一种基于关键字的XML检索排序处理系统及方法与流程
本发明涉及一种基于关键字的xml检索排序处理系统及方法,属于信息检索和xml数据管理领域,主要应用于对xml数据库查询和对查询结果进行数据处理。
背景技术:
关键字检索方式提供给用户友好、便捷的方式检索xml文档,用户只需提交关键字,无需掌握数据的模式信息,也不需要学习复杂的查询语法。针对www上的网页、办公文档等非结构化数据,google、百度、bing等搜索引擎提供了关键字检索功能,能够帮助用户在海量web数据中快速获取所需信息,已成为目前最受普通用户欢迎的互联网信息获取方式。xml已成为web上表示和交换数据的标准格式,各个领域不断涌现出大量的xml数据。如何有效检索满足用户意向的xml数据,已经成为当前数据库与信息检索领域中的研究热点。xml关键字检索方式,无需用户掌握查询语法与数据模式,仅提交关键字即可获取查询结果,深受普通用户欢迎。与传统信息检索中的关键字检索不同,xml关键字检索的目标不是整个xml文档,而是满足关键字条件的xml数据片段。如何根据关键字,快速、准确返回粒度适中且符合用户查询意向的xml结果片段,是xml关键字检索需要解决的基本问题。
用户在提交关键字检索xml文档时,通常希望获得的检索结果是具有相对完整信息的紧致片段,片段粒度过大不利于用户浏览,片段粒度过小不能满足用户的信息需求。将xml文档树划分为符合用户意向、相对独立、粒度适中的片段以便用户检索,为xml关键字检索提供了新的思路。
为提高基于slca语义的检索结果的准确度,研究人员尝试在slca语义基础之上,进行适当改进以达到目的。y.li(参见y.li,c.yu,h.v.jagadish,enablingschema-freexquerywithmeaningfulqueryfocus,vldbj.,2008,17(3),pp.72–84.)提出了mlca(meaningfullowestcommonancestor,有意义的最低公共祖先)利用xml模式信息来提高查询结果的准确性。黄静(参见黄静,徐俊劲,周军锋,孟小峰.mlcea:一种基于实体的xml关键字查询语义.计算机研究与发展,第45卷(增刊):372-377,2008.10)提出了mlcea(meaningfullowestcommonentityancestor,有意义的最低公共实体祖先)语义以实体作为基本语义单元,要求求取的slca节点为实体节点,并排除关键字对应多个同名实体的不同属性的情况,提高查询结果准确性。g.li(参见g.li,j.feng,j.wang,l.zhou,efficientkeywordsearchforvaluablelcasoverxmldocuments,in:proceedingsofthe16thacmconferenceoninformationandknowledgemanagement(cikm2007),2007,pp.31–40.)提出了vlca(valuablelowestcommonancestor,有价值的最低公共祖先)语义,通过语义信息过滤掉不相关结果,提高查询结果的准确性。z.liu(参见z.liu,y.chen,identifyingmeaningfulreturninformationforxmlkeywordsearch,in:proceedingsoftheacmsigmodinternationalconferenceonmanagementofdata(sigmod2007),2007,pp.329–340.)提出了xseek将xml树节点分为实体结点、属性节点和连接节点,利用用户输入的关键字推测用户查询意向,从而提高结果准确性。
