmax),(0.5n)=mapping(tmid),(0.25n)=mapping(tmin),其中n代表全部像素点个数,
d.差分形态学特征编码
其中,
综合以上4种编码,可以将每一个样本编码表示成一个7npc+3d-2维的向量,其中npc表示基图像的个数,d表示波段数。将这些样本点分成三个集合:有标记样本集dt1,无标记样本集dt2以及测试集dt3。其中对于每一类样本,dt1中包含n1个样本,实验中设置为10,剩余样本中20%加入dt2,80%加入dt3。最后随机选择部分dt1中样本记录位置。
4.初始化代表点集合dnac:
借鉴以往算法,本发明将每一类代表点设置为nc个,初始化时在dt1中将所有类别的样本都随机选择nc个,组成代表点集合,记为dnac,即完成初始化,实验中nc在两个数据集中都取为3。因此对于有nclass个地物类别的数据集,dnac集合的大小为nc×nclass。
5.进入迭代:
设置当前迭代为第1代,并限制最大迭代次数,本例中的最大迭代次数为500;用以对各类地物的代表样本点进行优化。
本发明中,最大迭代次数为500,也可以根据优化中适应度函数值的变化增加至另外一个较大的数值,比如1000,1500等;而当优化较好时,也可以提前结束,最大迭代次数可以选择小一些,但要保证算法收敛。
6.判断停止条件:
判断当前迭代是否达到最大次数或者进化算法是否达到收敛,本发明中收敛表示进化操作得到的dnac代表点集合的适应度函数值在较多的迭代之后仍未有所增加。若未达到,则继续执行,否则跳至步骤9;
7.构建遗传算子:
在这一步中,首先将代表点集合整体复制,并从第二份及以后的代表点集合dnac开始进行交叉变异算子,将第一份代表点集合作为精英保留。其中的交叉算子并非完全随机,而是根据一定的模版进行的,需要根据有标记样本集dt1和无标记样本集dt2的并集,产生完整的交叉模版。对于无标记样本集合dt2中的样本,由于没有明确的类标,需要用当前最优的代表点集合dnac,即第一份dnac来为其分配的虚拟类标来作为参考;而虚拟类标的获取是用当前dnac集合为dt2集合中所有个体分配类标产生的。可以度量两个编码的相似性来分配类标,如下式所示:
式中∩表示两个向量对应位置之间的逻辑与操作:两者相同,结果为1;两者不同,结果为0,而||·||表示计算向量中非零元素的个数,dnacj表示dnac集合中第j个样本,而dnai表示dt2集合中第i个样本,也就是待分配虚拟类标的样本,label(dnac,dnai)表示用dnac为dt2中第i个样本分配的虚拟类标。产生完整的交叉模版之后,将第二份及之后的dnac中所有样本作为待交叉样本,针对每一个待交叉样本,都有一个明确的类标;因此,对于每一次交叉操作,需要从完整的交叉模版中选择出与待交叉样本类标相同的样本集合,组成与这个类标所对应的小交叉模版,用这个小交叉模版与每一个待交叉样本进行普通的交叉操作;普通的交叉操作是在两个编码向量中随机选择一个交叉点,将两个向量在交叉点前后的数值互相交换即可;而普通的变异操作表示对于任意向量,随机选择一个变异点,将其数值随机变为其他可能数值中的任意一个。可参见附图2。
附图2是设计的交叉模版以及复制规模,变异交叉算子等的具体说明。附图2中每一列代表一个样本,最后一行是每个样本的类标,其中黄色的类标代表了真实类标,而绿色的类标代表虚拟类标,是用dnac为dt2集合分配的类标。而在普通的交叉变异时,可以看出交叉点前后的数据完全交换,而交叉点(蓝色)则随机变异为另一个允许的数值即可。图中nc代表每一类选择的代表个数,在本例中设置为3,nclass代表数据集的地物类别数,mul代表复制规模,实验中设置为10,n1是有标记样本集的大小,n是非背景样本数目。
8.选择策略:
首先要选择合适的适应度函数,可以将使用某一份dnac集合对于dt1数据集的分类总体正确率oa作为适应度函数值,即:
其中dnaci表示第i份dnac,mul表示复制规模,实验中设置为10,而oai表示用第i份dnac为有标记样本集合dt1分配类标的总体正确率。在确定了适应度函数之后,可以评价所有dnac集合的优劣,适应度函数值越高的代表点集合越好。之后在复制进化得到的多个dnac集合中,选择适应度函数值最大的dnac集合进入下一代优化,即迭代次数加1,返回第6步。
9.获得中间结果:
当进化算法收敛或者达到最大迭代次数之后,利用此时保存的dnac集合来对dt2,dt3中的所有样本进行分类,分类的准则同步骤7中的公式所述,只是此时的dnacj不再表示dt2中的所有样本,而是dt2与dt3取并集的集合中的所有样本,初步分类结束后可以得到中间的分类结果mo。
10.最终优化:
根据中间的分类结果,我们还要根据第3步中记录的标记样本位置信息进一步的优化,其具体步骤如下所述:
