基于Wrapper特征选择Bagging学习处理心电图的系统及方法与流程
本发明涉及计算机医疗应用领域,具体涉及一种基于wrapper特征选择bagging学习处理心电图的系统及方法。
背景技术:
智慧医疗旨在通过打造健康档案区域医疗信息平台,利用最先进的物联网技术,实现患者与医务人员、医疗机构、医疗设备之间的互动,逐步达到信息化。近年来,由人工智能、医用机器人和数字化辅助医疗技术等相结合的智能医疗技术,正引领新一轮的医疗变革。智能医疗技术开始贯穿于诊断、手术、护理和康复等医疗的各个环节。在临床诊断过程中,医院一直依赖心电图作为监测病人心脏电活动的仪器。由于纸张易破碎且热敏纸字迹不稳定、易消退,多数纸质心电图都遭到了不同程度的破坏。
尽管外许多研究者提出了较多针对心电波形曲线的提取和医疗诊断预测技术,但由于纸质心电图提取的易破碎且热敏纸字迹不稳定、易消退,以及提取后的心电数据多是偏性,对后续机器学习的模型建立与训练上有很大的影响,现有纸质心电图提取和诊断预测模型包含如下几方面缺点:
(1)心电曲线的提取问题
临床采集的心电图表现为心电曲线和背景网格交错在一起,且纸面上会有不同程度的污损、字迹等其他干扰信息。目前的相关研究中,纸质心电图波形数据提取的主要瓶颈是需要人工干预。
(2)如何将提提取的波形曲线转化为波形数据
临床采集的心电信号由高维向量表示的,在使用计算机对心电信号分析的过程中就是对这组高维向量进行分析。由于扫描原因会使得提取出的波形曲线的宽度大于l,所以提取的曲线是以矩阵的形式存在,而不是以向量的形式存在。如何将以矩阵形式存在的波形曲线以最大的满意度转换为以向量形式保存的波形数据值得研究。
(3)数据不平衡性
现有的smote数据平衡方法,只是在原有的基础上将数据平衡,这样做的结果只会增加数据量,对后续wrapper方法筛选冗余特征这一步骤的时间效率上产生负面的影响。
(4)机器学习算法的不稳定性
决策树算法依据信息熵理论,选择当前样本集中具有最大信息增益率的属性作为测试属性不断对样本集进行划分,最终构造出一棵完全决策树。但是它是不稳定的算法,训练集的小范围变动就可能造成分类模型的显著变化。
技术实现要素:
为解决上述技术问题,本发明提出了一种基于wrapper特征选择bagging学习处理心电图的方法,以达到准确分析心电数据的目的。
为达到上述目的,本发明的技术方案如下:
一种基于wrapper特征选择bagging学习处理心电图的系统,包含有扫描模块和数据分析处理模块,所述扫描模块与所述数据分析处理模块之间通过网络进行连接,
所述扫描模块,用于将心电图纸的内容扫描成心电图像;
所述数据分析处理模块包含有:波形矫正提取模块、数据平衡压缩模块、wrapper特征选择模块、baggingc4.5集成模块,所述波形矫正提取模块,用于检测矫正心电波形并将心电波形曲线和背景分离发展;所述数据平衡压缩模块,用于对心电数据进行平滑处理和压缩处理;所述wrapper特征选择模块,用于剔除心电数据中的冗余特征;所述baggingc4.5集成模块,用于对心电数据进行分析预测,各模块间通过数据总线进行通信连接。一种基于wrapper特征选择bagging学习处理心电图的方法,通过sobel_mco筛选机制的k-means方法将纸质心电图提取出数字化数据集,对于得到的心电数据,通过基于wrapper特征选择的新型baggingc4.5算法进行医疗数据分析预测,将分析预测的结果反馈给用户,具体包括如下步骤:
