一种基于非负矩阵分解的股票市场中的异常检测方法与流程
本发明属于证券市场的智能检测算法,特别涉及一种基于非负矩阵分解的股票市场中的异常检测方法。
背景技术:
异常检测旨在检测出不符合期望行为的数据,因而适合应用于故障诊断、疾病检测、入侵和欺诈检测、金融市场波动检测等多个领域。在对股票市场波动相关理论和模型的研究中,主要集中于异常波动的分析,具有时间序列的股票市场数据中的异常波动通常会导致模型参数估计偏差、较低的波动预测准确性以及得出一些无效的结论等。因此,对股票市场的时间序列数据中的异常值检测具有重要意义。
通常,根据机器学习、模式识别的理论和方法可以把检测方法归为六类:基于类别的检测,最邻近检测法,基于聚类的检测,统计检测、基于信息理论的检测、基于光谱理论的检测。近年来也发展了利用信号处理的方法来进行异常检测。特别是在高频或者超高频金融数据的建模方面,取得了一些研究成果,比如在garch类模型基础上发展的弱garch模型和异质archcharch模型等,但是还没有一个被普遍认可的模型框架。andersen和bollerslev于1998年提出了“己实现”波动的测量方法,通过“己实现”波动理论,把高频数据的金融波动转换成一个可观测的时间序列,如此就可以采用常规的标准时间序列分析方法对高频数据进行建模研究。在多变量的情况下,“己实现”波动理论还可以克服多元garch模型和多元sv模型参数估计中的“维数灾难”问题。
bilenc和huzurbazar,s.grane提出了一种基于小波的异常值检测方法,但该方法检测到的异常值的平均错误率很高。franses,doornik,ooms等提出了一种通过多次循环建立garch模型的方法检测异常值。zhang,king进一步发展了一种基于曲率的方法来检测小扰动在回归分析和garch模型中的影响,也被用来检测异常值。grane和veiga以时间序列的garch模型残差为基础,提出了检测并定位异常的方法,并对道琼斯指数的历史数据做了实证分析,能够检测出历史上股市因发生重大事件而表现出的较大波动。股票市场本身也是一个复杂系统,因此复杂系统理论亦可用以金融数据的检测。最早由ray在2004年提出的d-markov模型就是基于复杂系统隐含模式的时间序列数据快速检测方法。之后,chin,ray等进一步在异常检测领域将该模型与统计方法和神经网络方法进行对比,发现d-markov模型更优于其他两种方法。
技术实现要素:
为解决上述现有技术存在的问题,本发明的目的在于提供一种基于非负矩阵分解的股票市场中的异常检测方法,本发明在考虑直接用小波分析进行异常检测的局限性的基础上,引入了一种非负矩阵分解(nmf,nonnegativematrixfactorization)的数据处理方式。非负矩阵分解自1999年lee和seung在《nature》上提出后,在图像处理、文本信息处理、生物信息等领域有着广泛的应用。nmf的最大优点是能够在一定程度上识别数据的局部特征,定量地刻画局部与整体之间潜在的、可加的非线性组合关系。我们利用nmf对高维股指数据进行分解,得到最具股指特征的权系数向量,并对该向量构成的信号采用了小波分析的方法,得到权系数向量的多层分解波形,通过加权融合的方式,计算出超出波动阈值的异常点。
为达到上述目的,本发明的技术方案为:
一种基于非负矩阵分解的股票市场中的异常检测方法,包括如下步骤:
步骤一、建立股指数据矩阵;
以股票每日收盘时的指数特征属性,构成一个记录项为矩阵行,时间维度构成矩阵的列,以股票每天收盘时候指数作为一个记录项,构成了股指数据矩阵,所述股指数据矩阵为非负矩阵,满足:x=[xi,j]n×m;
