一种基于全文检索的精确查找方法与流程
本发明属于信息检索领域,涉及一种基于全文检索的精确查找方法。
背景技术:
随着电子信息化的普及以及移动互联网的飞速发展,政府、高校、企业、网站等都积累了大量的数据,尤其政府、企业的部门之间可能会有多套电子办公系统;各个系统间都是独立的,用户有时需要在多个系统间进行切换来查找信息;这时不仅仅需要一个能够将这些信息连接起来的桥梁,并且能够让用户高效、准确的获取自己想要的信息。全文检索系统正是针对这些问题提供完善的解决方案。
全文检索只是针对输入的关键词进行检索查询,虽然相比关系数据库中的检索在数据规模和准确性上都有了很大提升。但是依然存在如下问题:
1)为了保证查全率而牺牲准确率,结果中包含了大量非用户需要的信息,例如:搜索苹果,如不加任何限定,会搜索出手机、电脑、水果相关等等;这样就是使得用户还需要在结果集中翻找自己想要的结果。
2)如果搜索的关键词没在索引中,则无法搜到结果,用户只能不停变换关键词进行检索。
3)全文检索用到的相似性匹配多数用到的是tf-idf或bm25等,这些比较常用的相似性算法在精确度上有时有些欠缺。
4)检索长句子时,只能按句子中包含的词进行检索,有时候返回的结果不一定是要表达的意思,例如:问句为“我们都不在老家,离婚手续怎么办?离婚手续可以在异地办理吗?”前五个结果中,有两条如下:
●律师你好,家庭暴力!他不给离婚手续怎么办?
●如果前妻坚持不办理离婚手续,我可以向法院要求按原协议判离吗?
可见这两条结果与原问句的主题并不一致。
技术实现要素:
根据上述的问题,本发明的目的在于提出一种基于全文检索的精确查找方法,本发明在全文检索的基础上结合了语义处理、再次相似性打分等处理。本发明减少用户反复更换检索词,提升信息查询的精度,节约用户的时间成本。该方法的主要思路为在语义上对检索关键词进行扩展,在得到的结果集中再与原句子进行二次相似度计算。
为了达到上述目的,采取如下方案:
一种基于全文检索的精确查找方法,其步骤包括:
1)从输入的查询语句中提取关键词,并对关键词进行扩展,得到关键词的扩展词;
2)根据该查询语句中的非关键词,关键词及其扩展词生成一布尔查询语句;
3)根据该布尔查询语句在全文检索库中进行检索,并选取与该布尔查询语句相关性最高的前n条检索结果;
4)将选取的每条检索结果分别与输入的所述查询语句进行语义相似度计算,并根据语义相似度计算得分对该n条检索结果重新排序。
进一步的,所述扩展词包括关键词的同义词、近义词、上位词和下位词。
进一步的,所述步骤4)中,进行语义相似度计算的方法为:
31)设t1为输入的查询语句,t2为该n条检索结果之一;根据t1的分词结果{w1,w2,w3,...,wl}生成t1的向量为:t1={w1,w2,w3,...,wl},根据t2的分词结果{w1,w2,w3,...,wm}生成t2的向量为:t2={w1,w2,w3,...,wm};取t1、t2向量的并集为t={w1,w2,w3,...,wn},n≤l+m;
32)令s1表示句子t1基于t计算的语义向量,s1={c11,c12,c13,...,c1n};其中,对于向量t中的每一个词wj,如果wj在向量t1中出现,则将wj在语义向量s1中的语义分数c1j设为1,否则将c1j设为设定值c;同理,计算句子t2基于t的语义向量s2={c21,c22,c23,...,c2n};
33)根据语义向量s2、s2计算t1、t2之间的语义句子相似度为:
进一步的,所述设定值c的取值为0.2或0。
进一步的,所述非关键词,关键词及其扩展词分别设置有对应的权重;在全文检索库中进行检索时,根据检索结果中的分词对应的权重计算检索结果的相似度;其中,关键词的权重>同义词的权重>非关键词的权重>近义词的权重>上位词的权重=下位词的权重。
进一步的,所述关键词的权重为4,所述同义词的权重为1.5,所述非关键词的权重为1。
现结合实例对本发明的处理流程进行描述:
1.对用户输入的短语或句子按如下顺序处理,分词、提取关键词、对关键词进行同义词/近义词/上下位词扩展。
例:句子”我们都不在老家,离婚手续怎么办?离婚手续可以在异地办理吗?”
