一种结合直接度量和间接度量的行人再识别方法与流程
本发明涉及一种图像识别技术,尤其是涉及一种结合直接度量和间接度量的行人再识别方法。
背景技术:
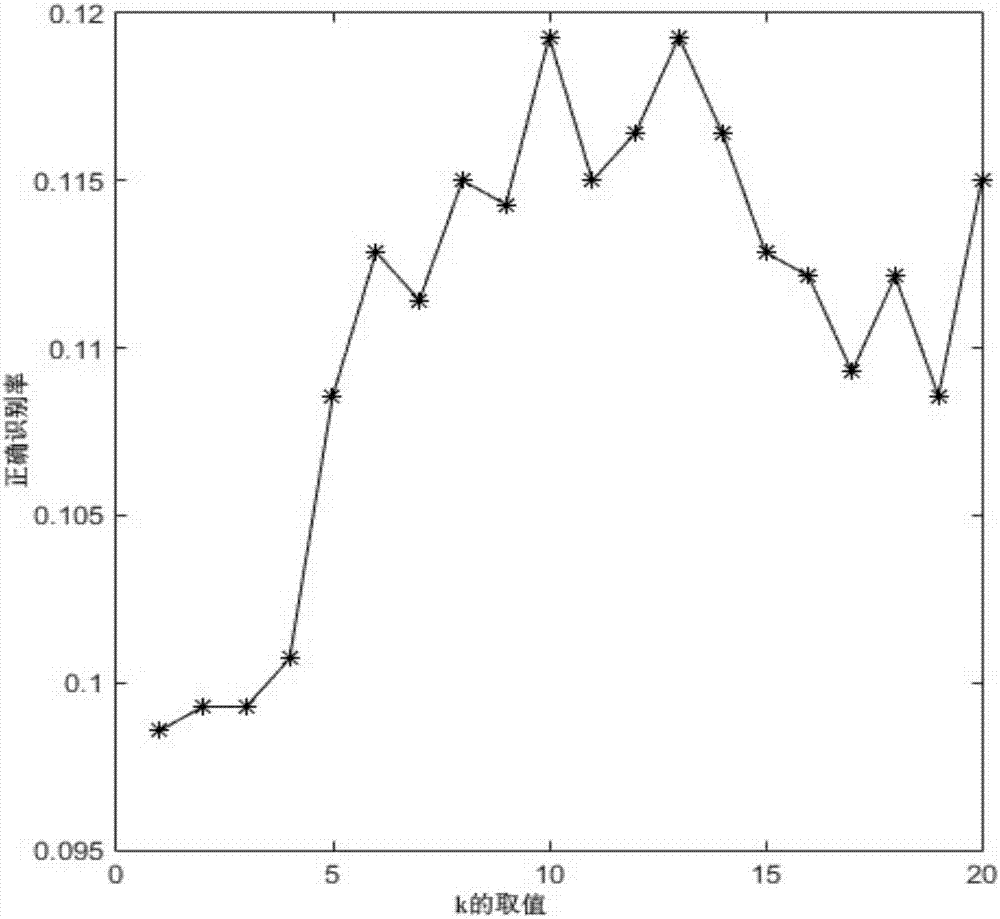
:行人再识别是计算机视觉中的核心技术,现如今很多计算机视觉中的高层应用都依赖于准确的行人识别结果,如目标跟踪、智能视频监控等。然而,由于图像存在光照变化、视角变化、遮挡等问题,因此行人再识别一直是计算机视觉中最具有挑战性的任务之一。作为多种视觉应用的基础和富有挑战性的任务,行人再识别技术在计算机视觉领域一直广受关注,如何更好地对行人进行再识别,国内外相关机构进行了深入地研究。度量学习的主要任务是学习一个线性或非线性的映射,将行人高维表观特征映射到目标空间进行度量,使得同一行人的距离更小,不同行人的距离更大。kostingerm,hirzerm,wohlhartp,etal.largescalemetriclearningfromequivalenceconstraints[c]//computervisionandpatternrecognition(cvpr),2012:2288-2295.(马丁-克斯汀格,马丁-海瑞泽尔,保罗-沃海哈瑞特,等价约束中的大尺度度量学习[c].计算机视觉与模式识别大会,2012,2288-2295),其提出了保持最简单、最直接度量学习算法,其将两个高斯分布的对数似然比检验作为度量学习算法。chend,yuanz,huag,etal.similaritylearningonanexplicitpolynomialkernelfeaturemapforpersonre-identification[c]//conferenceoncomputervisionandpatternrecognition,2015:1565-1573(陈大鹏,袁泽建,华刚,基于多项式核特征映射的相似性学习的行人再识别[c].计算机视觉与模式识别大会,2015,1565-1573),其将内核特征图作为相似性度量学习算法,能够匹配行人图像中某个块与另一行人图像中所有块,也能度量相同位置块的相似性。carr,peter.personre-identificationusingdeformablepatchmetriclearning[c]//ieeewinterconferenceonapplicationsofcomputervision,2016:1278-1287.(卡尔,彼得,基于弹性块度量学习的行人再识别[c].ieee,计算机视觉的应用研讨会,2016,1278-1287),其提出弹性模型,在对探测图像与目标图像中的块进行匹配时,允许错位匹配,且块错位的范围可以调节,有效地解决了不同摄像机下行人图像的视角和姿态的变化问题。zhangy,lib,luh,etal.sample-specificsvmlearningforpersonre-identification[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2016:1278-1287(张影,李宝华,卢湖川,基于明确样本的svm训练的行人再识别[c].计算机视觉与模式识别,2016,1278-1287),其考虑到已有度量学习都是计算探测图像与目标图像的相似性,而忽略了探测图像与目标图像自身的差异性,因此提出将图像自身的差异性也作为度量学习的一部分,学习得到的度量对于每幅图像都有较高的适应性。上述的度量学习算法,直接利用了探测图像与目标图像自身包含的判别信息来计算探测图像与目标图像之间的相似性,而忽略了与探测图像和目标图像相关的其它图像的判别信息对于计算两者之间相似性的重要性。liw,zhaor,wangx.humanreidentificationwithtransferredmetriclearning[c]//asianconferenceoncomputervision.springerberlinheidelberg,2012:31-44(李伟,赵瑞,王小刚,基于转移度量学习的行人再识别[c].计算机视觉亚洲会议,2012,31-44),其在转移框架下,利用目标图像的k近邻(k-nearestneighbor,knn)及其groundtruth下对应的探测图像来训练度量,减少了因摄像头变化导致的识别错误。zhongz,zhengl,caod,etal.re-rankingpersonre-identificationwithk-reciprocalencoding[j].conferenceoncomputervisionandpatternrecognition,2017(钟准,郑亮,曹东林,使用k相互编码的行人再识别重排序[c].计算机视觉与模式识别,2017),其将探测图像和目标图像各自的k相互近邻的重合数作为两者的相似性,充分利用近邻图像的判别信息来度量探测图像和目标图像的相似性。