步骤1:纸质心电图数字化;
步骤2:将步骤1采集的数字化心电数据,通过s-c4.5-smote数据平衡方法进行平滑处理,从而降低数据的大小和不平衡性;
步骤3:将经过s-c4.5-smote处理后的数据进行wrapper特征选择,剔除数据的冗余特征(其中算法评价器c4.5),通过这一步骤可以剔除对医疗数据分析有害的特征;
步骤4:对上述步骤获取的医疗数据进行bagging-c4.5方法分析预测,并将分析预测的结果通过设备反馈给医疗机构和用户。
作为优选的,步骤1所述纸质心电图数字化的具体步骤为:设定原始心电图彩色图像,对所述原始心电图彩色图像进行边缘检测,获得阶跃状边缘点集合,所述边缘点集合包含了波形的上下轮廓以及其他点,对所述边缘点集合进行形态学闭运算并且填补波峰和尖锐波谷,保留像素点集合,对所述像素点集合进行基于sobel_mco筛选机制的k-means算法处理,处理结果是将波形曲线和背景分离发展。
作为优选的,步骤2所述s-c4.5-smote数据平衡方法是将步骤1提取的数字化心电数据集合进行平衡与压缩处理,所述s-c4.5-smote数据平衡方法集成了简单随机抽样法和合成少数民族抽样法(smote)的优点,减少冗余特征,提高bagging学习的泛化能力。
作为优选的,步骤3所述wrapper特征选择是搜索策略和机器学习算法相结合,选择出最终的算法达到较高的特征子集,有p个特征,那么就会有2p种特征组合,每种组合对应了一个模型。
作为优选的,步骤4所述bagging-c4.5方法是采用bagging方法对c4.5算法进行集成,所述c4.5算法将上述步骤获取的心电数据进行训练,训练过程按照分支属性选择方法,自顶向下形成决策树分类器,内部节点表示分支属性,叶节点代表类,所述bagging方法为:输入经c4.5算法训练后的训练集,生成预测函数,输出集成预测模型。
本发明具有如下优点:
(1).本发明将纸质心电图转化为数字化心电数据,实现心电波形曲线和复杂背景的有效分离,进行心电波形曲线提取。该方法先使用筛选机制进行预处理,尽可能多的保留属于波形曲线的像素点,并尽可能多的排除无用点,保留的像素点集合作为聚类对象。
(2).提出了一种新的数据平衡算法—s-c4.5-smote,有效的处理了医疗数据的偏性问题,并且降低了数据的大小,提高了后续wrapper特征选择方法筛选的效率。
(3).通过引入bagging学习方法,解决了传统决策树算法的不稳定性,并且通过wrapper特征筛选后的特征子集,解决了因为冗余特征带来的bagging学习的泛化能力差的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例公开的基于wrapper特征选择bagging学习处理心电图的系统的结构示意图;
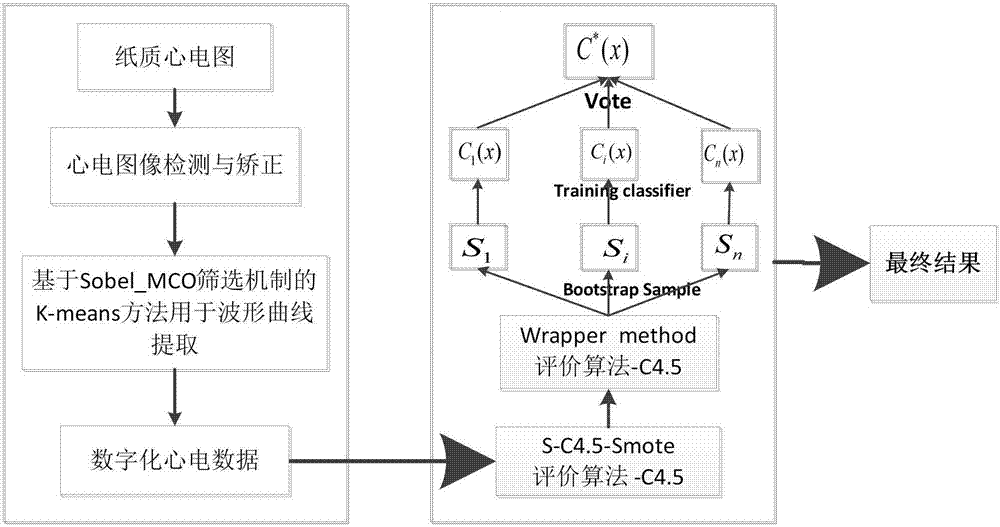
图2为本发明实施例公开的基于wrapper特征选择bagging学习处理心电图的方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了一种基于wrapper特征选择bagging学习处理心电图的方法,其工作原理是通过sobel_mco(morphologicalclosedoperation)筛选机制的k-means方法用于纸质心电图波形曲线的提取以转化为数字化心电数据;将得到的数字化心电图通过s-c4.5-smote和wrapper方法进行预处理,以平衡心电数据集和筛选对诊断有害的特征;最终通过bagging-c4.5集成技术对得到的数字化心电数据进行分析预测,达到准确分析心电数据的目的。
