基于网格的空间数据分布式存储及检索方法和系统与流程
本发明涉及一种存储及检索方法和系统,属于空间数据处理领域,具体是涉及一种基于网格的空间数据分布式存储及检索方法和系统。
背景技术:
随着测绘遥感技术的发展,空间数据不仅在数据规模上日益增长,而且在数据精度上也日趋精确,还在数据实时性上有大幅度提升。特别是近年来,在互联网/移动互联网行业以lbs/sns为核心的空间数据相关应用需求驱动下,空间大数据分布式存储、计算技术得到了广泛的应用。空间大数据具有数据量大、数据关联性强、数据块之间解耦困难等特性,这些特性对其存储、索引与检索提出了特殊的要求。
现有空间数据存储计算技术主要基于传统分布式文件系统技术或分布式关系数据库集群技术:前者仅采用路径名/文件名来索引数据,未构建空间索引;后者检索过程难以实现去中心化,且空间索引的改写/更新过程难以实现真正的并行化。上述技术限制一定程度上制约了空间大数据的应用和发展。
在一些行业应用场景中,通过引入互联网行业普遍采用的nosql存储技术,一定程度上实现了空间大数据的高效率分布式查询。这些技术以类似日志数据的形式存储空间数据,并在分布式环境下通过采用逐条遍历的方式实现查询、更新等操作。这样虽然一定程度上提升了空间大数据应用的效率,但由于其后端依然依赖于分布式文件存储,因此对于一部分应用场景特别是涉及空间数据写入/更新的操作,存在一定的延迟,难以满足实时化/准实时化应用的需求。
在一些对实时性要求较高的空间大数据应用场景中,普遍采用缓存机制提升应用的实时性,如图1所示。
在分布式空间数据库集群与用户之间增加缓存服务器,该服务器首先根据用户请求将特定的数据块从空间数据库集群中取出,返回给用户的同时将该数据块存入缓存数据中;当下一次接收到用户请求后,首先与缓存数据中存储的数据块进行比对,如果该请求要求的数据块与缓存中存在的数据块一致或该请求要求的数据块被缓存中的数据块所包含(缓存命中)则直接将缓存的数据块返回给用户,否则需要从空间数据库集群中取出用户所需的数据块并返回给用户(缓存不命中),同时将该数据块存入缓存。如果此时缓存已满则使用某种策略(lru、fifo等)从缓存中选择一块数据进行替换。
应用缓存机制一定程度上能够提升分布式空间数据库的响应速度。然而,由于空间数据的强关联性,应用传统的文件缓冲策略容易造成缓存不命中的问题,甚至在特定场景下由于不同数据块边界处的频繁访问引发抖动现象,最终造成间歇性的系统实时性大幅度下降。
现有空间数据分布式存储技术本质上是将数据分块之后存储在每个节点的磁盘上,因此其访问速度受到磁盘i/o速率的限制。当同一节点上的数据被高频率访问时,该节点磁盘i/o压力较大,会引起数据访问的响应度大幅度下降。
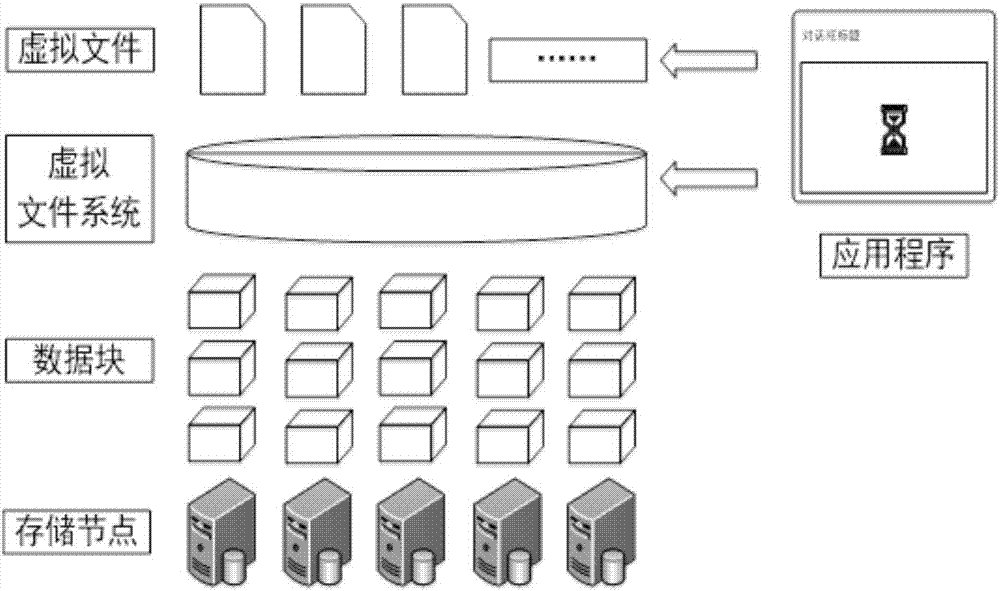
现有分布式存储技术通常对数据的存储进行多次抽象,并对应用程序隐藏这种抽象机制,如图2所示。应用程序能够访问上层的虚拟文件系统以及其中的虚拟文件,却无法直接访问特定文件对应的数据块或存储特定数据块的存储节点,即数据的物理存储形式对应用来说是完全透明的。在空间大数据的应用中,该模式可能会造成空间关联较强的两个文件(或者是同一文件中空间关联较强的两个数据块)实际上被存储在不同的存储节点上。当应用需要访问这部分空间对应的数据时,可能造成对多个物理存储节点的频繁访问,从而降低访问效率。
技术实现要素:
本发明主要是解决在分布式集群环境下,因多节点间的协调和数据同步的限制对空间数据响应度造成的影,提供了一种基于网格的空间数据分布式存储及检索方法和系统。该方法和系统提出了新的数据存储、组织和索引形式,可以有效的提升分布式集群环境下的地理信息检索效率
本发明的上述技术问题主要是通过下述技术方案得以解决的:
一种基于网格的空间数据分布式存储及检索方法,包括:
数据分块步骤,以网格形式将数据划分为数据块,将数据块存储于节点的内存中,其中,每个数据块包括数据块id,hash值,时间戳;
数据查询步骤,计算待检索空间坐标对应的hash值并判断其所属网格的网格号,根据网格号查询元数据表以获得节点号,根据节点号、网格号和hash值在存储集群中进行检索。