(1)分词:["我们","都","不在","老家","离婚手续","离婚","手续","怎么办","怎么","离婚手续","离婚","手续","可以","在","异地办理","异地","办理","吗"]。
(2)提取关键词:["离婚手续","异地办理","离婚","手续"]
(3)对关键词进行扩展,这里只做同义词的扩展:
离婚手续:[](同义词为空)
异地办理:[](同义词为空)
离婚:["解除婚姻关系","婚姻关系解除"]
手续:["步骤","步调","步子"]。
2.可根据具体的需求对关键词、同义词/近义词/上下位词、非关键词(语句分词后,除关键词外的词)设置权重(权重大小的设置需根据实际测试结果而定,一般权重值大小为:关键词>同义词>非关键词>近义词>上位词/下位词,词权重越高对检索结果的相似度影响越大),并组成一条布尔查询语句。
例:继续使用步骤1中的分词、关键词、同义词等结果
(1)设置关键词、同义词、非关键词权重:
关键词:4
同义词:1.5
非关键词:1。
以上数值是根据多次实验后所得。词权重越高对检索结果的相似度影响越大:例如:词a权重为4,词b权重为1。检索结果中只有两条记录,两条记录的长度相等,记录1只命中了词a,记录2只命中了词b,则记录1的分数要高于记录2的分数。权重值只是最初为了在全文检索库中获取到更准确的结果集。
(2)组成布尔查询语句,关键词、同义词、非关键词之间都用“与”、“或”(即and或
or)连接。词的格式表示为:“词:权重值”,查询语句个的格式为:
这里关键词用kw表示,同义词用ks表示,非关键词用w表示:
((kw1orks1orks2orksn)orkw2orkwn))or(w1orw2orwn)
也可以有如下格式:
((kw1orks1orks2orksn)andkw2andkwn))and(w1orw2orwn)
上面的两种格式只给是出参考,具体使用or还是and需根据实际情况而定,不只局限于上面两种格式。
例:将步骤1中的问题转化为查询语句如下:
((离婚手续:4.0)or(异地办理:4.0)or(离婚:4.0or解除婚姻关系:1.5or婚姻关系解除:1.5)or(手续:4.0or步骤:1.5or步调:1.5or步子:1.5))or
(我们:1.0or都:1.0or不在:1.0or老家:1.0or怎么办:1.0or怎么:1.0or可以:1.0or在:1.0or异地:1.0or办理:1.0)。
该查询语句中,只是用了or连接,在本次试验的数据中使用or连接效果比较好。另外无论是“与、或”连接,词语的顺序对于查询结果和效率不会有影响。
3.使用步骤2中的查询条件在全文检索库中进行检索,并按全文检索库默认的相关性倒序排列。
4.取结果集中的前n条(如前40条)。每条结果与原始输入进行语义相似度计算,并按语义相似度计算得分对结果集按得分从高到低重新排序。
本发明中使用的语义相似度算法是基于语义句子相似度计算,基于语义句子相似度计算过程如下:
t1代表原始输入句子,t2代表检索出的结果之一,t1、t2的向量表示为:t1={w1,w2,w3,...,wl},t2={w1,w2,w3,...,wm},取t1、t2向量的并集为t={w1,w2,w3,...,wn},n<=l+m。
