基于主题模型和机器学习的回答者推荐方法与流程
本发明涉及软件工程及机器学习领域,具体地,涉及一种基于主题模型和机器学习的回答者推荐方法。
背景技术:
随着问答社区的发展,越来越多的互联网用户通过问答社区获取所需信息。由于大型互动问答系统中每天产生大量的新问题,提问者不得不等待较长的时间,问题才能得到响应和解决;同时,回答者不得不在成千上万的未解决的问题中浏览查找自己感兴趣的问题回答,非常费时费力,从而利用回答者推荐方法来准确、快速地获取所需信息受到了越来越多的重视。
问答社区中问题回答者推荐问题,致力于解决问答社区中由于海量信息给提问者和回答者造成的困难,帮助问答社区中回答者便捷地得到自己感兴趣的问题,同时减少提问者问题得到解决的等待时间。根据问题的主题分类,利用主题相似性对问题感兴趣的回答者进行推荐,并进行相应回答的验证是比较容易实现的,绝大多数问答社区的回答者推荐都利用此类推荐方法进行验证。然而,该方法只能解决与问题主题相似的回答者进行推荐,但不能保证被推荐的回答者是否能够及时的回答提问者的问题,因此缺乏回答者推荐的有效性,以及问题被回答的可能性。本发明在考虑主题相似性的同时考虑了回答者的活跃度,并在原有的训练模型的语料库中加入了用户的评论信息,进一步精确了数据的分析精准度,基于对这两个方面的充分考虑,可以使得问题不仅为其推荐主题相似的回答者,而且该回答者最有可能回答该问题,从而可以减少问题得到解决的等待时间。
现有的基于stackoverflow问答社区进行回答者推荐的研究,例如yangliu等人提出的cqarank方法和jose等人提出的rankslda方法等,它们大都应用主题模型进行回答者推荐问题的研究工作。目前大部分回答者推荐模型只考虑了问题主题相似性、回答者专业知识,针对这两个因素进行相关的主题模型的研究,针对回答者的活跃程度在问答社区中也是一个重要的回答者推荐因素,然而已有的这些推荐方法不能做到活跃度这方面的回答者推荐,因此这些回答者推荐方法缺乏一定的有效性。
目前已经证明,已有的回答者推荐方法进行帮助问答社区中的问题推荐回答者以及提问者等待问题解决的时间的有效性和及时性存在问题。此外,现有的一些推荐方法的语料库缺乏用户评论信息的数据,从而导致回答者推荐的准确度有待提高,相比已有的推荐方法在回答者推荐方面的研究并不具备显著优势。
技术实现要素:
针对当前问答社区中涌现的大量新问题,使得回答者推荐方法复杂化、多样化等特点,以及现有的回答者推荐方法具有面向stackoverflow问答社区缺乏的有效性,现有推荐方法对语料库信息考虑的不够充分等问题,本发明提出一种基于主题模型和机器学习的回答者推荐方法。该方法可以较好地解决上述问题,使得针对主题模型和机器学习的回答者推荐方法能够应用到stackoverflow问答社区中,为新问题提供回答者推荐列表。
本发明是一种基于主题模型和机器学习的回答者推荐方法,具体包括如下步骤:
(一)基于扩展隐含的狄利克雷主题模型构建回答者推荐模型,所述回答者推荐模型包括三部分:用户的专业知识、用户的主题和用户的活跃度;包括如下步骤:
步骤1,从问答社区中获取历史数据,得到每个用户在各个时间段内的问答记录,问答记录内容包括提问信息、回答信息和评论信息,对问答记录内容清理后获得主题模型训练的语料库,根据语料库训练得到主题模型和问题标签特征;并利用回答者获得的投票数作为回答者的专业知识水平,利用用户访问问答社区的记录计算用户的活跃度;
步骤2,基于主题模型计算用户主题分布、主题词项分布、用户主题专业知识分布和用户主题活跃度分布;其中,用户主题分布表示为θu,k,用户主题专业知识分布为φk,u,e,用户主题活跃度分布为δk,u,a,主题词项分布为
步骤3,将为问题推荐回答者的问题转化为机器学习领域的分类问题,将步骤2所获得的概率分布转化为机器学习的特征向量,获得用户的主题特征、专业知识特征和活跃度特征;
步骤4,将主题特征、专业知识特征、活跃度特征和问题标签特征转化为特征向量,作为机器学习的输入,通过机器学习得到回答者推荐模型。
(二)利用回答者推荐模型为提问者推荐回答者;
步骤5,当问答社区中有提问者提出新的问题时,对该问题进行特征提取,获得问题主题的分布θq,k;
步骤6,利用回答者推荐模型获得问题回答者的推荐列表。
本发明的优点和积极效果在于:(1)本方法直观、简单、有效,在一定程度上解决了现有的回答者推荐方法在提问者等待问题解决时间和预料库信息考虑的缺乏导致有效性、准确性和及时性不高等问题;(2)本发明将问答社区中回答者的活跃度加入到主题模型中,对原有主题模型使用的语料库进行了丰富,同时将问答社区中用户的评论信息加入到机器学习进行训练的语料库中,能够更好的提高回答者推荐的有效性和可用性。(3)本发明根据推荐者的影响因素得到改进的主题模型,利用机器学习技术进行特征提取作为用户待推荐的标准,并且与现有的回答者推荐方法(如cqarank方法和rankslda方法)进行验证,验证了本发明方法实现的有效性、可用性和及时性。
附图说明
图1为本发明实施例的stackoverflow问答社区中提问帖子的示例图;
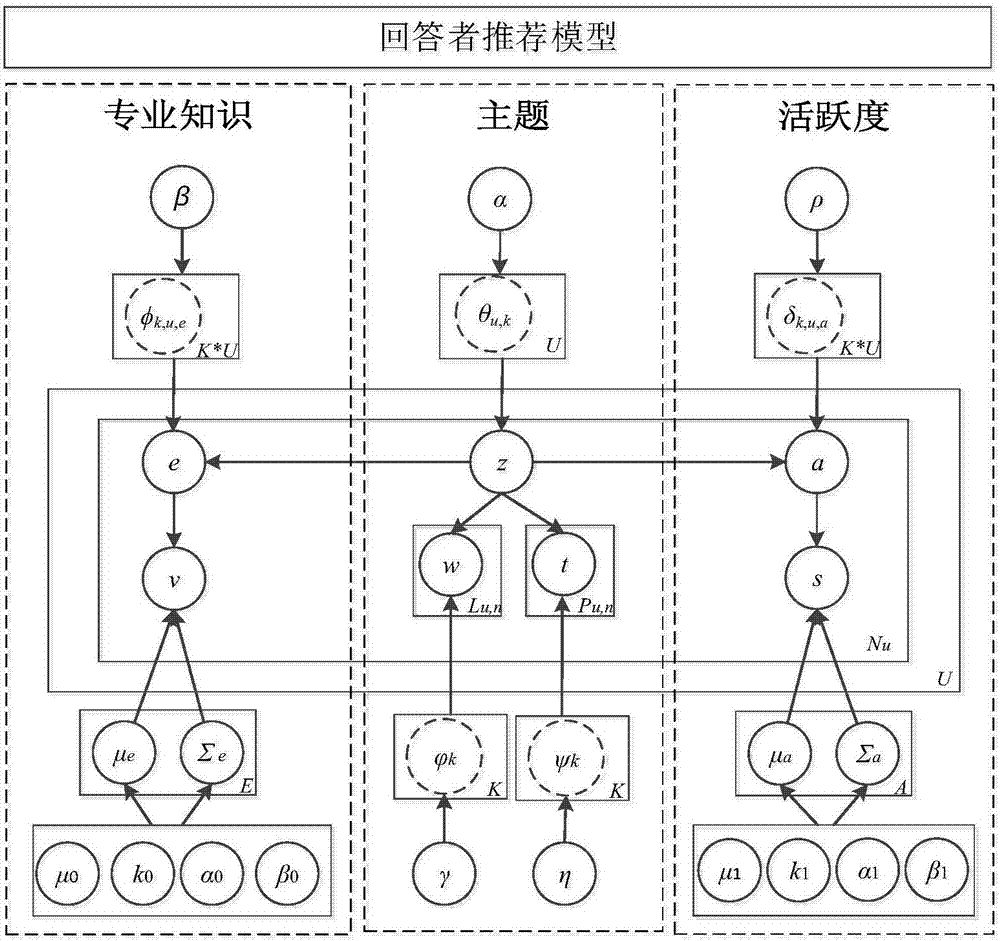
图2为本发明提供的回答者推荐模型示意图;
图3为本发明的回答者推荐方法的总体流程示意图。
具体实施方式
为便于本领域一般技术人员理解和实施本发明,现结合附图描述本发明的具体实施方式。
本发明结合stackoverflow问答社区为例来说明。stackoverflow是一个与程序相关的it技术问答社区。用户可以在问答社区中免费提交问题,浏览问题和回答,检索相关内容等。如图1所示,为本发明在stackoverflow问答社区中一个提问帖子的完整例子。在图1中,提问者chronotrigger提出了一个“getsizeofstd::arraywithoutaninstance”的问题,其他用户可以对该问题进行投票、评论以及回答(如投票数为37)。每个提问者需要对自己的问题进行加标签操作,便于stackoverflow问答社区对问题的管理和分类。回答者根据自己的兴趣可以找到与自己专业知识相关的问题进行回答,其他用户可以对其回答进行投票和评论。
本发明将为问题推荐回答者的问题转化为机器学习领域的分类问题,使得回答者利用机器学习技术对主题模型训练的语料库进行学习。首先如图2所示,本发明方法根据回答者的推荐特征,基于扩展隐含的狄利克雷主题模型(latentdirichletallocation,lda)建立了回答者推荐模型(topicexpertiseactivenessmodel,team)。