间接度量方式能够很好地利用与探测图像和目标图像相关的其它图像的识别信息来度量两者之间的相似性,但是却忽略了图像自身的识别信息,从而降低了识别效果。基于以上原因,有必要研究一种结合直接度量和间接度量的行人再识别技术,要求该技术能够充分利用两幅图像所有的信息进行判别,不仅要充分利用两幅图像自身的判别信息,同时还要充分利用与两幅图像相关的其它图像的判别信息进行识别,以提高识别率。技术实现要素:本发明所要解决的技术问题是提供一种结合直接度量和间接度量的行人再识别方法,其不仅充分利用了两幅图像自身的判别信息,而且还充分利用了与两幅图像相关的其它图像的判别信息,从而大幅提高了行人识别精度。本发明解决上述技术问题所采用的技术方案为:一种结合直接度量和间接度量的行人再识别方法,其特征在于包括以下步骤:①选取一个包含训练集和测试集的行人图像库,训练集包含有针对多个不同行人的行人图像,测试集也包含有针对多个不同行人的行人图像;其中,行人图像的尺寸大小为m×n像素;设定训练集中包含的行人图像的总幅数为num;然后根据训练集中的num幅行人图像,将训练集分为第一待识别图像库和第一目标图像库,具体过程为:在训练集中,针对每个行人对应的多幅行人图像,从中任意挑选,以两幅行人图像作为一组组对,若每对行人图像来自不同摄像头,则将该对行人图像中的一幅行人图像归入第一待识别图像库、另一幅行人图像归入第一目标图像库;若该对行人图像来自同一摄像头,则丢弃该对行人图像;再设定第一待识别图像库中包含的行人图像的总幅数为total1,设定第一目标图像库中包含的行人图像的总幅数也为total1;其中,num和total1均为正整数,total1≥100,num≥2total1;设定测试集中的第二待识别图像库中包含的行人图像的总幅数为total2,设定测试集中的第二目标图像库中包含的行人图像的总幅数为total2';其中,total2和total2'均为正整数,total2≥1,total2'≥10;提取第一待识别图像库和第一目标图像库及第二待识别图像库和第二目标图像库各自中的每幅行人图像的特征向量;其中,特征向量的维数为符号为向下取整符号;②采用结构为的bp神经网络将第一目标图像库中的所有行人图像各自的特征向量和第一待识别图像库中的所有行人图像各自的特征向量映射到嵌入空间中;然后采用内积法求解第一待识别图像库中的每幅行人图像在嵌入空间中的嵌入特征向量与第一目标图像库中的各幅行人图像在嵌入空间中的嵌入特征向量之间的相似性得分,并作为第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的直接相似性得分,将第一待识别图像库中的第u幅行人图像与第一目标图像库中的第v幅行人图像之间的直接相似性得分记为gdirect(su,tv),gdirect(su,tv)=<f(su),f(tv)>=(f(su))tf(tv);其中,x表示第一目标图像库中的行人图像的特征向量或第一待识别图像库中的行人图像的特征向量,f(x)表示x映射到嵌入空间中后得到的嵌入特征向量,也即为第一目标图像库中的行人图像在嵌入空间中的嵌入特征向量或第一待识别图像库中的行人图像在嵌入空间中的嵌入特征向量,tanh()为bp神经网络的激活函数,wt为w的转置,w表示维数为d1×d2的映射矩阵,d1表示x的维数,d2表示f(x)的维数,b表示维数为d2的偏差向量,||tanh(wtx+b)||2表示求tanh(wtx+b)的2-范数,u和v均为正整数,1≤u≤total1,1≤v≤total1,su表示第一待识别图像库中的第u幅行人图像的特征向量,tv表示第一目标图像库中的第v幅行人图像的特征向量,符号“<>”为内积运算符号,(f(su))t为f(su)的转置,f(su)表示su映射到嵌入空间中后得到的嵌入特征向量,f(tv)表示tv映射到嵌入空间中后得到的嵌入特征向量;③采用bp算法构建映射矩阵求解最优化模型,描述为:然后采用梯度下降法求解上述映射矩阵求解最优化模型,得到w和b各自的值;其中,min()为求最小值函数,||w||f为求w的f-范数,th表示第一目标图像库中的第h幅行人图像的特征向量,h为正整数,1≤h≤total1,gdirect(su,th)表示第一待识别图像库中的第u幅行人图像在嵌入空间中的嵌入特征向量f(su)与第一目标图像库中的第h幅行人图像在嵌入空间中的嵌入特征向量f(th)之间的相似性得分,也即表示第一待识别图像库中的第u幅行人图像与第一目标图像库中的第h幅行人图像之间的直接相似性得分,表示su对应的正样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像为同一行人,则将第一目标图像库中的该幅行人图像的特征向量归入中,表示su对应的负样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像不为同一行人,则将第一目标图像库中的该幅行人图像的特征向量归入中,表示求中的元素的总个数,表示求中的元素的总个数,[]+为铰链损失函数;④计算第