用于无人驾驶的识别方法、电子设备、存储介质以及系统与流程
本发明涉及运动识别领域,尤其涉及用于无人驾驶的识别方法、电子设备、存储介质以及系统。
背景技术:
目前无人驾驶汽车成为汽车行业的新宠,对无人驾驶汽车的研究的力度也在逐年增加。对路面上的行人或物体的识别技术使无人驾驶汽车的核心技术。目前无人驾驶汽车使用的传感器为摄像头,摄像头主要承担采集路况信息给后端算法使用的重任,后端算法将摄像头采集到的rgb信息进行车辆识别、车道线识别、交通标志物识别等诸多复杂算法。在众多的识别算法中,通过摄像头采集的信息判断路上行人、车辆的运动情况是非常重要的,只有准确地判断行人是否运动,以及运动的速率,车辆是否运动,运动的速率等,才能使智能系统对无人驾驶汽车的下一步控制做出准确的判断。
但是,目前安装在无人驾驶汽车上的摄像头,由于路况颠簸、无人车本身也在运动等原因,即使停在路边并未行动的行人、停在路边尚未发动的汽车,在摄像头采集到的视频中也往往是抖动的(主要是路况颠簸,摄像头上下左右晃动造成的),或者是运动的(主要原因是相对于地面来说,无人车本身是运动的)。因此目前的无人驾驶汽车并不能准确的识别行人的运动状态。
技术实现要素:
为了克服现有技术的不足,本发明的目的之一在于提供用于无人驾驶的识别方法,其能解决目前的无人驾驶汽车并不能准确的识别行人的运动状态的问题。
本发明目的之二在于提供一种电子设备,其能解决目前的无人驾驶汽车并不能准确的识别行人的运动状态的问题。
本发明目的之三在于提供一种计算机可读存储介质,其能解决目前的无人驾驶汽车并不能准确的识别行人的运动状态的问题。
本发明的目的之四在于提供用于无人驾驶的识别系统,其能解决目前的无人驾驶汽车并不能准确的识别行人的运动状态的问题。
本发明的目的之一采用以下技术方案实现:
用于无人驾驶的识别方法,该方法包括:
获取路面上的影像数据;
将所述影像数据进行背景运动去除处理,得到待识别影像数据;
将所述待识别影像数据进行识别和定位处理,得到含有关键目标影像的已处理影像数据;
将所述已处理影像数据中的关键目标影像进行提取处理,得到关键目标影像数据;
根据所述关键目标影像数据计算关键目标的运动状态。
进一步地,所述根据关键目标影像数据计算关键目标的运动状态具体为:对所述关键目标进行跟踪,得到实时关键目标影像,对所述实时关键目标影像进行所述背景运动去除处理,得到关键目标的运动的像素值,若所述像素值与静止阈值相同,则所述关键目标为静止;若像素值与静止阈值不同,则根据预设的像素值与移动距离值的对应关系,将所述像素值换算为实际移动距离值。
进一步地,所述将所述待识别影像数据进行识别定位处理具体为:建立第一深度学习模型,通过所述第一深度学习模型对所述待识别影像数据进行识别和定位,得到含有关键目标影像的已处理影像数据。
进一步地,所述建立第一深度学习模型具体为:将imagenet数据库作为训练数据库,将所述imagenet数据库中的图片的rgb信息进行多次卷积操作和进行融合后卷积,得到对应的第一深度学习模型。
