一种静态社交网络的重叠社团发现方法与流程
本发明属于计算机应用技术领域,尤其涉及一种静态社交网络的重叠社团发现方法。
背景技术:
在社交网络中,网络往往具有分簇的形态,簇内中的社交成员联系紧密,簇间的社交成员联系稀疏,把这种簇叫作社团或是社群,挖掘社团的过程叫做社团发现。在社交网络中,将社交成员当成节点,社交成员之间的联系用节点之间的连线表示,这样就形成了图网络。ahn等人在2010年《nature》杂志发表了文章“linkcommunitiesrevealmultiscalecomplexityinnetworks”首次提出边图概念,而且利用边图进行社团发现,边图的概念在后来被人们多次使用,本发明所进行的社团发现也是以边图为基础的,该文章所提出的方法复杂度较高,不适合大规模社交网络。zhang在2007年ieeeinintelligenceandsecurityinformatics的文章“anlda-basedcommunitystructurediscoveryapproachforlarge-scalesocialnetworks”中利用lda方法,但是他是以节点为lda模型的输入数据。于乐等在2014年asonam2014会议上发表了“overlappingcommunitydetectioninlargenetworksfromadatafusionview”,文章在边图下利用lda模型,然而在设计重叠划分准则时过于简单。
综上所述,现有技术存在的问题是:针对大规模社交网络,利用边图进行社团发现的算法效率低下,而且重叠程度固定不可调。对于于乐等人提出的方法,重叠划分准则只考虑了边的归属概率值大小,本发明指出这样的准则是不准确的,本发明提出了一种更加准确的划分准则方法。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种静态社交网络的重叠社团发现方法。
本发明是这样实现的,一种静态社交网络的重叠社团发现方法,所述静态社交网络的重叠社团发现方法包括以下步骤:
第一步,对社交网络进行边图转化;
第二步,将边图和主题发现模型进行映射,得到边的归属情况;
第三步,利用划分准则对边的归属概率矩阵进行重叠划分。
进一步,所述静态社交网络的重叠社团发现方法包括以下步骤:
步骤一,将原图转化为边图,对边图进行网络量化编码;
步骤二,边图结构与主题发现模型的映射;
步骤三,重叠社团划分。
进一步,所述步骤一具体包括:
(a)给定网络g=(v,e),其中顶点集为v=(v1,…,vn),边集为e=(e1,…em),构建边图将原图g中的边ei看作边图中的节点,边图中的两节点是否有边连接是看在原图g中是否两条边是否存在公共节点;
边图lg的节点原图g中边映射为边图中的节点,边图中的节点表示为v(lg)=e(g);
边图lg的边边图中的边取决于在原图中两条边是否存在公共节点,对于e∈e(g),用ep(e)表示原图g中边的两个端点,于是边图lg中的边即原图中两条边是否存在公共节点表示为:
边图lg边的权重定义边图中边的权重,建立g的关联矩阵a:
通过关联矩阵a得到边的权重:
其中,d(vm)表示原图g节点vm的度;
(b)对边图进行网络量化编码
对于图g=(v,e),按照定义先转化为边图lg,定义边图的邻接矩阵he×e,而且h(i,j)=wi,j。
进一步,所述步骤二具体包括:
(1)lda模型文档和主题之间服从参数为
(2)文档和主题、主题和词语之间通过主题联系。
进一步,所述步骤三具体包括:
定义归属概率计算方法:
其中,pr*(i,j)=max{pr(i,:)},count{pr*(i,j)}表示第i条边划分到第j个社团的次数,α和β为权重系数;得到节点的归属概率值后,可调重叠的策略;
