基于标签模型的文本无载体信息隐藏方法与流程
本发明涉及通信技术领域,尤其涉及一种基于标签模型的文本无载体信息隐藏方法。
背景技术:
目前已经有相当数量的无载体信息隐藏方法。文本无载体信息隐藏方法主要是利用从网络上采集的正常文本数据作为文本库。将待隐藏信息切分成“关键词”,再设置包含接收方特征的“隐秘标签”来引导“关键词”提取,在文本库中查找符合“隐秘标签”+“关键词”特征的文本来生成含密数据。接收方接受到含密文本后根据自身特征来获取特征,最后根据隐秘标签来提取秘密信息。虽然现有的无载体信息隐藏方法可以在一定程度上抵抗隐写检测,但由于该技术不对采集来的文本做任何修改,导致其隐藏容量不高。
技术实现要素:
本发明提供一种基于标签模型的文本无载体信息隐藏方法,用以解决现有技术中无载体信息隐藏方法的隐藏容量较低的技术问题,同时确保隐藏的成功率。
为了解决上述问题,本发明提供了一种基于标签模型的文本无载体信息隐藏方法,包括如下步骤:
第一步,收集文本及建立索引:从网络中收集大量的自然文本并进行存储,以构建文本库,然后采用如下步骤建立索引:
步骤11:对于任意一文本,获取其路径位置及文件名;
步骤12:对所述文本进行分词、去除停用词的预处理,得到文本关键词序列;
步骤13:对于所述文本关键词序列中的第一个关键词,使用‘start’作为文本标签;对于所述文本关键词序列中非第一个的关键词使用紧邻的前一个字的unicode二进制码作为文本标签;然后用文本标签加文本关键词作为文本索引项;
第二步,秘密信息的隐藏:采用如下步骤进行秘密信息的隐藏:
步骤21:对秘密信息进行分词、去停用词的预处理,得到秘密信息关键词序列,所述秘密信息关键词序列中包括顺序排列的i个待隐藏的秘密信息关键词,其中,i为正整数;
步骤22:使用汉字的unicode作为秘密信息标签,根据接收方相应的特征计算得到秘密信息标签序列,所述秘密信息标签序列中包括顺序排列的j个秘密信息标签,其中,j为正整数,且j≥i+1;
步骤23:采用所述秘密信息标签序列中的第一个秘密信息标签和所述秘密消息关键词序列中n个秘密信息关键词的长度值的组合作为头文件,采用所述秘密信息标签序列中的第二个至第n+1个秘密信息标签与所述秘密消息关键词序列中的前n个秘密信息关键词一一组合构成n个含密文本,其中,n为正整数,且n≤6;
步骤24:通过所述文本索引项从所述文本库中选择与所述的头文件和n个所述含密文本一一对应的n+1个目标文本信息,所述目标文本信息包括所述目标文本的位置及文件名;
步骤25:当i>n时,以剩下的秘密信息关键词作为新的秘密信息关键词序列,并以剩下的秘密信息标签作为新的秘密信息标签序列,重复步骤23、步骤24,直至所有的秘密信息关键词都参与构建含密文本;
第三步,秘密信息的发送:将所有的目标文本信息顺序排列作为隐藏文本发送至所述接收方。
优选的,所述基于标签模型的文本无载体信息隐藏方法还包括如下步骤:
第四步,秘密信息的提取:采用如下步骤进行秘密信息的提取:
步骤31:所述接收方使用汉字的unicode作为秘密信息标签,根据接收方相应的特征计算得到秘密信息标签序列;
步骤32:根据第一个秘密信息标签从所述隐藏文本中的第一个目标文本信息中获取后续个n个含密文本中秘密信息关键词的长度;
步骤33:根据第二个至第n+1个目标文本信息和第二个至第n+1个秘密信息标签获得n个秘密信息关键词的位置,再根据n个秘密信息关键词的长度从所述文本库中提取n个秘密信息关键词并组合成片段信息。
步骤34:以剩下的秘密信息标签作为新的秘密信息标签序列,剩下的目标文本信息作为信息的隐藏文本,重复步骤32、步骤33,直至所有的目标文本信息都被提取;
步骤35:将所有的片段信息按获取的先后顺序排列,以组合成所述秘密信息。
本发明提供的基于标签模型的文本无载体信息隐藏方法,在传统的无载体信息隐藏方法的基础上添加了标签和头文件,在确保隐藏的成功率的同时,提高了隐藏容量。
附图说明
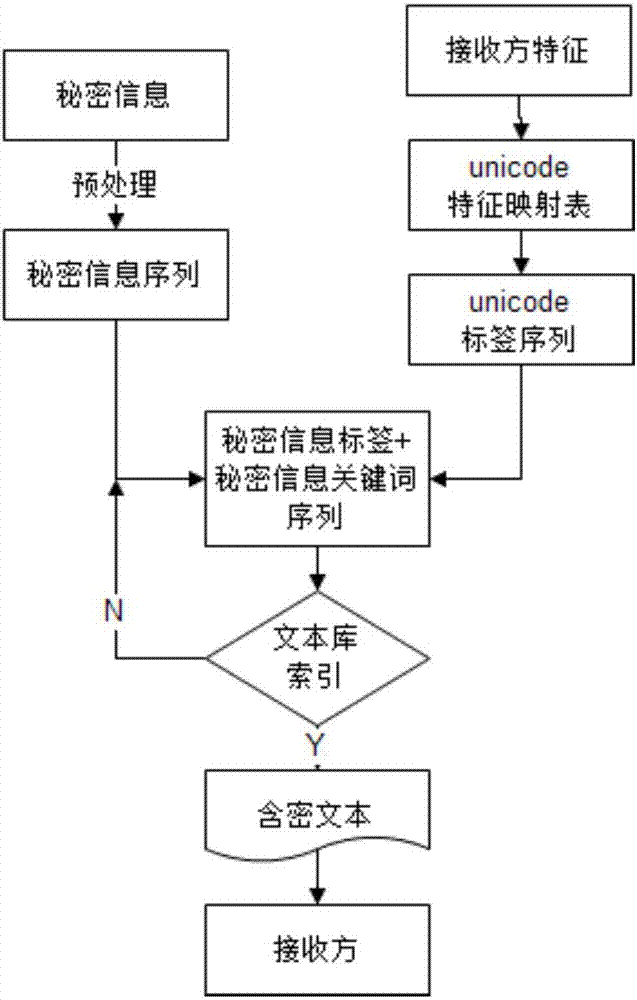
附图1是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的整体流程示意图;
