基于时序文本网络的社区检测与用户关系预测方法与流程
本发明涉及到时序文本网络探社区检测领域,具体地,涉及一种基于时序文本网络的社区检测与用户关系预测方法。
背景技术:
网络是一个强大的语言,它能够阐释社会、自然以及学术领域中的数据关系。一个理解网络的方法是定义和分析一组有着相同属性的节点。这样的一组节点可以被解释为社交网络中的组织单位,或者引用网络中的相同领域。探测社区问题就是在网络中寻找这样的一组节点的研究任务。传统的方法大都基于一个节点只属于一个社区这个假设,集中寻找离散社区。那么在除去这个假设的情况下,交叉社区检测问题变得越来越普遍并在最近引起了越来越多的关注。
尽管在过去网络中的交叉多等级社区问题已经被讨论过,但在一个大的网络中定义一个有意义的社区网络依旧是个艰难的任务。大多数方法很难应用于大型网络,并且在缺少有信服力的标准情况下,对检测出的社区进行评估极其困难。因此,尽管网络问题已经被广泛的研究,小型网络中的社区的存在和特性已经被熟知,在特大型网络中定义交叉社区的方法依旧不甚清晰。
探测重叠社区一般有两种形式的信息可以利用。第一种是链型结构,例如边的有无。经典方法大都集中于这种形式的信息,并致力于获取一组节点,这些节点之间的连接相比于外部网络而言更为紧密。第二种是节点属性,包括在线的用户档案,预先存在的蛋白质功能和论文的文本内容。由于链接结构中普遍存在的噪音,同时基于这两种方法检测社区信息的方法已经越来越受欢迎。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于时序文本网络的社区检测与用户关系预测方法,研究在时序文本网络中探测交叉社区的问题,在时序文本网络识别有意义的社区为后续应用开发提供了有用的知识。
为实现上述目的,本发明是根据以下技术方案实现的:
一种基于时序文本网络的社区检测与用户关系预测方法,包括如下步骤:
步骤s1:基于原始数据构建时序文本网络;
步骤s2:针对时序文本网络,构建基于关系图模型的生成模型;
步骤s3:利用梯度下降法构建生成模型的推断过程;
步骤s4:根据模型的推断过程,对时序文本网络进行训练,提取出社区信息以及社区间的关系,其中社区指表现出较高相关性的点的集合,社区间的关系指的是社区之间的相似度;
步骤s5:根据提取出的社区信息,进行网络节点间的连接预测。
上述技术方案中,所述步骤s1包括:
步骤s101:将顶点集v设为空集,将边集e设为空集;
步骤s102:将原始数据集中的每一篇文章加到顶点集v中;
步骤s103:顶点集v中的每一篇文章对应一个标签t,该标签是指每一篇文章的发表时间;
步骤s104:将原始数据集中文章间的链接关系加到边集e中;
步骤s105:(v,e;t)的集合构成图g,图g为时序文本网络。
上述技术方案中,所述步骤s2包括:
步骤s201:定义节点u与节点v之间通过社区i、j产生连接的概率:
p(u,v,i,j)=(1-exp(-fuiηijfvj))δ(u→v),
其中fui表示节点u与社区i的连接强度;fvj表示节点v与社区j的连接强度;ηij表示社区i与社区j的连接强度;t(u)表示节点u的时间戳;t(v)表示节点v的时间戳;
步骤s202:定义节点u与节点v之间通过任意两个社区产生连接的概率为:
其中fui表示节点u与社区i的连接强度;fvj表示节点v与社区j的连接强度;ηij表示社区i与社区j的连接强度;
步骤s203:针对时序文本网络,根据步骤s202定义的公式,生成时序文本网络gp:
gp=(v∪vω,e∪eωd;t∪tω)
其中,v、e、t分别是时序文本网络中的节点集合、边集合以及时间戳集合;vω代表一个单词;存在于eωd的边(ωi,dj)代表单词i存在于文章j中;tω代表单词的时间戳,被设置成0;对于该网络中任意两点,根据s202所定义的概率,预测两点间是否有边存在。
上述技术方案中,所述步骤s3包括:
步骤s301:利用块坐标梯度下降法,对于对每个节点u,假设对
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合,如图3所示,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量,η表示社区间的相似度的矩阵,
步骤s302:利用梯度下降法,根据如下公式可以进行对f的更新:
其中
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量,η表示社区间的相似度的矩阵;
步骤s303:f更新完成后,假设f不变,根据如下公式可以进行对η的更新:
其中αη为利用回溯搜索算法计算所得步长;
其中e表示时序文本网络中所有边的集合;fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量;η表示社区间的相似度的矩阵;
步骤s304:计算
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合;n(u)表示inn(u)和outn(u)的并集,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量;η表示社区间的相似度的矩阵;
