一种按涉及借壳上市主题的PDF文件切割方法与流程
本发明属于大数据研究方面的非结构化数据的数据结构化处理领域,涉及一种按涉及借壳上市主题的pdf文件切割方法。
背景技术:
将非结构化数据包括以word、excel、pdf、txt、音频、视频格式存储的文件转换为用户友好、较为便宜的、且可直接用于统计分析的结构化数据如以sql或orcal等数据库格式存储的结构化数据是目前大数据应用领域较为迫切的需求和研究的难点。
当前针对篇幅较短且以pdf格式存储的文件数据结构化方法已经存在一些成果,其主要思路为首先将pdf文件这一完全非结构化的数据转换为以xml或者word格式存储的半结构化数据文件,通过正则条件最终转换为以sql或orcal等数据库格式存储的结构化数据;而这种思路方法均存在当所处理pdf文件的篇幅和规格较大时,数据结构化转换效率较低、转换错误率较高等不足。
技术实现要素:
本发明的目的在于克服上述现有技术的缺点,提供了一种按涉及借壳上市主题的pdf文件切割方法,该方法能够高效、精准的实现涉及借壳上市主题的pdf文件切割。
为达到上述目的,本发明所述的按涉及借壳上市主题的pdf文件切割方法包括以下步骤:
1)通过分布式互联网爬虫技术获取公开的且以pdf格式存储的业务文件;
2)依据业务层需求对步骤1)获取的公开的且以pdf格式存储的业务文件进行涉及借壳上市主题的业务层分析,确定涉及借壳上市主题的pdf文件的语言描述特征、关键字及关键字标题;
3)通过涉及借壳上市主题的pdf文件及步骤2)所确定涉及借壳上市主题的pdf文件的语言描述特征逐页对源pdf文件进行关键字及关键字标题的正则搜索,确定包含关键字及关键字标题的pdf文件的页码信息集合p;
4)采用页码异常去除机制对步骤3)得到的pdf文件页码信息集合p中的异常页码进行去除,得去除后的pdf文件页码信息集合pfinal;
5)根据步骤4)所获得的去除后pdf文件页码信息集合pfinal对源pdf文件进行关于借壳上市主题的切割,完成涉及借壳上市主题的pdf文件切割。
涉及借壳上市主题的pdf文件的关键字及关键字标题集合记作jkt={jkt1,jkt2,jkt3,...,jktn},其中,jkt1表示收购交易方,jkt2表示收购交易对方,jkt3表示收购总股数,jkt4表示收购总股本,jkt5表示发行股份,jkt6表示发行股份及支付现金,jkt7表示收购,jkt8表示资产重组,jkt9表示购买,jkt10表示吸收合并,jkt11表示重大资产置换,jkt12表示参与**的竞拍,jkt13表示与**签署定向增发协议,jkt14表示是否构成借壳上市,jkt15表示交易时间。
包含关键字及关键字标题的pdf文件的页码信息集合
步骤4)具体操作为:采用页码异常去除机制对步骤3)得到的pdf文件页码信息集合p中的异常页码进行去除,得去除后的pdf文件页码信息集合pfinal;
当pdf文件页码信息集合p中第一元素对应页码值与第二元素对应页码值之差大于pthreshold,即|p2-p1|>pthreshold时,则去除pdf文件页码信息集合p中第一元素对应页码值;当pdf文件页码信息集合p中倒数第一元素对应的页码值与倒数第二元素对应页码值之差大于pthreshold,即|pm-pm-1|>pthreshold时,则去除pdf文件页码信息集合p中倒数第一元素所对应页码值,得去除后的pdf文件页码信息集合pfinal。
本发明具有以下有益效果:
本发明所述的按涉及借壳上市主题的pdf文件切割方法在具体操作时,先获取公开的且以pdf格式存储的业务文件,再确定涉及借壳上市主题的pdf文件的语言描述特征、关键字及关键字标题,然后确定包含关键字及关键字标题的pdf文件页码信息集合p,同时为提高pdf文件页码信息集合p的精准性及可靠性,实现对pdf文件页码信息集合p约简化,再通过页码异常去除机制对步骤3)得到的pdf文件页码信息集合p中的异常页码进行去除,然后再根据去除后pdf文件页码信息集合p完成涉及借壳上市主题的pdf文件切割,从而有效的提高切割的精准度及可靠性,高效、简洁,具有普适性及较强的应用基础性。
附图说明
图1为本发明的流程图;
图2为实施例一的流程图。
具体实施方式
下面结合附图对本发明做进一步详细描述:
参考图1,本发明所述的按涉及借壳上市主题的pdf文件切割方法包括以下步骤:
1)通过分布式互联网爬虫技术获取公开的且以pdf格式存储的业务文件;
2)依据业务层需求对步骤1)获取的公开的且以pdf格式存储的业务文件进行涉及借壳上市主题的业务层分析,确定涉及借壳上市主题的pdf文件的语言描述特征、关键字及关键字标题;
3)通过涉及借壳上市主题的pdf文件及步骤2)所确定涉及借壳上市主题的pdf文件的语言描述特征逐页对源pdf文件进行关键字及关键字标题的正则搜索,确定包含关键字及关键字标题的pdf文件的页码信息集合p;
4)采用页码异常去除机制对步骤3)得到的pdf文件页码信息集合p中的异常页码进行去除,得去除后的pdf文件页码信息集合pfinal;
5)根据步骤4)所获得的去除后pdf文件页码信息集合pfinal对源pdf文件进行关于借壳上市主题的切割,完成涉及借壳上市主题的pdf文件切割。
涉及借壳上市主题的pdf文件的关键字及关键字标题集合记作jkt={jkt1,jkt2,jkt3,...,jktn},其中,jkt1表示收购交易方,jkt2表示收购交易对方,jkt3表示收购总股数,jkt4表示收购总股本,jkt5表示发行股份,jkt6表示发行股份及支付现金,jkt7表示收购,jkt8表示资产重组,jkt9表示购买,jkt10表示吸收合并,jkt11表示重大资产置换,jkt12表示参与**的竞拍,jkt13表示与**签署定向增发协议,jkt14表示是否构成借壳上市,jkt15表示交易时间。
包含关键字及关键字标题的pdf文件的页码信息集合
步骤4)具体操作为:采用页码异常去除机制对步骤3)得到的pdf文件页码信息集合p中的异常页码进行去除,得去除后的pdf文件页码信息集合pfinal;
当pdf文件页码信息集合p中第一元素对应页码值与第二元素对应页码值之差大于pthreshold,即|p2-p1|>pthreshold时,则去除pdf文件页码信息集合p中第一元素对应页码值;当pdf文件页码信息集合p中倒数第一元素对应的页码值与倒数第二元素对应页码值之差大于pthreshold,即|pm-pm-1|>pthreshold时,则去除pdf文件页码信息集合p中倒数第一元素所对应页码值,得去除后的pdf文件页码信息集合pfinal。
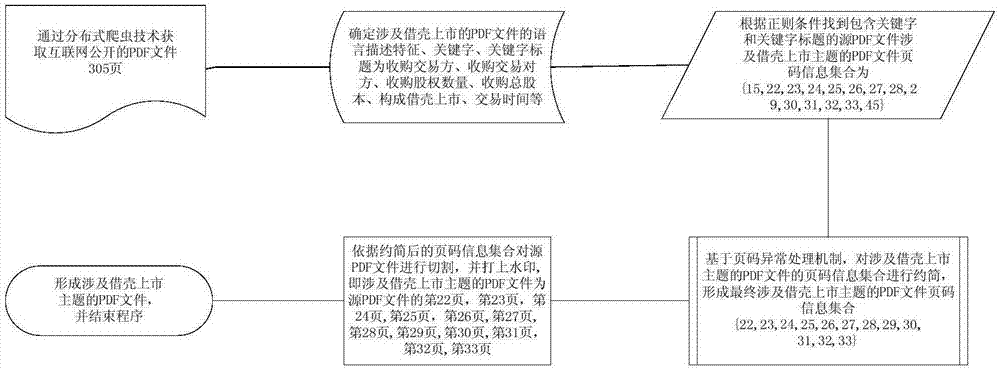
实施例一
参考图1,根据对涉及借壳上市主题的pdf文件的业务分析,确定涉及借壳上市主题的pdf文件的语言描述特征、关键字及关键字标题,涉及借壳上市主题的pdf文件的关键字及关键字标题确定为“收购交易方”、“收购交易对方”、“收购股权数”、“收购总股本”、“发行股份”、“发行股份及支付现金”、“收购”、“资产重组”、“购买”、“吸收合并”、“重大资产置换”、“参与**的竞拍”、“与**签署定向增发协议”、“构成借壳上市”、“交易时间”;利用此关键字和关键字标题采用正则条件找到关键字和关键字标题所在的源pdf文件的页码信息集合p,相对应与“收购交易方”的页码值集合为p1={15,22,25},相对应与“收购交易对方”的页码值集合为p2={22,23,25,26,27},相对应与“收购股权总数目”的页码值集合为p3={25,26,27,28,31},相对应与“收购股权总股本”的页码值集合为p4={25,26,28,32},相对应与“发行股份”的页码值集合为p5={26,27,28,30},相对应与“发行股份及支付现金”的页码值集合为p6={27,28,31,32},相应于“收购”的页码值集合为p7={29,30,31,33},相应与“资产重组”的页码值集合为p8={29,30,33},相对应与“购买”的页码值集合为p9={22,24,25,29,32,33},相应与“吸收合并”的页码值集合为p10={28,29,32},相应与“重大资产置换”的页码值集合为p11={28,29,30,31,32},相应于“参与**竞拍”的页码值集合为p12={29,30,31,32},相应与“与**签署定向增发协议”的页码值集合为p13={29,32},相应与“构成借壳上市”的页码值集合为p14={29,30},相对应与“交易时间”的页码值集合为p15={15,28,31,45},则涉及借壳上市主题的源pdf文件的页码数集合为
- 还没有人留言评论。精彩留言会获得点赞!