一种用户意见抽取方法及系统与流程
本发明涉及大数据领域,尤其涉及一种用户意见抽取方法及系统。
背景技术:
随着互联网的快速发展,细分领域的网站越来越多,例如汽车、餐饮、住宿等服务的网站。很多用户在细分领域中,伴随着自己的实际经验,会针对自己的服务发表自己的观点。用户的反馈对产品或者服务提供者具有重要的意义,特别是追踪用户对产品或者服务的舆情走向以及对产品或服务的后续改进。
对用户反馈数据的意见抽取是大数据分析的重点和难点,通过自动抽取方法,从海量的用户反馈数据中抽取大多数用户的关注点以进一步改进产品或服务。
现有技术中,用户意见的抽取技术方案主要包括:
1、通过人力从网上大量浏览用户对该产品的反馈结果,然后总结抽取,得到用户意见;
2、通过自然语言处理(nlp)相关算法进行典型意见抽取,首先使用词袋模型(bag-of-words,bow)对文本提取特征向量,然后使用k-means、akm或自组织映射(som)进行聚类分析得到类簇,进而得到用户意见。
通过人工手动的收集整理某产品用户的反馈意见,并将其通过一些辅助工具,比如excel等进行人工归纳总结,抽取出用户意见需要占用大量的人力资源,并且当数据量比较大的时候,比如公众号、头条号等用户量巨大的自媒体,受到内存以及计算能力等硬件资源的限制,很难全面考虑所有样本数据并进行总结。
人工总结的方式很难应用到自动化实现中,比如时下比较流行的舆情监控,要求系统可以实时把握某产品或者某领域的舆情走势,通过自动抓取互联网上所有相关数据并进行实时分析处理,得到群众对于该产品的整体舆情,而人工总结的方式显然不能满足该应用场景。
已有的通过bow模型结合聚类算法得到用户典型意见方法更多的适合长文本,比如新闻数据,这样文本特征才不至于过于稀疏,但用户的评论数据或者论坛的跟帖数据都是短语句表示,映射到几万维度的特征空间过于稀疏,无法用后续模型进行有效的处理,故而该方案取得的效果一般。
技术实现要素:
有鉴于此,本发明提供一种用户意见抽取方法及系统,以提供采集用户意见以及用户情感评分的技术方案。
本发明提供了一种用户意见抽取方法,该方法包括:
根据词向量模型处理文本数据,得到所述文本数据中语料的词向量集合;
根据所述词向量对句子进行处理得到句子向量;
对所述句子向量进行聚类分析得到用户的意见聚类簇;
抽取所述意见聚类簇的中心用户评论得到用户意见。
优选地,该方法还包括:
通过网络爬虫从网络抓取文本数据;
对文本数据进行预处理。
优选地,所述根据所述词向量对句子进行处理得到句子向量包括:
将句子中的词向量相加,或者对句子中的词向量进行加权平均。
优选地,该方法还包括:
根据循环神经网络模型处理所述句子向量得到用户意见的情感评分。
优选地,所述根据循环神经网络模型处理所述句子向量得到用户意见的情感评分包括:
根据所述词向量模型处理用户意见,得到所述用户意见的词向量;
对所述用户意见的词向量进行一维卷积;
对所述一维卷积的结果进行最大池化;
将所述最大池化的结果输入循环神经网络模型;
对所述循环神经网络模型输出的结果进行分类,得到用户意见的情感评分。
本发明提供了一种用户意见抽取系统,该系统包括:
词向量模块,用于根据词向量模型处理文本数据,得到所述文本数据中语料的词向量集合;
句子向量模块,用于根据所述词向量对句子进行处理得到句子向量;
聚类模块,用于对所述句子向量进行聚类分析得到用户的意见聚类簇;
抽取模块,用于抽取所述意见聚类簇的中心用户评论得到用户意见。
优选地,该系统还包括:
抓取模块,用于通过网络爬虫从网络抓取文本数据;
预处理模块,用于对文本数据进行预处理。
优选地,所述句子向量模块还用于将句子中的词向量相加,或者对句子中的词向量进行加权平均。
