针对大数据分析的多hadoop分布式文件系统的制作方法
本发明涉及信息技术行业数据库技术领域,尤其涉及针对大数据分析的多hadoop分布式文件系统。
背景技术:
hadoop的框架最核心的设计就是:hdfs和mapreduce。hdfs为海量的数据提供了存储,则mapreduce为海量的数据提供了计算。
对于基于hadoop的大数据分析系统,在计算任务和需处理数据之间保证数据的本地化对系统性能至关重要。实现上述目标依赖于hadoop分布式文件系统(以下简称hdfs)命名节点提供的数据位置信息。
在实际的hadoop部署实践中,尤其是企业级的hadoop部署中,经常见到的情况是,不同的团队/部门拥有各自独立的hadoop集群及文件系统。这就导致数据竖井的形成,进而导致用户如果想要实施跨文件系统的大数据分析任务,必须对分散在不同文件系统的数据进行统一迁移,或者改变hadoop任务调度器来识别多个文件系统。
当hdfs和hadoop计算节点被部署在同一个虚拟基础设施上的不同集群,例如私有云,用户可以在同一个hdfs上层部署多个hadoop计算集群,上述问题更为明显。为了更好的利用资源,避免大量数据移动以取得更好的分析性能,允许用户部署跨多hdfs的hadoop集群带来的好处显而易见。
技术实现要素:
本发明的目的是提供针对大数据分析的多hadoop分布式文件系统,在避免大量数据移动和不改变hadoop组件源代码的前提下,保证了计算任务和数据的本地化,大幅提高系统性能,提供了按不同的逻辑视图重新聚合hdfs并保证计算任务性能的灵活性。
为实现上述目的,本发明采用以下技术方案:
针对大数据分析的多hadoop分布式文件系统,包括以下步骤:
步骤1:用户环境下拥有数个分散的原始hdfs文件存储系统,所述原始hdfs文件存储系统被部署在数个分散的分布式服务器中,每一个所述原始hdfs文件存储系统中均存储有大量分级文件,每一个所述原始hdfs文件存储系统均使用一个唯一的hdfs文件位置信息作为根节点;
步骤2:创建hdfs聚合节点,所述创建hdfs聚合节点的步骤如下:
a.将所述分布式服务器进行归类,集中所有所述原始hdfs文件存储系统的所述根节点;
b.将所有所述根节点作为叶节点使用,并将所有叶节点聚合为一个开放应用程序编程接口api;
c.对所述开放应用程序编程接口api进行新的命名,并作为所述聚合节点使用;
d.将所述聚合节点部署在新的分布式服务器中,创立聚合节点hdfs文件存储系统;
步骤3:用户执行map/reduce任务调度器,从所述聚合节点hdfs文件存储系统中请求查询文件p的位置信息;
步骤4:所述聚合节点hdfs文件存储系统从所述叶节点中取得所述文件p位置信息,集中归纳并把整理完善的所述文件p位置信息的映射信息返回给所述map/reduce任务调度器;
步骤5:所述map/reduce任务调度器根据所述聚合节点hdfs文件存储系统返回的所述映射信息调度任务。
本发明所述的针对大数据分析的多hadoop分布式文件系统,在避免大量数据移动和不改变hadoop组件源代码的前提下,保证了计算任务和数据的本地化,大幅提高系统性能,提供了按不同的逻辑视图重新聚合hdfs并保证计算任务性能的灵活性;避免了数据竖井的形成,更好的利用资源,避免大量数据移动以取得更好的分析性能,实现了用户部署跨多hdfs的hadoop集群的可能性。
附图说明
图1是本发明的流程图;
图2是本发明的实施示意图。
具体实施方式
如图1所示的针对大数据分析的多hadoop分布式文件系统,包括以下步骤:
步骤1:用户环境下拥有数个分散的原始hdfs文件存储系统,所述原始hdfs文件存储系统被部署在数个分散的分布式服务器中,每一个所述原始hdfs文件存储系统中均存储有大量分级文件,每一个所述原始hdfs文件存储系统均使用一个唯一的hdfs文件位置信息作为根节点;