进一步地,所述将所述已处理影像数据中的关键目标影像进行提取处理具体为:建立第二深度学习模型,将imagenet数据库作为训练数据库对所述第二深度学习模型进行训练,得到第三深度学习模型,根据所述第三深度学习模型对所述已处理影像数据中的关键目标影像的特征记性深度学习匹配,并对匹配过的所述特征进行非监督聚类,得到关键目标影像的物体边缘,从而得到关键目标影像数据。
本发明的目的之二采用以下技术方案实现:
一种电子设备,该设备包括:处理器;
存储器;以及程序,其中所述程序被存储在所述存储器中,并且被配置成由处理器执行,所述程序包括用于执行本发明中的用于无人驾驶的识别方法。
本发明的目的之三采用以下技术方案实现:
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行本发明中的用于无人驾驶的识别方法。
本发明的目的之四采用以下技术方案实现:
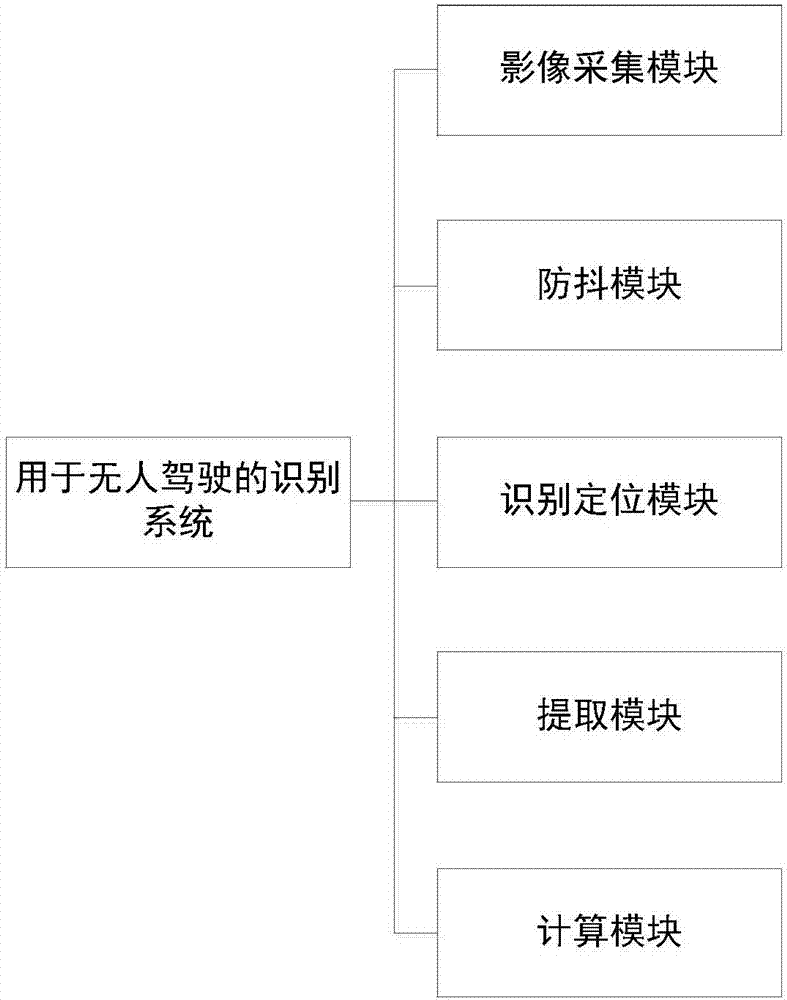
用于无人驾驶的识别系统,该系统包括:防抖模块、识别定位模块、提取模块以及计算模块;
所述防抖模块用于获取路面上的影像数据;所述防抖模块还用于将所述影像数据进行背景运动去除处理得到待识别影像数据;
所述识别定位模块用户将所述待识别影像数据进行识别和定位处理,得到含有关键目标影像的已处理影像数据;
所述提取模块用于将所述已处理影像数据中的关键目标影像进行提取处理,得到关键目标影像数据;所述计算模块根据所述关键目标影像数据计算关键目标的运动状态。
进一步地,还包括影像采集模块,所述影像采集模块用于采集路面上的影像数据,所述防抖模块获取所述影像采集模块采集的上路面影像数据。
进一步地,所述影像采集模块为摄像头。
相比现有技术,本发明的有益效果在于:本申请中的用于无人驾驶的识别方法,通过采集路面上的影像数据,并对影像数据进行背景运动去除处理,以及进行识别定位处理,得到含有关键目标影像的已处理影像数据,并对已处理影像数据中的关键目标影像进行提取处理,得到关键目标影像数据,并根据关键目标影像数据计算关键目标的运动状态。
附图说明
图1为本发明的用于无人驾驶的识别方法的流程图;
图2为本发明的用于无人驾驶的识别系统的模块框图;
图3为本发明的用于无人驾驶的识别方法的每秒钟背景动态移动图;
图4为本发明的用于无人驾驶的识别方法的关键目标影像中的原图片;
图5为本发明的用于无人驾驶的识别方法的关键目标影像中的原图片经过第三深度学习模型进行学习匹配得到的兴趣区域的图片;
图6为本发明的用于无人驾驶的识别方法的对图中的兴趣区域的图片进行卷积核卷积处理得到的图片。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例:
如图1所示,本申请的用于无人驾驶的识别方法,该方法包括以下步骤:
步骤s10:获取路面上的影像数据,无人驾驶汽车中的影像采集设备(摄像头)对无人驾驶汽车前方以及周围的路面上的影像数据进行采集,防抖模块对摄像头采集的路面上的影像数据进行获取。影像数据包括行人影像数据和车辆影像数据以及其他障碍物影像数据。
