基于快速选取地标点的图像谱聚类方法与流程
本发明属于图像处理
技术领域:
,更进一步涉及图像聚类
技术领域:
中的一种基于快速选取地标点的图像谱聚类方法。本发明可用于对手写体数字图像、手写体英文字母图像等无标签图像进行自动聚类。
背景技术:
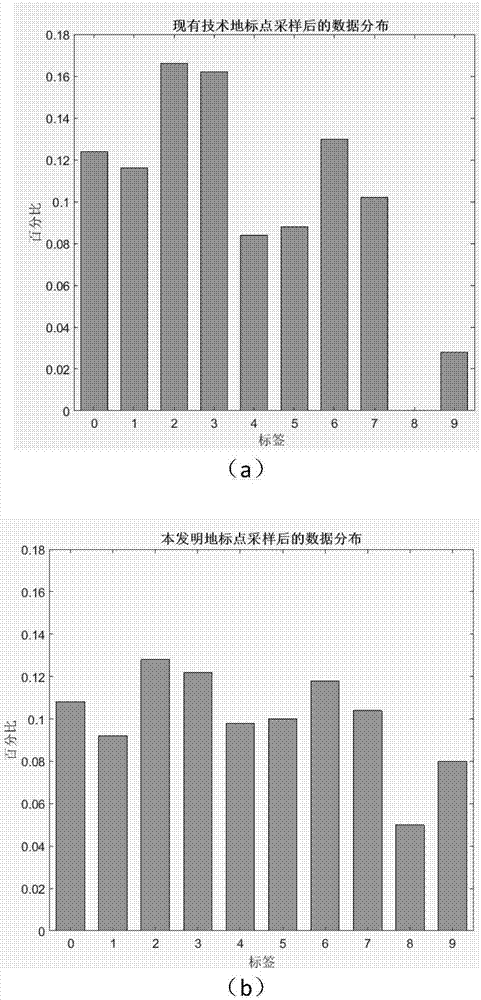
:聚类分析是机器学习与模式识别中一种重要的方法,是人们认识和探索事物之间内在联系的有效手段。它要求能按样本的特性来进行合理的分类,使得在同一簇中的对象之间具有较高的相似度,不同簇中的对象差别较大。传统的聚类算法如k均值算法、em算法等都是建立在凸球形的样本空间上。当样本空间不为凸时,算法会陷入局部最优解。谱聚类算法克服了k均值算法的缺点,能在任意形状的样本空间上聚类,而且实现简单,收敛于全局最优解。西安电子科技大学在其申请的专利文献“基于谱聚类的极化sar图像分类方法”(申请号:cn201210424175.6申请公开号:cn102982338b)中公开一种基于谱聚类的极化sar图像分类方法。该方法包括如下步骤:步骤1,对待分类的大小为r×q的极化sar图像进行滤波,去除斑点噪声;步骤2,对滤波后的极化sar图像每个像素点的相干矩阵进行cloude分解,提取每个像素的散射熵h特征,得到整幅图像的关于散射熵h的特征空间;步骤3,用meanshift算法对获取到的特征空间进行分割,得到m个区域;步骤4,在已获得的m个区域上,选取每个区域的典型代表点作为新的像素点yδ,δ=1,2,...,m得到m个新像素点,将这m个新像素点映射为具有m个节点的全连接图,并对这个全连接图进行谱聚类;步骤5,在m个区域上,将由新像素点yδ所代表的区域标记为与新像素点yδ相同的类别,完成对整幅图像的预分类;步骤6,对预分类得到的整幅图像用能反映极化sar分布特性的wishart分类器进行迭代分类,得到更为准确的分类结果。该方法存在的不足之处是:对sar图像进行谱聚类的时候,只是减少了输入图像特征的数量,该方法的运算量和存储量依旧很大。caid,chenx.等人在其发表的论文“largescalespectralclusteringvialandmark-basedsparserepresentation”(ieeetransactionsoncybernetics),45(8),1669-16802015)中提出了一种基于地标点稀疏表示的大尺度谱聚类方法。该方法的实现步骤是:步骤1,输入数据x和聚类数k;步骤2,在数据x中通过k均值聚类方法或者随机采样方法产生p个地标点;步骤3,将所述数据x基于所述p个地标点构建稀疏表示矩阵z;步骤4,根据所述稀疏表示矩阵z计算ztz的前k个特征向量a;步骤5,根据所述稀疏表示矩阵z计算z的右奇异向量得到ztz的前k个特征向量bt;步骤6,对特征向量bt的每一行通过k均值算法进行聚类,最终输出聚类结果。该方法存在的不足之处是,在选取图像作为地标点进行谱聚类时,选取的地标点受图像数据结构影响,导致图像数据分布信息损失,图像的稀疏表示误差大。技术实现要素:本发明的目的在于克服上述已有技术的不足,提出一种快速选取地标点的谱聚类方法。本发明选取的地标点分布均匀,能保留较多的图像数据分布信息,使得谱聚类结果的准确度更高。本发明实现上述目的的思路是:首先,读入待谱聚类的所有图像,计算其近邻图;其次,利用近邻图的边列表计算每个图像的度属性特征,去除噪声后,不断地从地标点的备选集合中选取最大度属性特征值对应的图像,移动到地标点集合之中,移除地标点的备选集合中该图像的所有近邻图;然后,构建稀疏表示矩阵,计算稀疏表示矩阵的相关矩阵和稀疏表示矩阵的右奇异矩阵;最后,利用k均值聚类法,对右奇异特征矩阵的每个元素进行聚类,得到右奇异特征矩阵每个元素的聚类标号,依次作为图像的谱聚类类别标号,输出图像的谱聚类结果。