步骤2:创建hdfs聚合节点,所述创建hdfs聚合节点的步骤如下:
a.将所述分布式服务器进行归类,集中所有所述原始hdfs文件存储系统的所述根节点;
b.将所有所述根节点作为叶节点使用,并将所有叶节点聚合为一个开放应用程序编程接口api;
c.对所述开放应用程序编程接口api进行新的命名,并作为所述聚合节点使用;
d.将所述聚合节点部署在新的分布式服务器中,创立聚合节点hdfs文件存储系统;
步骤3:用户执行map/reduce任务调度器,从所述聚合节点hdfs文件存储系统中请求查询文件p的位置信息;
步骤4:所述聚合节点hdfs文件存储系统从所述叶节点中取得所述文件p位置信息,集中归纳并把整理完善的所述文件p位置信息的映射信息返回给所述map/reduce任务调度器;
步骤5:所述map/reduce任务调度器根据所述聚合节点hdfs文件存储系统返回的所述映射信息调度任务。
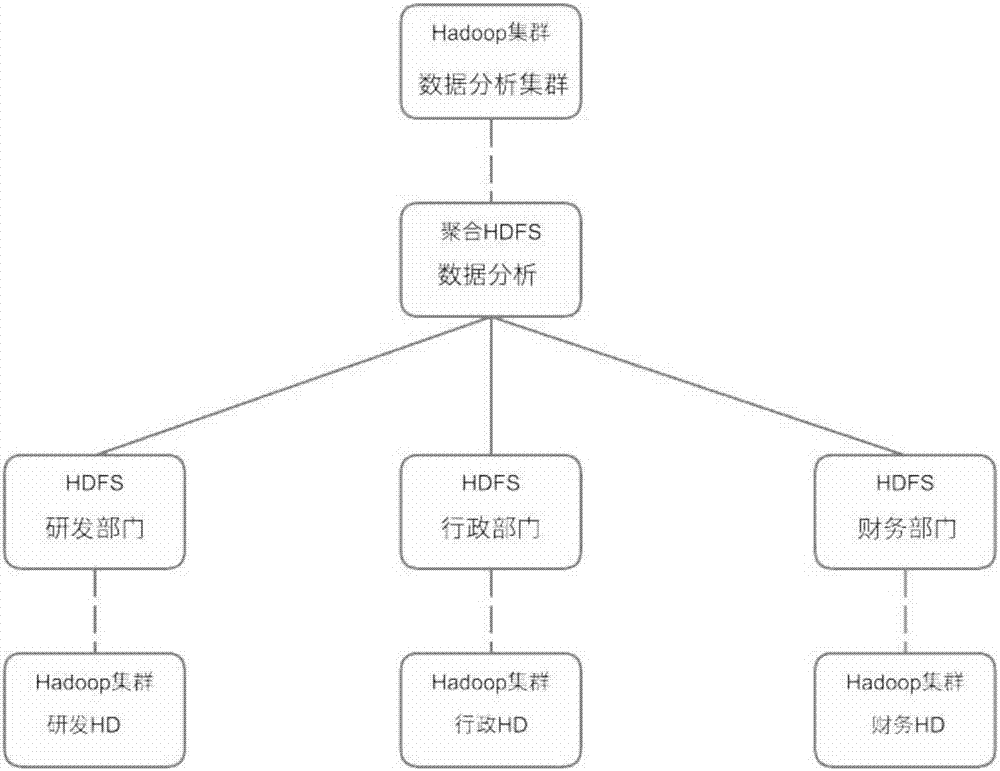
具体实施如图2所示展示了一个典型的用户环境,其中用户环境下拥有3个部门:研发部门、行政部门和财务部门,针对该用户环境下的大数据分析的多hadoop分布式文件系统聚合技术及设计方法,包括以下步骤:
步骤1:每个部门所拥有的原始hdfs文件存储系统分别对应为:hadoop集群研发hd、hadoop集群行政hd和hadoop集群财务hd;hadoop集群研发hd部署在研发部门分布式服务器中,hadoop集群行政hd部署在行政部门分布式服务器中,hadoop集群财务hd部署在财务部门分布式服务器中,每个部门的所述原始hdfs文件存储系统中均存储有大量分级文件,所述hadoop集群研发hd所采用的根节点为hdfs研发部门,所述hadoop集群行政hd所采用的根节点为hdfs行政部门,所述hadoop集群财务hd所采用的根节点为hdfs财务部门。
步骤2:创建该用户环境下的hdfs聚合节点,所述创建hdfs聚合节点的步骤如下:
a.将所述分布式服务器进行归类,集中所有所述原始hdfs文件存储系统的所述根节点;该用户环境下的分布式服务器分为研发部门分布式服务器、行政部门分布式服务器和财务部门分布式服务器,该用户环境下3个部门的根节点分别为:hdfs研发部门、hdfs行政部门和hdfs财务部门;
b.将所有所述根节点作为叶节点使用,并将所有叶节点聚合为一个开放应用程序编程接口api;将hdfs研发部门、hdfs行政部门和hdfs财务部门作为叶节点使用,并聚合为一个开放的应用程序编程接口api;
c.对所述开放应用程序编程接口api进行新的命名,并命名为聚合hdfs数据分析,并作为所述聚合节点使用;
d.将所述聚合节点部署在新的分布式服务器hadoop数据分析集群中,创立聚合节点hdfs文件存储系统;
步骤3:用户执行map/reduce任务调度器,准备从所述聚合节点hdfs文件存储系统中请求查询研发部门的某个文件p的位置信息;
步骤4:所述聚合节点hdfs文件存储系统分析聚合节点的信息,找出叶节点——hdfs研发部门,并从中取得所述文件p位置信息,集中归纳并把整理完善的所述文件p位置信息的映射信息返回给所述map/reduce任务调度器;
步骤5:所述map/reduce任务调度器根据所述聚合节点hdfs文件存储系统返回的所述映射信息调度任务。
本发明所述的针对大数据分析的多hadoop分布式文件系统,在避免大量数据移动和不改变hadoop组件源代码的前提下,保证了计算任务和数据的本地化,大幅提高系统性能,提供了按不同的逻辑视图重新聚合hdfs并保证计算任务性能的灵活性;避免了数据竖井的形成,更好的利用资源,避免大量数据移动以取得更好的分析性能,实现了用户部署跨多hdfs的hadoop集群的可能性。
- 还没有人留言评论。精彩留言会获得点赞!