步骤二、利用nmf对股指数据矩阵进行分解,得到代表股指特征基的基矩阵u和代表低维的权重系数的系数矩阵v,其中,u=[ui,j]n×d和v=[vi,j]d×m,使得它们满足
x≈uv(1)
其中,原矩阵x的任意一列矢量可以解释为对左矩阵u中所列矢量-基矢量的加权组合,而权重系数为右矩阵v中对应的矢量元素;如果矩阵u,v分别重写为:
u=[ui,j]n×d=[u1,u2,...ud](2)
v=[vi,j]d×m=[v1,v2,...vm](3)
进行非负矩阵分解后,矢量xj被表示为
xj≈uv,其中vj=[v1j,v2j,...vdj]t(4)
xj≈v1ju1+v2ju2+...+vdjud(5)
矢量xj可以通过矩阵u的列矢量u1,u2,…ud的线性组合来近似表示,而x与uv之间的误差定义为:
其中
步骤三、寻找最优u,v的过程就是最小化d(x||uv)值的过程,因此需要满足既能快速把x分解为u和v两个非负矩阵,又要确保d(x||uv)的值最小;这里采用一种求解非负矩阵的迭代计算机方法,通过重复迭代规则可以保证u,v收敛于局部最优,对股票时间序列xn×m进行非负矩阵分解得到基矩阵un×r和系数矩阵vr×m,其计算表达为:
其中x,u,v分别表示对应矩阵的元素,u,v可以选取任意的非负矩阵作为初始值,通过多次迭代最终收敛到稳定的v,u,将基矩阵u看作是构成股票时间序列数据的基本单元,任何一支股票指数都是由这些基本单元构成,这里定义为“股指特征基”;系数矩阵是这些特征基组合成股票时序数据的权值,vi是矩阵v的列向量,是对应股指向量xi的权系数向量,也就是说单个股指的时间序列数据是由股指特征基u与vi的乘积;由于vi的维度小于n,这一步实现了维度约减;
步骤四、对权系数向量vi实施小波变换,得到多层级的不同粒度的波形;对波形的波动幅度进行检测,从波形幅度中判断异常情况;
步骤五、在确定了序列异常位置后,进行实证分析:从对权系数向量vi进行小波变换后的序列中找出检测到的异常波动相对于序列的位置,然后在原始矩阵数据中对应的位置标记出异常事件的时间点,并考察该时间点股市指数的变换情况,从而判断检测的准确性,具体做法如下:
(1)从进行小波变换后的序列中,标记出异常点的位置;
(2)对序列进行小波变换的逆变换到股指序列向量vi',还原出股指特征向量,即股票指数时间序列向量;
(3)从带标记的股票指数时间序列向量中,定位出出现异常波动的时间点。
进一步的,所述步骤一的股指数据矩阵,以股票每日收盘时的指数特征属性,有多空指数bbi、意愿指标br、平均趋向指数dmi.adx、平均方向指数评估dmi.adxr、多方指数dmi.+di、空方指数dmi.-di)、随机指数kdj、指数平滑移动平均线macd、威廉变异离散量wvad、价格推动量power、相对强弱指数rsi、人气指标ar、乖离率bias、顺势指标cci、指数平均数expma、动量指标mtm、能量潮obv、心理线psy、停损点转向sar、容量比率vr、均价线avl、收盘价的n日简单移动平均boll.boll、布林线上缘boll.ub、布林线下缘boll.lb、cr指标cr、换手率线hsl、移动平均线ma、加权移动平均线、成本移动平均线ma5、成交量柱体及其均线mv、震荡量指标osc、变动率指标roc、宝塔线tower、威廉指数wms、容量比率vr、均价线avl、成交量柱体及其均线mv、分水岭fsl指标、市场成本指标mcst、平行线差指标dma、人气意愿指标brar、开盘价,共计42个属性值,构成一个记录项为矩阵行,时间维度构成矩阵的列,以股票每天收盘时候指数作为一个记录项,构成了股指数据矩阵。