为了实现上述目的,本发明的具体实现步骤如下:(1)读取待谱聚类的所有的图像;(2)计算待谱聚类图像的近邻图:(2a)利用希尔弗曼经验法则,计算读取的所有图像所有近邻图的径向基核函数的带宽;(2b)利用径向基核函数公式,计算读取的所有图像的特征核矩阵的切片矩阵中的每一个值;(2c)将切片矩阵中每一行的所有元素按数值的大小降序排列,依照数值的大小将每一行的前位数值,加入到读取图像序号与切片矩阵行号对应的所读取图像的边列表,n表示读取的所有图像的总数,k表示读取的所有图像的类别数量;(3)选取地标点:(3a)将每个所读取图像的边列表中的所有数值相加后作为该图像的度属性特征值;(3b)将所有图像的度属性特征值按数值的大小降序排列,将后个度属性特征值对应的图像作为噪声图像,其余特征值对应的图像依次加入到地标点的备选集合中;(3c)从地标点的备选集合中选取最大度属性特征值对应的图像,移动到地标点集合之中,移除地标点的备选集合中该图像的所有近邻图;(3d)判断地标点的备选集合中是否还有图像,若是,则执行步骤(3c),否则,执行步骤(3e);(3e)依次读取被移除的所有近邻图,将其加入到地标点的备选集合中;(3f)判断地标点集合中图像总数是否为500个,若是,执行步骤(4),否则,执行步骤(3c);(4)计算待谱聚类图像的特征稀疏表示矩阵:(4a)利用特征相似度值权重公式,依次计算每一个待谱聚类图像和每一个地标点集合中图像特征相似度的权重值;(4b)将特征相似度权重值依次放入特征稀疏表示矩阵,得到待谱聚类图像的特征稀疏表示矩阵;(5)计算待谱聚类图像的相关矩阵:(5a)对稀疏表示矩阵进行归一化处理,得到归一化后的稀疏表示矩阵;(5b)将归一化的稀疏表示矩阵转置,用转置后的矩阵与稀疏表示矩阵相乘,得到待谱聚类图像的相关矩阵;(6)计算稀疏表示矩阵的右奇异特征矩阵:(6a)利用奇异值分解法,将相关矩阵进行特征值分解,得到相关矩阵的特征值和特征向量;(6b)将相关矩阵的特征值按数值的大小降序排列,将前k个特征值作为对角元素依次组成特征值矩阵,将前k个特征值对应的特征向量依次组成特征向量矩阵;(6c)利用右奇异特征矩阵公式,计算稀疏表示矩阵的右奇异特征矩阵;(7)识别聚类:(7a)利用k均值聚类法,对右奇异特征矩阵的每个元素进行聚类,得到右奇异特征矩阵每个元素的聚类标号;(7b)将右奇异特征矩阵每个元素的聚类标号,依次作为图像的谱聚类类别标号,输出图像的谱聚类结果。与现有技术相比,本发明具有以下优点:第一,由于本发明在选取地标点时,采用从地标点的备选集合中选取最大度属性特征值对应的图像的方法,克服了现有技术在选取地标点时受图像数据结构影响,图像数据分布信息损失的缺点,使得本发明提高了谱聚类结果的准确率。第二,由于本发明采用将所有图像的度属性特征值按数值的大小降序排列,将后个度属性特征值对应的图像作为噪声图像的方法,克服了现有技术在选取地标点时受噪声影响,选取不均匀的缺点,使得本发明降低了图像的稀疏表示误差。第三,由于本发明采用计算待谱聚类图像的相关矩阵的方法,将待谱聚类的图像特征的拉普拉斯矩阵的奇异值分解转换为相关矩阵的奇异值分解,克服了现有技术在对图像进行谱聚类时计算量大的缺点,使得本发明降低了计算复杂度,提高了谱聚类的处理速度。附图说明图1为本发明的流程图;图2为本发明的仿真图。具体实施方式下面结合附图对本发明做进一步的描述。参照附图1,本发明的具体步骤如下。步骤1,读取待谱聚类的所有的图像。步骤2,计算待谱聚类图像的近邻图。利用希尔弗曼经验法则,计算读取的所有图像所有近邻图的径向基核函数的带宽。所述的利用希尔弗曼经验法则的具体步骤如下:第1步,按照下式,计算读取的所有图像在同一个特征维度的标准差:其中,σh表示读取的所有图像在第h个特征维度的标准差,表示开方操作,n表示读取的所有图像的总数,∑表示求和操作,xjk表示所读取的第j个图像在第k个特征维度的值,μw表示读取的所有图像在第w个特征维度的平均值,h、k、w的取值对应相等。