一种基于数据挖掘的区域广告推送系统的制作方法
本发明涉及一种数据挖掘的景区广告推送系统,主要用于实现景区信息化领域的数据挖掘。
背景技术:
随着互联网的发展以及通讯设备的普及和更新,移动终端成为了人们不可或缺的设备,运营商的用户规模逐渐扩大。面对日益增加现有以及潜在的广告受众,越来越多的企业和广告商逐渐深入挖掘广告市场的价值。
借助于信息技术的高速发展以及存储技术的提高,使得人们获得的数据量急剧膨胀,数据逐渐成为企业和国家战略发展的重要资源。国内的电信行业所拥有庞大的用户数据,这些数据对电信行业来说是尚未彻底挖掘的重要资产和宝贵财富。如果对这些数据进行深入分析,往往可以从中获得大量有价值的信息,为企业带来一个又一个增长点。
目前,广告的投放主要对某一区域的人流量和基于内容的推荐,如在车流量多的收费站附近、广场、网吧以及其他人流量多的位置,通过大型的电子屏幕推送商业广告。这种投放方式是投放某种固定的广告,不能根据当前的用户属性和特征做出灵活地调整,降低了广告投放的效益。
当前比较主流的广告推荐技术主要是根据用户的浏览记录和关键词的搜索,根据这些信息将合适的广告推送给用户。通过对用户的上网日志进行挖掘,并分析出在搜索引擎上搜索的关键字或网页来给用户打上标签,当用户下一次登录到某个网页时,便在该网页的消息推送区把广告的关键字和链接推送给用户。
然而,这种推荐方法没有考虑到用户群体的分类,而没有针对某个人群的共同特征来针对性得进行广告投放,不能充分地反应用户的需求,同时也不能挖掘潜在的受众,用户也会对自己毫不感兴趣的广告产生反感,进而可能会关闭一个广告推送的渠道。
技术实现要素:
针对上述问题,本发明将区域用户特点与广告推送相结合,提出了一种基于数据挖掘的区域广告推送系统,通过对区域内用户的历史数据的分析和计算,建立准确有效的广告推荐模型,从而有效提高该区域及类似区域中的广告投放的精准度。
该系统包括数据采集模块、数据处理模块、算法分析模块和消息推送模块。
所述数据采集模块,采集用户在区域内的历史脱敏数据和广告的特征及关键字,并传输到所述数据处理模块。
所述数据处理模块,接收数据采集模块采集的数据,先清除无效的用户数据,所述无效的用户数据是指历史脱敏数据中失效的数据,再通过数据存储区,存储并预处理数据。
所述算法分析模块,提取所述数据处理模块中存储并预处理的脱敏数据进行运算分析,并将聚类的结果和广告特征进行匹配,形成广告推荐模型;其步骤为:
s1:分析该区域内用户的属性,针对其不同的数据类型选用合适的算法;
s2:结合三角不等式加速所述算法的收敛,对脱敏数据进行聚类分析,并将聚类的结果和广告特征进行匹配,从而建立广告推荐模型。
所述s1中针对其不同的数据类型选用合适的算法包括k-means、k-modes和k-prototypes算法。所述s2中结合三角不等式加速算法的收敛,对数据进行聚类分析,并将聚类的结果和广告特征进行匹配的方法为:
s21、将广告中的属性直接分类,并把该类的属性作为算法的聚类中心。
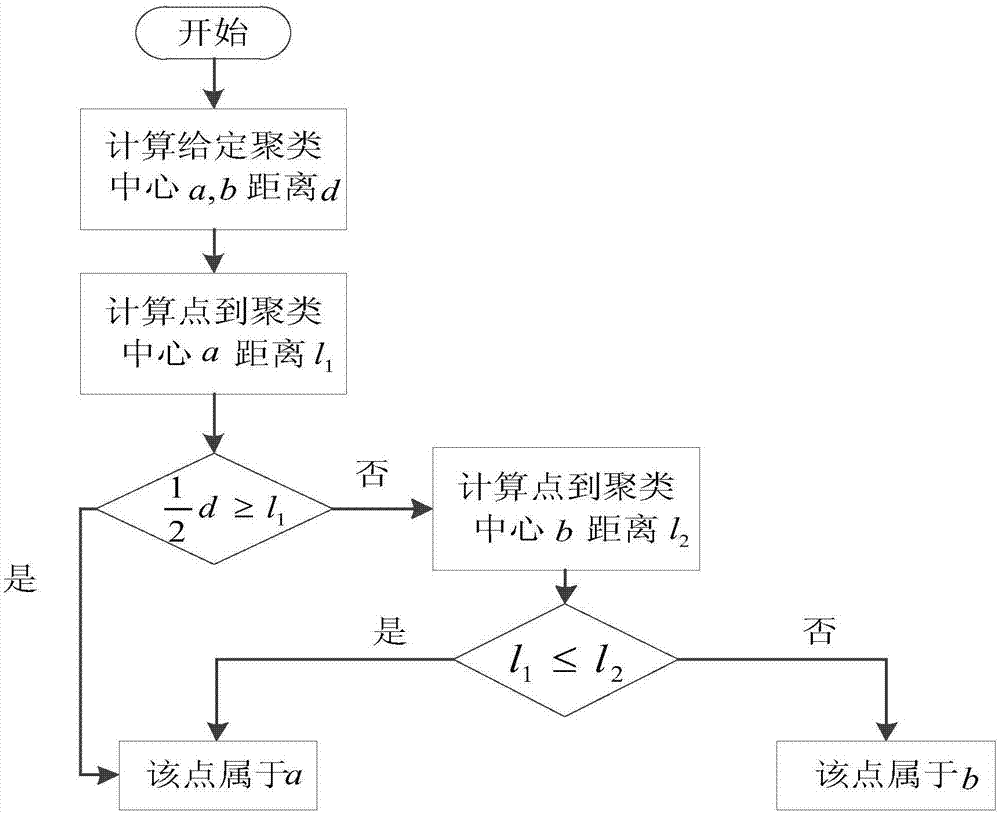
s22、对采集到的数据集进行聚类分析,首先计算一个聚类中心到另一个聚类中心的距离,记为d;
s23、计算一个点到距离为d的两个聚类中心中其中一个聚类中心a的距离,记为l1;