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的间接相似性得分,将第一待识别图像库中的第u幅行人图像与第一目标图像库中的第v幅行人图像之间的间接相似性得分记为gindirect(su,tv),其中,k为正整数,r(su,k)表示由第一待识别图像库中的第u幅行人图像的k相互近邻组成的集合,r(tv,k)表示由第一目标图像库中的第v幅行人图像的k相互近邻组成的集合,符号“∩”为集合交运算符号,符号“∪”为集合并运算符号,|r(su,k)∩r(tv,k)|表示求r(su,k)∩r(tv,k)中的元素的总个数,|r(su,k)∪r(tv,k)|表示求r(su,k)∪r(tv,k)中的元素的总个数;⑤根据第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的直接相似性得分和间接相似性得分,对第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的最终相似性得分进行描述,将第一待识别图像库中的第u幅行人图像与第一目标图像库中的第v幅行人图像之间的最终相似性得分记为g(su,tv),描述为:g(su,tv)=βdirect×gdirect(su,tv)+βindirect×gindirect(su,tv),其中,βdirect为gdirect(su,tv)的权值参数,βindirect为gindirect(su,tv)的权值参数,βdirect+βindirect=1;⑥根据第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的最终相似性得分的描述,训练获取βdirect和βindirect的值;然后根据训练获取的βdirect和βindirect的值,得到最终相似性得分计算模型,描述为:g(s*,t*)=βdirect×gdirect(s*,t*)+βindirect×gindirect(s*,t*),其中,s*表示任意一幅待识别图像的特征向量,t*表示任意一幅目标图像的特征向量,gdirect(s*,t*)表示任意一幅待识别图像与任意一幅目标图像之间的直接相似性得分,gindirect(s*,t*)表示任意一幅待识别图像与任意一幅目标图像之间的间接相似性得分,g(s*,t*)表示任意一幅待识别图像与任意一幅目标图像之间的最终相似性得分;⑦按照步骤②和步骤④的过程,以相同的操作,获取第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的直接相似性得分和间接相似性得分,将第二待识别图像库中的第u'幅行人图像与第二目标图像库中的第v'幅行人图像之间的直接相似性得分和间接相似性得分对应记为和然后将第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的直接相似性得分和间接相似性得分输入g(s*,t*)=βdirect×gdirect(s*,t*)+βindirect×gindirect(s*,t*)中进行测试,得到第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的最终相似性得分,将第二待识别图像库中的第u'幅行人图像与第二目标图像库中的第v'幅行人图像之间的最终相似性得分记为再根据第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的最终相似性得分,识别第二待识别图像库中的每幅行人图像;对于第二待识别图像库中的第u'幅行人图像,找出该幅行人图像与第二目标图像库中的所有行人图像之间的最终相似性得分中的最高得分,将该幅行人图像中的行人识别为最高得分所对应的第二目标图像库中的行人图像中的行人;其中,u'和v'均为正整数,1≤u'≤total2,1≤v'≤total2',表示第二待识别图像库中的第u'幅行人图像的特征向量,表示第二目标图像库中的第v'幅行人图像的特征向量。所述的步骤①中,第一待识别图像库中的每幅行人图像的特征向量和第一目标图像库中的每幅行人图像的特征向量及第二待识别图像库中的每幅行人图像的特征向量和第二目标图像库中的每幅行人图像的特征向量的提取过程相同,将第一待识别图像库或第一目标图像库或第二待识别图像库或第二目标图像库作为待处理库,对于待处理库中的第t幅行人图像,作为当前图像,将当前图像的特征向量记为xt,其中,t为正整数,1≤t≤total*,total*表示待处理库中包含的行人图像的总幅数,xt的获取过程为:①_1、将当前图像划分成多个尺寸大小为10×10像素、步长为5像素的相互重叠的图像块;①_2、提取当前图像中的每个图像块的hsv颜色特征、siltp纹理特征以及scncd特征;然后获取当前图像中的每个图像块的特征向量,对于当前图像中的第p个图像块,该图像块的特征向量为由该图像块的hsv颜色特征、siltp纹理特征以及scncd特征按序组合而成的列向量;其中,p为正整数,1≤p≤p,p表示当前图像中包含的图像块的总个数,符号为向下取整符号;①_3、获取当前图像中的每个水平条的特征向量,对于当前图像中的第q个水平条,该水平条的特征向量中的每个bin下的值为属于该水平条的所有图像块的特征向量中相对应的bin下的值中的最大值;其中,q为正整数,1≤q≤q,q表示当前图像中包含的水平条的总个数,①_4、将当前图像中的所有水平条的特征向量按序组成的列向量作为当前图像的特征向量xt。