第2步,按照下式,计算读取的所有图像在所有特征维度的平均标准差:其中,表示读取的所有图像在所有特征维度的平均标准差,d表示读取的所有图像的特征维度的总数。第3步,按照下式,计算读取的所有图像的所有近邻图的径向基核函数的带宽:其中,σ表示读取的所有图像所有近邻图的径向基核函数的带宽。利用径向基核函数公式,计算读取的所有图像的特征核矩阵的切片矩阵中的每一个值。所述的径向基核函数公式如下:其中,k(s,t)表示读取的所有图像的特征核矩阵的切片矩阵中第s行第t列元素,e表示以自然常数为底数的指数操作,||||表示取模操作,xu表示所读取的第u个图像的特征,xv表示所读取的第v个图像的特征,u和s的取值对应相等,v和t的取值对应相等。将切片矩阵中每一行的所有元素按数值的大小降序排列,依照数值的大小将每一行的前位数值,加入到读取图像序号与切片矩阵行号对应的所读取图像的边列表,n表示读取的所有图像的总数,k表示读取的所有图像的类别数量。步骤3,选取地标点。第1步,将每个所读取图像的边列表中的所有数值相加后作为该图像的度属性特征值。第2步,将所有图像的度属性特征值按数值的大小降序排列,将后个度属性特征值对应的图像作为噪声图像,其余特征值对应的图像依次加入到地标点的备选集合中。第3步,从地标点的备选集合中选取最大度属性特征值对应的图像,移动到地标点集合之中,移除地标点的备选集合中该图像的所有近邻图。第4步,判断地标点的备选集合中是否还有图像,若是,则执行步骤第3步,否则,执行第5步。第5步,依次读取被移除的所有近邻图,将其加入到地标点的备选集合中。第6步,判断地标点集合中图像总数是否为500个,若是,执行步骤4,否则,执行本步骤的第3步。步骤4,计算待谱聚类图像的特征稀疏表示矩阵。利用特征相似度值权重公式,依次计算每一个待谱聚类图像和每一个地标点集合中图像特征相似度的权重值。将特征相似度权重值依次放入特征稀疏表示矩阵,得到待谱聚类图像的特征稀疏表示矩阵。所述的特征相似度值权重公式如下:其中,zfg表示第f个待谱聚类图像特征与第g个地标点集合中图像特征相似度的权重值,k(xf,ug)表示第f个待谱聚类图像中第xf个特征值与第g个地标点集合中图像第ug个特征值的相似度值,k(xf,ub)表示第f个待谱聚类图像中第xf个特征值与第b个地标点集合中图像第ub个特征值的相似度值。步骤5,计算待谱聚类图像的相关矩阵。对稀疏表示矩阵进行归一化处理,得到归一化后的稀疏表示矩阵。将归一化的稀疏表示矩阵转置,用转置后的矩阵与稀疏表示矩阵相乘,得到待谱聚类图像的相关矩阵。步骤6,计算稀疏表示矩阵的右奇异特征矩阵。利用奇异值分解法,将相关矩阵进行特征值分解,得到相关矩阵的特征值和特征向量。将相关矩阵的特征值按数值的大小降序排列,将前k个特征值作为对角元素依次组成特征值矩阵,将前k个特征值对应的特征向量依次组成特征向量矩阵。所述的右奇异特征矩阵公式如下:其中,b表示稀疏表示矩阵的右奇异特征矩阵,d表示特征值矩阵,a表示特征向量矩阵,t表示转置操作,表示归一化后的稀疏表示矩阵。利用右奇异特征矩阵公式,计算稀疏表示矩阵的右奇异特征矩阵。步骤7,识别聚类。利用k均值聚类法,对右奇异特征矩阵的每个元素进行聚类,得到右奇异特征矩阵每个元素的聚类标号。所述k均值聚类法的具体步骤如下:第1步,从右奇异特征矩阵中随机选择k个元素作为初始聚类中心,将每个聚类中心各自划分为一类。第2步,计算右奇异特征矩阵中所有元素到k个聚类中心值的距离。第3步,比较右奇异特征矩阵中每个元素到k个聚类中心值的距离,将每个元素最小值对应的聚类中心值类别标号赋予相应的元素,得到右奇异特征矩阵中每个元素的类别标号。第4步,计算右奇异特征矩阵中每类元素的平均值,得到新的聚类中心值。第5步,判断当前聚类中心值与原聚类中心值是否相同,若是,则得到右奇异特征矩阵每个元素的聚类标号;否则,执行第2步。将右奇异特征矩阵每个元素的聚类标号,依次作为图像的谱聚类类别标号,输出图像的谱聚类结果。下面结合仿真实验对本发明的效果做进一步的说明。1.