优选地,该系统还包括评分模块,用于根据循环神经网络模型处理所述句子向量得到用户意见的情感评分。
优选地,所述评分模块,用于根据所述词向量模型处理用户意见,得到所述用户意见的词向量;对所述用户意见的词向量进行一维卷积;对所述一维卷积的结果进行最大池化;将所述最大池化的结果输入循环神经网络模型;对所述循环神经网络模型输出的结果进行分类,得到用户意见的情感评分。
本发明可以自动的抽取出针对某个产品或服务的用户反馈的典型意见以及该意见的情感分析,从而避免了目前大多数采用的人工总结抽取的繁重任务,大幅度提高了生产效率。本发明依托于大数据,在数据的处理以及模型的训练过程中,通过分布式集群可以容纳更大规模的数据,使用了千万级别的数据进行模型学习,远远超出了单机的处理能力。
附图说明
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
图1是本发明提供的用户意见抽取的流程图;
图2a是本发明提供的基于词向量模型的用户意见抽取流程图;
图2b是基于循环神经网络的情感分类流程图;
图3是基于本发明的抽取用户意见及情感评分示意图;
图4a和图4b是基于本发明的两种车型动力的用户意见示意图;
图5是本发明提供的用户意见抽取系统示意图。
具体实施方式
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
如图1所示,本发明提供了用户意见的抽取方法,具体包括:
步骤105,通过网络爬虫从网络抓取文本数据;具体而言,可以通过网络爬虫抓取门户网站、自媒体、垂直媒体领域抓取用户对某个产品或者服务或者某个关键词的所有文本数据,比如对汽车领域某车型用户的论坛数据、口碑数据,并整理存入数据库,例如mongodb数据库;门户网站例如新浪、搜狐等网站,自媒体例如微信中的公众号、视频网站中的个人频道等,垂直媒体例如知乎、今日头条等。
步骤110,对文本数据进行预处理。具体而言,对抓取的文本数据进行分词,词与词之间用分隔符进行分隔,并虑无意义词,比如“的”、“了”等文字。分词可以采用现有的分词算法,例如基于字符串匹配的分词算法,基于理解的分词算法,基于统计的分词算法等。
步骤115,根据词向量模型处理文本数据,得到所述文本数据中语料的词向量集合;具体而言,用预处理后的语料数据训练深度神经网络word2vec模型,得到所有语料的词向量集合;将预处理后得到的分词输入深度神经网络word2vec模型可以得到词的向量。
步骤120,根据词向量对句子进行处理得到句子向量;在进行分词之后,每个句子可以对应若干个词,可以通过对句子中词的向量进行加和或者加和平均得到句子向量。
步骤125,对句子向量进行聚类分析得到用户的意见聚类簇;具体而言,将得句子向量通过k-means聚类算法或者akm算法等进行聚类分析,人为指定聚类中心个数(例如1个),得到用户对产品或服务的意见聚类簇;
步骤130,抽取所述意见聚类簇的中心用户评论得到用户意见。具体而言,根据聚类中心个数,例如1个,则抽取意见聚类簇中的1个意见作为用户意见。
步骤135,根据循环神经网络模型处理句子向量得到用户意见的情感评分。具体而言,将句子向量作为循环神经网络gru的输入,得到用户评论的情感评分,评分结果为正面、负面或者中性。
本发明主要侧重于两个方面,一个方面是基于词向量模型的用户意见抽取,另一个方面是基于深度神经网络的情感分析。
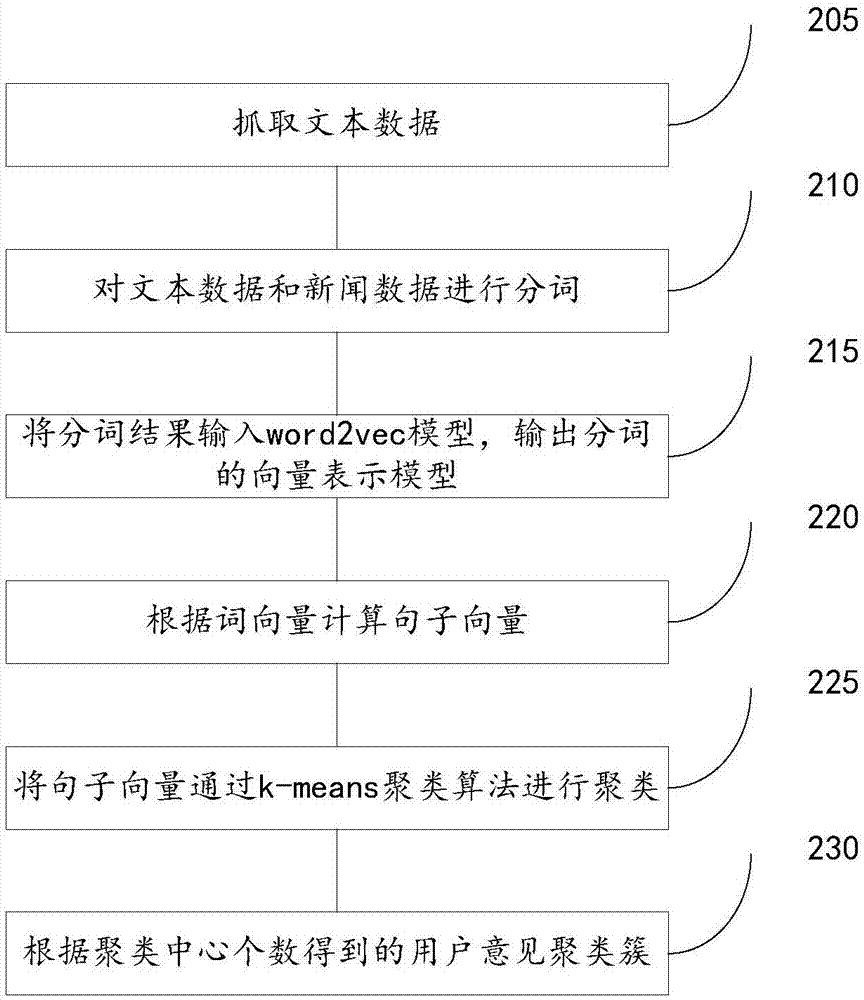
图2a示出了基于词向量模型的用户意见抽取流程,具体包括:
步骤205,抓取文本数据;
步骤210,对文本数据和新闻数据进行分词;
