新浪微博事件推荐方法与流程
本发明属于数据挖掘领域,特别涉及一种社交网络文本推荐技术。
背景技术:
微博作为一种新型传播媒体,发展迅猛,具有传播速度快、互动性强、信息更新方便等特点,已经开始对社会生活产生巨大影响,成为我国主要社交网络传播媒介之一。由于人们可以随时随地可以通过web、网页等各种形式向外界发布信息,实现即时分享,越来越多的人喜欢在微博上分享信息、交流意见以及表达情感。比起传统媒体,对于很多重大新闻事件,微博的操作简便、低门槛性决定了微博更可以占据信息发布的制高点。这点在突发事件中表现更为突出,因为在事件现场的任何微博用户都可以通过手机将整个事件信息发布到微博上去。例如,2009年11月,西安发生4.4级地震,微博只在1分钟后就对该事件做了报道,而国家官方网站第一次发布是15分钟之后。
但随着微博的普及,也带来了一些新的问题。首要问题是信息爆炸,海量的数据信息充斥着互联网,给人们带来了严重的信息过载问题。人们面对这种海量的信息往往难以找到自己想要的数据,而想要快速、准确地找到对于自己最重要的数据则更加困难了。在web2.0以前,人们通常是通过专业的搜索引擎获取信息,但这也存在一些问题,最主要的问题之一是搜索引擎需要用户主动去查询,它不能主动地推送信息,实时性不高,使得用户有可能错过重要信息。web2.0的出现,使得人人都可通过网络来参与信息的发布、传播与过滤,从而达到信息共享的目的。这种定向消息源的信息推送方式虽然颠覆了以前通过搜索引擎拉取信息的方式,但也很好的弥补了搜索引擎当前面临的窘境。
推荐系统作为一个信息获取的方法,它从用户出发,研究用户的喜好,能够在用户意图模糊的情况下,引导用户发现他潜在的需求,推送给他感兴趣的信息,这种信息获取方式是解决信息过载问题非常有潜力的方法。推荐系统的主要任务在于准确把握用户的兴趣点,利用高效的推荐算法,向其推送可能感兴趣的事件。
新浪微博作为国内最受欢迎的微博工具,具有如下特征:博文字数限制在140字以内、数据海量、短文本性、文本缺失性、实时性、丰富的社交信息。由于微博数据的特性,博文形式不固定,且很多博文可能并不包含有效信息,给处理带来了很大的麻烦,因此目前针对这种短文本的推荐系统的研究仍旧是富有挑战性的。为了达到良好的推荐效果,开发高效的推荐算法是极为重要的。目前的推荐系统大多为文本推荐系统,对于微博这种短文本数据的推荐系统的研究还不够深入,其研究结果还不能满足实际应用需要。
技术实现要素:
为了解决上述技术问题,本申请提出了一种新浪微博事件推荐方法,实时修正用户模型,提高了微博事件推荐系统的推荐准确度,改善用户体验。
本发明采用的技术方案为:新浪微博事件推荐方法,包括:
s1、采用改进的余弦夹角算法计算用户模型与事件向量之间的相似度,若相似度大于阈值,则将该事件推荐给用户;否则不推荐;
s2、根据最近时长k内到达事件数据库的推荐事件对用户模型进行更新;
s3、根据被用户点赞事件对用户模型进行更新。
进一步地,改进的余弦夹角算法具体为:
其中,samewordnum表示用户模型a和事件模型b相同的关键词数目;min(|a|,|b|)表示用户模型a和事件模型b中最小的维数;wai表示用户模型a中特征词ai对应的权重;wbj表示事件模型b中特征词bj对应的权重。
更进一步地,所述用户模型从用户数据库中提取。
更进一步地,所述事件向量从事件数据库中提取。
进一步地,步骤s2具体为:
s21、当事件数据库中有新的推荐事件到达,则提取最近的时长k内到达的推荐事件;