下面结合实施例和具体实施方式对本发明作进一步详细的说明:
如图1所示:基于wrapper特征选择bagging学习处理心电图的系统,包含有扫描模1块和数据分析处理模块2,所述扫描模块1与所述数据分析处理模块2之间通过网络进行连接,
所述扫描模块1,用于将心电图纸的内容扫描成心电图像;
所述数据分析处理模块2包含有:波形矫正提取模块3、数据平衡压缩模块4、wrapper特征选择模块5、baggingc4.5集成模块6,所述波形矫正提取模块3,用于检测矫正心电波形并将心电波形曲线和背景分离发展;所述数据平衡压缩模块4,用于对心电数据进行平滑处理和压缩处理;所述wrapper特征选择模块5,用于剔除心电数据中的冗余特征;所述baggingc4.5集成模块6,用于对心电数据进行分析预测,各模块间通过数据总线进行通信连接。
如图2所示,基于wrapper特征选择bagging学习处理心电图的方法,具体包括如下步骤:
步骤1:纸质心电图提取
将纸质心电图转化为数字化心电数据,设原始心电纸质图像为f(x,y),边缘检测过程中阈值为tk,边缘检测获得的阶跃状边缘点集合为{g(x,y)},{g(x,y)}包含了波形的上下轮廓以及其他点。形态学闭运算的结构元素定义为b。将{g(x,y)}进行形态学闭运算并且填补波峰和尖锐波谷后保留的像素点集合定义为{k(x,y)}。
初始化tk,b,{g(x,y)}=φ,{g(x,y)}=φ;
使用梯度算子进行边缘检测,梯度也就是一阶导数,设图像为f(x,y),则图像在(x,y),出的梯度向量如公式(1)表示:
该向量的大小即梯度值,用
设向量在(x,y)处的方向角用α表示:
图像边缘在(x,y)处的方向垂直于该梯度向量的方向。通常计算中为了减少计算量,使用绝对值方法近似获得(x,y)处的梯度值,即
由上述梯度算子的公式,sobel梯度算子实现,
(1)sobel算子模板
表格(1)为sobel梯度算子水平方向的模板和垂直方向的模板,水平方向的模板用于计算水平梯度值,垂直方向的模板用于计算垂直梯度值。箭头所指位置为中心点,设模板移动过程中经过的中心点用(i,j)表示,则中心点的八个邻域分别表示为,(i-1,j-1),(i-1,j),(i-1,j+1),(i,j+1),(i+1,j-1),(i+1,j),(i+1,j+1),则(i,j)处的水平方向的梯度值g表示为:
gx=f(i+1,j-1)+2*f(i+1,f)+f(i+1,j+1)-[f(i-1,j-1)+2*f(i-1,f)+f(i-1,j-1)](5)
垂直方向的梯度值g表示为:
gy=f(i-1,j+1)+2*f(i,j+1)+f(i+1,j+1)+[f(i-1,j-1)+2*f(i,j-1)+f(i+1,j-1)](6)
由公式(4)可知,(i,j)处的梯度值用|gx|+|gy|近似表示。
通过公式(4)、(5)、(6),对{g(x,y)}进行形态学闭运算,
根据{k(x,y)}的二维直方图(灰度一位置)波峰确定初始聚类中心m1,m2,...mn,按照距离最近的原则,根据簇中对象的平均值(聚类中心),将每个对象赋给最类似的簇,更新簇中的平均值,即重新计算每个簇的平均值。