步骤s20:将影像数据进行背景运动去除处理,得到待识别影像数据,将影像数据中的视频每连续的两帧组成帧对,并对每个帧对进行像素差比较,从而背景运动的变化速度形成了一个背景运动函数,根据背景运动函数上的背景运动移动值,根据背景运动移动换算出影像数据的位置实际值,即去除了背景运动所带来的影响,得到了含有相对地面静止的影响特征的影像数据,得到待识别影像数据。
上述将影像数据中的视频每连续的两帧组成帧对,并对每个帧对进行像素差比较,从而背景运动的变化速度形成了一个背景运动函数的这一过程可为:将每连续的两帧组成帧对,假设每幅图像的像素坐标为x,y在两幅图上上取m*n的像素块,并将两幅图中像素块的坐标进行去差值,并对去差值去平均值,得到坐标差的平均值,即为背景运动的幅度。以下通过具体举例进行说明:以第一幅图片与第二幅图片为例,此时m为10,n为10;则在第一幅图的像的(1/16*x,1/16*y),(1/16*x,15/16*y),(15/16*x,1/16*y),(15/16*x,15/16*y),(1/8x,1/8y),(7/8x,1/8y),(1/8x,7/8y),(7/8*x,7/8*y)上取10*10的像素块,在第二幅图中采用10*10的滑窗寻找与第一幅图像相同的像素块,因为取的8个像素块都集中在图像边缘,将两幅图像想用像素块的坐标进行去差值,并对差值去平均值,得到坐标差的平均值s,此s即为该帧对中背景运动的幅度,根据背景运动幅度即为背景运动中的像素差,本申请中以无人驾驶汽车摄像头每秒采集24帧的影像,两两连续形成23个帧对,通过对帧对继续逆行像素差比较,形成一个由23个值的折线,该折线表示一秒钟时间段内背景运动函数,如图3所示为每秒钟背景动态移动图即背景运动函数图,图像中模拟的是由于道路颠簸造成的无人驾驶汽车的摄像头中背景的抖动,在系统中建立该函数模型后,可以通过反向减去相应像素值抵消背景的运动。针对于道路颠簸造成的抖动来说,该函数在图像上更曲折,针对无人车运动造成的背景移动来说,图像上更平缓但单位时间内的像素位移更大。
步骤s30:将待识别影像数据进行识别和定位处理,得到含有关键目标影像的已处理影像数据;具体为:建立第一深度学习模型,通过所述深度学习模型对待识别影像数据进行识别和定位,得到含有关键目标影像的已处理影像数据。
上述建立第一深度学习模型为将imagenet数据库作为训练数据库,将所述imagenet数据库中的图片的rgb信息进行多次卷积操作和进行融合后卷积,得到对应的第一深度学习模型。第一深度学习模型用来对待识别影像数据中的对应的图像进行识别以及分类出关键目标影像的重要特征,并将关键目标影像进行定位。第一深度学习模型包括机动车深度学习模型、行人深度学习模型、婴儿车深度学习模型、行李箱深度学习模型、非机动车深度学习模型以及动物深度学习模型。