针对关于xml关键字查询的排序方法,lil(参见lil,leeml,hsuwe.etal.apruferbasedapproachtoprocesstop-kqueriesinxml[c]//proceedingsofthedexaconference,2009:348-355)提出了xpram方法,即将松弛与序列匹配过程相结合,在匹配过程中使用边泛化、叶子删除、子树提升的松弛方法来获得top-k结果。lij(参见lijx,liucf,etal.efficienttop-ksearchacrossheterogeneousxmldatasource[c]//proceedingsofthedasfaaconference,lncs4947.2008:314-329)提出了一种关键字top-k查询方法,该方法通过约束阈值的策略跳过不符合用户偏好的文档,并且基于中间结果在每一个访问过的文档删减侯选结果。baozf(参见baozf,lingtw,chenb,etal.effectivexmlkeywordsearchwithrelevanceorientedranking[c]//proceedingsoftheicdeconference.2009:517-528)提出了一种ir-style方式,其主要利用潜在的xml数据统计来解决文本数据库和xml数据库导致的用户查询意图的鉴定;关键字歧义问题和计分功能的实现。张雷(参见张雷.xml关键字查询中最紧致片段问题的研究[d].济南:山东大学,2009)提出了xml数据库中支持top-k的关键字查询方法,将关键字查询评估降低到关系的合并范围,并引入了关键字top-k合并的思想。
目前现有的xml检索方法一般是基于slca语义进行的,基于slca语义会造成结果的损失,主要是结果的粒度过大或者过小和单关键字结果查询情况不好。关键字越少,slca语义的查询结果越容易出现结果粒度和返回无意义信息结果问题。现有的xml查询结果排序方法由于基于slca语义所以结果粒度差异较大,一般只会考虑关键字节点和slca节点之间的结构关系,不会考虑在固定范围粒度的情况下关键字节点之间的关系和返回结果的层次,返回得到的结果比较不准确,而且不能排除返回结果粒度问题。
技术实现要素:
本发明的技术解决问题:克服现有技术的不足,提供基于关键字的xml检索排序处理系统及方法,可以根据所检索关键字准确提供粒度适当,结构合理的xml返回结果,并对多个返回结果进行适当排序,排序后的可根据用户需求筛选出结构更加紧凑,语义更加完整,更加符合用户查询的结果,返回结果的准确性有了提升的同时也可以根据用户的需求,固定返回查询结果的个数。
本发明的技术解决方案:一种基于关键字的xml检索排序系统,如图1所示包括:
基本语义节点单元筛选模块:将需要查找关键字的xml文档数据库,抽象为g=(v,e,r,a),g为xml文档对应的xml数据树,其中v表示g中所有节点的集合,e表示g中所有边的集合,r表示g的根节点,a是所有节点所带标签的集合;对g中的节点进行分析,计算g中每一个节点的规模数和包含的属性类型数,基于g中的节点的规模数和节点的属性类型数以及节点的标签,把xml数据树的节点以同样标签进行整合,统计同标签节点的平均规模数表和同标签节点的平均属性类型数表,根据节点平均规模数表和节点平均属性类型数表设定节点平均属性类型数阈值下界和节点平均规模数阈值下界,在节点平均规模数表和节点平均属性类型表中同时高于两个阈值下界的节点即为基本语义节点,得到基本语义节点集合,将基本语义节点集合存放在结果文件中,供文档语义分割模块调用;
文档语义分割模块:对xml文档数据库以基本语义节点集合为基础进文档语义分割,以结果文件中的基本语义节点为中心,对xml数据树中的其他节点进行分析归类,对基本语义节点的临近节点进行优先归类分析,继而分析临近节点的临近节点,分割xml数据树,每一个分割后的xml数据集合即是一个以基本语义节点为中心的基本语义单元,整理每个基本语义单元,即得到基本语义单元集合,把基本语义单元集合输出至关键字检索模块;
