一种基于Kriging模型的多点并行全局优化方法与流程
本发明涉及基于元模型的智能优化、计算机仿真应用领域,尤其涉及的是,一种基于kriging模型的多点并行全局优化方法。
背景技术:
计算机仿真分析的最终目的是优化设计,基于kriging模型的仿真优化方法利用计算机试验设计、优化算法、kriging建模及其所给出的有效信息来实现模型的仿真优化。在优化过程中,来自于kriging模型的估值、方差等信息能够有效地指导优化搜索朝向全局的方向。因此,针对复杂并行仿真,基于计算机试验设计的kriging优化方法是一种有效的解决途径。但目前仍存在不足。
kriging是一种通过已知点来预测未知观察点的一种插值方法。kriging思想源于南非的矿业工程师krige;接着法国数学家georges对该思想进行系统化、理论化分析,提出一种插值和外推理论;进而又被运用到计算机科学,产生kriging模型;后来,试验设计与kriging实现过程的结合被称为计算机试验设计与分析(dace),广泛应用于采矿业、水文地质学、自然资源、环境科学、遥感、工程分析、机电产品设计的黑箱仿真模型中。
在少量昂贵估值下,基于kriging的优化效率不高,且难以获得更好的优化精度。复杂仿真问题易导致基于kriging的优化方法在某些情况下陷入局部最优区域。在算法无法准确判断是否陷入该区域的情况下,往往需要经过大量的昂贵估值方可跳出,这将大幅降低优化效率。在优化精度方面,以少量昂贵估值次数作为停止准则将无法判断搜索到的近似最优解是否为全局最优解,但又不得不接受这个最优解。随着优化问题复杂度的增加,由填充采样准则的多峰性所导致优化采样复杂度的增加也将影响优化精度。
基于kriging的并行优化难以实现。相对于昂贵仿真估值,优化时间的消耗几乎可以忽略,每次迭代获得q个设计点的采样准则将使总优化时间减少为原来的近1/q。而大多数优化方法在每次迭代中仅能产生一个新采样点,无法实现并行昂贵估值,也难以实现多个采样点定位到设计空间的不同吸引域内,以改善优化效率和收敛精度。
技术实现要素:
本发明所要解决的技术问题是提供一种兼顾kriging建模和多点并行采样的基于kriging模型的多点并行全局优化方法。
为实现上述目的,本发明所采用了下述的技术方案:一种基于kriging模型的多点并行全局优化方法,包括步骤如下:
s1,初始试验设计:为保证采样点在空间分布的独立性和均匀性,对于d维优化问题,初始试验设计采用对称拉丁方超立方空间填充试验设计方法在整个设计空间至少获取2*d个初始采样点和相应的仿真或函数估值;
s2,昂贵仿真估值以及初始建模:通过对初始采样点进行并行昂贵的仿真估值来减少昂贵估值带来的大量时间消耗,并利用dace方法、采样点及其估值信息建立kriging模型;
s3,构造多点采样准则:将公式1中每次迭代只能获取一个采样点的广义期望改善准则变化为公式2中多点采样的广义期望改善准则;
公式1中,初始条件
公式2中,j=1,...,p,fmin是当前最小函数值,k为新增采样点的数目,
从而以此采样准则构造多目标优化问题;
s4,构造多目标优化问题:根据多点广义期望改善采样准则,构造多目标优化问题:
通过优化所构造多目标优化问题,并采用多目标优化算法从pareto前沿上获取pareto最优解集;
s5,从pareto最优解集中筛选出最终的采样点:通过采样筛选准则
s6,停止准则:如果多点广义期望改善的最大值小于0.1%或者超出所容许的最大昂贵函数估值次数,将停止优化过程。
相对于现有技术的有益效果是,采用上述方案,本发明在一次迭代优化过程中获取多个有效的并行昂贵估值(采样)点,以便大幅减少昂贵仿真时间的消耗并提高全局寻优速度,从而解决的收敛精度与优化速度之间的均衡问题。
附图说明
图1是基于kriging模型的多点并行全局优化方法的基本流程图;
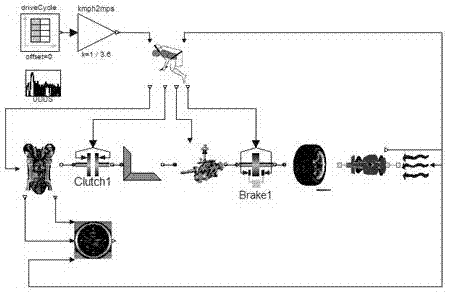
图2是方法验证的实例模型-某款重型汽车燃油经济性仿真模型;
图3是并行优化过程中燃油消耗的迭代曲线图;
图4是并行优化结果中第3、4设计变量与燃油消耗的关系曲面图;
图5是并行优化结果中每个设计变量对目标函数的权重影响,即主要因子所占比重的分析图。
具体实施方式
为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。附图中给出了本发明的较佳的实施例。但是,本发明可以以许多不同的形式来实现,并不限于本说明书所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
需要说明的是,当元件被称为“固定于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。本说明书所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
除非另有定义,本说明书所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本说明书中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是用于限制本发明。
如图1-5所示,本发明的一个实施例是,该基于kriging模型的多点并行全局优化方法包括以下步骤:
s1、初始试验设计:对于d维优化问题,初始试验设计采用对称拉丁方超立方空间填充试验设计方法在整个设计空间获取2*d个初始采样点,并对初始采样点进行相应的仿真或函数估值。
s2、kriging建模:利用计算机试验设计与分析(dace)方法、初始试验设计所获取的样本数据建立kriging模型。
s3、构造多点采样准则:将每次迭代只能获取一个采样点的广义期望改善准则
s4、建立多目标优化问题:根据所构造的多点广义期望改善采样准则,构造多目标优化问题
s5、从pareto最优解集中筛选出最终所需要的采样点:通过采样筛选准则
s6、判断是否满足算法的停止准则:如果多点广义期望改善的最大值小于0.1%或者超出所容许的最大昂贵函数估值次数,将终止整个优化过程。否则的话,将新获取的pareto最优解加入到采样点集中,并返回到步骤s2,进行下一轮的迭代循环。
本发明的计算构思为:kriging模型近似复杂仿真问题的能力强,但迭代优化过程中每次仅采样一个数据点进行昂贵仿真估值将导致较低的优化效率,考虑基于kriging模型的多点并行全局优化方法以提高全局优化效率,解决基于kriging模型的全局收敛精度与优化速度之间的均衡问题。依据算法的设计将整个算法分为两个部分:第一部分是kriging的构造或更新问题,在该阶段,利用包括新增采样点在内的所有数据点建立kriging模型;第二个部分是优化采样阶段,在每次迭代过程中,通过多点采样准则从pareto前沿获取多个采样点,并作进一步筛选。重复上述两个阶段的操作,从而在满足收敛精度的情况下大幅提高基于kriging模型的全局优化效率。本发明在优化采样阶段,采样快速非支配排序遗传算法从pareto前沿上获取多个pareto最优解集。当方差满足|φ(i)-φ(i-1)|<0.001情况下,将终止快速非支配排序遗传算法。
需要说明的是,上述各技术特征继续相互组合,形成未在上面列举的各种实施例,均视为本发明说明书记载的范围;并且,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!