基于超像素边缘和全卷积网络的图像语义分割方法与流程
本发明属于图像处理技术领域,涉及一种图像语义分割方法,具体涉及一种基于超像素边缘和全卷积网络的图像语义分割方法,可用于图像分类、目标识别、目标跟踪等要求检测目标的场合。
背景技术:
在数字图像处理领域,与分割相关的应用有目标分割、前景分割、图像分割以及图像语义分割,其中目标分割旨在将图像中的主要目标分割出来;前景分割指的是将视频或图像序列中感兴趣区域分割出来;图像分割是将图像划分为若干个互不交迭的且属性不同的区域,在图像分割中,像素被划分到任一区域的可能性是相同的,像素最后被划分到哪一区域只取决于像素的灰度、颜色、纹理等特征。而图像语义分割是指将图像分割为若干个互不重叠的、具有一定视觉意义的区域,同时对这些区域进行语义标注。本质上,语义分割实现的是像素级的分类,通过对每个像素点进行分类,实现整幅图像的语义标注。从应用的角度来讲,图像语义分割是指将图像中不同的目标进行分割,同时对不同目标做不同的标记。
早期图像语义分割方法主要采用条件随机场模型(conditionrandomfields,crf),crf模型的缺点是不能定位到单个目标,难以利用图像的全局形状特征,容易造成误识,导致分割准确率降低。2010年,深度卷积神经网络alexnet提出后,基于分类网络的图像语义分割算法诞生,如girshick等提出的r-cnn模型和hariharan等提出的sds模型,这类算法的缺点是分割准确率会不可避免地受到自底向上的区域生成算法性能的限制。2015年,long等人提出的fcn模型,对网络最后一个卷积层的输出进行上采样,上采样的结果恢复到与输入图像相同的尺寸,从而对每个像素产生了一个预测,然后进行逐像素分类实现图像的语义分割,在pascalvoc2012挑战赛中达到了62.7%的分割准确率。尽管fcn模型能够实现像素级的分类,但是该模型由于只用到了深度神经网络抽象出的高级图像特征,对图像低级边缘信息的运用较少,导致它对细小边缘的分割定位准确度有所欠缺,如果能够在使用高级图像特征的同时,还能保留图像内的边缘信息,则图像分割准确率将会有所提升。
在图像平面内,超像素是一系列位置相邻且亮度、颜色、纹理等特征相似的像素点组成的连续的、互不重叠的区域,这些区域的像素点通常属于同一物体或平面。超像素具有良好的局部特征表达能力,能够提取图像的中层特征,并方便地表达图像的边缘信息。
技术实现要素:
本发明的目的在于针对上述现有技术存在的缺陷,提出了一种基于超像素边缘和全卷积网络的图像语义分割方法,用于解决现有图像语义分割方法中存在的准确度低的技术问题。
本发明的技术思路是:构建训练、测试和验证样本集,训练、测试并验证输出像素级语义标记的全卷积网络,利用已验证的输出像素级语义标记的全卷积网络对待分割图像进行语义分割,获得像素级语义标记,并对待分割图像进行bslic超像素分割,利用像素级语义标记对bslic超像素进行语义标注,得到融合了超像素边缘和全卷积网络输出的高级语义信息的语义分割结果,具体步骤包括:
(1)构建训练样本集、验证样本集和测试样本集:
(1a)获取图像样本集:获取包含原始彩色图像以及与原始彩色图像对应的真实语义分割数据的图像样本集;
(1b)从图像样本集中选择多数样本作为训练样本集,其余样本的部分作为验证样本集,另一部分作为测试样本集;
(2)搭建输出像素级语义标记的全卷积网络:
(2a)获取待搭建全卷积网络的基础网络和初始值:将vgg-16网络作为待搭建全卷积网络的基础网络,同时将matconvnet工具箱中的vgg-16网络预训练权值作为待搭建全卷积网络的初始值;
(2b)搭建全卷积网络:将待搭建全卷积网络中的全连接层fc-4096转换为4096个卷积核大小为1×1、卷积步长为1个像素的卷积层,全连接层fc-1000转换为1000个卷积核大小为1×1、卷积步长为1个像素的卷积层,得到全卷积网络;
(2c)获取输出像素级语义标记的全卷积网络:
(2c1)获取fcn-32s模型下的输出像素级语义标记的全卷积网络:将全卷积网络的第5个池化层输出的特征映射进行32倍上采样,得到fcn-32s模型下的输出像素级语义标记的全卷积网络;
(2c2)获取fcn-16s模型下的输出像素级语义标记的全卷积网络:将全卷积网络的第5个池化层输出的特征映射进行2倍上采样,并将上采样结果与第4个池化层输出的特征映射进行融合,再将融合结果进行16倍上采样,得到fcn-16s模型下的输出像素级语义标记的全卷积网络;
(2c3)获取fcn-8s模型下的输出像素级语义标记的全卷积网络:分别将全卷积网络的第4、5个池化层输出的特征映射进行2倍、4倍上采样,并将上采样结果与第3个池化层输出的特征映射融合,再将融合结果进行8倍上采样,得到fcn-8s模型下的输出像素级语义标记的全卷积网络;
(3)对输出像素级语义标记的全卷积网络进行训练、测试和验证,得到验证后的输出像素级语义标记的全卷积网络:
(3a)设定语义分割正确率阈值;
(3b)对输出像素级语义标记的全卷积网络进行训练:利用训练样本集对输出像素级语义标记的全卷积网络进行若干次迭代监督训练,得到训练后的输出像素级语义标记的全卷积网络;
(3c)对输出像素级语义标记的全卷积网络进行测试:将测试样本集中的所有原始彩色图像输入到训练后的输出像素级语义标记的全卷积网络中,得到fcn-32s、fcn-16s和fcn-8s三种模型下的像素级语义标记,并将其与测试样本集中的真实语义分割数据进行比对,得到语义分割正确率,若语义分割正确率大于设定的语义分割正确率阈值,得到测试后的输出像素级语义标记的全卷积网络,并执行步骤(3d),否则执行步骤(3b);
(3d)对输出像素级语义标记的全卷积网络进行验证:将验证样本集中的所有原始彩色图像输入到测试后的输出像素级语义标记的全卷积网络中,得到fcn-32s、fcn-16s和fcn-8s三种模型下的像素级语义标记,并将其与验证样本集中的真实语义分割数据进行比对,得到语义分割正确率,若语义分割正确率大于设定的语义分割正确率阈值,得到验证后的输出像素级语义标记的全卷积网络,并执行步骤(4),否则执行步骤(3b);
(4)将待分割彩色图像i输入到验证后的输出像素级语义标记的全卷积网络中,得到待分割彩色图像i的像素级语义标记;
(5)对待分割彩色图像i进行bslic超像素分割:
(5a)对待分割彩色图像i进行颜色空间转换,得到lab颜色空间的转换彩色图像ilab;
(5b)按照六边形分布,在转换彩色图像ilab上进行初始化,得到平面聚类中心pa,其中,a表示平面聚类中心编号,且a=1,2,...,np,np为平面聚类中心总数;
(5c)在平面聚类中心pa的范围内搜索边界点,并从搜索到的所有边界点里随机选取一个中值点作为边界聚类中心eb,其中,b表示边界聚类中心编号,且b=1,2,...,ne,ne为边界聚类中心总数;