关键字检索模块:给定w={ωi|i=1,...,k}为待查询关键字组成的关键字集合,其中ωi为待查询关键字,i代表第i个关键字,关键字一共有k个,按照w中的顺序取关键字,选取一个关键字对基本语义单元集合进行倒排索引,得到回答某一关键字的基本语义单元集合,遍历w中所有关键字,得到包含全部关键字的基本语义单元集合,把能够回答所有关键字的基本语义单元集合按照关键字顺序存入临时结果文件传给单元结构分析模块;
单元结构分析模块:接收关键字检索模块中的临时结果文件,遍历基本语义单元集合,每一个元素均为一个以基本语义节点为中心的基本语义单元,取一个基本语义单元,以其基本语义节点为中心,保留返回的关键字节点,和基本语义节点与关键字路径上的节点,删除其余节点,得到基本语义节点和关键字节点之间的小枝结构关系,对基本语义单元集合中每一个元素都进行此操作,得到每一个基本语义单元中基本语义节点与关键字之间的结构关系集合,将集合储存在临时结果文件中传送给语义加权模块;
语义加权模块:遍历临时结果文件中的基本语义节点与关键字之间的结构关系集合,分析集合中每一个元素的重要性,对元素中结构树的每一个节点进行加权计算,并将每一个结构树加权计算的结果存入数组中,并把语义重要性加权数组传递至结果筛选模块;
结果筛选模块:接收语义加权模块输入的语义重要性加权数组,对语义重要性加权数组进行排序操作,对结构关系的重要性程度按照从大到小的顺序排列,数组中排位越靠前,即为结构关系最严格,最为符合用户检索意图,输入用户所需检索结果的个数,根据用户的需求,对已经排序完成的数组按数组顺序输出符合用户指定个数的检索xml基本语义单元,即为用户所求的检索结果。
所述的基本语义节点单元筛选模块实现过程如下:
(1)对xml标签有向树中所有节点进行遍历,对各节点进行编码,设节点v为xml标签树中的一个节点,则对v进行区间编码(prev,level,size),其中prev为其先序编码,level为节点v在该xml文档中所属层数,size为节点v的后裔节点数,即得到该节点的规模数值。
(2)根据遍历后的节点编码结果计算各节点的平均属性类型数和节点平均规模数。其中节点平均属性类型数为该类型节点的子节点的属性类型数除以该类型节点的节点数,节点平均规模数为该类型节点的平均规模数除以该类型节点的节点数。可得到该xml文档节点的平均属性类型数表和平均节点规模数表。
(3)根据得到的平均属性类型数表和节点平均规模数表,设定平均属性类型数阈值下界和节点的平均规模数阈值下界。并根据阈值下界对两个表中的数据进行筛选。得到大于平均属性类型数阈值下界的节点集合和大于平均规模数阈值下界节点的集合。对两个集合的节点取交集,如果交集中有连接节点则去掉连接节点。
(4)取交集生成的集合即为此xml文档的基本语义节点集合。
所述的文档语义分割模块实现过程如下:
(1)读取基本语义节点集合,取其中一个节点p,获取以p为中心的基本语义单元;
(2)节点p为根的子树为st(p),如果节点p的后裔节点中存在其他基本语义节点,断开其他基本语义节点与st(p)树的父子关系边,得到子树st′(a);
(3)已知节点p的编号路径,若节点p的祖先节点中存在其他基本语义节点,则连接其他基本语言节点到节点p的编号路径上的所有节点到st′(p)得到st″(p),若节点p的祖先节点中不存在其他基本语义节点,则连接根节点到节点p上的所有节点到st′(p)得到st″(p),则st″(p)为节点p对应的基本语义单元;
(4)遍历基本语义节点集合中的所有节点,即获取以基本语义节点为中心的基本语义集合。
所述的关键字检索模块实现过程如下:
(1)初始化结果集合为空集,以基本语义单元集合为元素建立倒排索引。索引项为<prev,keyword>,prev为基本语义单元中对应基本语义节点的先序编号,keyword为关键字序号;
(2)扫描关键字倒排索引分别获取匹配每个关键字的基本语义集合,对于确定的关键字,有对应的基本语义单元,对于关键字集合,就有对应每个关键字不同的基本语义单元集合;