s24、判断
所述消息推送模块,包括推送模块和优化模块;所述推送模块,提取所述算法分析模块中形成的准确有效的广告推荐模型,对区域内的用户发送有针对性的广告;所述优化模块,用于反馈区域内用户的选择,优化并完善系统。
本发明的优点及有益效果:
本发明通过对特定区域内用户的历史脱敏数据及广告的基本属性进行运算分析,形成一个针对该特定区域准确有效的广告推荐模型,使对该区域或类似区域的用户进行的广告推送更具针对性和准确性,有效地挖掘出潜在的受众,提高投放的效益,为商家有针对性的推送广告及决定其他商业决策建立依据。同时,在运算分析中通过针对不同的数据类型,提供不同的聚类算法,并结合三角不等式加速算法的收敛,实现每个模块地精准计算。加入的优化模块,反馈区域内用户的选择,优化并完善系统。
附图说明
图1是系统整体的模块框图;
图2算法分析模块流程图。
具体实施方式
下面将结合发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
如图1所示,本发明提供了一种基于数据挖掘的区域广告推送系统,包括包括数据采集模块、数据处理模块、算法分析模块和消息推送模块。
数据采集模块用于采集运营商客户在区域内的历史脱敏数据和广告数据,包括:运营商客户数据标签的收集、广告特征及关键字的收集。运营商的客户数据采集:数据来自于运营商的用户脱敏信息,以及用户的标签。广告的特征及关键字收集:数据主要来自于广告商对广告属性的挖掘。运营商客户数据,主要包括用户的基本属性(手机号、年龄、性别、话费套餐)。用户的标签(消费水平、兴趣标签)。
所述的广告商数据,主要包括广告的类型、广告费用、关键字以及广告所面向的对象。
收集到的数据,在通过数据处理模块,先进行数据清洗,将运营商中的欠费超过半年的用户以及非个人移动号码进行清除,以保证数据的可靠性。再通过数据存储区,收集并预处理所述数据采集模块收集到的内容。
存储到数据处理模块的数据,再通过算法分析模块,先基于运营商用户的脱敏数据分析用户的属性,判断属于哪种数据类型,运用基于聚类算法,针对不同的数据类型选用包括k-means、k-modes和k-prototypes算法在内的合适的算法,对收集到的数据进行挖掘;根据用户的消费等级、标签、话费详单等信息,对整个区域的用户群体进行聚类分析,并结合三角不等式,计算一个点到距离为d的两个聚类中心中任意一个的距离,记为l1;如果d≥l1,则有该点到另外一个聚类中心的距离l2大于l1,因此不用计算l2;加速算法的收敛,从而建立准确有效的广告推荐模型,为商家有针对性的推送广告及决定其他商业决策建立依据。
该方法同时提高了算法的收敛速度,并可以处理整型、字符型和混合型数据。
最后由消息推送模块中的推送模块,根据所述算法分析模块中形成的一个准确有效的广告推荐模型,对区域内的用户发送有针对性的广告。而优化模块,则负责根据游客的选择及反馈,不断地对该系统进行优化,使得该系统不断完善,更好地向该区域内的用户进行个性化的广告推荐。
如图2所示,将聚类的结果和广告特征进行匹配的步骤为:
1.计算一个聚类中心a到另一个聚类中心b的距离,记为d;
2.计算一个点到距离为d的两个聚类中心中其中一个聚类中心a的距离,记为l1;
3.判断
- 还没有人留言评论。精彩留言会获得点赞!