计算
上述技术方案中,所述步骤s4包括:
步骤s401:从数据文件中读取数据,并根据步骤s1构建时序文本网络;
步骤s402:初始化用户与社区间的联系强度矩阵f;基于向网络中的导率模型,如果节点u的入邻居inn(u)有比所有点v∈outn(u)的入邻居inn(v)有更小的导率,则该入邻居inn(u)在邻近是最小的;对于属于一个在邻近最小的邻域k内的节点u',初始化节点u'与一个社区k之间的联系强度fu'k=1,否则令fu'k=0;为了初始化η,设置主对角线上的项为0.9,其他项为0.1;
步骤s403:每轮次根据公式更新f与η,首先针对每个节点u,根据梯度公式更新节点u与所有社区之间的联系强度向量fu,梯度公式如下:
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量,η表示社区间的相似度的矩阵;
f更新完成后,根据梯度公式更新社区间的联系矩阵η,梯度公式如下:
其中e表示时序文本网络中所有边的集合;fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量;η表示社区间的相似度的矩阵;
步骤s404:经过一定轮次后,判定每个节点与社区间的隶属关系,针对每个社区k,设定一个阈值δk,具体设定方法如下:
其中n为节点总数;ηkk为社区间联系矩阵η第k行第k列的分量,对于节点u与社区k,若联系强度fuk大于社区k的阈值δk,则认为节点u隶属于社区k。
上述技术方案中,所述步骤s5包括:
步骤s501:对选定的文本数据集进行训练,提取出节点与社区间联系强度矩阵f,以及社区间的联系关系矩阵η;
步骤s502:读取矩阵f与矩阵η;
步骤s503:根据步骤s2所定义的公式计算节点u与节点v之间边的存在概率。
本发明与现有技术相比,具有如下有益效果:
本发明基于时序文本网络中的网络结构信息和文本信息,同时提取出了节点与社区间的隶属关系和社区间的联系关系,弥补了现有技术在分析节点连接原因上的不足;本发明构建了全新的社区检测模型,考虑了社区间的联系关系,同时提供了一种新的文本信息在社区检测中的应用方法,提高了社区检测的效率和准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1为本发明的预测方法流程图;
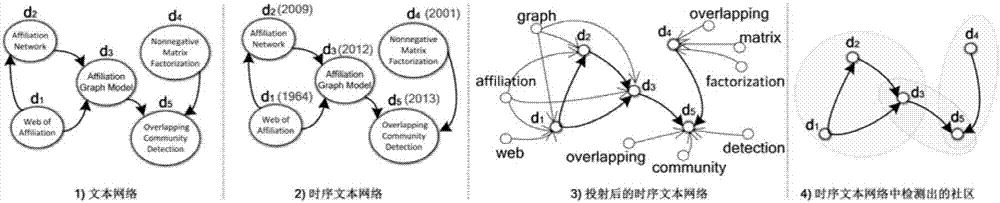
图2为本发明构造的适用的时序文本网络的示意图;
图3为本发明的出、入邻居示意图;
图4为本发明构造的词聚类的词云示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
根据本发明提供的基于时序文本网络的社区检测与用户关系预测方法,涉及整理含时序文本网络的自动化程序、基于生成模型的新型社区检测方法、新型方法的推断过程和参数估计、社区成员及社区间关系提取、节点间连接预测;具体地,如图1所示,包括如下步骤:
步骤s1:基于原始数据构建时序文本网络;
步骤s2:针对时序文本网络,构建基于关系图模型的生成模型;
步骤s3:利用梯度下降法构建生成模型的推断过程;
步骤s4:根据模型的推断过程,对时序文本网络进行训练,提取出社区信息以及社区间的关系,社区指的是表现出较高相关性的点的集合,社区间的关系指的是社区之间的相似度;
步骤s5:根据提取出的社区信息,进行网络节点间的连接预测并绘制词云。
如图2所示,所述步骤s1包括:从互联网上获得公开的时序文本数据集,从数据集中抽取出时序文本网络,例如在论文网络中以论文的发表时间作为时序信息、以论文的标题和摘要作为文本信息,在社交网络中以用户推送的短文内容作为文本信息、推送时间座位时序信息,在超链接的网页网络中以网页标题和主要文字作为文本信息、网页更新时间作为时序信息;从数据集中抽取出链接信息,例如在论文网络中以论文的参考文献作为链接信息,在社交网络中以转发行为作为链接信息,在超链接的网页中以网页的链接作为链接信息;将提取出的信息生成csv格式的文件,具体地:
步骤s101:将顶点集v设为空集,将边集e设为空集,将图g设为v,e的集合;
步骤s102:将原始数据集中的每一篇文章加到顶点集v中;
步骤s103:顶点集v中的每一篇文章对应一个标签t,该标签是指每一篇文章的发表时间;
步骤s104:将原始数据集中文章间的链接关系加到边集e中。
步骤s105:(v,e;t)的集合构成图g,即为时序文本网络
所述步骤s2包括:对时序文本网络结构中的文本和链接的生成过程进行建模,生成模型是指在已知参数的条件下,假设文章生成过程服从的模型;具体地:
步骤s201:定义节点u与节点v之间通过社区i、j产生连接的概率:
p(u,v,i,j)=(1-exp(-fuiηijfvj))δ(u→v),
其中fui表示节点u与社区i的连接强度;fvj表示节点v与社区j的连接强度;ηij表示社区i与社区j的连接强度;t(u)表示节点u的时间戳;t(v)表示节点v的时间戳;