(5d)将所有平面聚类中心和边界聚类中心更新为各自3×3邻域内的梯度最小点,得到更新后的平面聚类中心pa′和边界聚类中心eb′,然后将更新后的平面聚类中心pa′和边界聚类中心eb′作为初始值,利用局部k-means算法对转换彩色图像ilab的像素点进行分类标记;
(5e)判断平面聚类中心pa与更新后的平面聚类中心pa′之间的相对误差值是否小于5%,若是,则将转换彩色图像ilab的像素点的分类标记作为待分割彩色图像i的最终分类标记,并执行步骤(5f),否则执行步骤(5d);
(5f)将待分割彩色图像i里所有具有相同分类标记的像素点分别标记为一个超像素,得到多个bslic超像素;
(6)利用步骤(4)得到的像素级语义标记对步骤(5f)得到的多个bslic超像素分别进行语义标注,得到融合了超像素边缘和全卷积网络输出的高级语义信息的语义分割数据,标注规则为:
(i)若超像素中没有边缘,且超像素中所有像素点的语义标记相同,采用步骤(4)得到的语义标记对超像素进行语义标注;
(ii)若超像素中没有边缘,但超像素中像素点的语义标记不同,采用占比最多的语义标记对超像素进行语义标注;
(iii)若超像素中有边缘,且超像素中所有像素点的语义标记相同,则忽略边缘信息,采用步骤(4)得到的语义标记对超像素进行语义标注;
(iv)若超像素中有边缘,同时超像素中像素点的语义标记不同,采用由不同语义标记的占比确定的语义标记对超像素进行语义标注。
本发明与现有的技术相比,具有以下优点:
1.本发明在获得像素级语义标记的过程中,考虑到图像的超像素对图像的局部边缘有非常好的贴合度,将图像的超像素边缘信息与全卷积网络输出的像素级语义标记进行融合。结果表明,本发明在继承了现有基于全卷积网络的图像语义分割技术优异的特征抽象能力的同时,提升了对图像边缘的分割准确度,进而提升了整体图像分割准确率。
2.本发明在搭建全卷积网络时将vgg-16网络的全连接层转换为卷积层,去除了现有基于分类网络的图像分割方法对输入图像的宽度和高度限制,大大降低了构建图像样本集时的工作量,同时扩大了样本集的选择范围。
附图说明
图1是本发明的实现流程框图;
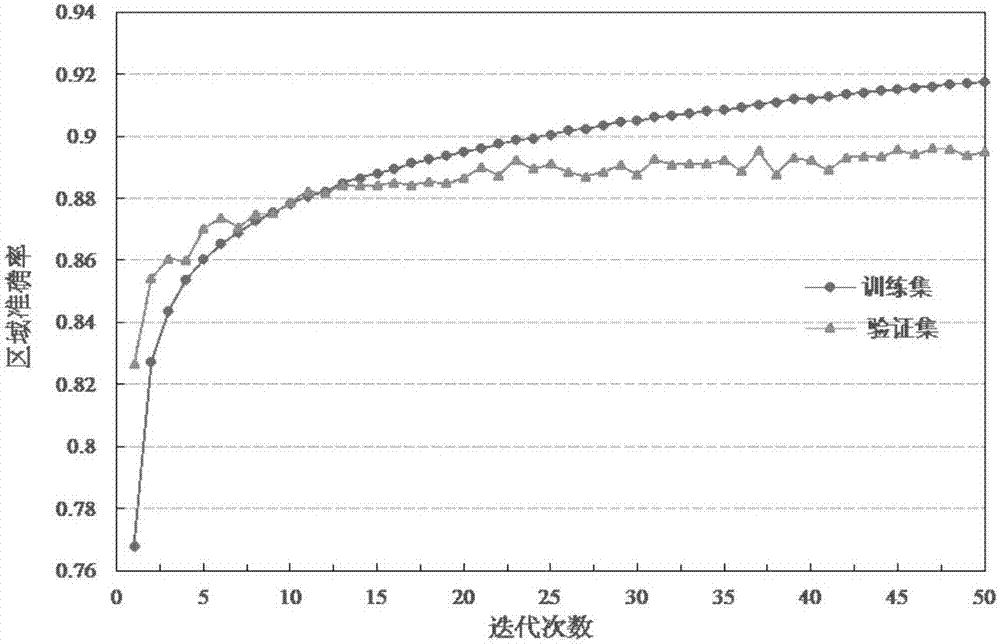
图2是本发明中训练输出像素级语义标记的全卷积网络时分割准确率随迭代次数的变化曲线图;
图3是本发明中fcn-32s、fcn-16s和fcn-8s三种模型下的像素级语义标记结果图;
图4是本发明与现有基于全卷积网络的语义分割方法的分割结果对比图;
图5是本发明与现有基于全卷积网络的语义分割方法的区域分割准确率和像素分割准确率的对比柱状图。
具体实施方案
下面结合附图和具体实施例,对本发明作进一步详细描述:
参照图1,基于超像素边缘和全卷积网络的图像语义分割方法,包括如下步骤:
步骤1构建训练样本集、验证样本集和测试样本集:
为了扩大样本集的规模,本实例将现有的最常用的样本集bsds500和pascalvoc2011取并集,共得到12023张图像,随机选取其中的11223(90%)张图片作为训练样本集,400(5%)张作为验证样本集,剩余的400(5%)张作为测试样本集。在进行训练时,只能只用训练样本集;在进行测试时,只能只用测试样本集;同样,在进行验证时,只能使用验证样本集。
步骤2搭建输出像素级语义标记的全卷积网络:
全卷积网络由分类网络转换而来,本实例将vgg-16网络转换为全卷积网络,与其他深度卷积神经网络相比,如resnet(152层)、goolenet(22层)、vgg-19(19层)、alexnet(8层)等,vgg-16网络在特征提取和训练效率之间能取得更好的平衡。resnet和goolenet虽然能提取更高级的图像特征,但是由于网络层数太多,在对大规模样本集进行训练时,模型容易过拟合,并易出现梯度弥散现象;vgg-16网络由于采用了更小的3×3卷积核,提高了模型的非线性表达能力,在一定程度上弥补了网络层数较小带来的特征抽象能力的不足的缺点。在多个样本集上的测试结果表明,vgg-16与vgg-19的top-1错误率均为24.4%,top-5错误率则分别为7.2%和7.1%,19层的网络对识别率的提升并不明显,选择vgg-16在保证网络识别能力的同时,使网络层数更低,所以选择前者更合理。
(2a)获取待搭建全卷积网络的基础网络和初始值:将vgg-16网络作为待搭建全卷积网络的基础网络,同时将matconvnet工具箱中的vgg-16网络预训练权值作为待搭建全卷积网络的初始值;
(2b)搭建全卷积网络:将待搭建全卷积网络中的全连接层fc-4096转换为4096个卷积核大小为1×1、卷积步长为1个像素的卷积层,全连接层fc-1000转换为1000个卷积核大小为1×1、卷积步长为1个像素的卷积层,得到全卷积网络;
(2c)获取输出像素级语义标记的全卷积网络:
(2c1)获取fcn-32s模型下的输出像素级语义标记的全卷积网络:将全卷积网络的第5个池化层输出的特征映射进行32倍上采样,得到fcn-32s模型下的输出像素级语义标记的全卷积网络;
(2c2)获取fcn-16s模型下的输出像素级语义标记的全卷积网络:将全卷积网络的第5个池化层输出的特征映射进行2倍上采样,并将上采样结果与第4个池化层输出的特征映射进行融合,再将融合结果进行16倍上采样,得到fcn-16s模型下的输出像素级语义标记的全卷积网络;
(2c3)获取fcn-8s模型下的输出像素级语义标记的全卷积网络:分别将全卷积网络的第4、5个池化层输出的特征映射进行2倍、4倍上采样,并将上采样结果与第3个池化层输出的特征映射融合,再将融合结果进行8倍上采样,得到fcn-8s模型下的输出像素级语义标记的全卷积网络;
步骤3对输出像素级语义标记的全卷积网络进行训练、测试和验证,得到验证后的输出像素级语义标记的全卷积网络:
(3a)本实例设定语义分割的区域准确率为60%、像素准确率为70%;
(3b)对输出像素级语义标记的全卷积网络进行训练;利用11223张测试图像及其真是语义标签数据对全卷积网络进行监督训练,为了使网络学习到的图像特征更高级抽象,本实例对训练样本集进行50次迭代监督训练,即前一次训练完成后的模型作为下次训练时的模型初始值。迭代训练需要保证每一个训练样本被迭代的次数相同,否则模型会对迭代次数多的图像更熟悉,导致模型对与之同类型的测试图像的分割性能更好;
(3c)对输出像素级语义标记的全卷积网络进行测试;将测试样本集中的400幅图像输入到已训练好的模型中,得到fcn-32s、fcn-16s和fcn-8s三种模型下的语义分割结果;
(3d)对输出像素级语义标记的全卷积网络进行验证:将验证样本集中的400幅图像输入到已测试的网络中,得到fcn-32s、fcn-16s和fcn-8s三种模型下的语义分割结果,并将其与验证样本集中的真实语义分割数据进行比对,本实例中得到的语义分割正确率大于设定的语义分割正确率阈值;