附图2是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的秘密信息的隐藏步骤中的具体流程示意图;
附图3a是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的头文件的结构示意图;
附图3b是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法中多个含密文本的结构示意图;
附图4是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的秘密信息的提取步骤中的具体流程示意图;
附图5a、5b是本发明实施例1的结构示意图。
具体实施方式
下面结合附图对本发明提供的基于标签模型的文本无载体信息隐藏方法的具体实施方式做详细说明。
本具体实施方式提供了一种基于标签模型的文本无载体信息隐藏方法,附图1是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的整体流程示意图。
如图1所示,本具体实施方式提供的基于标签模型的文本无载体信息隐藏方法包括如下步骤:
第一步,收集文本及建立索引。从网络中收集大量的自然文本并进行存储,以构建文本库。即从网络大数据中采集数据,并将采集后的数据存储于计算机中。然后采用如下步骤建立索引:
步骤11:对于任意一文本,获取其路径位置及文件名。
步骤12:对所述文本进行分词、去除停用词的预处理,得到文本关键词序列。在本具体实施方式中,文本关键词序列中包括顺序排列的多个关键词。
步骤13:对于所述文本关键词序列中的第一个关键词,使用‘start’作为文本标签;对于所述文本关键词序列中非第一个的关键词使用与其紧邻的前一个字的unicode二进制码作为文本标签;然后用文本标签加文本关键词作为文本索引项。所谓与其紧邻的前一个字,是指在关键词序列中,与该关键词紧邻的前一个关键词的最后一个汉字。
在本具体实施方式中,对于文本库中的所有文本都采用上述步骤11-步骤13的方法来进行处理,从而最终得到多个文本索引项。
第二步,秘密信息的隐藏。附图2是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的秘密信息的隐藏步骤中的具体流程示意图。具体来说,采用如下步骤进行秘密信息的隐藏:
步骤21:对秘密信息进行分词、去停用词的预处理,得到秘密信息关键词序列,所述秘密信息关键词序列中包括顺序排列的i个秘密信息关键词,其中,i为正整数。例如,所述秘密信息关键词序列可以表示为k1,k2...ki,其中i为正整数,ki表示第i个秘密信息关键词序列中的第i个秘密信息关键词。所述秘密信息关键词序列中的多个秘密信息关键词是顺序排列的。
步骤22:使用汉字的unicode作为秘密信息标签,根据接收方相应的特征计算得到秘密信息标签序列,所述秘密信息标签序列中包括顺序排列的j个秘密信息标签,其中,j为正整数,且j≥i+1。例如,所述秘密信息标签序列可以表示为t1,t2...tj。在本具体实施方式中,所述接收方相应的特征是指接收方的标识号、秘密信息发送时间等随机信息;所述根据接收方相应的特征计算得到秘密信息标签序列是指,采用一预设算法,例如根据所述随机信息得到特征数、然后根据特征数循环取数等,得到一串unicode二进制码序列。在本具体实施方式中,由于增加了头文件,因此,每使用一个头文件所述秘密信息标签序列中所包含的秘密信息标签的数量比所述秘密信息关键词序列中所包含的秘密信息关键词的数量多一个;当使用a个头文件时,秘密信息标签序列中所包含的秘密信息标签的数量j应该满足j≥i+a。
步骤23:采用所述秘密信息标签序列中的第一个秘密信息标签和所述秘密消息关键词序列中n个秘密信息关键词的长度值的组合作为头文件,采用所述秘密信息标签序列中的第二个至第n+1个秘密信息标签与所述秘密消息关键词序列中的前n个秘密信息关键词一一组合构成n个含密文本,其中,n为正整数,且n≤6。所谓关键词的长度值,是指关键词中的文字数量。附图3a是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的头文件的结构示意图。在本具体实施方式中,每个头文件中包含n个秘密信息关键词的长度值,因而,就可以得到n个秘密信息关键词的长度值的unicode二进制码;将这n个秘密信息关键词的长度值的unicode二进制码组合为一个整体,所述头文件就是由第一个秘密信息标签与这个整体共同构成的。