步骤s202:定义节点u与节点v之间通过任意两个社区产生连接的概率:
其中fui表示节点u与社区i的连接强度;fvj表示节点v与社区j的连接强度;ηij表示社区i与社区j的连接强度;
步骤s203:针对时序文本网络g,根据步骤s202定义的公式,生成时序文本网络gp:
gp=(v∪vω,e∪eωd;t∪tω)
其中,v,e,t分别是时序文本网络中的节点集合,边集合以及时间戳集合。vω代表一个单词;存在于eωd的边(ωi,dj)代表单词i存在于文章j中;tω代表单词的时间戳,被设置成0;对于该网络中任意两点,根据s202所定义的概率,预测两点间是否有边存在。
所述步骤s3包括:构建生成模型的推断过程,估计生成模型中的参数,通过已知的文本信息、链接信息和时序信息去推断隐含的参数;本发明采用梯度下降法进行推断,具体地:
步骤s301:利用块坐标梯度下降法,对于对每个节点u,假设对
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量,η表示社区间的相似度的矩阵;
步骤s302:利用梯度下降法,根据如下公式可以进行对f的更新:
其中
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量,η表示社区间的相似度的矩阵;
步骤s303:f更新完成后,假设f不变,根据如下公式可以进行对η的更新:
其中αη为利用回溯搜索算法计算所得步长;
其中e表示时序文本网络中所有边的集合;fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量;η表示社区间的相似度的矩阵;
步骤s304:计算
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合;n(u)表示inn(u)和outn(u)的并集,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量;η表示社区间的相似度的矩阵;
这样,计算
所述步骤s4包括:训练时序文本网络,并根据得到的参数来计算节点与社区间的隶属关系以及社区间的联系关系,计算得到的关系强度用于步骤s5中的节点连接预测,具体地:
步骤s401:从数据文件中读取数据,并根据步骤1构建时序文本网络;
步骤s402:初始化用户与社区间的联系强度矩阵f。基于有向网络中的导率模型,如果节点u的入邻居inn(u)有比所有点v∈outn(u)的入邻居inn(v)有更小的导率,则该入邻居inn(u)在邻近是最小的。对于属于这样一个在邻近最小的邻域k内的节点u',初始化节点u'与一个社区k之间的联系强度fu'k=1,否则令fu'k=0。为了初始化η,设置主对角线上的项为0.9,其他项为0.1;
步骤s403:每轮次根据公式更新f与η,首先针对每个节点u,根据梯度公式更新节点u与所有社区之间的联系强度向量fu,梯度公式如下:
其中inn(u)和outn(u)表示进入u节点和从u节点发出的节点的集合,fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量,η表示社区间的相似度的矩阵。
f更新完成后,根据梯度公式更新社区间的联系矩阵η,梯度公式如下:
其中e表示时序文本网络中所有边的集合;fu、fv和fv′分别表示u节点、v节点和v’节点与所有社区的连接强度的向量;η表示社区间的相似度的矩阵;
步骤s4.4:经过一定轮次后,判定每个节点与社区间的隶属关系。针对每个社区k,设定一个阈值δk,具体设定方法如下:
其中n为节点总数;ηkk为社区间联系矩阵η第k行第k列的分量。对于节点u与社区k,若联系强度fuk大于社区k的阈值δk,则认为节点u隶属于社区k。
所述步骤s5包括:根据前述步骤提取出的节点与社区间的隶属关系以及社区间的联系关系进行节点连接预测并绘制词云,如图4所示,具体地:
步骤s501:对选定的文本数据集进行训练,提取出节点与社区间联系强度矩阵f,以及社区间的联系关系矩阵η;
步骤s502:读取矩阵f与矩阵η;
步骤s503:根据步骤s2所定义的公式计算节点u与节点v之间边的存在概率。具体公式如下:
其中fui表示节点u与社区i的连接强度;fvj表示节点v与社区j的连接强度;ηij表示社区i与社区j的连接强度;
步骤s504:对任意一个社区k,找出隶属于这个社区的所有词以及每个词w与这个社区间的联系强度fwk,之后将每个词与该社区的联系强度作为这个词的权重,导入词云生成器中,即可绘制词云。
首先,本发明收集32个标准的时序文本网络社区,能深入洞察社会结构并且得到了定量评估社区检测方法。其次,本发明研究了时序文本网络中这些标准社区之间的关系,并发现大部分节点的连接基于社区之间的交互,也分析节点属性是如何有助于提高检测社区的质量并发现在同一个社区的节点有相似的文本内容。第三,基于实证观察,本发明提出了一个可以利用时序文本网络中所有的信息来源并可以囊括数以百万计的网络节点的概率生成模型。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!