(3)获取各个语义单元集合中各元素的交集,因为在获取基本语义单元集合时关键字倒排索引为前向遍历,所以基本语义单元集合中符合关键字搜索结果的元素都已按照前序编号排列,具体如下:
(3.1)计算基本语义单元集合内部的元素个数,即集合内部元素数量将按照集合内元素数量升序排列;
(3.2)取排序之后集合内部元素个数最少的基本语义单元集合,顺序遍历集合中的所有元素,判断每个元素在是否存在于其他的语义单元集合中,把存在于所有的语义单元集合中的元素存入结果集合;
(4)该基本语义节点集合对应的基本语义单元集合即为回答关键字查询的基本语义单元集合。
所述的语义加权模块实现过程如下:
根据节点结构关系树对检索结果进行排序。节点的位置信息可以衡量该节点能否直接,明确地描述xml数据,一个节点对xml数据的区分能力越强,则子树的权重越大。节点之间的紧密度可以描述节点之间的相关程度,在基本语义单元节点结构关系树中,各个关键字节点对应的结构越紧密,对应的查询结果应该越符合用户的查询意图。
节点之间的距离可以表示节点之间的相关度,距离越短则节点之间的相关度越高,如果在基本语义单元中,关键字匹配节点之间的距离越短证明该单元中关键字匹配节点之间的关系越紧密。对于节点的位置信息,通常认为,越接近根节点的节点越能够直接描述该xml文档,该节点对文档的贡献也就越大,越接近文档本身的表述内容。
根据对基本语义单元节点结构树的分析,得出影响一个基本语义单元重要程度的几个因素。
(1)基本语义节点和关键字节点的层级可以影响该基本语义单元对xml文档的描述程度。不同的xml数据结构中同样的节点因其表示内容的不同而具有了不同的权重。一个节点层次越低,即该节点越靠近根节点,就表示该节点对xml数据区分能力越强,则对应的基本语义单元越能够描述文档主要内容,该单元所占权重越大。其权重可以表示为:
d(v)为单元的层级权重,
(2)关键字节点之间的距离可以用来衡量节点之间的相关度。关键字节点之间的距离可以表示节点之间的相关度,距离越短相关度越高,相关度会影响关键字检索结果的权重,关键字之间相关度越高,检索权重应越高。其权重为:
式中r1(v)为单元的关键字严格程度的权重,θ为调节因子,i和j代表第i个关键字和第j个关键字,且有i≠j,k表示关键字的数量,d(wi→wj)表示各关键字节点之间的距离。
(3)关键字节点与基本语义节点之间的距离。基本语义单元结构越紧密,关键字节点与基本语义节点之间的距离越小,该单元节点之间的相关度越高,就越能对查询内容进行描述,其权重应该越高。其权重可以表示为:
式中r2(v)为关键字与基本语义单元之间严格程度的权重,θ为调节因子,i代表第i个关键字,k表示关键字的数量,d(v→wi)表示各关键字节点到基本语义节点之间的距离。
基于以上描述的影响基本语义单元中关键字权重的因素,把基本语义单元在xml数据指定关键字查询中的权重表示为:
rank(v)=d(v)×r1(v)×r2(v)
rank(v)为基本语义单元中关键字的权重。将求得的基本语义单元结构导入关键字的权重模型进行计算,即可得到基本语义单元基于关键字的语义加权。
本发明的一种基于关键字的xml检索排序处理方法,包括:基本语义节点单元筛选、文档语义分割、关键字检索、单元结构分析、语义加权模块和结果筛选步骤;其中:
基本语义节点单元筛选步骤:将需要查找关键字的xml文档数据库,抽象为g=(v,e,r,a),g为xml文档对应的xml数据树,其中v表示g中所有节点的集合,e表示g中所有边的集合,r表示g的根节点,a是所有节点所带标签的集合;对g中的节点进行分析,计算g中每一个节点的规模数和包含的属性类型数,基于g中的节点的规模数和节点的属性类型数以及节点的标签,把xml数据树的节点以同样标签进行整合,统计同标签节点的平均规模数表和同标签节点的平均属性类型数表,根据节点平均规模数表和节点平均属性类型数表设定节点平均属性类型数阈值下界和节点平均规模数阈值下界,在节点平均规模数表和节点平均属性类型表中同时高于两个阈值下界的节点即为基本语义节点,得到基本语义节点集合,将基本语义节点集合存放在结果文件中,供文档语义分割步骤调用;