进一步的,所述步骤四中,异常情况判断的具体方法为:设定一个正常波动幅度区间,凡是在这区间范围内变化的波形,都认为是正常波动,而超出该范围的则为异常波动。从而对于小波变换后得到各个层级的波形都会计算出异常波动点,然后采用加权方式对异常波型进行判断,如果加权后该波形的幅值仍然在设定的区间范围外,那么最终认定为异常波动,考虑小波分解各层次的粒度不同,采用加权融合的权重计算方式进行叠加,并最终计算出该点的波动幅值,加权融合的权重计算方式如下:
设x为实际值,v为观测时的随机误差,假定x估计值
因为
因此代价函数可写为:
为使得j最小,对其求导解出最优权值:
因此最优估计量为:
根据多元函数求极值理论,可求出均方误差最小时所对应的加权因子为
这里加权因子
以上方法是计算一个权重系数矢量构成的波形,由于进行小波分解的数据来源于对股指数据进行非负矩阵分解后得到的权重系数v,因此非负矩阵分解过程选择的尺度r,决定了最终产生权重系数波形的个数,选择了r=1,5,10进行了分解,并对每个权重系数波形进行单独的小波分解,并检测出相应异常波动位置,对于具有多个权重系数波形,如r=5,10,这里直接采用加权平均的方式计算波动幅度值,因此,在计算波动幅度值的过程中,有两次加权求值;
1)、对于nmf产生的权重系数矢量,进行5层小波分解后,计算出每层的异常点,然后进行加权融合,得到该权重系数矢量对应波形的异常点;
2)、当nnf的分解尺度r≠1时,需要对分解得到每个矢量波形经小波处理后的异常点的幅度值进行加权平均;
最后,经过两次加权得到幅度值,仍在设定的波动区间外,我们认定为异常。
进一步的,所述步骤四中,对权重系数矩阵v实施小波变换,得到多层级的不同粒度的波形;从波形幅度中判断异常情况的具体操作为:
(1)、把权重系数矩阵v的每一列vi当作一个序列;由于v是进行非负矩阵分解后的权系数矩阵,对原时间序列数据矩阵的压缩,相当于减少的序列的属性,因此只需要分别对序列向量vi(i=1,..r)进行小波变换,然后综合分析1到r个向量的异常情况;
(2)、选择小波函数,利用不同小波基函数来对v进行多尺度分解,通过选择不同的小波基来进一步分析异常检测的能力;
(3)、生成小波变换序列,找出序列的异常点,采用包含序列5%的最大值的点为异常点。
进一步的,所述步骤五中,异常点的判断方式如下:
1)对序列向量vi进行小波变换后的序列,分类得到低频系数a1和高频系数d1;
2)找出所有大于阈值的极大值点dmax∈|d1|,并用数组p记录dmax在d1的位置p;
3)将dmax置为0,重构d',d'=(d1,...di-1,0,di+1,dn/2)
4)将a1和d’做逆小波变换,得到新的序列;
5)对新产生的序列重复步骤1到4,直到不存在大于阈值的极大值点;
6)根据数组p中的每个p找到序列向量vi中的异常点;在去除vi中位于2p和2p-1两点后,计算样本均值
相对于现有技术,本发明的有益效果为:
股票市场的异常波动会影响整个金融市场正常运行,从而引发整个经济运行过程中的各种不稳定因素的释放。因此,通过对股票市场的数据样本进行分析,对其中的异常波动进行检测,能快速发现市场中存在的潜在风险。本文根据股指数据的时间序列特性,利用非负矩阵分解的方法,获取最具股指数据特征的权系数向量集,并对该集合进一步进行小波分解,从分解的各个层次中计算出异常的波动点,然后通过加权融合的方式最终定位出异常波动。实证分析发现,本文的方法与实际情况吻合,且由于经过非负矩阵分解,实现了数据规约,检测时间较短,同时能确保较高的精准度。
附图说明
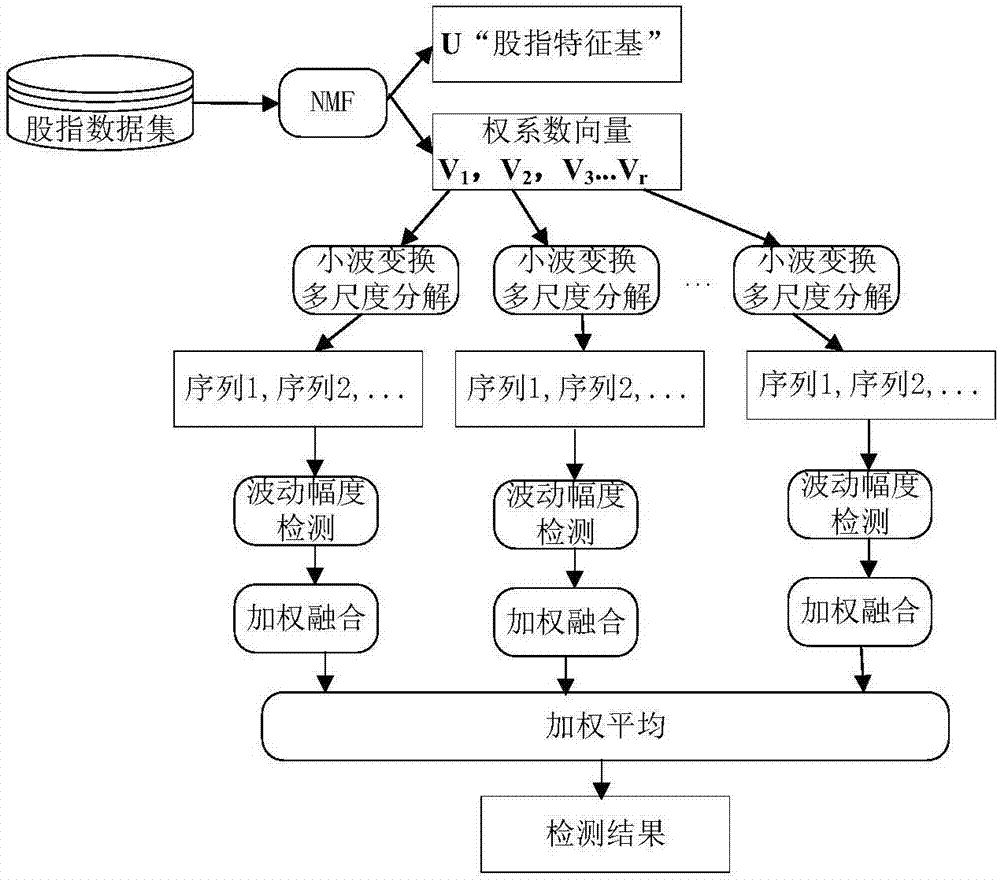
图1为基于nmf的股指波动异常检测流程图;
图2为r=1时,随机系数矩阵来初始化基矩阵u,稀疏度为51%条件数为185.2的波形图;