s22、选取步骤s21提取的各推荐事件中权重大于第一阈值的特征词加入用户模型中;
s23、选取当前用户模型特征词中的高频词汇作为新的用户模型。
进一步地,步骤s3具体为:当有新的事件被点赞,则记录被点赞事件的id,根据id从事件数据库中查找对应事件,提取该事件的高频词汇。
本发明的有益效果:本申请的新浪微博事件推荐方法,通过改进的余弦夹角算法计算用户模型与事件向量的相似度;若相似度高于设定的阈值,则向用户推送该事件;并且通过最近一段时间内新到达的时间对用户模型进行更新,使其能够跟踪事件最新发展状态;结合用户点赞行为再次对用户模型进行更新,使推荐结果更加符合用户预期;本申请的方法能够以较高的准确率推荐新浪微博事件,能够对模型进行合理的漂移,并且能够及时响应对用户推荐结果的反馈。
附图说明
图1为本申请的方案流程图;
图2为模型漂移工作流程;
图3为用户反馈更新流程。
具体实施方式
为便于本领域技术人员理解本发明的技术内容,下面结合附图对本发明内容进一步阐释。
如图1所示为本申请的方案流程图,本申请的技术方案为:新浪微博事件推荐方法,包括:
s1、采用改进的余弦夹角算法计算用户模型与事件向量之间的相似度,若相似度大于阈值,则将该事件推荐给用户;否则不推荐;
s2、根据最近时长k内到达事件数据库的推荐事件对用户模型进行更新;
s3、根据被用户点赞事件对用户模型进行更新。
步骤s1具体为:经典的余弦夹角算法公式如下:
其中,a、b分别代表用户模型向量和事件向量,可表示如下:
a={(a1,wa1),(a2,wa2),(a3,wa3),……,(am,wam),}
b={(b1,wb1),(b2,wb2),(b3,wb3),……,(bn,wbn),}
wa1表示用户模型a中特征词a1所对应的权重;b向量同理。化简得到:
其中,wai与wbj相乘的条件为特征词ai=bj。
但是如果两个向量相同的词语较多,则余弦值较大。考虑到用户模型和事件向量维数可能较大,单纯地以词形相同来计算相似度难免会造成推荐精度不高的问题。造成该现象的原因之一是,一些事件向量中权重高的特征词可能并不具有划分事件的能力,如“中国”、“美国”等,而一些权重稍低的词有可能才是事件的侧重点,如“空难”、“金球奖”等。因此,本申请引入一个衰减系数来提高推荐精度,改进后的余弦夹角算法如下:
其中,samewordnum表示用户模型a和事件模型b相同的关键词数目;min(|a|,|b|)表示用户模型a和事件模型b中最小的维数;wai表示用户模型a中特征词ai对应的权重;wbj表示事件模型b中特征词bj对应的权重。
引入衰减系数之后,若向量之间只有少量关键词相同,则其相似度会大幅度衰减,只要设定合适的阈值,本申请中阈值的设定不是固定的;一般合适的阈值能够实现所推荐的结果符合预期,则说明该阈值的设置是合适的;否则重新调整阈值。就可以很大程度提高推荐精度。除引入衰减系数外,本申请同时还用到了另外两种提高推荐精度的办法。一是硬性规定相同关键词数大于多少才进行推荐。一般情况下,用户输入的关键词不会太多,约为5个左右,则本申请设定当用户模型与事件向量至少有三个相同关键词时才进行相似度计算。当用户输入词数有大的变化时,该门限值可以做出相应调整。二是为了避免同一个词不同词形带来的负面影响,在计算相似度的时候,本申请提取了各关键词的词干来进行计算。
获得推荐事件后,将其存入用户数据库,生成推荐日志。在要求不高的情况下,可以用事件的摘要代表一个事件,将该摘要推送给用户。若用户需要阅读原始博文,则需要从事件中提取与用户模型最相关的博文。
