一种语义导向的半监督视频对象分割方法与流程
本发明涉及视频对象分割领域,尤其是涉及了一种语义导向的半监督视频对象分割方法。
背景技术:
在如今的信息化社会中,视频能给我们提供丰富而全面的信息内容,因此其越来越受到现代交通、网络媒体以及计算机视觉等行业的重视。但是一般原始视频所含有的信息量都很大,其中部分甚至一大部分对于行业研究和实际应用的意义都不大。因此,我们需要对视频进行缩减,提取其中有用的信息。视频对象分割技术就是近几年发展起来的一种提取视频有效信息的重要基础性技术,它已经广泛运用于交通流视频监控、工业自动化监控、安防、网络多媒体交互以及视频压缩编码等实际生产生活中。然而,原有的方法易受到光线的变化或遮挡的影响,且无法实现半监督,因此实际应用效果并不好。
本发明提出了一种语义导向的半监督视频对象分割方法,先用卷积神经网络提取特征,再利用语义实例分割算法作为输入,估计待分割对象的语义,接着通过条件分类器将外观模型与语义先验相结合,最后训练构架,以确定特定图像的前景像素,在测试时间内用权重初始化卷积神经网络并进行微调和迭代。本发明能克服光线的变化或遮挡的影响,有效提取视频中的有用信息,大大减少了查看视频花费的大量时间、人力和物力;分割更加精细,准确度也有所提高。
技术实现要素:
针对易受到光线变化或遮挡影响的问题,本发明的目的在于提供一种语义导向的半监督视频对象分割方法,先用卷积神经网络提取特征,再利用语义实例分割算法作为输入,估计待分割对象的语义,接着通过条件分类器将外观模型与语义先验相结合,最后训练构架,以确定特定图像的前景像素,在测试时间内用权重初始化卷积神经网络并进行微调和迭代。
为解决上述问题,本发明提供一种语义导向的半监督视频对象分割方法,其主要内容包括:
(一)卷积神经网络提取特征;
(二)语义选择和语义传播;
(三)通过条件分类器将外观模型与语义先验相结合;
(四)训练网络。
其中,所述的卷积神经网络提取特征,使用vgg16卷积神经网络作为骨干网;去除完全连接层和最后的池层,增加空间特征分辨率;添加跳过连接,提取超柱状体的特征,聚合来自不同层的多尺度信息;在第二、第三、第四和第五卷积层块相应的合并层之前,从它们之中提取输出特征图;然后调整特征图,使其与输入图像大小相同,并且将它们连接形成超柱状体的特性。
其中,所述的语义选择和语义传播,利用语义实例分割算法作为输入,估计待分割对象的语义;选择多任务网络级联(mnc)作为输入实例分割算法;mnc是一个多阶段网络,由三个主要部分组成:共享卷积层、区域提议网络(rpn)和感兴趣区域(roi)-智能分类器。
进一步地,所述的语义选择,语义选择发生在视频第一帧中,根据标定的真实数据掩码选择匹配对象的掩码(处于半监督框架中,其中第一帧的真实掩码为输入);选择感兴趣区域,进行分类,将标定的真实数据与实例分段提议重叠。
进一步地,所述的语义传播,语义传播阶段发生在第一帧以后,将第一帧中估计的语义传播到之后的帧;使用第一轮前景估计对实例分割掩码进行过滤,并且选择池顶部匹配对象。
其中,所述的通过条件分类器将外观模型与语义先验相结合,使用完全卷积网络的密集标签,通常表达为每个像素的分类问题;因此,可以理解为在整个图像上滑动的全局分类器,并且根据外观模型将前景或背景标签分配给每个像素;如果将最终分类之前的语义合并,可以作为当前框架中最有可能的实例(或一组实例)的掩码。
进一步地,所述的像素,对于每个像素i,估计给定图像的前景像素的概率:p(i|i);概率可以分解为由先前加权的k个条件概率的和:
其中,k=2。
进一步地,所述的条件分类器,构建两个条件分类器,一个注重前景像素,另一个侧重于背景像素;基于实例分割输出估计先验项p(k|i);具体来说,如果像素位于实例分割掩码内,则像素依赖于前景分类器;并且如果背景分类掩码脱离实例分割掩码,则背景分类器更重要;在实验中,应用高斯滤波器将所选掩模的空间平滑作为语义先验。
进一步地,所述的条件分类器的层,条件分类器可以以端到端可训练的方式集成在网络中;该层采用两个预测图f1和f2,以及使用语义预先作为输入获得的权重图ω;其中每个输入元素与权重映射相乘,然后与另一个映射中的相应元素相加:
fout(x,y)=ω(x,y)f1(x,y)+(1-ω(x,y))f2(x,y)(2)
类似地,在反向传播步骤中,根据权重图将顶部gtop的梯度传播到两个部分:
g1(x,y)=ω(x,y)gtop(x,y)(3)
g2(x,y)=(1-ω(x,y))gtop(x,y)(4)
分别如上式所示。