步骤4将待分割彩色图像i输入到验证后的输出像素级语义标记的全卷积网络中,得到待分割彩色图像i的像素级语义标记:
将测试图像输入验证后的输出像素级语义标记的全卷积网络中,获得测试图像像素级的语义标记;
步骤5对待分割彩色图像i进行bslic超像素分割:
本实例为了获得边缘贴合度更好的超像素,利用改进后的bslic超像素分割算法对待分割图像进行超像素分割。由于测试图像的分辨率从320×210到500×440不等,所以,在实际的超像素分割过程中,超像素的数目会根据平均大小15×15浮动地设定。例如,分辨率为500×333的测试图像,本文将其期望生成的超像素数目设为500,实际生成的超像素数目为610,生成的超像素平均大小为16×16;16×16与15×15大小的局部区域对分辨率为500×333的测试图像而言,几乎相等。具体步骤如下:
(5a)计算待分割彩色图像i的二值化边界图像b;
(5b)对待分割彩色图像i进行颜色空间转换,得到lab颜色空间的转换彩色图像ilab;
(5c)按照六边形分布,在转换彩色图像ilab上进行初始化,得到平面聚类中心pa:
(5c1)以像素为单位分别计算平面聚类中心的水平步长sh和垂直步长sv:
其中,n为图像像素点总数,k为期望的超像素数目;
(5c2)对平面聚类中心进行行向初始化,即在转换彩色图像ilab平面内,从
(5c3)对平面聚类中心进行列向初始化:
对于奇数行,从
对于偶数行,从sh列像素开始,每间隔sh列,选定一个像素作为平面聚类中心初始值;
(5c4)将步骤(5c2)~(5c3)产生的平面聚类中心标记为pa,a=1,2,...,np,np为平面聚类中心总数;
(5d)在平面聚类中心的局部范围内初始化边界聚类中心eb:
(5d1)在转换彩色图像ilab平面内确定搜索窗口:
在转换彩色图像ilab平面内,将以平面聚类中心pa为中心的sh×sh邻域范围作为搜索窗口wp,并记录wp在图像平面内的几何位置,记为[r0,c0,δr,δc],其中r0、c0分别为搜索窗口左上角像素点的行号、列号,δr、δc分别为搜索窗口的行宽、列宽;
(5d2)在二值化边界图像b平面内确定边界窗口:
在二值化边界图像b平面内,将左上角像素坐标为[r0,c0],行宽为δr,列宽为δc的矩形范围作为边界窗口wb;
(5d3)在转换彩色图像ilab平面内初始化边界聚类中心:
将wp与wb进行与运算,若运算结果中含有非零元素,说明平面聚类中心pa的sh×sh邻域范围内存在边界点,随机选取边界点的一个中值点,将其作为边界聚类中心的初始值;若运算结果中没有非零元素,说明平面聚类中心pa的sh×sh邻域范围内没有边界点,则不产生任何边界聚类中心;
(5d4)将步骤(5dc)产生的边界聚类中心标记为eb,b=1,2,...,ne,ne为边界聚类中心总数;
(5e)将所有平面聚类中心和边界聚类中心更新为各自3×3邻域内的梯度最小点,得到更新后的平面聚类中心pa′和边界聚类中心eb′;
(5f)将更新后的平面聚类中心pa′和边界聚类中心eb′作为初始值,利用局部k-means算法对转换彩色图像ilab的像素点进行分类标记;
(5g)循环迭代步骤(5f)的分类标记过程,直至连续两次的平面聚类中心和边界聚类中心的误差之和不超过5%,得到所有像素点的最终标记;