优选的,上述的一种基于网格的空间数据分布式存储及检索方法,所述数据分块步骤中,
将数据块划分为分区,每个分区储存在一个节点上,每个分区包括2n个数据块,n≧1;
在向节点分发数据块时采用冗余分区,两个相邻的分区有若干行和/或若干列重复的数据块,分区完成后按照分区的创建顺序依次将分区分配至对应节点中,基于分区结果构造元数据表,描述每个数据块所在的分区和所在的节点;
当一个数据块具有存在于多个分区的副本时,所有分区中的副本使用相同的数据块编号,并在元数据表中记录其每个副本的信息。
优选的,上述的一种基于网格的空间数据分布式存储及检索方法,所述数据分块步骤中,采用geohash函数来生成hash值,基于以下步骤生成geohash索引:
区间递归子步骤,已知空间坐标(x,y),其中x是纬度,y是经度;首先分别按照区间递归等分的方法进行0-1编码直到编码位数对应的空间划分粒度符合精度要求,得到二进制串bx,by;
合并拆分子步骤,对bx和by按照奇偶位数进行合并,bx拆分后作为新二进制串的奇数位,by拆分后作为新二进制串的偶数位,从而得到新二进制串b;
哈希生成子步骤,令字符串h=base32(b),字符串h即为空间坐标(x,y)的geohash值。
优选的,上述的一种基于网格的空间数据分布式存储及检索方法,所述数据分块步骤中,按照网格划分空间,每个网格对应一个数据块;数据的索引采用数据块编号+geohash值的形式表示;数据的索引存储在数据索引数据表中。
优选的,上述的一种基于网格的空间数据分布式存储及检索方法,所述数据查询步骤中,通过计算出检索目标点的geohash值作为待检索hash值,从数据索引表中检索与待检索hash值最接近的geohash值所对应的网格号和/或数据块号;然后通过该网格号和/或数据块号从元数据表中检索到其对应的分区和对应的节点。
优选的,上述的一种基于网格的空间数据分布式存储及检索方法,所述数据查询步骤中,
在查询时检索函数如果从元数据表中检索到该数据块具有多个副本,则同时执行多次检索;然后从检索到的多个数据块中选择时间戳与检索发生时间最接近的数据块作为检索结果,同时对其他副本进行更新,实现冗余数据块的同步。
一种基于网格的空间数据分布式存储及检索系统,包括:
数据分块模块,以网格形式将数据划分为数据块,将数据块存储于节点的内存中,其中,每个数据块包括数据块id,hash值,时间戳;
数据查询模块,计算待检索空间坐标对应的hash值并判断其所属网格的网格号,根据网格号查询元数据表以获得节点号,根据节点号、网格号和hash值在存储集群中进行检索。
优选的,上述的一种基于网格的空间数据分布式存储及检索系统,所述数据分块模块中,
将数据块划分为分区,每个分区储存在一个节点上,每个分区包括2n个数据块,n≧1;
在向节点分发数据块时采用冗余分区,两个相邻的分区有若干行和/或若干列重复的数据块,分区完成后按照分区的创建顺序依次将分区分配至对应节点中,基于分区结果构造元数据表,描述每个数据块所在的分区和所在的节点;
当一个数据块具有存在于多个分区的副本时,所有分区中的副本使用相同的数据块编号,并在元数据表中记录其每个副本的信息。
优选的,上述的一种基于网格的空间数据分布式存储及检索系统,所述数据分块模块中,采用geohash函数来生成hash值,基于以下模块生成geohash索引:
区间递归单元,已知空间坐标(x,y),其中x是纬度,y是经度;首先分别按照区间递归等分的方法进行0-1编码直到编码位数对应的空间划分粒度符合精度要求,得到二进制串bx,by;
合并拆分单元,对bx和by按照奇偶位数进行合并,bx拆分后作为新二进制串的奇数位,by拆分后作为新二进制串的偶数位,从而得到新二进制串b;
哈希生成单元,令字符串h=base32(b),字符串h即为空间坐标(x,y)的geohash值。
优选的,上述的一种基于网格的空间数据分布式存储及检索系统,所述数据查询模块中,
在查询时检索函数如果从元数据表中检索到该数据块具有多个副本,则同时执行多次检索;然后从检索到的多个数据块中选择时间戳与检索发生时间最接近的数据块作为检索结果,同时对其他副本进行更新,实现冗余数据块的同步。