步骤24:通过所述文本索引项从所述文本库中选择与所述的头文件和n个所述含密文本一一对应的n+1个目标文本信息,所述目标文本信息包括所述目标文本的位置及文件名。具体来说,从所述文本索引项中选择与一秘密信息标签对应的一目标文本标签,然后选择与所述目标文本标签对应的一目标文本内容,然后将与所述目标文本标签、所述目标文本内容对应的目标文本的位置及文件名作为一目标文本信息。
步骤25:当i>n时,以剩下的秘密信息关键词作为新的秘密信息关键词序列,并以剩下的秘密信息标签作为新的秘密信息标签序列,重复步骤23、步骤24,直至所有的秘密信息关键词都参与构建含密文本。当i≤6时,在步骤23中n=i。举例来说:假设现在要隐藏一句话,含有由14个秘密信息关键词组成的秘密信息关键词序列,我们将秘密信息关键词序列表示成k1,k2...k14,以n=6为例,即每六个秘密信息关键词加一个头文件,则我们需要由17个秘密信息标签组成的秘密信息标签序列,我们将秘密信息标签序列表示为label1,label2,label3,…,label17,则头文件与含密文本的对应关系是label1+head1,label2+k1,label3+k2,...label7+k6,label8+head2,label9+k7,label10+k8,...label14+k12,label15+head3,label16+k13,label17+k14;其中,head1表示秘密信息关键词k1、k2、k3、k4、k5、k6中每一个秘密信息关键词长度值的unicode二进制码组合(例如k1、k2、k3、k4、k5、k6的长度值分别为2、3、2、2、3、3,则head1表示为101110101111),label1+head1构成第一个头文件;head2表示秘密信息关键词k7、k8、k9、k10、k11、k12中每一个秘密信息关键词长度值的组合,label8+head2构成第二个头文件;head3表示秘密信息关键词k13、k14中每一个秘密信息关键词长度值的组合,label15+head3构成第三个头文件。
第三步,秘密信息的发送:将所有的目标文本信息顺序排列作为隐藏文本发送至所述接收方。
在本具体实施方式中,我们设定每两位的二进制数来作为一段头文件中关键词的文字数量信息,映射关系为每段头文件代表的是后面隐藏文件中标签后的关键词的长度值。这是因为,经过以往的统计研究发现无载体信息隐藏对于隐藏单个汉字的成功率高达98%。汉字字符总数为91251,其中国标一级汉字gb2312-80(gb/t16-55。1980)数量为3755,这里根据文本库中的汉字出现频率补至4096,然后将它映射成一个12bit(4096)的二进制。每两位包含一个自然文本的关键词数量,所以本具体实施方式将所述秘密信息可以一个含密文本包括6个秘密信息关键词的方式进行划分,即在本具体实施方式中,n优选为6。
附图3b是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法中多个含密文本的结构示意图。当n=6时,本具体实施方式将秘密信息分成每6个秘密信息关键词为一组,每组由7个秘密信息标签(头文件中包括一个秘密信息标签)、6秘密信息关键词,即由第一个秘密信息标签和六个秘密信息关键词的长度组成的头文件、以及由六个秘密信息标签与六个秘密信息关键词一一对应构成的六个含密文本。如果秘密信息较短,则只需将秘密信息分为一组;如果秘密信息较长,则需要将秘密信息分为多组。当所述秘密信息关键词序列中所包含的秘密信息关键词的数量不为n的整数倍时,将最后剩余的m个秘密信息关键词与m+1个秘密信息标签作为一组,以实现对所有秘密信息关键词的隐藏,其中,m为正整数,且m<n。