(5h)将具有相同标记的像素点看成一个超像素,在图像平面内画出所有超像素的边界,得到待分割图像i的超像素分割结果。
步骤6利用步骤(4)得到的像素级语义标记对步骤(5f)得到的多个bslic超像素分别进行语义标注,得到融合了超像素边缘和全卷积网络输出的高级语义信息的语义分割数据:
bslic算法赋予给超像素的数字标记没有包含任何语义信息,在利用全卷积网络的像素级语义标记对超像素进行语义标注时,分如下几种情况:(1)超像素中没有图像边缘,且所有像素点的fcn语义标记相同;(2)超像素中没有图像边缘,但像素点的fcn语义标记不同;(3)超像素中有图像边缘,但所有像素点的语义标记相同;(4)超像素中有边缘,同时像素点的语义标记不同。下面对这四种情况分别进行说明:
(6a)针对第一种超像素,可以直接用该语义标记对超像素进行语义标注。这类超像素通常为背景或某一目标的主体区域,也可能为图像中超像素边缘贴合度非常高的地方,如清晰的、平滑边缘等处;
(6b)第二种超像素没有边缘,代表该超像素为背景或目标的主体部分,或者为目标边缘清晰突出且平滑的地方。这类超像素中的像素点的语义类别不同,是由全卷积网络模型在对低级信息进行预测时,上采样过程中复制操作带来的扩散误差,通常表现为语义分割的结果在目标边缘的拐点处将部分背景像素标记为目标类别。针对这类超像素,可以用概率最大的语义类别对超像素进行标记;
(6c)第三种超像素中的像素点的语义类别一致,说明该超像素为某一语义类别下的目标的主体部分,超像素内的边缘则为该类别目标自带的边缘特征。输入图像最开始由像素的灰度值等低级特征表达,在全卷积网络模型的逐层特征抽象过程中,表达图像的特征越来越高级,这种高级特征表达通常对光照、形变具有鲁棒性;所以,这类超像素中的边缘特征可以由全卷积网络模型进行修正,这类超像素中的像素语义标注即为全卷积网络模型输出的像素类别;
(6d)第四种超像素既跨越了图像边缘又具有不同的语义标记类别,这类超像素即为“跨边界超像素”,通常出现在图像的结构发生突变或图像的虚弱边缘等处,这类超像素的语义标注分如下两种情况说明:
(6d1)若其中超过80%的像素隶属同一类,则用该概率最大的类别对超像素进行语义标注,这类超像素由于只有不到20%的像素属于其他类别,所以通常出现于图像结构发生突变的地方,如细缝等,这种结构上的细小突变在fcn模型的高层特征映射中无法体现,所以这类结构的准确定位依赖于bslic超像素提供的边缘信息;
(6d2)超像素中有边缘,像素的语义类别不一致,但不同类别的像素在超像素中占据的比例相差不大,即没有哪一类的概率高达80%。这类超像素往往出现在图像虚弱边缘处,由于处在这些边缘两侧的目标和背景相似度太高,所以超像素无法将二者进行有效区分;fcn模型能够赋予这类超像素中的像素不同的语义类别,源于fcn模型通过高层的抽象特征对两种类别进行了有效的区分所以,对这类超像素可以直接用fcn模型给出的标记结果对超像素中的像素进行标记。
以下结合仿真试验,对本发明的效果作进一步说明:
1.仿真条件和内容
实验数据采用伯克利计算机视觉研究组的bsds500图像库和pascalvoc2011图像库,本实施例的算法仿真平台为:主频为4.00ghz的cpu,20.0gb的内存,samsung840pro的固态硬盘,windows7(64位)操作系统,matlab2014a开发平台,matconvnet深度学习工具箱的beta23版本。