图3为r=5随机系数矩阵来初始化基矩阵u,稀疏度为51%,条件数为185.2的波形图;
图4为r=10随机系数矩阵来初始化基矩阵u,稀疏度为51%,条件数为185.2的波形图。
图5为对图1表示的权中系数采用haar小波进行5级分解后的波形图。
图6为加权融合方法中的加权系数分布图。
具体实施方式
下面结合附图和具体实施方式对本发明技术方案做进一步详细描述:
如图1所示,一种基于非负矩阵分解的股票市场中的异常检测方法,包括如下步骤:
矩阵分解是实现大规模数据处理与分析的一种有效工具,是一种特征提取方法,主要用于降维处理、数据压缩和局部特征提取等方面。其基本思想简单描述为:对于任意给定的一个非负矩阵x=[xi,j]n×m,nmf能够寻找到非负矩阵u=[ui,j]n×d和v=[vi,j]d×m,使得它们满足
x≈uv(1)
原矩阵x的任意一列矢量可以解释为对左矩阵u中所列矢量(称为基矢量)的加权组合,而权重系数为右矩阵v中对应的矢量元素。如果矩阵u,v分别重写为:
u=[ui,j]n×d=[u1,u2,...ud](2)
v=[vi,j]d×m=[v1,v2,...vm](3)
进行非负矩阵分解后,矢量xj被表示为
xj≈uv,其中vj=[v1j,v2j,...vdj]t(4)
xj≈v1ju1+v2ju2+...+vdjud(5)
矢量xj可以通过矩阵u的列矢量u1,u2,…ud的线性组合来近似表示,而x与uv之间的误差定义为
其中
寻找最优u,v的过程就是最小化d(x||uv)值的过程,因此我们需要找到一种方法既能快速把x分解为u和v两个非负矩阵,又要确保d(x||uv)的值最小。这里我们采用一种求解非负矩阵的迭代计算机方法。通过重复迭代规则可以保证u,v收敛于局部最优。迭代算法公式如下:
其中u,v可以选取任意的非负矩阵作为初始值,通过多次迭代最终收敛到稳定的v,u。
3.基于非负矩阵分解的股票市场异常波动检测
在对股票指数的异常检测中,我们需要建立股指数据矩阵,该矩阵以股票每日收盘时的指数特征属性,包含br、ar、kdj等共计42个属性值,构成一个记录项(矩阵行),时间维度构成矩阵的列(即以股票每天收盘时候指数作为一个记录项)。行列数据就构成了股指数据矩阵。针对股票市场数据的异常检测,我们利用nmf对股指数据矩阵进行分解,同样可以得到代表股指特征基(u)和低维的权重系数(v),然后对权重系数矩阵(v)实施小波变换,得到多层级的不同粒度的波形,从波形幅度中判断异常情况。其具体流程如下:
1对股票时间序列xn×m进行非负矩阵分解得到基矩阵un×r(股指特
征的基)和系数矩阵vr×m(权重系数)。其计算表达为:
其中x,u,v分别表示对应矩阵的元素。基矩阵u可以看作是构成股票时间序列数据的基本单元,任何一支股票指数都是由这些基本单元构成。这里可以称为“股指特征基”。系数矩阵是这些特征基组合成股票时序数据的权值。vi是矩阵v的列向量,是对应股指向量xi的权系数向量,也就是说单个股指的时间序列数据是由股指特征基u与vi的乘积。由于vi的维度小于n,这一步实现了维度约减。
2由于u是基,因此对股票异常波动的检测被转换为对系数矩阵中的异常分析。这里把vi看成r维空间的点,这点是具有时间序列性的。因此现在的问题是解决vi构成的序列中,存在哪些异常变化。这里,我们利用小波变换分别对v中的序列进行变换,从变换后的序列中找出那些“尖锐”的波形作为异常。具体步骤如下:
(1).把v的每一列vi当作一个序列。由于v是进行非负矩阵分解后的权系数矩阵,对原时间序列数据矩阵的压缩,相当于减少的序列的属性,因此我们只需要分别对序列向量vi(i=1,..r)进行小波变换,然后综合分析1到r个向量的异常情况。