所述的步骤⑥中训练获取βdirect和βindirect的值的具体过程为:⑥_1、构建权值参数求解最优化模型,描述为:其中,min()为求最小值函数,β为βdirect和βindirect组成的向量,β=[βdirect,βindirect],||β||f为求β的f-范数,ξu表示su对应的松弛项,λ用于平衡正则项和total1个松弛项之和λ的取值为0.01,“s.t.”表示“受约束于……”,βt为β的转置,,y={yv,h|1≤v≤total1,1≤h≤total1},表示第一待识别图像库中的第u幅行人图像对应的正样本排在第一待识别图像库中的第u幅行人图像对应的负样本前面,表示第一待识别图像库中的第u幅行人图像对应的正样本排在第一待识别图像库中的第u幅行人图像对应的负样本后面,表示第一待识别图像库中的第u幅行人图像对应的正样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像为同一行人,则将第一目标图像库中的该幅行人图像归入中,表示第一待识别图像库中的第u幅行人图像对应的负样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像不为同一行人,则将第一目标图像库中的该幅行人图像归入中,表示求中的元素的总个数,表示求中的元素的总个数,g1(su,tv)为由gdirect(su,tv)与gindirect(su,tv)构成的相似性得分向量,g1(su,tv)=[gdirect(su,tv),gindirect(su,tv)],g1(su,th)为由第一待识别图像库中的第u幅行人图像与第一目标图像库中的第h幅行人图像之间的直接相似性得分gdirect(su,th)与第一待识别图像库中的第u幅行人图像与第一目标图像库中的第h幅行人图像之间的间接相似性得分gindirect(su,th)构成的相似性得分向量,δ(y*,y)表示y*与y之间的auc损失;⑥_2、利用ranksvm求解上述权值参数求解最优化模型,得到β,即得到βdirect和βindirect。与现有技术相比,本发明的优点在于:1)本发明方法采用融合直接度量和间接度量进行行人再识别的方法,直接度量能够基于两幅图像自身的判别信息度量图像对的相似性,间接度量能够基于与两幅图像相关的k相互近邻的判别信息度量图像对的相似性,依据与两幅图像相关的其它图像的判别信息计算相似性的方法可以有效消除相似的不同行人的误匹配,两者结合使用能够充分利用与待识别图像、目标图像相关的所有判别信息,从而可有效提高识别准确率。2)本发明方法利用数据库中的样本训练出适用于取自不同场景的不同数据库的权值参数,而不是简单地给出固定的直接相似性得分和间接相似性得分的权值,利用本发明方法获得的权值参数很好地权衡了直接相似性得分和间接相似性得分的占比,从而提高了识别精度。附图说明图1为本发明方法的总体实现框图;图2a为本发明方法中的间接度量中的k相互近邻的k值对识别率的影响趋势图;图2b为本发明方法中的间接度量中的k相互近邻的k值对平均精度的影响趋势图。具体实施方式以下结合附图实施例对本发明作进一步详细描述。本发明提出的一种结合直接度量和间接度量的行人再识别方法,其总体实现框图如图1所示,其包括以下步骤:①选取一个包含训练集和测试集的行人图像库,训练集包含有针对多个不同行人的行人图像,测试集也包含有针对多个不同行人的行人图像;其中,行人图像的尺寸大小为m×n像素。设定训练集中包含的行人图像的总幅数为num;然后根据训练集中的num幅行人图像,将训练集分为第一待识别图像库和第一目标图像库,具体过程为:在训练集中,针对每个行人对应的多幅行人图像,从中任意挑选,以两幅行人图像作为一组组对,若每对行人图像来自不同摄像头,则将该对行人图像中的一幅行人图像归入第一待识别图像库、另一幅行人图像归入第一目标图像库;若该对行人图像来自同一摄像头,则丢弃该对行人图像;再设定第一待识别图像库中包含的行人图像的总幅数为total1,设定第一目标图像库中包含的行人图像的总幅数也为total1;其中,num和total1均为正整数,total1≥100,num≥2total1。设定测试集中的第二待识别图像库中包含的行人图像的总幅数为total2,设定测试集中的第二目标图像库中包含的行人图像的总幅数为total2';其中,total2和total2'均为正整数,total2≥1,total2'≥10;在此,测试集中已明确给出待识别图像库和目标图像库,即作为第二待识别图像库和第二目标图像库。