一种对K/V格式的数据快速存储和查询方法与流程
本发明涉及大数据量的k/v格式数据快速存取方法,特别是一种充分利用计算机资源实现对k/v格式的数据快速存储和查询方法。
背景技术:
随着互联网的发展,系统存储和读取的数据越来越多,对数据的读写性能要求也越来越高,计算分片和数据分片已成为储取和读取数据必不可少的手段了。目前的存储技术实现,存储和查询操作都要考虑保证数据的强一致性,对计算机cpu的利用不充分,存储和查询数据性能较差。但是对于很多应用场景,查询数据的量远远多于存储数据的量,且查询操作对数据强一致性要求不高,只要求数据最终一致性就能满足需求,但对查询数据的性能要求很高,这种情况下对数据读写性能的要求就高于对数据强一致的要求,我们就可以考虑牺牲数据的强一致性来换取数据读写性能的提升。
技术实现要素:
本发明的目的在于提供一种充分利用计算机资源实现对k/v格式的数据快速存储和查询方法,它主要解决上述现有技术所存在的技术问题,本发明方法分离对数据的读和写操作,在磁盘上分片存储数据,并发建立数据索引,为数据提供快速的存储和查询的方法。
为解决上述技术问题,本发明是这样实现的:
一种对k/v格式的数据快速存储和查询方法,其特征在于:它包括如下操作步骤:
s1、分离对数据的读和写操作;该读操作就是查询操作,该写操作就是存储操作;
s2、在磁盘上分片存储数据;将数据按照预定的分片算法存储到不同的文件分片,分片算法除了要求性能高效外,还需确保同一个k的数据存储在同一个分片文件上;
s3、建立数据索引;定时读取分片文件,将数据索引后重新存储到索引文件;
s4、实施读操作。
所述的对k/v格式的数据快速存储和查询方法,其特征在于:所述s2进一步包括如下步骤:
步骤s201:为了充分利用cpu资源,根据计算机cpu的核心数启动同数量的数据分片服务;
步骤s202:计算机收到客户端发来的写请求,参数为k和v,将写请求随机发给任一分片服务;
步骤s203:预先设置文件的分片总数n,分片文件编号a的算法公式为:a=crc32(k)%n;根据公式可算出当前请求的k的分片文件编号a;
步骤204:数据分片服务利用cpu、内存和磁盘资源把数据写入编号为a的分片文件上;分片文件中存储的数据内容是t:key:value,t是操作类型,如:新增、修改和删除,key:value是数值对。
所述的对k/v格式的数据快速存储和查询方法,其特征在于:所述s3、s4进一步包括如下步骤:
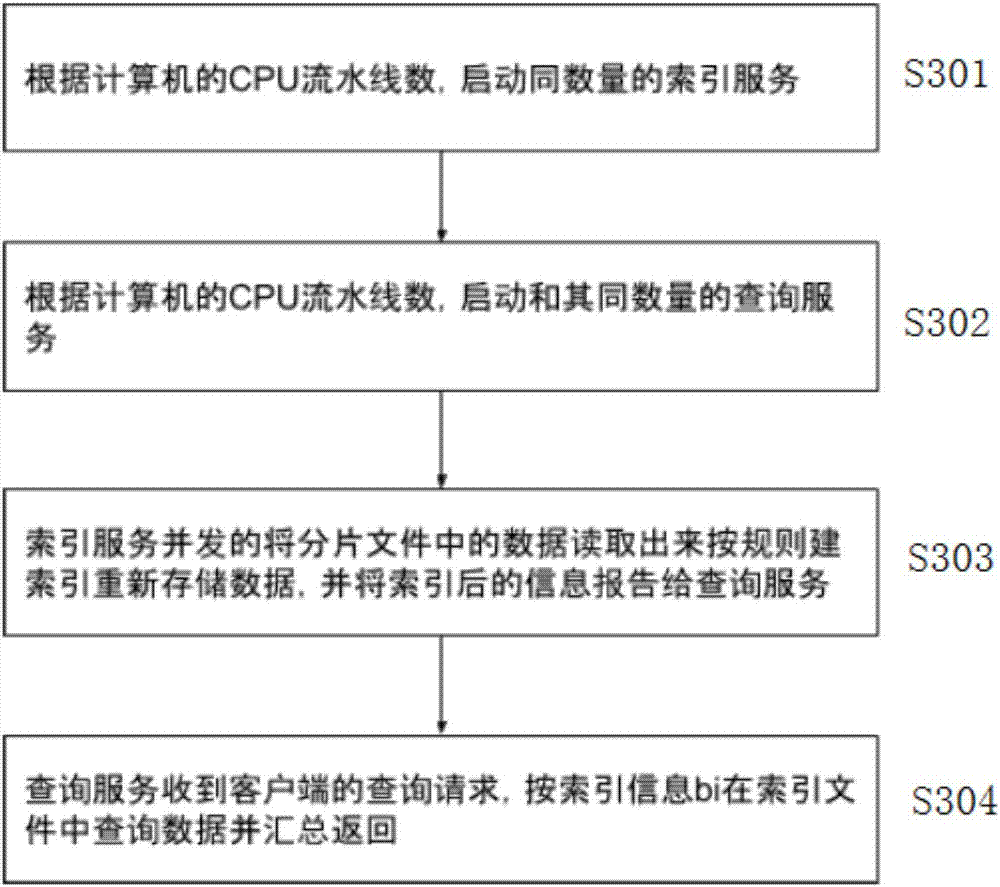
步骤s301:为了充分利用cpu资源,根据cpu的核心数启动同数量的索引服务;
步骤s302:根据cpu的核心数启动同数量的数据查询服务;
步骤s303:索引服务并发的将分片文件中的数据读取出来,根据索引规则建立文件索引重新存储数据;
步骤s304:查询服务收到客户端的查询请求,将请求按k并发的根据k的索引信息在索引文件中查找并读取数据,并将符合条件的数据汇总后返回给客户端。
所述的步骤s303的具体做法是:把索引文件分成以64k为单位的物理存储块,一个索引文件是由连续的64k大小的存储块构成,将分片文件中的数据顺序读出并重新写入索引文件,读取数据的时候以一个存储块作为基本读取单位,索引服务会记录每条数据的k对应的存储块地址,并将每个k的索引信息报告给查询服务,以提高查询速度。
所述的对k/v格式的数据快速存储和查询方法,其特征在于:所述的步骤s203中crc32也可以是md5、sha1、sha256、sha384、sha512的数据摘要算法。