步骤s40:将所述已处理影像数据中的关键目标影像进行提取处理,得到关键目标影像数据;具体为:建立第二深度学习模型,此处建立第二深度学习模型与步骤s30中建立方法相同,深度学习模型的第一和第二只是为了区分步骤的顺序,第一深度学习模型与第二深度学习模型实质相同;将imagenet数据库作为训练数据库对所述第二深度学习模型进行训练,使用imagenet数据库中的车与预存的行人数据库中的30%图片进行手动标注精细边缘,并以标注过精细边缘的关键目标主体进行切割,并以此为深度学习模型的输入数据进行训练;经过训练的深度学习模型即为得到的第三深度学习模型,根据所述第三深度学习模型对所述已处理影像数据中的关键目标影像的特征记性深度学习匹配,并对匹配过的所述特征进行非监督聚类,得到关键目标影像的物体边缘,从而得到关键目标影像数据。以关键目标影像中的一图片为例,如图4-6所示,图4为关键目标影像中的原图片,图5为经过第三深度学习模型进行学习匹配得到的兴趣区域的图片,再对其兴趣区域进行卷积核卷积得到如图6所示的图片,将经过卷积核卷积的图片进行非监督聚类,得到目标图片的边缘,即相当于得到关键目标图片。
步骤s50:根据关键目标影像数据计算关键目标的运动状态。对所述关键目标进行跟踪,得到实时关键目标影像,对实时关键目标影像进行背景运动去除处理,得到关键目标的运动的像素值,若所述像素值与静止阈值相同,则关键目标为静止;若像素值与静止阈值不同,则根据预设的像素值与移动距离值的对应关系,将像素值换算为实际移动距离值;上述的静止阈值理论值为0,但是由于现实中车辆以及影像设备的抖动不可能做到将外在因素完全排除,因此此处的静止阈值可在一定的误差范围内,当像素值在此误差范围内时,即认定像素值与静止阈值相同,反之,则不同。
本申请中的一种电子设备,其特征在于包括:处理器;
存储器;以及程序,其中所述程序被存储在所述存储器中,并且被配置成由处理器执行,所述程序包括用于执行本申请中的用于无人驾驶的识别方法。
本申请的一种计算机可读存储介质,其上存储有计算机程序,其特征在于:所述计算机程序被处理器执行本申请中的用于无人驾驶的识别方法。
本申请中的用于无人驾驶的识别系统,其特征在于包括:影像采集模块、防抖模块、识别定位模块、提取模块以及计算模块;
影像采集模块用于采集路面上的影像数据;影像采集模块为摄像头;防抖模块获取影像采集模块采集的上路面影像数据;防抖模块还用于将影像数据进行背景运动去除处理得到待识别影像数据;
识别定位模块用户将待识别影像数据进行识别和定位处理,得到含有关键目标影像的已处理影像数据;
提取模块用于将已处理影像数据中的关键目标影像进行提取处理,得到关键目标影像数据;计算模块根据关键目标影像数据计算关键目标的运动状态。
本申请中的用于无人驾驶的识别方法,通过采集路面上的影像数据,并对影像数据进行背景运动去除处理,以及进行识别定位处理,得到含有关键目标影像的已处理影像数据,并对已处理影像数据中的关键目标影像进行提取处理,得到关键目标影像数据,并根据关键目标影像数据计算关键目标的运动状态。
对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!