提取第一待识别图像库和第一目标图像库及第二待识别图像库和第二目标图像库各自中的每幅行人图像的特征向量;其中,特征向量的维数为符号为向下取整符号。在此具体实施例中,步骤①中,第一待识别图像库中的每幅行人图像的特征向量和第一目标图像库中的每幅行人图像的特征向量及第二待识别图像库中的每幅行人图像的特征向量和第二目标图像库中的每幅行人图像的特征向量的提取过程相同,将第一待识别图像库或第一目标图像库或第二待识别图像库或第二目标图像库作为待处理库,对于待处理库中的第t幅行人图像,作为当前图像,将当前图像的特征向量记为xt,其中,t为正整数,1≤t≤total*,total*表示待处理库中包含的行人图像的总幅数,xt的获取过程为:①_1、为了减少视角变化对行人图像的影响,将当前图像划分成多个尺寸大小为10×10像素、步长为5像素的相互重叠的图像块。①_2、提取当前图像中的每个图像块的hsv颜色特征、siltp纹理特征以及scncd特征;然后获取当前图像中的每个图像块的特征向量,对于当前图像中的第p个图像块,该图像块的特征向量为由该图像块的hsv颜色特征、siltp纹理特征以及scncd特征按序组合而成的列向量;其中,p为正整数,1≤p≤p,p表示当前图像中包含的图像块的总个数,符号为向下取整符号。①_3、获取当前图像中的每个水平条的特征向量,对于当前图像中的第q个水平条,该水平条的特征向量中的每个bin下的值为属于该水平条的所有图像块的特征向量中相对应的bin下的值中的最大值,如:设属于一个水平条的图像块共有5个图像块,则先找出这5个图像块各自的特征向量中的第1个bin下的值中的最大值,设第3个图像块的特征向量中的第1个bin下的值最大,那么将第3个图像块的特征向量中的第1个bin下的值作为该水平条的特征向量中的第1个bin下的值,依次类推;其中,q为正整数,1≤q≤q,q表示当前图像中包含的水平条的总个数,①_4、将当前图像中的所有水平条的特征向量按序组成的列向量作为当前图像的特征向量xt。考虑到单个颜色模型并不能保证对所有光照变化的鲁棒性,所以提取scncd特征时,提取了多个颜色模型下的特征,如rgb、正则化rgb、l1l2l3、以及hsv模型。考虑到多尺度下能够增加特征对尺度的鲁棒性,对于一幅尺寸大小为128×48像素的行人图像,降采样后分别得到尺寸大小为64×24像素的图像和尺寸大小为32×12像素的图像,提取每个尺度下图像的特征。对每个图像块提取8×8×8bin的hsv特征、两个尺度下的siltp特征(和)、以及4个颜色模型下的scncd特征(每个模型下特征为16bin),每个尺度下的图像划分得到的水平条的数目分别为24、11、5,最终得到的行人图像的特征向量的维度为(8×8×8+34×2+16×4)×(24+11+5)=29520。其中,hsv是smithar.colorgamuttransformpairs[j].acmsiggraphcomputergraphics,1978,12(3):12-19.(史密斯-艾尔维-瑞,颜色域转化对[j].acmsiggraph计算机图形,1978,第12期(3):12-19)提出的颜色特征提取方法,siltp是liaos,zhaog,kellokumpuv,etal.modelingpixelprocesswithscaleinvariantlocalpatternsforbackgroundsubtractionincomplexscenes[c]//computervisionandpatternrecognition(cvpr),2010:1301-1306.(廖胜才,赵国英.复杂场景下背景消除的尺度不变局部模式的像素建模过程[c].计算机视觉与模式识别大会,2010:1301-1206)提出的纹理特征提取方法。②为了能够从提取的行人图像的特征向量中得到更具代表性的特征,使得在度量图像对之间相似性时能够更加充分地体现两者之间的相似性,本发明采用将第一目标图像库中的每幅行人图像的特征向量和第一待识别图像库中的每幅行人图像的特征向量映射到嵌入空间中进行求解图像对(imagepairs)之间相似性得分的方法,得到图像对之间的直接相似性得分。采用结构为的bp神经网络将第一目标图像库中的所有行人图像各自的特征向量和第一待识别图像库中的所有行人图像各自的特征向量映射到嵌入空间中;然后采用简单的内积法求解第一待识别图像库中的每幅行人图像在嵌入空间中的嵌入特征向量与第一目标图像库中的各幅行人图像在嵌入空间中的嵌入特征向量之间的相似性得分,并作为第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的直接相似性得分,将第一待识别图像库中的第u幅行人图像与第一目标图像库中的第v幅行人图像之间的直接相似性得分记为gdirect(su,tv),gdirect(su,tv)=<f(su),f(tv)>=(f(su))tf(tv);其中,x表示第一目标图像库中的行人图像的特征向量或第一待识别图像库中的行