仿真1,对训练样本集进行50次迭代监督训练,并记录每次训练后的分割准确率,其准确率如图2所示;然后将测试样本集中的400幅图像输入到已训练好的网络中,其输出的语义分割结果如图3所示;
仿真2,从bsds500和pascalvoc2011样本集构成的测试样本集中选择若干幅含有细小边缘的图像作为输入图像,期望的超像素数目k=1000,加权因子m=5,用本发明与现有基于全卷积网络的语义分割方法分别进行语义分割,其结果如图4所示;
仿真3,基于区域分割准确率和像素分割准确率两个性能参数,用本发明与现有基于全卷积网络的语义分割方法对400幅测试图像作准确率对比实验,其结果如图5所示。
2.仿真结果分析
参照图2,可以看出随着训练迭代次数的增加,分割准确率在逐渐提高,从准确率曲线可以看出,本实例对训练样本集进行50次迭代监督训练足以达到测试时的准确率阈值要求;
参照图3,其中:
图3(a)为原始图像;图3(b)、图3(c)、图3(d)分别为fcn-32s、fcn-16s、fcn-8s三种模型下的语义分割结果;
图3(e)为真实(groundtruth)语义标签数据;
将图3(b)、图3(c)、图3(d)与图3(e)对比可以看出,相比fcn-32s和fcn-16s两种模型,fcn-8s的语义分割效果最好,对目标边缘的刻画最细致;
参照图4,其中:
图4(a)为待分割的测试图像;
图4(b)为采用bslic方法的超像素分割结果图;
图4(c)为采用现有基于全卷积网络的语义分割方法的分割结果图;
图4(d)为采用本发明的语义分割结果图;
图4(e)为待分割图像的真实语义分割数据。
比较图4(c)、图4(d)两列的语义分割结果,本发明比fcn-8s的分割效果更好,尤其对图像中细小边缘的定位更准确,如图中椭圆形标记的区域所示。改进后的模型继承了全卷积网络模型的语义识别准确度和目标形状的整体定位精度,由图4(c)、图4(d)两列中目标的颜色标记相同和目标形状整体相似可以看出。本发明对细小边缘、细缝等结构的定位精度更高,如飞机的机轮、鸟的脚、羊的耳朵、汽车的前视镜等,全卷积网络模型对这些结构无法准确分割是因为提取的高级抽象特征在预测低级特征时有扩散误差,表现为图像中的细小结构向背景区域扩散,使背景像素划分到目标区域,实际分割结果的区域比真实结果的更大。本发明通过对图像进行超像素分割,尤其使用对图像细小边缘更贴合的bslic超像素分割,能够向全卷积网络模型提供更丰富准确的图像边缘信息,能够给全卷积网络模型预测低级特征时提供参考,从而提高模型对边缘的定位精度。
上述对本发明和现有基于全卷积网络的语义分割方法的分割结果的定性分析表明,本发明能良好地继承fcn模型优异的图像高级语义信息的提取能力,同时由于该模型充分利用了图像边缘等位置信息,其对图像中的细小边缘、细缝等结构有更准确的定位。
参照图5,从中可以看出,相比现有基于全卷积网络的语义分割方法,本发明在平均区域准确率上达到了65.20%,有了2.51%的提升。其中,类别2(自行车)、类别13(马)和类别17(羊)的改进效果较好,这三个类别的区域准确率分别提升了8.14%、6.02%和4.28%。本发明在像素准确率上达到了77.14%,相比现有基于全卷积网络的语义分割方法有了1.29%的提升。
- 还没有人留言评论。精彩留言会获得点赞!