因此,本发明具有如下优点:1.采用本发明方法进行空间数据分布式存储由于避免了磁盘i/o瓶颈,且利用跨节点内存空间数据结构降低了节点间的冗余通讯,因此相比现有的分布式空间数据存储技术(基于分布式文件系统或分布式空间数据库)能提供更高的响应度;
2.本发明用内存存储取代了基于磁盘的存储,在实施上存在增添内存的成本问题和内存的掉电易失特性问题:对于前者,随着内存制造技术的发展,内存设备的造价已经大幅度下降,对于存储服务区处于可接受范围内;对于后者,具体实现中可对内存数据周期性创建磁盘快照,以实现快速的灾难恢复。
附图说明
附图1是现有技术中的采用缓存机制存储数据时的示意图;
附图2是本发明的一种工作流程图;
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:
本发明的核心思想是将空间数据分散存储在集群各个节点的内存中,并构建跨节点的空间索引,避免了基于磁盘i/o的数据存储方式和基于数据块且与空间数据位置关系无关的数据分配方式。
1、数据存储方式:数据以数据块的形式存放在每个节点的每个内存中,每个数据块包含id、geohash值、空间数据内容(wkt/wkb/geojson等)和时间戳。每个节点上可以存放多个数据块。
2、数据索引与检索:数据索引采用网格+geohash的形式实现。待检索空间坐标通过检索函数首先计算出geohash值并判断其所属网格的网格号并查询元数据表得知其所在节点号,然后依据节点号、网格号和geohash值在存储集群中进行检索。
3、数据划分与边界冗余数据:按照网格划分数据块,每个数据块对应网格中的一格。每个节点上存放2n个数据块(n≧1)。在向节点分发数据块时采用如图所示的冗余分区,两个相邻的分区会有一行(或一列)重复的数据块。
4、数据一致性检验:根据应用场景可设置不同的冗余度,导致同一个数据块在不同的节点上存在多个副本;此外3中提及的边界冗余数据也会导致一个数据块在不同节点上存在多个副本。当访问过程存在改写操作时,可能出现该数据块的多个副本内容不一致的情况。为了保证查询结果的时序正确性,在查询时检索函数如果从元数据表中检索到该数据块具有多个副本,则同时执行多次检索;然后从检索到的多个数据块中选择时间戳与检索发生时间最接近的数据块作为检索结果。具休的,在对元数据表进行检索时,如果同一个数据块编号检索到多条对应的记录,则认定该数据块具有多个副本(也就是该数据块被冗余存储)。储存多个副本事实上起到了分散网络通讯的作用:读取多个副本的过程在多个节点上并行化执行,且每个数据读取操作都是直接从内存存储区域中读取数据,不受到磁盘i/o瓶颈的影响,故整体性能不会有明显下降。
本实施例中,所有数据块具有唯一的编号。分区完成后按照分区的创建顺序依次分配到每个节点,并在分配后通过集群内部高速网络传输到每个对应的节点并存储于该节点内存中。分区大小根据数据规模和集群规模进行适配,确保每个分区储存在一个节点上。基于分区结果构造元数据表,描述每个数据块所在的分区和所在的节点。
为了解决空间数据连续化的访问与空间数据的分块分区存储存的矛盾,加快分区边界区域数据的访问速度,在每个分区间增加一行(或一列)的冗余部分。当访问边界处的空间数据时,可以利用冗余行/列实现访问过程的跨节点无缝切换,即对冗余部分的数据请求由包含冗余数据的两个(或多个)节点同时响应。当一个数据块有多个副本时,所有的副本使用相同的数据块编号,并在元数据表中记录其每个副本的信息。
本实施例中,基于以下步骤生成geohash索引:
1)已知空间坐标(x,y),其中x是纬度,y是经度。首先分别按照区间递归等分的方法进行0-1编码直到编码位数对应的空间划分粒度符合精度要求,得到二进制串bx,by;
2)对bx和by按照奇偶位数进行合并,bx拆分后作为新二进制串的奇数位,by拆分后作为新二进制串的偶数位,从而得到新二进制串b;
3)令字符串h=base32(b),字符串h即为空间坐标(x,y)的geohash值。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!