仿真条件:本发明的仿真实验是在计算机硬件配置为intelcorei3-7100cpu@3.9ghz、8gbram的硬件环境和计算机软件配置为matlabr2016a的软件环境下进行的。测试对象为pendigits数据集、letterrec数据集、seismic数据集。pendigits数据集是由uci机器学习数据库提供的手写体数字数据集,该数据集由0~9数字构成,总共包含10992个手写数字图像,分为10类,每个图像有784个特征。letterrec数据集是由uci机器学习数据库提供的手写英文数据集,该数据集由a~z字母构成,总共包含20000个图像特征数据,分为26类,每个图像有16个特征。seismic数据集是由libsvm机器学习数据库提供的车辆数据集,总共包含98528个样本,分为3类,每个样本提取其50个特征。2.仿真内容与结果分析:仿真实验1:使用本发明的地标点采样方法和现有技术的快速选取代表子集的采样方法这两种方法对pendigits数据集进行地标点采样。如图2所示,其中:图2(a)是使用现有技术快速选取代表子集的采样方法对pendigits数据集采样后得到的数据分布图。图2(b)表示使用本发明地标点采样方法对pendigits数据集采样后得到的数据分布图。在图2(a)中,横坐标表示对应数字的标签,纵坐标表示快速选取代表子集的采样方法对pendigits数据集采样后标签所占的百分比。在图2(b)中,横坐标表示对应数字的标签,纵坐标表示本发明的地标点采样方法对pendigits数据集采样后标签所占的百分比。从图2(a)中可以看出,快速选取代表子集的采样方法采样后标签8的图像所占百分比为0%,从图2(b)中可以看出,本发明地标点采样方法采样后标签8的图像所占百分比为5%,因此本发明地标点采样方法采样后数据分布比快速选取代表子集的采样方法采样后的数据分布更加均匀。仿真实验2:使用本发明方法和现有技术的基于随机采样的地标点谱聚类算法(lsc-r)、基于k均值采样的地标点谱聚类算法(lsc-k)分别对数据集seismic、pendigits、letterrec进行仿真,采用两种度量标准比较不同方法的效果:准确率和标准化互信息。仿真2的仿真结果如表1和表2所示,其中:表1为使用本发明方法和现有技术的基于随机采样的地标点谱聚类算法(lsc-r)、基于k均值采样的地标点谱聚类算法(lsc-k)分别对数据集seismic、pendigits、letterrec进行谱聚类的准确率的一览表。表1仿真实验1中聚类数据集的准确率一览表(%)数据集lsc-rlsc-k本发明seismic67.5167.1468.03pendigits77.278.9683.66letterrec29.3830.6733.02由表1可见,本发明在seismic数据集的准确率为68.03%,pendigits数据集的准确率为83.66%,letterrec数据集的准确率为33.02%,由此得到的结论是,本发明在这三个数据集的准确率都要高于现有方法。表2为使用本发明方法和现有技术的基于随机采样的地标点谱聚类算法(lsc-r)、基于k均值采样的地标点谱聚类算法(lsc-k)分别对数据集seismic、pendigits、letterrec进行谱聚类的标准化互信息的一览表。表2仿真实验1中聚类数据集的标准化互信息一览表(%)数据集lsc-rlsc-k本发明seismic28.3428.524.27pendigits73.6575.9277.61letterrec38.1640.6541.7由表2可见,本发明在seismic数据集的标准化互信息为24.27%,pendigits数据集的标准化互信息为77.61%,letterrec数据集的标准化互信息为41.7%,由此得到的结论是,本发明在大部分数据集的标准化互信息都要高于现有方法。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1