(2).选择小波函数。利用不同小波基函数来对v进行多尺度分解,通过选择不同的小波基来进一步分析异常检测的能力。
(3).生成小波变换序列,找出序列的异常点。通常学者采用包含序列5%的最大值的点为异常点,判断方式如下:
1)对序列向量vi进行小波变换后的序列,分类得到低频系数a1和高频系数d1。
2)找出所有大于阈值的极大值点dmax∈|d1|,并用数组p记录dmax在d1的位置p。
3)将dmax置为0,重构d',d'=(d1,...di-1,0,di+1,dn/2)
4)将a1和d’做逆小波变换,得到新的序列。
5)对新产生的序列重复步骤1到4,直到不存在大于阈值的极大值点。
6)根据数组p中的每个p找到序列向量vi中的异常点。在去除vi中位于2p和2p-1两点后,计算样本均值
4.在确定了序列异常位置后,要进行实证分析。因此我们需要从对v(权重系数)进行小波变换后的序列中找出检测到的异常波动相对于序列的位置,然后在原始矩阵数据中对应的位置标记出异常事件的时间点,并考察那个时候股市指数的变换情况,从而判断检测的准确性。具体做法如下:
(1)从进行小波变换后的序列中,标记出异常点的位置(步骤3),具体做法参见下述的加权方式
(2)对序列进行小波变换的逆变换到股指序列向量vi',还原出股指特征向量,即股票指数时间序列向量。
(3)从带标记的股票指数时间序列向量中,定位出具体那个时间点出现异常波动。
实验例:
我们采集了从2000/01/04到2015/12/03的上证股指数据,共3851项记录,42个属性值。对应的是42条15年的时间序列股票指数。然后,进行非负矩阵分解xm×n=um×rvr×n,r为分解指数。其中u表示基矩阵,每个列向量是构建整个股指矩阵的基元;v表示系数矩阵,是基元构建股指的权重,我们用权重序列来表示整个股指序列;r同时也表示了对特征空间的压缩程度。r=n,则分解过程中没有压缩。实验分别取r=1,5,10获取的三组分解后的系数矩阵,以压缩的方式来表示原始采样数据。
由于分解采用了迭代分解的方式,即先初始化基矩阵u,然后根据式(9)(10),迭代计算u和v,并达到收敛条件。实验选取了随机系数矩阵来初始化基矩阵u。下图展示的是进行非负矩阵分解后,系数矩阵v的序列表示。横坐标表示采样点位置,对应于原始采样数据的采样时间,纵坐标表示的是分解后得到的权重系数值。图2r=1时,随机系数矩阵来初始化基矩阵u,稀疏度为51%条件数为185.2;图3r=5随机系数矩阵来初始化基矩阵u,稀疏度为51%,条件数为185.2;图4r=10随机系数矩阵来初始化基矩阵u,稀疏度为51%,条件数为185.2。
为了从权重系数v中分析出异常情况,我们进一步对这些权重系数序列进行小波变换。由于股指数据的波动比较频繁,为了更好地分析异常波动,应该适当增加小波分解阶数。但随着分解阶数的增加,尺度空间和小波空间的变化越来越小,而工作量却成倍的增加,故分解层数也不宜过多。经过实验比较,选用5级分解。然后,从分解的5级序列中找出超过波动阈值的“尖锐”波形,这里将波动阈值超过所有最大取值5%的数据下限的波形记为尖锐波形;并对尖锐波形(第3节,第2点的方法),进行加权平均。然后从这些加权平均的“尖锐”波形中,然后根据,第3节,第4点所述步骤,检测出异常波动。