10.1.将中间结果mo进行分割,这样就会形成多个连通集。并做出假设:在一个连通集中的像素点都属于同一类;分割的方法是基于区域的:如果在某像素点的8邻域中有与之分类相同的像素点,则可以将两者看为是一个区域的。不断地迭代遍历所有样本点,使得每个区域尽可能覆盖更多的面积,直到所有样本点的区域归属全部确定;
10.2.搜索每一个连通集:在每个连通集覆盖的区域中,标记样本多数为哪一类,就将这个连通集中所有像素点都分为哪一类;如果连通集中不存在标记样本,则不改变中间结果mo的分类;
10.3.将连通集搜索完毕之后,本方法结束,得到最终的结果。
空间信息可以为周围样本的分类提供一个较为可靠的依据,本发明在pca降维后得到的多个基图像上进行形态学操作,可以提取到差分形态学特征dmp,作为一种空间信息。利用进化算法的选择性和随机性,能够启发式地选择更优的用以对无标记样本进行分类的代表点集合dnac,同时每一次迭代的随机性也可以避免陷入局部最优的情况,在进化算法中加入精英保留策略可以保证其在每一代迭代的有效性,不会出现退化现象。同时,由于本发明采用了半监督学习,使得对于有标记样本点数目的要求并不高,可以在相对较低的获取标记样本代价下解决问题。在最后一步,仅仅使用少量的标记样本以及它们的位置信息做出进一步优化,达到了更高的分类精度。正是由于以上几点优势,本发明能够更好地解决高光谱图像分类问题,提高了分类精度。
实施例7
基于标记样本位置的高光谱图像进化分类方法同实施例1-6,下面结合附图3和附图4对本发明做进一步的描述。
仿真实验条件:
本发明的仿真实验采用的硬件平台为:处理器intercorei7,主频2.60ghz,内存8gb;
软件平台为:windows10家庭中文版64位操作系统、matlabr2016b。
实验内容:
本发明的仿真实验采用的是常见的高光谱图像数据集indianpines以及paviauniversity,其真实地物图分别见附图3(a)与附图4(a),对其中的非背景点进行分类。其中indianpines数据集于1992年用aviris传感器采集于美国印第安纳松林西北部,场景包含三分之二和三分之一的农业、森林等自然植被。去除水吸收波段后包含200个波段,图像大小为145×145,共包含16种地物。而paviauniversity是于2003年由rosis传感器采集到的意大利paviauniversity地区。总光谱范围为从0.43μm到0.86μm的115个波段,去掉12个含噪波段之后,包含103个波段,图像大小为610×340,共包含9种真实地物类别。实验内容是将两个数据集中的非背景样本点利用样本点的各种编码信息以及标记样本点的位置信息进行分类,比较不同方法的分类效果,本发明可以达到更好的分类效果。
实验结果分析:
附图3(a)是indianpines数据集的真实地物图,而图3(b)是记录的标记样本的分布图,图3(c)是利用支持矢量机算法(svm)对于数据的分类结果,图3(d)是利用正交匹配追踪算法(omp)对数据的分类结果,图3(e)是利用基于半监督与子空间的dna匹配算法(ssdna)对数据的分类结果,图3(f)是本发明对该数据的分类结果。从分类的视觉效果来看,本发明与svm,omp,以及ssdna等现有方法相比,本发明更能在大体上接近真实情况。虽然在图3(f)中的1,2,3部分中均出现了杂乱点的情况,这也是标记样本的位置信息不足造成的,但是其他对比方法中对应位置处杂乱点更多,可见本发明在1,2,3位置上的分类精度均高于其他方法。
附图4(a)是paviauniversity数据集的真实地物图,而图4(b)是记录的标记样本的分布图,图4(c)是利用支持矢量机算法(svm)对于数据的分类结果,图4(d)是利用正交匹配追踪算法(omp)对数据的分类结果,图4(e)是利用基于半监督与子空间的dna匹配算法(ssdna)对数据的分类结果,图4(f)是本发明对该数据的分类结果。从附图4(f)中可以看出在大的联通区域,图中的1,2部分中,由于借鉴了有标记样本的标签,所以本发明几乎可以完全正确地分类,而其他算法附图4(c),4(d)以及4(e)的相应位置上均有不同程度的杂乱点,本发明相比于现有方法来说,错分点较少,尤其在大连通区域1,2中可以实现完全正确的分类。
简而言之,本发明公开的一种基于标记样本位置的高光谱图像进化分类方法。解决了高光谱图像分类中空间信息的利用问题,具体步骤有:输入数据,用pca降维后的基图像;提取差分形态学特征;差分形态学与光谱特征结合编码,分割数据集、记录部分标记样本的位置;初始化代表样本点;开始迭代,确定最大迭代次数;判断停止条件,若满足,则直接对无标签样本分类;不满足则设计交叉模版、精英保留策略进行进化后选择代表点集合再次迭代,直至满足条件;在无标签样本分类后,对分类结果分割,参考标记样本点位置,进一步优化。本发明用空间信息以及进化算法完成了对高光谱图像的分类。搜索更有依据;提高了分类精度。应用于高光谱图像分类。
- 还没有人留言评论。精彩留言会获得点赞!