文档语义分割步骤:对xml文档数据库以基本语义节点集合为基础进文档语义分割,以结果文件中的基本语义节点为中心,对xml数据树中的其他节点进行分析归类,对基本语义节点的临近节点进行优先归类分析,继而分析临近节点的临近节点,分割xml数据树,每一个分割后的xml数据集合即是一个以基本语义节点为中心的基本语义单元,整理每个基本语义单元,即得到基本语义单元集合;
关键字检索步骤:给定w={ωi|i=1,...,k}为待查询关键字组成的关键字集合,其中ωi为待查询关键字,i代表第i个关键字,关键字一共有k个,按照w中的顺序取关键字,选取一个关键字对基本语义单元集合进行倒排索引,得到回答某一关键字的基本语义单元集合,遍历w中所有关键字,得到包含全部关键字的基本语义单元集合,把能够回答所有关键字的基本语义单元集合按照关键字顺序存入临时结果文件;
单元结构分析步骤:针对临时结果文件,遍历基本语义单元集合,每一个元素均为一个以基本语义节点为中心的基本语义单元,取一个基本语义单元,以其基本语义节点为中心,保留返回的关键字节点,和基本语义节点与关键字路径上的节点,删除其余节点,得到基本语义节点和关键字节点之间的小枝结构关系,对基本语义单元集合中每一个元素都进行此操作,得到每一个基本语义单元中基本语义节点与关键字之间的结构关系集合,将集合储存在临时结果文件中;
语义加权步骤:遍历临时结果文件中的基本语义节点与关键字之间的结构关系集合,分析集合中每一个元素的重要性,对元素中结构树的每一个节点进行加权计算,并将每一个结构树加权计算的结果存入数组中,得到语义重要性加权数组;
结果筛选模块:接收语义加权模块输入的语义重要性加权数组,对语义重要性加权数组进行排序操作,对结构关系的重要性程度按照从大到小的顺序排列,数组中排位越靠前,即为结构关系最严格,最为符合用户检索意图;输入用户所需检索结果的个数,根据用户的需求,对已经排序完成的数组按数组顺序输出符合用户指定个数的检索xml基本语义单元,即为用户所求的检索结果。
本发明与现有技术相比的优点在于:
(1)本发明以基本语义单元为单位进行xml关键字的检索,与传统的基于slca的ile方法相比,返回结果相对独立,粒度更加适中,信息更加完整,尤其在xml文档层次较深,结构较复杂时,返回查询结果能够更好地符合用户的查询意图。
(2)本发明建立了对返回结果严格程度的模型,与已有的严格程度计算方法相比,更加准确地描述了返回结果的严格程度,可以进一步对返回结果进行筛选,并筛选出冗余信息过多的查询结果,使返回结果按照用户查询意图的符合程度进行排序,进一步贴近了用户的查询意图。
附图说明
图1为本发明系统的体系结构图;
图2为本发明系统中的基本语义筛选模块实现过程;
图3为本发明系统中的文档语义分割模块实现过程;
图4为本发明系统中的关键字检索模块实现过程;
图5为本发明系统中的单元结构分析模块实现过程;
图6为本发明的语义加权模块实现过程。
具体实施方式
为了更好地理解本发明,先对一些基本概念进行一下解释说明:
xml标签有向树:xml数据包含的信息可分为两部分,一为内容,由xml数据中包含的text文本及属性值组成,二为结构信息,由xml数据的标签间的嵌套关系组成。因此,待查询xml文档可被抽象成xml标签有向树模型,g=(v,e,r,a),其中v表示g中所有节点的集合,e表示g中所有边的集合,r表示g的根节点,a是所有节点所带标签的集合。
节点编号路径:path(v)为节点编号路径函数,用来获取节点v从根节点r到v的节点编号路径,根节点r的编号路径为1。目标节点到根节点路径上节点编号的集合即为节点编号路径。