回答者推荐模型主要包括三个部分:回答者的专业知识、回答者的主题和回答者的活跃度。team模型是基于隐含的狄利克雷模型进行扩展得到的。首先,利用dirichlet分布计算主题模型分布,该分布包含两个因素:词语(word)和标签(tag);其次,根据专业知识的特征服从高斯分布,利用回答者获得的投票数作为回答者的专业知识水平并将其作为回答者主题专业知识分布的参数;最后,利用回答者访问stackoverflow问答社区的记录,计算回答者的活跃度,分析发现回答者的活跃度同样服从高斯分布,并将其作为回答者主题活跃度分布的参数。通过对上述三个部分进行建模,最终得到了回答者推荐模型,即team模型,如图2所示。下面表1给出了回答者推荐模型中所涉及的参数。
表1回答者推荐模型中参数的说明
下面说明回答者推荐模型中,回答者的专业知识、主题和活跃度的计算实现过程。
(一)回答者的专业知识。每个回答者的专业知识是由所提问题的用户进行投票得到的,从而通过投票来确定回答者的专业知识水平,用户可以投支持票和反对票,投支持票的用户越多则说明回答者的专业知识水平越高,因此服从高斯分布,反之亦然。
(二)每个回答者是根据用户主题进行分类的,而每个主题是根据帖子的词项和标签进行分类的,回答者的分类情况是根据帖子的词项和标签先将帖子分成不同主题,然后通过主题将回答者分配到相应主题的帖子进行问题回答。
(三)每个回答者在问答社区都有一定的活跃期,根据用户的访问记录的时间来确定回答者的活跃情况,从而根据访问时间来确定用户的活跃度,由于回答者访问问答社区存在两种情况:活跃和不活跃,如果回答者的访问问答社区某段时间内的次数越多,说明回答者在该段时间的活跃度越高,因此服从高斯分布,反正亦然。
本发明根据获得的每个回答者在某一时间段内发帖的历史记录,计算回答者的活跃度s,计算公式为:
其中,activeness表示用户操作的活跃度计算函数,
根据狄利克雷先验分布的参数α,β,ρ,参数的初始值可通过经验来设置,本发明实施例中设置α,β,ρ的初始值分别为0.5,0.01,0.01。通过吉布斯(gibbs)采样获取回答者推荐模型的后验分布。因此,得到的相应分布如下:
根据狄利克雷先验分布的参数α,同时在主题k下的回答者u的主题服从狄利克雷分布θu,k,并且根据主题将回答者进行分类,设主题数为k,从而可以得到回答者的主题分布。回答者的主题分布公式为:
其中,
根据狄利克雷先验分布的参数β,同时在主题k下的回答者u的专业知识服从狄利克雷分布φk,u,e,并且根据专业知识将回答者进行分类,专业知识水平为e,从而可以得到回答者主题的专业知识分布。回答者主题的专业知识分布公式为:
其中,
根据狄利克雷先验分布的参数ρ,同时在主题k下的回答者u的活跃度服从狄利克雷分布φk,u,a,并且根据活跃度将回答者进行分类,设活跃度共a个等级,从而可以得到回答者主题的活跃度分布。回答者主题的活跃度分布公式为:
其中,
为了得到回答者推荐方法,需要对回答者进行主题、专业知识和活跃度三个特征进行提取,从而得到回答者的主题特征、回答者的专业知识特征和回答者的活跃度特征。这三种特征分布的计算如下:
(1)根据回答者的主题分布θu,k和问题主题的分布θq,k,可以得到回答者对于新问题的主题相似性的特征分布θu,q。其分布公式为:
θu,q=θu,k×θq,k,k=1,2,…,k
其中,
(2)根据回答者的主题专业知识分布φe,k和问题主题的分布θq,k,可以得到回答者对于新问题的专业知识的特征分布φe,q。其分布公式为:
φe,q=φe,k×θq,k,k=1,2,...,k
其中,φe,k=max(φk,u,e)是指用户u最高的主题-专业知识分布。
(3)根据回答者的主题分布δa,k和问题主题的分布θq,k,可以得到回答者对于新问题的主题活跃度特征分布δa,q。其分布公式为:
δa,q=δa,k×θq,k,k=1,2,...,k
其中,δa,k=max(φk,u,a)是指用户u的最高的主题-活跃度分布。
如图3所示,为本发明的回答者推荐方法总体框架。该框架由两个阶段构成,其包括回答者的模型构建阶段和回答者的推荐阶段。详细步骤描述如下:
步骤1:在stackoverflow问答社区中获取用户的历史数据;
步骤2:对获得的历史数据进行预处理,从而整理得到每个用户在时间段内问答记录,问答记录内容包括提问信息、回答信息和评论信息,对文本信息进行去掉停顿词、不同时态词语归并等操作,获得主题模型训练的语料库;
步骤3:根据得到的语料库,进行训练得到主题模型(teammodel)和问题标签特征(questiontagfeature);
步骤4:本发明的回答者推荐方法中,结合stackoverflow问答社区的特点,确定提问者选择回答者的影响因素包括:回答者的主题、回答者的专业知识,回答者的活跃度。利用gibbs采样获得隐含变量的分配和主题模型参数的评估。根据狄利克雷先验分布的参数α,β,ρ,以及通过gibbs采样方法得到相应的后验分布,即用户主题分布(usertopicdistribution)、主题词项分布(topic-worddistribution)、用户主题专业知识分布(usertopicexpertisedistribution)和用户主题活跃度分布(usertopicactivenessdistribution);
步骤5:基于上述主题模型的概率分布进一步得到主题特征(topicfeature)、专业知识特征(expertisefeature)和活跃度特征(activenessfeature)。
步骤6:将模型构建过程中得到的主题特征、专业知识特征、活跃度特征和问题标签特征转化为特征向量,作为机器学习的输入,从而通过机器学习技术得到一种基于主题模型和机器学习的回答者推荐方法(answrec)。
步骤7:在回答者推荐阶段,提问者提出一个新问题时,首先对该问题进行特征提取,获得θq,k;
步骤8:利用回答者推荐方法answrec进行回答者推荐,得到一个关于所提问题的回答者推荐列表。
用本发明的回答者推荐方法来解决为从stackoverflow中获取的新的一组问题推荐回答者的问题,实验数据使用的是爬取的stackoverflow网站的用户post数据。通过回答者推荐方法输出对一个新问题进行回答的相关回答者的排名,根据用户需要得到一个排名前n的回答者列表,即得到一个与待推荐问题相关的并且能够及时回答问题的用户推荐列表。
- 还没有人留言评论。精彩留言会获得点赞!