所述的对k/v格式的数据快速存储和查询方法,其特征在于:所述的数据分片文件和索引文件是磁盘文件,或是任意的存储介质或存储服务。
藉由上述技术方案,本发明的优点如下:
1、数据的存取一般瓶颈首先出现在i/o上,一般难以充分利用计算机资源,本发明可以根据负载情况启停分片服务和索引服务,动态的调整计算机cpu和内存的使用情况,有效的提高了硬件资源的使用率,显著提升了数据的整体存取速度。
2、本发明在数据非强一致性要求的场景下,可按需求分别扩展分片文件数量、索引文件数量、分片服务和查询服务的数量,也即可最大限度的利用计算机硬件资源来提高数据的存储和存储性能。为了提高i/o性能可将计算机磁盘换为固态硬盘。
附图说明
图1是本发明方法中写操作的具体步骤示意图。
图2是本发明方法中读操作的具体步骤示意图。
图3是本发明实施例的框架结构示意图。
具体实施方式
本发明公开了一种充分利用计算机资源实现对k/v格式的数据快速存储和查询方法。它包括如下操作步骤:
s1、分离对数据的读和写操作;该读操作就是查询操作,该写操作就是存储操作。
s2、在磁盘上分片存储数据;将数据按照预定的分片算法存储到不同的文件分片,分片算法除了要求性能高效外,还需确保同一个k的数据存储在同一个分片文件上。
s3、建立数据索引;定时读取分片文件,将数据索引后重新存储到索引文件。
s4、实施读操作。
如图1所示:所述s2进一步包括如下步骤:
步骤s201:为了充分利用cpu资源,根据计算机cpu的核心数启动同数量的数据分片服务。
步骤s202:计算机收到客户端发来的写请求,参数为k和v,将写请求随机发给任一分片服务。
步骤s203:预先设置文件的分片总数n,分片文件编号a的算法公式为:a=crc32(k)%n;根据公式可算出当前请求的k的分片文件编号a。
步骤204:数据分片服务利用cpu、内存和磁盘资源把数据写入编号为a的分片文件上;分片文件中存储的数据内容是t:key:value,t是操作类型,如:新增、修改和删除,key:value是数值对。
如图2所示:所述s3、s4进一步包括如下步骤:
步骤s301:为了充分利用cpu资源,根据cpu的核心数启动同数量的索引服务。
步骤s302:根据cpu的核心数启动同数量的数据查询服务。
步骤s303:索引服务并发的将分片文件中的数据读取出来,根据索引规则建立文件索引重新存储数据。
步骤s304:查询服务收到客户端的查询请求,将请求按k并发的根据k的索引信息在索引文件中查找并读取数据,并将符合条件的数据汇总后返回给客户端。
本发明中,所述的步骤s303的具体做法是:把索引文件分成以64k为单位的物理存储块,一个索引文件是由连续的64k大小的存储块构成,将分片文件中的数据顺序读出并重新写入索引文件,读取数据的时候以一个存储块作为基本读取单位,索引服务会记录每条数据的k对应的存储块地址,并将每个k的索引信息报告给查询服务,以提高查询速度。
作为变化例,所述的步骤s203中crc32也可以是crc32、md5、sha1、sha256、sha384、sha512的数据摘要算法。
作为可实施方式,所述的数据分片文件和索引文件是磁盘文件,或是任意的存储介质或存储服务。
实施例
以一台16核cpu的计算机为例,本发明的架构设计如图3。
综上所述仅为本发明的较佳实施例而已,并非用来限定本发明的实施范围。即凡依本发明申请专利范围的内容所作的等效变化与修饰,都应为本发明的技术范畴。
- 还没有人留言评论。精彩留言会获得点赞!