图5为对图1表示的权中系数采用haar小波进行5级分解后的波形,从图5中可以直观地看出,各级波形中,存在这种“尖锐”的异常波动,定位出这些“尖锐”波形的位置,即可对应于证券市场发生异常波动的时间。我们采用的方法是设定一个正常波动区间,凡是在这区间范围内变化的波形,都认为是正常波动,而超出该范围的则为异常波动。因此,对于小波变换后得到各个层级的波形都会计算出异常波动点,然后我们采用加权方式对这些异常波型进行判断。如果加权后该波形仍然在设定的区间范围外,那么最终认定为异常波动。考虑小波分解各层次的粒度不同,我们采用了加权融合的方式进行叠加,并最终计算出该点的波动幅值。加权融合的权重计算方式如下:
设x为实际值,v为观测时的随机误差,假定x估计值
因为
因此代价函数可写为:
为使得j最小,对其求导解出最优权值:
因此最优估计量为:
根据多元函数求极值理论,可求出均方误差最小时所对应的加权因子为
这里加权因子
以上方法是计算一个权重系数矢量构成的波形。由于进行小波分解的数据来源于对股指数据进行非负矩阵分解后得到的权重系数v,因此非负矩阵分解过程选择的尺度r,决定了最终产生权重系数波形的个数。本文中,我们选择了r=1,5,10进行了分解,并对每个权重系数波形进行单独的小波分解,并检测出相应异常波动位置。对于具有多个权重系数波形(如r=5,10),这里直接采用加权平均的方式计算波动幅度值。因此,在计算波动幅度值的过程中,有两次加权求值。
1.对于nmf产生的权重系数矢量,进行5层小波分解后,计算出每层的异常点,然后进行加权融合,得到该权重系数矢量对应波形的异常点。
2当nnf的分解尺度r≠1时,需要对分解得到每个矢量波形经小波处理后的异常点的幅度值进行加权平均。
最后,经过两次加权得到幅度值,仍在设定的波动区间外,我们认定为异常。为了进一步分析权重系数与异常点的关系,我们分析了根据式(14)计算得到的加权系数。根据小波变换得到5层波形,因此对应每组数据会得到5个加权系根据式(14)计算数,由于我们的数据量较大,把数据分为50个区域,每个区域包含80个样本,因此每组数据的加权实际上是80个样本的各自按照根据式(14)计算得到的均值。从图6中可以看出,在区间25-30,40-50中的样本的权重系数变化剧烈,而这部分正是异常点集中出现的区域。因此进行小波5层级分解后进行加权的系数,实际上也是受异常波动的影响出现较大幅度的波动,而非异常情况下的加权系数趋于一致,近似于加权平均。
在整个实验中分析中,根据我们提出的异常检测方法,在2000/01/04到2015/12/03的上证股指数据,共3851项纪录中,我们一共检测到异常波动107个,相应地,我们统计分析了在所有分段区间的每个记录项,股指波动幅度超过5%的有137个,且是时间点上基本吻合。
我们采集了从2000/01/04到2015/12/03的上证股指数据,共3851项记录,42个属性值。对应的是42条15年的时间序列股票指数。然后,进行非负矩阵分解xm×n=um×rvr×n,r为分解指数。其中u表示基矩阵,每个列向量是构建整个股指矩阵的基元;v表示系数矩阵,是基元构建股指的权重,我们用权重序列来表示整个股指序列;r同时也表示了对特征空间的压缩程度。r=n,则分解过程中没有压缩。实验分别取r=1,5,10获取的三组分解后的系数矩阵,以压缩的方式来表示原始采样数据。
nmf(非负矩阵分解)的实质是:在尽可能保持信息完整的情况下,将高维的随机模式({xj,j=1,2,…,n})简化为低维的随机模式({v1,v2,…vn}),这种简化的基础是估计出数据中的本质结构u。从代数的观点看,
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何不经过创造性劳动想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书所限定的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!