片段编号路径:设目标节点a和目标节点有祖先后裔关系,目标节点a到目标节点b的路径上的节点的编号集合即为片段编号路径。
叶子节点:xml文档最底层节点,叶子节点无孩子节点。
属性节点:xml文档中只有一个叶子节点为孩子节点的节点即为属性节点。
组属性节点:xml文档中节点如果有多个孩子节点,但孩子节点均为同类型节点,该节点即为组属性节点。
连接节点:在xml文档中只起到连接作用的节点即为连接节点。
节点规模:节点在xml标签树中所含有的后裔节点个数。
节点属性类型:节点在xml标签中含有的后裔节点的属性的类型数,其中组属性类型节点算做一个节点类型。
平均节点规模数:节点类型相同的节点的后裔节点个数相加除以节点个数,即为该类型节点的平均节点规模数。
平均属性类型数:节点类型相同的节点属性类型数相加除以节点个数,即为该类型节点的平均属性类型数。
基本语义节点:xml文档中节点大于设定的平均属性类型数和平均节点规模数的节点可以被称为基本语义节点。
基本语义单元:以基本语义节点为中心建立的语义片段。具体过程为,首先以基本语义节点为根取其子树,如果其后裔节点中存在其他基本语义节点,舍去以其他基本语义节点为根的子树;其次找到该基本语义节点的节点编号路径加入到子树中去,如果其节点编号路径上有其他基本语义节点,则取该基本语义节点与选定语义节点的片段路径加入到子树中去。经过以上两步即形成了基本语义单元。
节点结构关系树:以基本语义单元为单位,删除不在关键字到基本语义节点片段路径上的节点,即得到对应该基本语义单元的节点结构关系树。
节点距离:对于给定的节点v1和v2,如果v1和v2具有祖先后代关系,它们之间的距离可以表示为连接两个节点之间最短路径上边的数量,如果v1和v2之间不具有祖先后代关系,则它们之间的距离可以表示为d(v1→v2)=d(v→v1)+d(v→v2)。
节点层级:对于给定的节点v1和v2,其中v1是v2的祖先节点,则节点v2的层级为节点v1的层级与节点v1和v2之间距离的和(根节点的层级为1):
下面结合附图对本发明进行详细说明。
如图1所示,本发明涉及一种基于关键字的xml检索排序处理系统及方法,该系统及方法可用于对xml数据基于关键字的检索,并对检索结果进行排序,可使基于关键字的xml返回粒度更合适,更符合用户查询意图的结果,在xml文档检索方面提出了一种新的解决方案。所述系统由6个模块组成:基本语义节点筛选模块,文档语义分割模块,关键字检索模块,单元结构分析模块,语义加权模块以及结果筛选模块。这种方法克服了原本基于slca结构关键字查询方法返回结果粒度不合适,易返回粒度过大的不相关结果和单关键字返回结果效果不好的缺点,可以更加准确地返回粒度适中,相对独立,比较符合用户意图的语义片段。对xml结果进行排序使用户可以选择返回固定个数的查询结果,进一步提高了查询的准确率,较好地满足了用户的偏好。
整个实现过程如下:
(1)已知给定了需要查找关键字的xml文档,对文档中节点进行分析,计算g中每一个节点的规模数和包含的属性类型数,统计同标签节点的平均规模数表和同标签节点的平均属性类型数表,根据节点平均规模数表和节点平均属性类型数表设定节点平均属性类型数阈值下界和节点平均规模数阈值下界,在节点平均规模数表和节点平均属性类型表中同时高于两个阈值下界的节点即为基本语义节点,供文档语义分割模块调用;
(2)以结果解析文件中的基本语义节点为中心,对xml文档树中的其他节点进行分析归类,得到分割后的xml文档数据,每一个分割后的集合即为以一个基本语义节点为中心的基本语义单元,把基本语义单元集合输出至关键字检索模块;
(3)以得到的基本语义单元集合中的每一项为基本单元创建倒排索引,检查每一个基本语义单元是否可以回答关键字检索。对基本语义单元集合q进行倒排索引,得到回答关键字集合的基本语义单元集合di,取集合d1,d2,…,dk中元素的集合保存,集合s即为包含全部关键字的基本语义单元集合,把可以回答所有关键字的基本语义单元集合s存入临时结果文件传给单元结构分析模块;