人图像的特征向量,f(x)表示x映射到嵌入空间中后得到的嵌入特征向量,也即为第一目标图像库中的行人图像在嵌入空间中的嵌入特征向量或第一待识别图像库中的行人图像在嵌入空间中的嵌入特征向量,tanh()为bp神经网络的激活函数,wt为w的转置,w表示维数为d1×d2的映射矩阵,w未知需求解,d1表示x的维数,d1已知,即为d2表示f(x)的维数,d2人为设定即已知,b表示维数为d2的偏差向量,b未知需求解,||tanh(wtx+b)||2表示求tanh(wtx+b)的2-范数,u和v均为正整数,1≤u≤total1,1≤v≤total1,su表示第一待识别图像库中的第u幅行人图像的特征向量,tv表示第一目标图像库中的第v幅行人图像的特征向量,符号“<>”为内积运算符号,(f(su))t为f(su)的转置,f(su)表示su映射到嵌入空间中后得到的嵌入特征向量,f(tv)表示tv映射到嵌入空间中后得到的嵌入特征向量。③bp神经网络的结构需要通过建立模型并经过最优化模型求解得到bp神经网络的最优结构,上述bp神经网络本质上是一个单层的神经网络,而bp算法是一种以误差平方和为目标函数,用梯度下降法求其最小值,从而可得到bp神经网络的最优结构的算法。因此,本发明采用已有的bp算法构建映射矩阵求解最优化模型,描述为:然后采用梯度下降法求解上述映射矩阵求解最优化模型,得到w和b各自的值;其中,min()为求最小值函数,||w||f为求w的f-范数,th表示第一目标图像库中的第h幅行人图像的特征向量,h为正整数,1≤h≤total1,gdirect(su,th)表示第一待识别图像库中的第u幅行人图像在嵌入空间中的嵌入特征向量f(su)与第一目标图像库中的第h幅行人图像在嵌入空间中的嵌入特征向量f(th)之间的相似性得分,也即表示第一待识别图像库中的第u幅行人图像与第一目标图像库中的第h幅行人图像之间的直接相似性得分,表示su对应的正样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像为同一行人,则将第一目标图像库中的该幅行人图像的特征向量归入中,表示su对应的负样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像不为同一行人,则将第一目标图像库中的该幅行人图像的特征向量归入中,表示求中的元素的总个数,表示求中的元素的总个数,[]+为铰链损失函数。在此,在采用梯度下降法求解映射矩阵求解最优化模型的过程中,需要确定bp神经网络中的隐含层的节点数,及bp神经网络的学习率,但对于不同的数据库,bp神经网络中的隐含层的节点数和bp神经网络的学习率有所差异,如对于makret-1501数据库和cuhk03数据库,bp神经网络中的隐含层的节点数和bp神经网络的学习率可选用相同的值,bp神经网络中的隐含层的节点数均为200,bp神经网络的学习率均为10-2。④为了充分利用与第一待识别图像库中的行人图像和第一目标图像库中的行人图像相关的其它图像的判别信息来识别两幅行人图像,本发明采用求解第一待识别图像库中的行人图像和第一目标图像库中的行人图像各自的k相互近邻集合中的重叠图像数作为图像对之间的间接相似性得分的方法。计算第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的间接相似性得分,将第一待识别图像库中的第u幅行人图像与第一目标图像库中的第v幅行人图像之间的间接相似性得分记为其中,k为正整数,r(su,k)表示由第一待识别图像库中的第u幅行人图像的k相互近邻组成的集合,r(tv,k)表示由第一目标图像库中的第v幅行人图像的k相互近邻组成的集合,符号“∩”为集合交运算符号,符号“∪”为集合并运算符号,|r(su,k)∩r(tv,k)|表示求r(su,k)∩r(tv,k)中的元素的总个数,|r(su,k)∪r(tv,k)|表示求r(su,k)∪r(tv,k)中的元素的总个数。在此,图像的k相互近邻由zhongz,zhengl,caod,etal.re-rankingpersonre-identificationwithk-reciprocalencoding[j].conferenceoncomputervisionandpatternrecognition,2017(钟准,郑亮,曹东林,使用k相互编码的行人再识别重排序[c].计算机视觉与模式识别,2017)中提出。在此具体实施过程中,k的取值对于识别率影响较大,通过实验验证表明,对于makret-1501数据库,k可取值为20;对于cuhk03数据库,k可取值为14。⑤由于直接度量能够基于两幅图像自身的判别信息度量图像对的相似性,间接度量能够基于与两幅图像相关的其它图像的判别信息度量图像对的相似性,为了充分利用第一待识别图像库中的行人图像和第一目标图像库中的行人图像的所有判别信息进行识别,所以本发明采用加权融合的方法将第一待识别图像库中的行人图像与第一目标图像库中的行人图像之间的直接相似性得分和间接相似性得分相加,得到第一待识别图像库中的行人图像与第一目标图像库中的行人图像之间的最终相似性得分。