文本情感倾向的判别方法与流程
本发明涉及数据挖掘和模式识别的方法,具体讲是文本情感倾向的判别方法。
背景技术:
随着互联网技术的迅猛发展,人类社交早已不局限于面对面沟通和书信交流。而网络社交媒体因其蓬勃的发展态势,逐步成为当下民众不可或缺的沟通桥梁,也是自由发表意见的交流平台,极大程度上丰富了人类生活。人们通过网络社交媒体发布信息的渠道越来越简便,频率也逐渐增大,随之带来的网络文本数量也呈极速增长趋势。
网络社交媒体中很大部分都是以传播信息为主,并兼容着娱乐、教育、营销等功能。以微博为例,已经从早期的社交平台逐步转变为民众的舆论中心,上面发布着海量的评论信息,是民众对于热点事件所持态度的风向标。不仅如此,越来越多的公众人物通过微博进行营销宣传,甚至一些国家政务机关都使用微博公开或发布信息,这使得微博平台的盛行和传播力度得到了进一步扩展,从而引发文本信息的爆炸式增长。然而,这些文本信息通常都是非结构化数据,不仅内容泛滥、结构不规整、数据量庞大,往往还蕴含着民众的情感倾向。如果单纯地以人力资源对这些海量文本进行整理和分析,无疑是困难且费时的,因此迫切需要一种能够有效处理这些网络文本信息并判别其中蕴含的情感倾向性方法。
文本挖掘与自然语言处理技术密不可分,是当下的研究热点。而文本情感倾向性判别作为文本挖掘的一个分支,以从文本信息中挖掘用户对于热点事件或品牌口碑的情感倾向为目的,在日常生活场景中有着极大的研究意义。对消费者而言,文本情感倾向性判别技术能够提供其他用户对于商品的总体评价,并以此作为购买决策的依据。对企业而言,能够通过文本情感倾向判别技术获得产品在当前市场的口碑走势,从而针对性地对产品进行改善,获得更大的经济效益。作为政府的宏观调控,基于文本情感倾向判别技术能够实现对舆情的实时监控,及时发现群众对于热点事件的情绪及态度,对不利的舆情发展进行干预,为一些突发事件提前做好准备。因此,对文本情感倾向的判断是很有必要并且是有积极意义的。
技术实现要素:
本发明提供了一种文本情感倾向的判别方法,以有效提高文本情感倾向判断的准确性。
本发明的文本情感倾向的判别方法,包括:
a.从语料库中获得训练语句,并对训练语句赋予类别标签;
b.对测试语句进行拆分,并根据训练语句的类别标签获得测试文本拆分后的每条语句的情感倾向得分;
c.根据“情感纯净度”、“关键词特性”和“语句在文本中的位置”三种特征获得所述拆分后的每条语句的初始权重。
情感关键句表达的是文本的整体情感,蕴含的情感相对单一。情感纯净度是指句子情感单一的程度,情感纯净度越高,句子的情感单一程度越高,其情感贡献度越大,作为情感关键句的可能性越大;
由于人们的语言习惯,情感关键句作为奠定文本情感基调的句子,大多使用具有概括性的词语,例如“总而言之”、“总体”等关键词。因此,关键词特性也是计算每条语句初始权重的因素之一;
由于文本往往在开头表达情感,定下情感基调,或在结尾进行总结性的评述。因此,开头语句或者结尾语句都对整个文档的情感有着举足轻重的作用。于是在计算语句的初始权重时,也需要考虑语句位置带来的影响;
d.以所述的每条语句为节点、每条语句之间的相似度为边构建无向图;
e.根据所述的无向图构建有向图,有向图的节点为所述的每条语句,有向图的每条边表示始点到终点转移概率;
f.根据步骤e的有向图和步骤c的每条语句的初始权重,利用图排序方法迭代计算每条语句的权重值;
g.迭代结束后,将所述每条语句的情感倾向得分根据权重值加权求和,获得当前文本的情感倾向值,并以此判断当前文本的情感倾向性。
进一步的,步骤b中通过测试语句中的标点符号对测试语句进行拆分,例如“句号”、“问号”、“叹号”等。