(4)接收关键字检索模块中的临时结果文件,取一个基本语义单元,以其基本语义节点为中心,保留返回的关键字节点,和基本语义节点与关键字路径上的节点,删除其余节点,得到基本语义节点和关键字节点之间的小枝结构关系。将结果储存在临时结果文件中传送给语义加权模块;
(5)遍历临时结果文件中的基本语义节点与关键字之间的结构关系集合,对元素中结构树的每一个节点进行加权计算,并将每一个结构树加权计算的结果存入数组中,把映射关系和语义重要性加权数组传递给结果筛选模块;
(6)接收语义加权模块输入的语义重要性加权数组和映射关系,对数组进行排序操作,对结构关系的重要性程度按照从大到小的顺序排列。数组前几位所对应的基本语义单元和其他基本语义单元相比,结构更加合理,也更加符合用户的检索意图。
上述各模块实现功能如下:
1.基本语义节点筛选模块
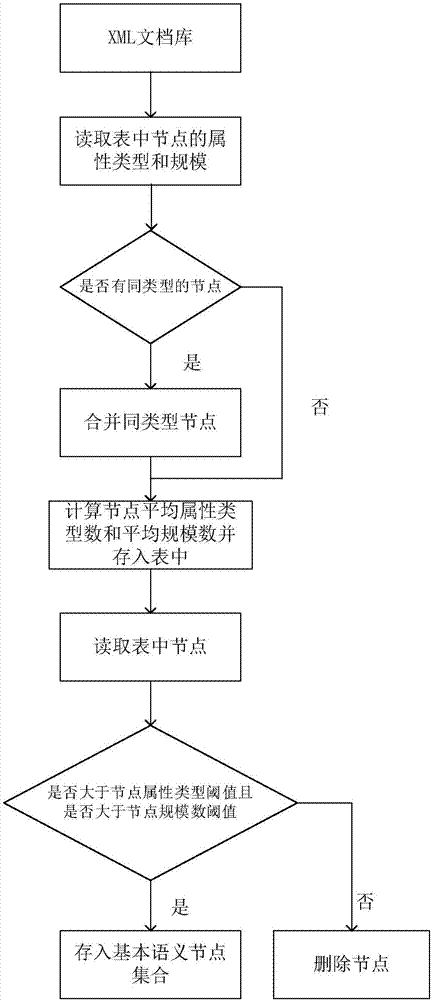
该模块的实现过程如图2所示:
(1)从文件中读取xml文档数据库,生成对应的xml标签有向树;
(2)遍历所有节点,计算同类型节点的平均节点规模数和平均属性类型数;
(2.1)遍历所有的节点,计算出每一个节点的规模数和每一个节点的属性类型数,存入节点规模数表和节点属性类型数表;
(2.2)遍历所有节点,读取每一个节点的标签,存入节点类型表;
(2.3)遍历节点类型表,如果有相同标签的节点,合并节点的规模数和节点的属性类型并除以相同标签的节点个数。如果节点没有相同的标签,执行步骤(2.4);
(2.4)节点按标签排序,并生成节点平均规模数表和节点平均属性类型数表。
(3)根据节点平均规模数表和节点平均属性类型表设定节点平均规模数阈值下界α和节点平均属性类型阈值下界β。
(4)遍历节点平均规模数表,筛选出大于节点平均规模数阈值下界的所有节点,存为集合a。
(5)遍历节点平均属性类型表,筛选出大于节点平均属性类型阈值下界的所有节点,存为集合b。
(6)取集合a和集合b的交集,得到基本语义节点集合,并将集合p存放在结果文件中。
(7)语义节点筛选完成,结束。
2.文档语义分割模块
该模块的分析过程如图3所示:
(1)读入基本语义节点集合p和xml文档库g。
(2)基于基本语义节点集合p和xml文档库g,对文档文件进行语义分割,计算基于给定基本语义节点集合p的基本语义单元集合q。
(2.1)选取一个基本语义节点a,获取以节点a为中心的基本语义单元。
(2.2)获得以节点a为根节点的子树st(a),根据st(a)进行如下判断。
(2.3)如果st(a)中存在其他基本语义节点ai,则断开ai与其父亲节点的父子关系边,如果不存在其他基本语义节点,则执行步骤(2.4)。
(2.4)更新st(a),得到st′(a)。并获得节点a的节点编号路径path(a),对path(a)进行如下判断。
(2.5)如果path(a)中存在其他基本语义节点ai,则断开ai与其孩子节点的父子关系边并更新path(a),如果不存在其他基本语义节点,则执行步骤(2.6)。
(2.6)按照组先后裔关系把path(a)连接到st′(a)上得到st″(a),st″(a)即为节点a对应的基本语义单元。
(3)遍历基本语义节点集合,按照步骤(2)计算出所有节点对应的基本语义单元q,存入临时文件。
(4)文档语义分割结束。
3.关键字检索模块
该模块的分析过程如图4所示:
(1)读入基本语义节点集合单元和关键字集合。
(2)遍历每一个基本语义单元集合中的元素,建立倒排索引,检查是否可以回答关键字检索。
(3)如果元素可以回答关键字检索,把元素加入一个新的集合中。该集合为回答关键字的基本语义单元集合。
(4)把回答所有关键字的基本语义单元集合存入临时结果文件。
(5)关键字检索模块结束。
4.单元结构分析模块
该模块的分析过程如图5所示:
(1)读入回答关键字的基本语义单元集合。