举例来说,假设待隐藏的秘密信息为文本s,对所述文本s进行上述步骤21得到关键词序列k={k1,k2,...ki};然后将秘密信息发送给接收方x,并根据所述接收方x的特征计算得到标签序列t={t1,t2,...tj}。如果是使用以往的无载体信息隐藏策略,则直接从索引库中检索满足t+k={t1+k1,t2+k2,...ti+ki}的文本作为含密文本。因此隐藏容量是一个含密文本隐藏一个只包含一个文字的关键词。但是在本具体实施方式中,增加了一个头文件来帮助存储包含多个文字的关键词。例如从所述文本库中能够根据文本标签检索到能包含更多关键词的自然文本t+k={t1+k1k2,t2+k3,t3+k4k5k6,...},那我们同样的检索满足标签要求t+h(headerfile)={t+(2,1,3,...)}的自然文本作为头文件。那么我们真正发送的文本包含的一个头文件加上n个秘密信息文本{t1+(2,1,3,...)+t2+k1k2,t3+k3,t4+k4k5k6,...}(如果n个秘密信息文本不够隐藏信息则继续添加头文件和n个秘密信息的组合)在所述头文件中,数字2、1、3等代表的是后续每个标签定位的关键词中的文字数量。从该例子中可以看出本例使用了一个头文件和3个自然文本隐藏了6个文字,即本具体实施方式的无载体隐藏方法大大优于以往的方案。头文件大大解放标签的负担,标签可以尽可能的定位更多的关键词。
在本具体实施方式中,通过使用多个秘密信息标签来与多个秘密信息关键词进行匹配,从而极大的提高了无载体信息隐藏的容量;同时通过增加一个头文件,来告知接收方所述秘密信息关键词序列中每一关键词的长度值,以确保隐藏成功率。
为了便于接收方提取含密文本中的秘密信息,优选的,所述基于标签模型的文本无载体信息隐藏方法还包括如下步骤:
第四步,秘密信息的提取。秘密信息的提取是秘密信息隐藏的逆步骤。附图4是本发明具体实施方式的基于标签模型的文本无载体信息隐藏方法的秘密信息的提取步骤中的具体流程示意图。在本具体实施方式中,第四步秘密信息的提取是第二步秘密信息的隐藏的逆步骤。具体采用如下步骤进行秘密信息的提取:
步骤31:所述接收方使用汉字的unicode作为秘密信息标签,根据接收方相应的特征计算得到秘密信息标签序列,所述秘密信息标签序列中包括顺序排列的j个秘密信息标签。
步骤32:根据第一个秘密信息标签从所述隐藏文本中的第一个目标文本信息中获取后续个n个含密文本中秘密信息关键词的长度。
步骤33:根据第二个至第n+1个目标文本信息和第二个至第n+1个秘密信息标签获得n个秘密信息关键词的位置,再根据n个秘密信息关键词的长度从所述文本库中提取n个秘密信息关键词并组合成片段信息。
步骤34:以剩下的秘密信息标签作为新的秘密信息标签序列,剩下的目标文本信息作为信息的隐藏文本,重复步骤32、步骤33,直至所有的目标文本信息都被提取;
步骤35:将所有的片段信息按获取的先后顺序排列,以组合成所述秘密信息。
本具体实施方式提供的基于标签模型的文本无载体信息隐藏方法,在传统的无载体信息隐藏方法的基础上添加了标签和头文件,在确保隐藏的成功率的同时,提高了隐藏容量。
实施例1
本实施例提供了一种秘密信息的隐藏以及秘密信息的提取方法。附图5a、5b是本发明实施例1的结构示意图。
例如隐藏秘密信息:中华人民共和国。具体步骤如下:
第一步:首先进行分词处理得到关键词序列:中华,人民,共和国,成立了。所述关键词序列中关键词长度依次为2,2,3,3。
第二步:明确接受者,根据接受者和一些额外随机量如发送时间,发送地址等得到标签特征,根据标签特征从标签库中获得标签序列,假设这里的标签特征生成为4,可以从标签库中第四位开始,步长为4依次获得标签序列:16,45...。
第三步:获取头文件。头文件为16+10101111(即关键词长2,2,3,3),含密文本45+中(关键词头的位置)+...。然后根据这组信息从文本库中查找符合条件的自然文本,如果找不到相应的组合就对关键词再次切分成更小的粒度。下面是实际情况,程序最后切分为的是中华人民,共和国,成,立了。对应的自然文本如图5a所示。
接收方接收到通过上述步骤发送的自然文本,采用上述同样的方法得到特征标签4,再根据标签4获得标签序列,根据第一个标签得到头文件信息:4,3,1,2。即后面含密文本中关键词的位置,根据位置和词长就得到了秘密信息。结果如图5b所示。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!