即:根据第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的直接相似性得分和间接相似性得分,对第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的最终相似性得分进行描述,将第一待识别图像库中的第u幅行人图像与第一目标图像库中的第v幅行人图像之间的最终相似性得分记为g(su,tv),描述为:g(su,tv)=βdirect×gdirect(su,tv)+βindirect×gindirect(su,tv),其中,βdirect为gdirect(su,tv)的权值参数,βindirect为gindirect(su,tv)的权值参数,βdirect+βindirect=1。⑥根据第一待识别图像库中的每幅行人图像与第一目标图像库中的各幅行人图像之间的最终相似性得分的描述,训练获取βdirect和βindirect的值;然后根据训练获取的βdirect和βindirect的值,得到最终相似性得分计算模型,描述为:g(s*,t*)=βdirect×gdirect(s*,t*)+βindirect×gindirect(s*,t*),其中,s*表示任意一幅待识别图像的特征向量,t*表示任意一幅目标图像的特征向量,gdirect(s*,t*)表示任意一幅待识别图像与任意一幅目标图像之间的直接相似性得分,gindirect(s*,t*)表示任意一幅待识别图像与任意一幅目标图像之间的间接相似性得分,g(s*,t*)表示任意一幅待识别图像与任意一幅目标图像之间的最终相似性得分。在此具体实施例中,由于不同数据库选取不同场景下的行人图像,导致数据库的视角、光照、背景等变化不相同,在某个场景中具有很强判别性的特征在另一个场景中可能变得无关紧要,因此提前预定义好的权值参数不能适用于所有的数据库。所以本发明采用基于数据库中的样本训练权值参数的方法,得到针对数据库自身特点的权值参数。为了训练权值参数,需要构建权值参数求解最优化模型,通过利用数据库中的样本训练模型得到权值参数。即:步骤⑥中训练获取βdirect和βindirect的值的具体过程为:⑥_1、构建权值参数求解最优化模型,描述为:其中,min()为求最小值函数,β为βdirect和βindirect组成的向量,β=[βdirect,βindirect],||β||f为求β的f-范数,ξu表示su对应的松弛项,λ用于平衡正则项和total1个松弛项之和λ的取值为0.01,“s.t.”表示“受约束于……”,βt为β的转置,,y={yv,h|1≤v≤total1,1≤h≤total1},表示第一待识别图像库中的第u幅行人图像对应的正样本排在第一待识别图像库中的第u幅行人图像对应的负样本前面,表示第一待识别图像库中的第u幅行人图像对应的正样本排在第一待识别图像库中的第u幅行人图像对应的负样本后面,表示第一待识别图像库中的第u幅行人图像对应的正样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像为同一行人,则将第一目标图像库中的该幅行人图像归入中,表示第一待识别图像库中的第u幅行人图像对应的负样本集合,若第一目标图像库中的一幅行人图像与第一待识别图像库中的第u幅行人图像不为同一行人,则将第一目标图像库中的该幅行人图像归入中,表示求中的元素的总个数,表示求中的元素的总个数,g1(su,tv)为由gdirect(su,tv)与gindirect(su,tv)构成的相似性得分向量,g1(su,tv)=[gdirect(su,tv),gindirect(su,tv)],g1(su,th)为由第一待识别图像库中的第u幅行人图像与第一目标图像库中的第h幅行人图像之间的直接相似性得分gdirect(su,th)与第一待识别图像库中的第u幅行人图像与第一目标图像库中的第h幅行人图像之间的间接相似性得分gindirect(su,th)构成的相似性得分向量,δ(y*,y)表示y*与y之间的auc损失。⑥_2、利用ranksvm求解上述权值参数求解最优化模型,得到β,即得到βdirect和βindirect。在此,ranksvm由joachimst,finleyt,yucnj.cutting-planetrainingofstructuralsvms[j].machinelearning,2009,77(1):27-59.(索斯藤-约芝,托马斯-费利益,约翰-余春娜.结构化支持向量机的切割平面训练法.机器学习,2009,第77期(1):27-59)中提出,该方法已经包含在matlab工具箱中。