其中,所述的训练网络,首先,使用预先训练的权重初始化该体系结构的vgg卷积神经网络的部分;训练架构的目的是确定特定图像的前景像素;
接着,专注于视频序列中要分割的特定对象学习外观模型,在测试时间内用权重初始化卷积神经网络并进行微调,进行几次迭代;为了在每个帧中产生分割,对视频序列的特定对象应用微调网络,获得与对象相对应的掩码,具有单个前向传递。
附图说明
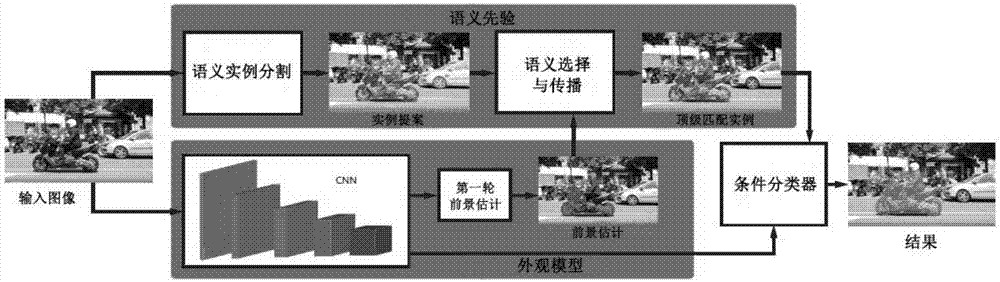
图1是本发明一种语义导向的半监督视频对象分割方法的系统流程图。
图2是本发明一种语义导向的半监督视频对象分割方法的流程示意图。
图3是本发明一种语义导向的半监督视频对象分割方法的语义选择和语义传播。
图4是本发明一种语义导向的半监督视频对象分割方法的条件分类器。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种语义导向的半监督视频对象分割方法的系统流程图。主要包括卷积神经网络提取特征,语义选择和语义传播,通过条件分类器将外观模型与语义先验相结合,训练网络。
卷积神经网络提取特征,使用vgg16卷积神经网络作为骨干网;去除完全连接层和最后的池层,增加空间特征分辨率;添加跳过连接,提取超柱状体的特征,聚合来自不同层的多尺度信息;在第二、第三、第四和第五卷积层块相应的合并层之前,从它们之中提取输出特征图;然后调整特征图,使其与输入图像大小相同,并且将它们连接形成超柱状体的特性。
通过条件分类器将外观模型与语义先验相结合,使用完全卷积网络的密集标签,通常表达为每个像素的分类问题;因此,可以理解为在整个图像上滑动的全局分类器,并且根据外观模型将前景或背景标签分配给每个像素;如果将最终分类之前的语义合并,可以作为当前框架中最有可能的实例(或一组实例)的掩码。
对于每个像素i,估计给定图像的前景像素的概率:p(i|i);概率可以分解为由先前加权的k个条件概率的和:
其中,k=2。
训练网络,首先,使用预先训练的权重初始化该体系结构的vgg卷积神经网络的部分;训练架构的目的是确定特定图像的前景像素;
接着,专注于视频序列中要分割的特定对象学习外观模型,在测试时间内用权重初始化卷积神经网络并进行微调,进行几次迭代;为了在每个帧中产生分割,对视频序列的特定对象应用微调网络,获得与对象相对应的掩码,具有单个前向传递。
图2是本发明一种语义导向的半监督视频对象分割方法的流程示意图。先用卷积神经网络提取特征,再利用语义实例分割算法作为输入,估计待分割对象的语义,接着通过条件分类器将外观模型与语义先验相结合,最后训练构架,以确定特定图像的前景像素,在测试时间内用权重初始化卷积神经网络并进行微调和迭代。
图3是本发明一种语义导向的半监督视频对象分割方法的语义选择和语义传播。利用语义实例分割算法作为输入,估计待分割对象的语义;选择多任务网络级联(mnc)作为输入实例分割算法;mnc是一个多阶段网络,由三个主要部分组成:共享卷积层、区域提议网络(rpn)和感兴趣区域(roi)-智能分类器。
语义选择发生在视频第一帧中,根据标定的真实数据掩码选择匹配对象的掩码(处于半监督框架中,其中第一帧的真实掩码为输入);选择感兴趣区域,进行分类,将标定的真实数据与实例分段提议重叠。
语义传播阶段发生在第一帧以后,将第一帧中估计的语义传播到之后的帧;使用第一轮前景估计对实例分割掩码进行过滤,并且选择池顶部匹配对象。
图4是本发明一种语义导向的半监督视频对象分割方法的条件分类器。构建两个条件分类器,一个注重前景像素,另一个侧重于背景像素;基于实例分割输出估计先验项p(k|i);具体来说,如果像素位于实例分割掩码内,则像素依赖于前景分类器;并且如果背景分类掩码脱离实例分割掩码,则背景分类器更重要;在实验中,应用高斯滤波器将所选掩模的空间平滑作为语义先验。
条件分类器可以以端到端可训练的方式集成在网络中;该层采用两个预测图f1和f2,以及使用语义预先作为输入获得的权重图ω;其中每个输入元素与权重映射相乘,然后与另一个映射中的相应元素相加:
fout(x,y)=ω(x,y)f1(x,y)+(1-ω(x,y))f2(x,y)(2)
类似地,在反向传播步骤中,根据权重图将顶部gtop的梯度传播到两个部分:
g1(x,y)=ω(x,y)gtop(x,y)(3)
g2(x,y)=(1-ω(x,y))gtop(x,y)(4)
分别如上式所示。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!