(2)取基本语义单元集合中的一个元素,即一个基本语义单元,解析出语义单元中的关键字节点和基本语义节点。
(3)以基本语义节点为中心判断语义单元中的其他节点。
(3.1)判断该节点是否为关键字节点,如果是,则保留该节点,否则进入步骤(3.2)。
(3.2)判断该节点是否为基本语义节点与关键字节点片段路径上的节点如果是,则保留该节点,否则删除该节点。
(3.3)通过步骤(3.1)和(3,2)即可得到一个基于基本语义单元的结构关系单元。
(4)遍历基本语义单元内所有元素,对每一个元素实行步骤(3),得到基于关键字的结构关系单元集合。
(5)将该结构关系集合存入临时结果文件。
(6)单元结构分析模块结束。
5.语义加权模块
该模块的分析过程如图6所示:
(1)从临时结果文件中读入基于关键字的语义单元结构集合。
(2)取语义单元结构集合中的一个元素,即单个语义单元结构,进行基于结构的语义加权计算,得出基本语义单元的权重:
(2.1)已知基本语义节点和关键字节点的层级可以影响该基本语义单元对xml文档的描述程度。不同的xml数据结构中同样的节点因其表示内容的不同而具有了不同的权重。一个节点层次越低,即该节点越靠近根节点,就表示该节点对xml数据区分能力越强,则对应的基本语义单元越能够描述文档主要内容,该单元所占权重越大。
取基本语义结构的关键字节点和基本语义节点。分别得到基本语义节点的层级和关键字节点的层级。对其层级进行加权计算,计算权重公式表示如下:
d(v)为单元的层级权重,
(2.2)关键字节点之间的距离可以用来衡量节点之间的相关度。关键字节点之间的距离可以表示节点之间的相关度,距离越短相关度越高,相关度会影响关键字检索结果的权重,关键字之间相关度越高,检索权重应越高。取基本语义结构中关键字节点,并计算两两关键字节点之间的距离,对关键字节点之间的距离再进行加权计算,其计算权重方法为:
式中r1(v)为单元的关键字严格程度的权重,θ为调节因子,i和j代表第i个关键字和第j个关键字,且有i≠j,k表示关键字的数量,d(wi→wj)表示各关键字节点之间的距离。
(2.3)关键字节点与基本语义节点之间的距离
基本语义单元结构越紧密,关键字节点与基本语义节点之间的距离越小,该单元节点之间的相关度越高,就越能对查询内容进行描述,其权重应该越高。取基本语义结构中的关键字节点,计算关键字节点与基本语义单元节点之间的距离,再对取得的距离进行加权计算。其计算权重可以表示为:
式中r2(v)为关键字与基本语义单元之间严格程度的权重,θ为调节因子,i代表第i个关键字,k表示关键字的数量,d(v→wi)表示各关键字节点到基本语义节点之间的距离。
(2.4)得到步骤(2.1),(2.2)和(2.3)中计算出的基于节点结构进行的加权语义计算,一个基本语义单元在xml数据中指定关键字的最终权重表示为:
rank(v)=d(v)×r1(v)×r2(v)
(3)遍历基本语义单元结构集合中所有元素,得到基本语义单元的权重集合。将该权重集合存入临时结果文件。
(4)语义加权模块结束。
6.结果筛选模块
(1)从临时文件中读入基本语义单元权重集合。
(2)对基本语义单元权重集合进行从大到小排序,排序步骤如下:
(2.1)将集合分为n/2个子集合,对集合中每两个数进行排序。
(2.2)将相邻的集合两两合并,对集合中的数再进行排序。
(2.3)对步骤(2.1)和步骤(2.2)进行迭代。
(2.4)所有元素合并到一个集合中,迭代完成,集合中所有元素完成排序
(3)设定权重阈值,按顺序输出集合中比权重阈值大的元素。
(4)根据输出的元素得到元素对应的基本语义单元,则这些基本语义单元为更符合查询意图的基本语义单元,且排序越靠前,结构越紧凑关键字之间相关度越高,越可能符合用户的查询意图。
(5)按顺序输出基本语义单元,完成结果筛选。
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!