社团重叠程度的方法:
其中,γ∈(0,1)是重叠因子。
本发明的另一目的在于提供一种应用所述静态社交网络的重叠社团发现方法的社区网络。
本发明的优点及积极效果为:提出门限准则来控制社团的重叠程度,可以得到不同重叠程度的社团发现结果。社团划分结果可以提高对社团内用户行为分析的准确性,而且还可以进行重要用户的挖掘和潜在好友的推荐。在本发明中,以这种图网络作为对象;在早期的社团发现中,人们只关注如何将网络结构划分成非重叠社团。然而在实际的社交网络中,社团之间往往是重叠的,某些社交成员往往属于多个社团,本发明把这种社团发现叫做重叠社团发现(也叫模糊社团发现)。
本发明采用对边图编码的数据,利用主题发现模型进行社团发现;边图的编码降低了原图中度数较大节点对社团发现的影响,采用文本主题发现模型中采样过程降低了社团发现中个别干扰边对社团的整体划分,重叠准则的设计,提高了社团重叠结构的准确性,并且使得重叠程度可控。
附图说明
图1是本发明实施例提供的静态社交网络的重叠社团发现方法流程图。
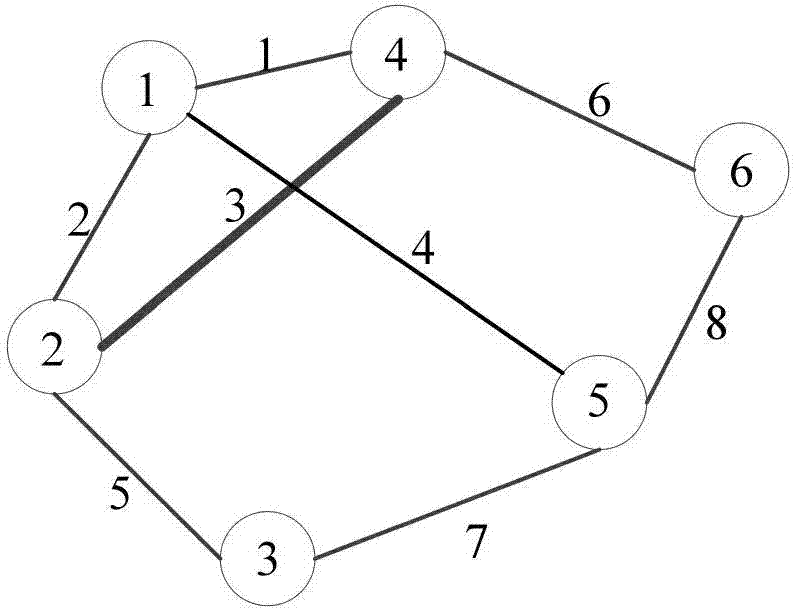
图2是本发明实施例提供的边图示意图。
图3是本发明实施例提供的边社团采样示意图。
图4是本发明实施例提供的lda模型的过程示意图。
图5是本发明实施例提供的社区发现重要节点示意图。
图6是本发明实施例提供的与(me)和oslom、abl方法示意图;
图中:(a)μ=0.1;(b)μ=0.4。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的静态社交网络的重叠社团发现方法包括以下步骤:
s101:对社交网络进行边图转化;
s102:将边图和主题发现模型进行映射,得到边的归属情况;
s103:利用划分准则对边的归属概率矩阵进行重叠划分。
下面结合附图对本发明的应用原理作进一步的描述。
本发明实施例提供的静态社交网络的重叠社团发现方法具体包括以下步骤:
步骤1:将原图转化为边图,然后对边图进行网络量化编码。
(1a)给定网络g=(v,e),其中顶点集为v=(v1,…,vn),边集为e=(e1,…em)。构建边图(linegraph)的方法是将原图g中的边ei看作边图中的节点,而边图中的两节点是否有边连接是看在原图g中是否两条边是否存在公共节点。
定义1-1边图lg的节点原图g中边映射为边图中的节点,那么边图中的节点可以表示为v(lg)=e(g)。
定义1-2边图lg的边边图中的边取决于在原图中两条边是否存在公共节点。对于e∈e(g),用ep(e)表示原图g中边的两个端点,于是边图lg中的边即原图中两条边是否存在公共节点可以表示为:
定义1-3边图lg边的权重定义边图中边的权重,首先建立g的关联矩阵a:
通过关联矩阵a可以得到边的权重。一种常用的边权重计算方式为(实际应用中计算方式可以根据需求进行调整):
其中,d(vm)表示原图g节点vm的度。
(1b)对边图进行网络量化编码
对于图g=(v,e),按照定义先转化为边图lg。定义边图的邻接矩阵he×e,而且h(i,j)=wi,j(根据边图中连接边权重定义)。
如图2,以3号边为例,与3号边相连的临边有1、2、5、6号边,组成了3号的临边集。于是,h的第三行h(3,:)=(w3,1w3,200w3,5w3,600)。考虑到实际情况,矩阵中会出现大量的零元素,在实际应用的时候采用稀疏矩阵存储数据。
步骤2:边图结构与主题发现模型的映射。
下面具体以lda模型为例介绍具体过程。边图结构与lda模型映射,把网络编码的结果作为模型的输入数据,利用lda–gibbssampling得到边的归属概率矩阵。
(2a)lda模型假设doc-topic(文档和主题之间)服从参数为