⑦按照步骤②和步骤④的过程(由于在训练过程中,在步骤③中已求得w和b各自的值,因此在计算第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的直接相似性得分时,只需以相同的操作执行步骤②即可),以相同的操作,获取第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的直接相似性得分和间接相似性得分,将第二待识别图像库中的第u'幅行人图像与第二目标图像库中的第v'幅行人图像之间的直接相似性得分和间接相似性得分对应记为和然后将第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的直接相似性得分和间接相似性得分输入g(s*,t*)=βdirect×gdirect(s*,t*)+βindirect×gindirect(s*,t*)中进行测试,得到第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的最终相似性得分,将第二待识别图像库中的第u'幅行人图像与第二目标图像库中的第v'幅行人图像之间的最终相似性得分记为再根据第二待识别图像库中的每幅行人图像与第二目标图像库中的各幅行人图像之间的最终相似性得分,识别第二待识别图像库中的每幅行人图像;对于第二待识别图像库中的第u'幅行人图像,找出该幅行人图像与第二目标图像库中的所有行人图像之间的最终相似性得分中的最高得分,将该幅行人图像中的行人识别为最高得分所对应的第二目标图像库中的行人图像中的行人;其中,u'和v'均为正整数,1≤u'≤total2,1≤v'≤total2',表示第二待识别图像库中的第u'幅行人图像的特征向量,表示第二目标图像库中的第v'幅行人图像的特征向量。为了更好地说明本发明方法的显著作用,对本发明方法进行实验。本发明利用market-1501数据库和chuk03数据库这两个数据库中的图像,对本发明方法进行测试。market-1501数据库共包含有1501个行人的行人图像,其中751个行人的行人图像用于构成训练集;剩余的750个行人的行人图像用于构成测试集中的第二目标图像库,另外在测试阶段,手动描绘3368幅行人图像用于构成测试集中的第二待识别图像库。cuhk03数据库提供了手动裁剪的图像集和使用目前效果最好的行人检测算法进行行人检测的图像集,每个图像集均包含了1467个行人的行人图像,对于每个图像集,本发明从中选取767个行人的行人图像构成训练集;选取700个行人的行人图像构成测试集。实验中使用rank排名表示前n幅行人图像中图像正确识别的比例,map表示平均精度,由l.zheng,l.shen,l.tian,etal.scalablepersonre-identification:abenchmark[c]//proceedingsoftheieeeinternationalconferenceoncomputervision.2015:1116-1124(郑亮,沈丽月,田璐,可扩展的行人再识别:一个基准[c].计算机视觉国际会议,2015,1116-1124)提出。对于market-1501数据库,表1给出了本发明方法在market-1501数据库上进行行人再识别的实验结果,并给出了单独使用直接度量和间接度量的识别效果。第二目标图像库中的所有行人图像按照相似性得分排名后,将第二待识别图像库中的行人图像识别为排名在第1的第二目标图像库中的行人图像,所有第二待识别图像库中的所有行人图像中有44.33%能被正确识别。表1不同方法在market1501数据库上进行行人再识别的识别率方法rank1map直接度量41.5118.12间接度量44.0925.35本发明方法44.3325.52对于cuhk03数据库,表2给出了本发明方法在cuhk03数据库上进行行人再识别的实验效果,并给出了单独使用直接度量和间接度量的识别效果。第二目标图像库中的所有行人图像按照相似性得分排名后,将第二待识别图像库中的行人图像识别为排名在第1的第二目标图像库中的行人图像,对于手动裁剪的行人图像集(labeled),所有第二待识别图像库中的所有行人图像中有11.93%能被正确识别;对于用行人检测算法提取的行人图像集(detected),所有第二待识别图像库中的所有行人图像中有10.57%能被正确识别。表2不同方法在cuhk03数据库上进行行人再识别的识别率图2a给出了本发明方法中的间接度量中的k相互近邻的k值对识别率rank1的影响趋势图,图2b给出了本发明方法中的间接度量中的k相互近邻的k值对平均精度map的影响趋势图。本发明针对cuhk03数据库进行实验,通过实验数据来说明k值对于两者变化的影响。从图2a中不难看出,rank1值先随着k值的增加而有幅度地增加,在k=10和k=14时,达到最优值后随着k值的增加而减少。从图2b中不难看出,map值随着k的增加先增加,在k=14左右时,达到最优值,然后随着k值的增加而有小幅地减少。为了同时使得rank1值和map值取最优值,针对cuhk03数据库选取k值为14。在market-1501数据库上使用相同的方法可以确定k的取值为20。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1