据公式k-means聚类平方误差准则,即公式:
计算:若e发生变化转到步骤2.3,若e不再发生变化则结束。
经过基于sobel_mco筛选机制的k-means算法,可以做到聚类前的预处理,尽可能多的保留属于波形曲线的像素点,并尽可能多的排除无用点,根据数据特点确定的聚类中心可以使得聚类过程向着预期目标—即波形曲线和背景的分离发展。
步骤2:将步骤1提取的数字化心电数据进行平衡处理
基于步骤1方法提取的心电数据,在临床数据分析中,得到的数据往往存在偏性,即阳性数据和阴性数据比例不平衡。如果数据不平衡,分析得到的结论可能会产生偏倚。比如在判别分析中,阳性数据如果多于阴性数据,那么分类的结果会更易于偏向阳性数据,造成灵敏度度较高、特异度较低的结果。因此需要对获得的医疗数据进行平衡。
s-c4.5-smote是smote的改进方法,它通过引入合成少数样本技术和简单随机抽样方法来提高wrapper方法的效率。因此,为了提高bagging学习的泛化能力,冗余特征也必须尽可能的减少。
首先按照等概率进行数据抽样(抽样比例1—100%),其中我们选取c4.5作为评价函数。通过比较最合适的抽样比例,对数据集进行抽样,然后应用合成少数样本方法,每个类的数据集的大小几乎相互平衡。其中smote的原理为:
假设有少数类样本,每一个样本x,搜索其k(通常取5)个少数类最近邻样本;若向上采样的倍率n,则在其k个最近邻样本中随机选择n个样本,记为y1,y2,,...,yn;在少数类样本x与yj(j=1,2,...,n)之间进行随机线性插值,构造新的少数类样本pj。
pj=x+rand(0,1)×(yj-x),j=1,2,...n(9)
式中,rand(0,1)表示区间(0,1)内的一个随机数。将这些新合成的少数类样本点合并到原来的数据集里即可以产生新的训练集。
通过s-c4.5-smote方法,不仅可以提高效率,并且不影响预测的准确性,其步骤描述如下
输入:数据集d,学习器c4.5。
1.数据集d中的元素总数为n
2.使用随机数函数从1到n生成随机数r。如果r未被标识为未选择,则将其标识为已选择并将r添加到样本。然后重复上述步骤,直到选择m个(采样比)样本。
3.数据集d用于通过c4.5算法预测采样效果按照采样率10%-100%,并与采样台配合选择最高的效率(实验部分记录在下面)以确定新的数据集d'。
4.对于新数据集d',找到每个最近邻的k个基于过采样率n的稀有类样本,然后n个样本随机选择。根据等式(9),n个新的罕见例子是生成使用每个样本的罕见例子及其选择的n个病例。
输出:新数据集d'
步骤3:wrapper特征选择方法筛选特征集
特征选择是指从d维的特征f中选择一个d维子集,该子集在f的所有维数为d的子集中使某个准则函数j是最优的。特征选择的两个重要方面是搜索策略和准则函数。wrapper方式是考虑具体的学习算法,由分类器的结果来评价特征好坏选择出最终的算法达到较高的特征子集,首先假如有个d特征,那么就会有2d种特征组合,每种组合对应了一个模型。
搜索策略:前向搜索和后向搜索
初始化特征向量f为空(f=φ)
循环直到到达阈值或者循环n趟
令f等于训练误差最小的fi
输出最终训练误差最小的特征向量的子集,其中评价方法使用后续的机器学习算法。
步骤4:医疗数据分析