进一步的,步骤b中获得测试文本拆分后的每条语句的情感倾向得分的方法为:先计算测试语句与所有训练语句的余弦相似度,利用knn算法(k-nearestneighbor)获取与测试语句最相似的k条训练语句,然后根据该k条最相似训练语句的类型标签以及对所述的余弦相似度归一化处理后的结果,加权获得测试语句的情感倾向得分。
具体的,步骤d中所述的相似度为每条语句之间的余弦相似度。
进一步的,步骤e中所述的始点到终点的转移概率为:始点与终点的相似度,占始点与其他所有节点相似度之和的比例。
具体的,步骤f中所述的权重值为:通过图排序方法迭代后的以有向图的各节点为终点的各有向边,每条有向边的始点权重与转移概率的乘积之和。
在此基础上,步骤g中,将所述的权重值先进行归一化处理后,在进行加权求和。
本发明的文本情感倾向的判别方法,通过对语句拆分,能够有效获得整个文本的情感倾向值,非常明显的提高了文本情感判断和分类的准确度。
以下结合实施例的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。在不脱离本发明上述技术思想情况下,根据本领域普通技术知识和惯用手段做出的各种替换或变更,均应包括在本发明的范围内。
附图说明
图1为本发明文本情感倾向的判别方法的流程图。
图2为构建的无向图的示意图。
图3为构建的有向图的示意图。
具体实施方式
如图1所示本发明文本情感倾向的判别方法,包括:
a.从语料库中获得训练语句,获得训练语句集合d={d1,d2,...,dn},并对训练语句赋予类别标签。训练语句集合一般来自比较具有权威性的中文语料库,例如中国科学院计算技术研究所的中文文本分类语料库tancorp、第二届自然语言处理与中文计算会议(nlp&cc2013)的中文微博情绪识别数据集等。对训练语句集合中的每条训练语句都赋予一个表示类别的标签c={正面,负面},即代表着类型标签值,正面为“1”,负面为“-1”。
b.当前的测试文本t,通过测试文本t的各测试语句中的标点符号对测试语句进行拆分,例如“句号”、“问号”、“叹号”等,形成测试语句集合v={v1,v2,...,vm}。并根据训练语句的类别标签获得测试文本拆分后的每条语句的情感倾向得分,方法为:先计算测试语句与所有训练语句的余弦相似度,利用knn算法(k-nearestneighbor)获取与测试语句最相似的k条训练语句。以测试语句vi和训练语句dj为例,找出vi和dj出现的所有词语并取并集,设并集中词语的个数为r,统计每个词语在vi和dj中出现的频率,组成vi和dj的词频向量。例如vi的词频向量为(ni1,ni2,...,nir),dj的词频向量为(nj1,nj2,...,njr),则vi和dj之间的余弦相似度计算公式如下:
通过上述方法,能够得出每条测试语句与所有训练语句之间的余弦相似度。
然后对这些余弦相似度计算结果进行排序,根据该k条最相似训练语句的类型标签以及对所述的余弦相似度归一化处理,所有归一化处理后的余弦相似度与对应的训练语句类型标签值的乘积之和即为当前测试语句的情感倾向得分。以测试语句vi为例,vi的情感倾向得分的计算公式如下所示,其中label(dj)表示训练语句dj的类型标签值。
c.计算出每条测试语句的情感得分后,根据“情感纯净度”、“关键词特性”和“语句在文本中的位置”三种特征获得所述拆分后的每条语句的初始权重。以测试语句vi为例,首先将计算vi的“情感纯净度”得分、“关键词特性”得分和“语句在文本中的位置”得分,再对这三项值进行加权求和,并以此结果作为vi的初始权重。
情感关键句表达的是文本的整体情感,蕴含的情感相对单一。情感纯净度是指句子情感单一程度,情感纯净度越高,句子的情感单一程度越高,其情感贡献度越大,因此作为情感关键句的可能性越大。vi的情感纯净度purity(vi)的得分公式为:
其中,|vi|是vi中的词语个数;polarity(w)表示词语w的情感极性,词语的情感极性在情感词典中如果为正面,则polarity(w)为1;如果词语w的情感极性为负面,则polarity(w)为-1。