步骤215,将分词结果输入word2vec模型,输出分词的向量表示模型,即每个中文词在语义特征空间都有一个多维向量表示,相关语义的词特征向量距离更小,而不相关词则距离较大,该模型还有更加高层语义特征表示,比如vec(“中国”)-vec(“北京”)=vec(“美国”)–vec(“华盛顿”)。词向量a与词向量b之间的距离度量采用余弦距离,公式如下:
其中n为向量长度,ai,bi为向量元素。word2vec模型通过学习输入语料得到词与词之间的相关性并把每个词映射到多维的语义空间中。在word2vec模型的训练过程中,通过词的上下文信息预测该词,并且在计算过程中结合了哈弗曼编码,大幅度提高了运算速度。若已知某词的上下文词,推测该词的出现概率如公式(2):
其中lw表示在哈弗曼树中节点经过的路径节点,p(w|content(w))表示由词w的上下文推导w的概率,p(d|v,θ)为节点处分类概率,σ为sigmod函数,每个节点都可以表示成逻辑回归的二分类问题,对每个节点,求解最大似然函数,得到最终所有节点的分类参数以及词的向量表示。
步骤220,根据词向量计算句子向量。计算句子向量可以有不同的方法,例如将词向量相加,或者将词向量相加后计算均值。计算均值的公式如下:
其中vec(sentence)表示句向量,vec(w)表示词w的词向量,len(sentence)为句子长度,即词个数。
步骤225,将句子向量通过k-means聚类算法进行聚类。在进行聚类时,可以根据不同领域或者应用场景,可以选择不同的聚类中心个数,比如针对汽车垂直领域,词向量维度为200,聚类中心数300,训练语料可以为千万条用户评论语料。
步骤230,根据聚类中心个数得到的用户意见聚类簇,从而获得用户意见。
图2b示出了基于循环神经网络的情感分类流程,具体包括:
步骤235,输入数据,例如用户意见的分词结果;
步骤240,对输入的数据进行词向量编码;
步骤245,对词向量进行一维卷积;
步骤250,将卷积结果进行最大池化;
步骤255,将最大池化结果输入gru循环神经网络单元;
步骤260,将神经网络输出结果进行分类,例如使用softmax函数进行分类,得到用户的情感分类,并给出置信度。情感分类可以为正面情感、负面情感、中性情感,可以用情感评分来表达为1、-1、0。
图3示出了本发明提供的技术方案提取的用户意见以及用户的情感评分示意图。从图3可以看到,在汽车领域的应用中,本发明能够从海量的用户文本数据中抽取出用户意见,比如“性价比不好”,并且通过深度神经网络算法把该意见作了负面的情感分类,不需要耗费大量的人力对海量的用户评论数据进行人工整理总结,非常便捷的满足其他业务线以及相应产品的需求。
图4a和图4b是利用本发明对两个不同的车型上市后,对其动力方面的评论的自动抽取用户意见的结果。可以看出,图4a中用户对动力方面的意见是“动力还是很好”、“动力充足”,图4b中用户对动力方面的意见是“起步有点肉”。通过本发明能够直观地获取市场对新上市车型动力的反馈。
图5是本发明提供的用户意见抽取系统示意图,具体包括:抓取模块505,用于通过网络爬虫从网络抓取文本数据;预处理模块510,用于对文本数据和新闻数据进行预处理;词向量模块515,用于根据词向量模型处理文本数据,得到文本数据中语料的词向量集合;句子向量模块520,用于根据词向量对句子进行处理得到句子向量;聚类模块525,用于对句子向量进行聚类分析得到用户的意见聚类簇;抽取模块530,用于抽取意见聚类簇的中心用户评论得到用户意见;评分模块535,用于根据循环神经网络模型处理句子向量得到用户意见的情感评分。
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!