使用概率图模型表示,lda模型的过程如下图3所示:
(2b)“doc”-“topic”“topic”-“word”之间通过主题联系的,采用lda模型进行社团发现的核心思想是,“doc”与边的映射,“word”与临边集的映射,“topic”与社团的映射。
如图4,z11表示边e1的临边集w11所属的社团。在边社团采样中,边作为采样对象,采样结果是记录每条边及边地临边集被划分到每个社团的次数,这里只关注
于是,将得到一个边划分的归属概率矩阵pr=[p(zi=k|ei)]mk。利用其它的主题发现模型同样可以得到边的归属概率,实际应用中可以根据不同的需要选择合适的主题发现模型。
步骤3:重叠社团划分准则
(3)如图5,像α这种节点在实际社团发现中是非常重要的,它是连接两个社团的重要节点。进行重叠社团发现的目的就是将类似这样的节点找出来。如果它属于a和b社团的概率接近,应该即把它划分到a中,也划分到b中,从而提高社团划分的准确性。
在实际应用中,可以设计具体的重叠划分准则,根据不同的需求,划分方式可以有细微的差异。例如式本发明定义了一种的归属概率计算方法:
其中,pr*(i,j)=max{pr(i,:)},count{pr*(i,j)}表示第i条边划分到第j个社团的次数,α和β为权重系数。当本发明得到节点的归属概率值后,设计可调重叠的策略。例如式,本发明给出了一种具体的社团重叠程度的方法:
其中,γ∈(0,1)是重叠因子。本发明可以通过调节γ来控制节点的重叠程度,提高社团发现的准确性。真实网络的社团结构往往是未知的,重叠程度更是无从知晓,在实际应用中本发明只有通过调节参数,加上其它外在条件才能得到更加准确的社团结构。
下面结合具体的应用对本发明的应用原理作进一步的描述。
lfr网络生成数据的应用,lfr是由lancichinetti等人在newjournalofphysics发表的文章“detectingtheoverlappingandhierarchicalcommunitystructureincomplexnetworks”提出的人为可控的网络生成程序。本发明可以通过该程序生成不同大小、不同重叠程度的人造网络,而且程序会给出标准的社团划分结构,一般本发明都会结合nmi准则来验证社团发现结果的准确率。归一化互信息(normalizedmutualinformation,nmi)是计算两个社团之间的互信息量的,两个社团结构越相似,nmi的值就越大,nmi的取值范围为0~1。
这里本发明生成节点数(1000),最大的节点度数(30),平均度数(10),最小社团数(10),最大社团数(20),重叠节点数(50),重叠节点所在社团数目(2)的参数下的网络数据。
下面结合对比对本发明的应用效果作详细的描述。
本发明和oslom(a.lancichinetti,f.radicchi,j.ramasco.findingstatisticallysignificantcommunitiesinnetworks[j].plosone,2011,6(4):el8961.)方法、abl(y.ahn,j.bagrow,s.lehmann.linkcommunitiesrevealmultiscalecomplexityinnetworks[j].nature,2010,466(7307):761-764.)方法进行比较,比较了在不同的μ(混合参数)下的nmi性能。
如图6,比较了本发明提出的方法(me)和oslom、abl方法,从图中本发明可以看出,本发明提出的方法的nmi性能明显优于oslom和abl方法。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!