令s1={c11,c12,c13,...,c1n},s2={c21,c22,c23,...,c2n}。s1、s2表示句子t1和t2基于t计算的语义向量。
s1的计算过程如下:
(1)对于t中的每一个词wj,如果wj在t1中出现,则在语义向量s1中将wj的语义分数c1j设为1。
(2)如果t1中不包含wj,则计算wj在t1中的语义分数c1j=c(c为预先设定的阈值,无阈值设为0,本文中阈值为0.2)。
s2的计算过程与s1的计算过程原理一致。
t1、t2之间语义句子相似度为:
与现有技术相比,本发明的积极效果为:
本发明能够提高检索的精准度,在没有用户相关日志信息的情况下返回用户最想要的结果;本发明能够减少用户反复更换检索词,提升信息查询的精度,节约用户的时间成本。
附图说明
图1为自动问答系统的基本流程图;
图2为接收到问题后对问题的处理流程图。
具体实施方式
为了使本发明的目的、方案及优点更加清楚明白,以下参照附图并举例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
以自动问答系统平台为例,描述基于全文检索的语义检索具体实施,本发明不限于自动问答系统平台,可以扩展倒任何需要全文检索的系统中使用。
如附图1所示,为自动问答系统的基本流程,自动问答系统中核心部分是在全文检索基础上搭建的。用户输入问题,问答系统对问题进行理解并在问题全文索引库中进行检索,将问题的最佳答案返回给用户。
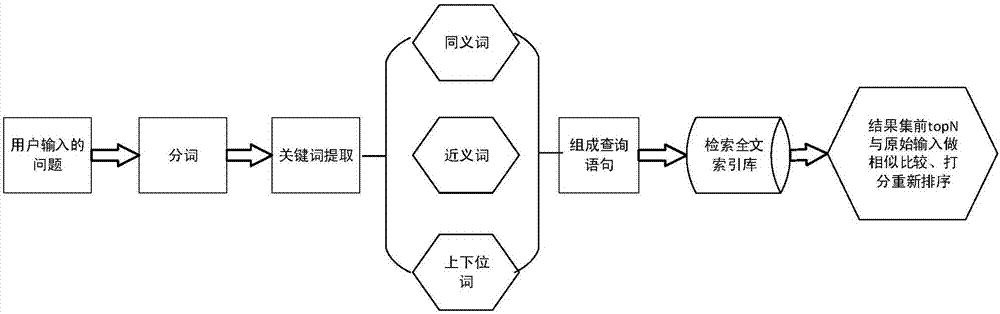
利用本发明可以在全文索引库中更精确找到匹配的问题并给出答案或提示。如附图2所示,接收到问题后对问题进行如下处理:
1.按相关领域的自定义词典对问题进行分词。
2.提取问句中的关键词(根据已有的相关专业的关键词典或关键词提取算法等,关键词提取方法不在本专利讨论范围。)。
3.对关键词进行同义词/近义词/上下位词扩展,并设置不同种类词所占的权重(同义词、近义词、上下位词都需要已有的相关专业词典)。
4.组成布尔查询语句,在问题索引库中对问题进行全文检索,利用全文检索自带的相关性分数进行倒序排列。
5.取检索结果中的前n条(如:提取前40条),并将结果集中每条的问题与原始问句做语义相似度计算,分值在0~1之间,值为1时为完全相同。语义相似度使用基于语义的句子相似度计算方法,具体的实现方法使用余玄定理来实现。
6.按新计算出的相似度分数排序并取出最佳的答案。
下面以检索一个问题为例,问题:"我们都不在老家,离婚手续怎么办?离婚手续可以在异地办理吗?",将分别进行普通全文检索与使用语义检索并重新计算相似度两种方式进行对比。
普通全文检索:取相关性分数最高的前5条,见表1:
表1为普通全文检索结果
语义检索:通过扩展检索词并重新计算相似度分数,结果见表2:
表2为本发明方法的检索结果
从上面的对比中可见,原问题主题为“异地离婚”,普通的全文检索只会按检索词进行匹配,获取的前5条结果中有两条是与“异地离婚”是无关的。而通过语义检索、与原始问句进行语义相似性计算排序后获取的前5条结果均是与“异地离婚”相关的。
以上所述仅为本发明的一个实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!