要提取最感兴趣博文,需要对博文进行预处理,进行分词、词干还原,若该博文包含相同关键词列表中权重最大的词,则该博文可能会是用户最感兴趣的。
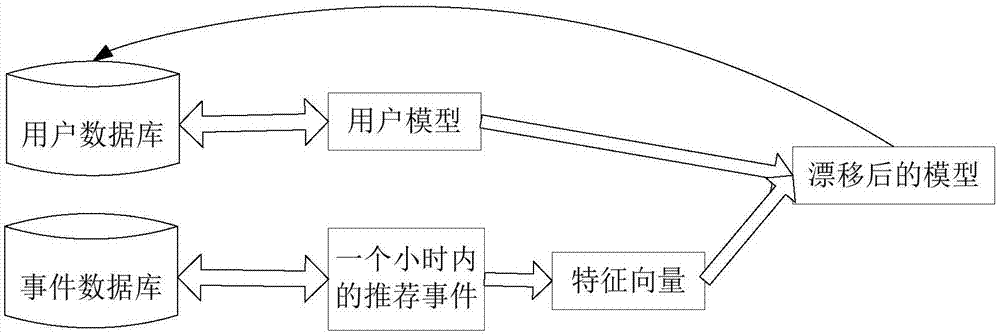
步骤s2具体为:模型漂移的主要任务是使用户模型随着时间的推移自动进行修正,其目的在于实时跟踪事件热点,掌握事件走向。
用户模型代表了用户的兴趣点,它通常也是一个事件的缩影,只是用户用一些关键词概括了这个事件。随着时间的推移,事件可能有新的发展,其热点词汇也有所变化。为了自动跟踪这种变化,保证用户能够接收到最新信息,本申请设计了模型漂移模块。
模型漂移核心之处在于修正用户模型,将最新热点词汇加入到用户模型,并删除模型中过时的关键词。其工作流程如图2所示。
同上文推荐模块,本申请从用户数据库提取用户模型,从事件数据库提取最新事件。值得注意的是,提取的是最近一个小时之内到达的事件,且提取触发点是该用户模型下有新的推荐事件到达。意即,当前用户模型有新的推荐事件时,通常提取该模型下最近一个小时之内被推荐的所有事件(即本申请中的时长k为一个小时,k的取值也可以是其他值,只是漂移幅度不同;但是为了保证新闻的时效性,不建议取太大的值),生成漂移向量。这样做的目的是使漂移过程趋于平缓,避免出现漂移过快的情形。如果漂移幅度太大,可能会与初始模型相去甚远,影响用户体验。关于特征向量的提取,也有一些值得注意的地方。一个小时之内的所有事件,生成的漂移向量可能会很大,远远超出初始用户模型的维度,为了排除权重极小的特征词并且避免初始用户模型被过分地冲淡,选取当前用户模型特征词中的高频词汇作为新的用户模型。
本实施例将提取的事件特征向量限定为20词,只取其权重最高的一部分词,将这些词添加到用户模型,并截取更新后权重前20的词作为新的用户模型。特别的,为了保证用户原始输入关键词的影响力,本申请将更新后的用户模型划分为两部分——原始输入关键词、新加入的关键词,每部分各占权重0.5。这样做既能保证原始输入关键词的权重,又能添加事件最新热点词并且删除过时的特征词。
同样的,将漂移后的用户模型存入用户数据库,生成漂移日志。
步骤s3具体为:用户反馈更新的主要目的是及时接收用户反馈信息,根据用户的喜好,对用户模型做出修正。用户对于推荐结果的反馈,反映了用户对当前结果是否满意,是对推荐进行修改的最重要参考信息。用户反馈更新流程如图3所示。
用户反馈,最直接的方式就是“点赞”。用户对一个事件或是一篇博文感兴趣时,他可以对该事件或博文点赞,系统识别到点赞行为并将被点赞事件id存入用户数据库。利用该点赞信息,可以及时获取用户最新兴趣点,更新用户模型。
如有新的事件被点赞,则从用户数据库中提取用户模型及感兴趣事件id,根据该id在事件数据库中查找相应事件,提取出该事件的高频词汇;高频词汇提取出以后,将高频词汇中词频最高的词的权重设置为原用户模型中最大的权重,其余高频词权重按比例调整。最后,再对整个更新后的用户模型进行归一化。所谓高频词汇,在这里,将其定义为词频大于相应事件博文数的特征词,这种词对于该事件有一定的代表意义,显然这些词的权重较高,更新到用户模型的时候会占有较大的比重,因此可以有力地反映出用户的主观爱好。同模型漂移,截取更新后的用户模型的前20个关键词,做归一化处理,仍旧使得原始输入关键词占权重0.5。最后,将更新后的用户模型存入用户数据库,生成更新日志。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!