由于人们的语言习惯,情感关键句作为奠定文本情感基调的子句,大多使用具有概括性的词语,例如“总而言之”、“总体”等关键词。因此,关键词特性也是计算每条语句初始权重的因素之一。vi的关键词特性keyword(vi)的得分公式为:
其中,kw是关键词集,kw={总体、整体、总的、总结、总的来说、总而言之、因此、所以};ekw(w)为指示函数,当词语w∈kw时,ekw(w)为1;当词语
在文本信息中,往往在开头表达情感,定下情感基调,或在结尾进行总结性的评述。因此,开头语句或者结尾语句都对整个文档的情感有重要的作用。因此,在计算语句的初始权重时,也会考虑语句位置带来的影响。vi的位置特性position(vi)的得分公式为:
position(vi)=i2-m×i+100
其中,m代表测试文本t所包含的语句总数;i表示测试语句vi是文档中的第i个子句,i∈[1,m];假定文本t中的语句总数都不超过20,为了保证每一个子句的位置得分都为一个非负数,因此添加了常量100。
以上已求得vi的“情感纯净度”得分、“关键词特性”得分和“语句在文本中的位置”得分,因此,再对这三项值进行加权求和,即为vi的初始权重,计算方法如下所示,其中λ1、λ2和λ3为以上三个得分对应的权重值,且λ1+λ2+λ3=1:
weight(vi)=λ1×purity(vi)+λ2×keyword(vi)+λ3×position(vi)
本实施例中对整个训练语句集合中的每条语句都被赋予了情感的分类标签,并将其中的80%作为训练数据,20%作为测试数据。在对每条测试语句进行初始权重的计算时,选取多组不同比例下的λ1、λ2、λ3权重值进行计算,最终通过在不同比例的λ1、λ2、λ3权重值下,根据测试语句情感分类准确率的高低,选出最适合的三个得分对应的权重值λ1、λ2和λ3。
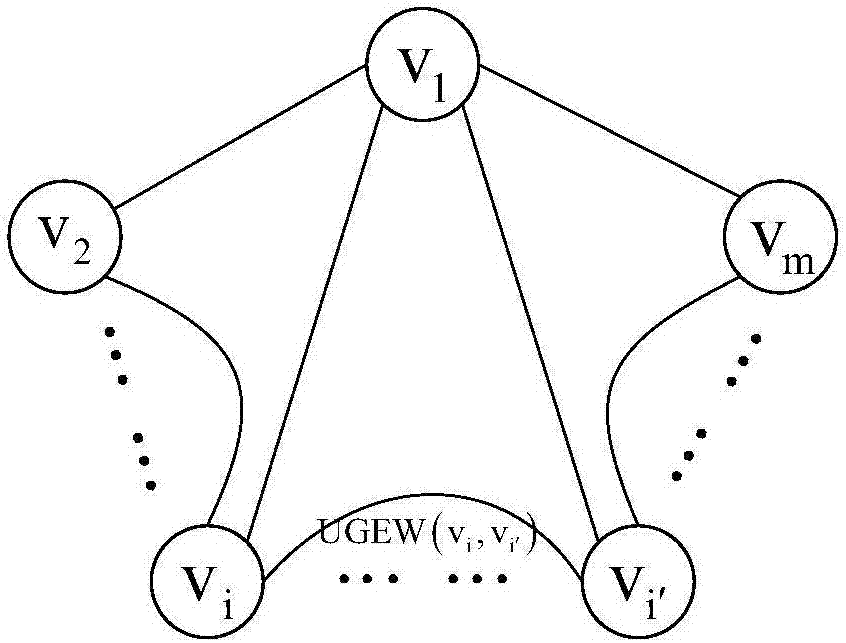
d.以所述的每条语句为节点、每条语句之间的余弦相似度为边构建无向图。如图2所示,以测试语句vi、vi′为例,它们之间的无向边权值以ugew(vi,vi′)表示,数值为cos(vi,vi′),且ugew(vi,vi′)=ugew(vi′,vi)。ugew表示无向图边权值(undirectedgraphedgeweight)。
e.根据所述的无向图构建有向图,有向图的节点为所述的每条语句,有向图的每条边表示始点到终点转移概率。如图3所示。以测试语句vi、vi′为例,vi至vi′的有向边权值以dgew(vi,vi′)表示,计算方法如下所示,其中dgew(vi,vi′)≠dgew(vi′,vi),v表示测试文本t经过语句拆分获得的测试语句集合v={v1,v2,...,vm},dgew表示有向图边权值(directedgraphedgeweight)。
f.根据步骤e的有向图和步骤c的每条语句的初始权重,通过图排序方法迭代计算每条语句的权重值,直至收敛。收敛时,获得每条语句的最终权重值。每次迭代时,每条语句的权重值是以有向图的各节点(有向图的节点为所述的每条语句)为终点的各有向边,每条有向边的始点权重与转移概率的乘积之和。以测试语句vi为例,其中weightn(vi)表示第n次迭代后vi的权重值,计算公式为:
g.迭代结束后,将所述每条语句的情感倾向得分根据归一化处理后的权重值加权求和,获得当前文本的情感倾向值,并以此判断当前文本的情感倾向性。如果情感倾向值大于0,则判断测试文本t为正面情感;如果情感倾向值小于0,则判断测试文本t为负面情感。假设利用图排序方法迭代计算n次就获得每条语句的权重值,测试文本t的情感倾向值以so(t)表示,计算公式为:
- 还没有人留言评论。精彩留言会获得点赞!