在本发明中用于心电图分析预测的算法是bagging-c4.5,使用bagging技术对决策树c4.5进行集成,可以有效的优化c4.5的不稳定性,提高预测效果。子分类器设计—c4.5决策树,c4.5具有几个优点:对训练集敏感,适合集成学习;训练模型时不需要过多先验知识;对需分类样本处理较简单,有较好的时间优势。因此本文选择决策树子分类器进行集成实现分类预测。
子分类器设计—c4.5决策树,算法原理:设训练样本集为s,样本共有n类,记为c={c1c2,...,cn}。则样本集合s的不确定程度即信息熵(entropy)如式(10)所示。
式中,pi表示训练样本集合中属于第i类的概率。若a为数据对象属性,具有v个不同值{a1,a2,...,an},则相应可将s划分为v个子集{s1,s2,...,sv};其中sj由s中样本属性a值为aj的样本构成。设sij是子集sj中类ci的样本数。根据属性a划分的熵为:
项
式中,pij表示sj中样本属于类ci的概率。则属性a的信息增益为:
(gain(a)):gain(a)=i(s)-e(a)(13)
每次选择增益值最大的属性作分支节点即可。为了避免传统决策树(id3算法)属性多值情况所占优势,常以信息增益率(c4.5算法)作为选择分支属性的标准。
ratio(s,a)=gain(s,a)/split(s,a)(14)
式中,
训练过程按照上述分支属性选择方法,自顶向下形成决策树分类器。内部节点表示分支属性,叶节点代表类。决策树分类器形成后,从根到叶节点提取合取范式,形成分类规则
采用bagging方法对c4.5算法进行集成,其主要思想如下:
给定一数据集l={(x1,y1),..,(xm,ym)},基础学习器为h(x,l),如果输入为x,就通过h(x,l)来预测y,现在,假定有一个数据集序列{lk},每个序列都由m个与l从同样分布下得来的独立观察组成,任务是使用{lk}来得到一个更好的学习器,它比单个数据集学习器h(x,l)要强,这就要使用学习器序列{h(x,lk)}。如果y是数值的,一个明显的过程是用{h(x,lk)},在k上的平均取代h(x,l),即通过气ha(x)=elh(x,l),其中el表示l上的数学期望,ha的下标a表示综合,如果h(x,l)预测一个类j∈{1,...,j},于是综合h(x,lk)的一种方法是通过投票,设mj={k,h(x,lk)=j},使
bagging算法的伪码描述如下:
输入训练集s={(x1,y1),...,(xn,yn)},弱学习器c4.5,训练的最大轮数t,
输出:集成预测模型,
(1)s'=bootstrapsampleformd”//从a中得到的数据集d”中采用boostrap方法抽取m个训练例组成子集s';
(2)将抽样后的数据集在c4.5算法上学习ht:x→y0//在s'上训练c4.5分类器,得到第t轮的预测函数ht;
(3)若t<t,回到(1),并令t=t+1,否则转(4);
(4)将各预测函数h1,h2,…,ht集合生成最终的预测函数:
ha(x)=sign(∑hi(x))(16)
通过对c4.5分类器的集成,可以有效提高分类器的泛化能力,使预测结果更加准确。
以上所述的仅是本发明所公开的基于wrapper特征选择bagging学习处理心电图的方法的优选实施方式,应当指出,本发明提供的方法除了可以应用在心电数据上还可以应用于其他多种医疗数据,还应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!