一种基于视频的安全帽佩戴情况的检测方法与流程
本发明属于检测技术领域,尤其是涉及一种基于视频的安全帽佩戴情况的检测方法。
背景技术:
在工地监控中,通过人眼长时间观看监视画面,或者安排人员定期巡检施工场地,观察施工人员安全帽佩戴状况既费时又费力,大规模集中监控中,需要足够的监控人员才能同时监控所有的监视画面或者巡视较大区域的施工场地,这样不但造成人力浪费,监控人员也会因为疲劳而发生遗留异常画面;同时,施工区域额外的人员出入,同样会增加发生意外的风险。
技术实现要素:
有鉴于此,本发明旨在提出一种基于视频的安全帽佩戴情况的检测方法,用于检测工地出入口以及施工区域的安全帽佩戴状况,通过警报或上报监控中心方式进行协助,防止未佩戴安全帽或者佩戴安全帽颜色错误的人员,进入施工区域。
为达到上述目的,本发明的技术方案是这样实现的:
一种基于视频的安全帽佩戴情况的检测方法,具体包括如下步骤:
(1)获取视频图像,利用两帧图像灰度差值获得运动区域,对于获得的运动区域内使用团块检测方法获得候选区域;
(2)对于获得的候选区域通过可变形的组件模型系统检测,得到明确的目标头肩区域;
(3)对于得到的目标头肩区域,进行级联系统检测以获得目标头部区域,然后对于目标头部区域进行hsv颜色空间转换;
(4)对于得到的hsv颜色空间下的头部区域,用神经网络对于头部区域图像进行分类判断,确定目标是否佩戴安全帽,随后通过hsv颜色空间,判断安全帽颜色;
(5)输出头部区域以及安全帽佩戴检测结果。
进一步的,所述步骤(1)具体包括利用两帧图像的每个像素的灰度值进行差值计算,差值的绝对值大于阈值标记为前景像素,否则标记为背景像素,对于前景图像进行团块检测,把相邻的前景点进行目标融合,得到候选区域。
进一步的,所述步骤(2)中,可变形的组件模型系统的检测包括训练与识别,训练时,通过输入样本训练可变形的组件模型系统,识别时,通过该系统对于运动目标的头肩位置进行识别。
进一步的,所述步骤(3)中,级联系统的检测包括训练与识别,训练时,通过输入样本训练级联系统,识别时,通过该系统对于头肩区域的头部位置进行识别。
进一步的,所述步骤(3)中,hsv颜色空间转换方法具体包括
对于原始的yuv颜色空间,首先转换为rgb颜色空间:
r(x,y)=y(x,y)+1.042*(v(x,y)-128)
g(x,y)=y(x,y)-0.3441*(u(x,y)-128)-0.7141*(v(x,y)-128)
b(x,y)=y(x,y)+1.772*(u(x,y)-128)
然后对于rgb颜空间,转换为hsv颜色空间:
v(x,y)=max(r(x,y),g(x,y),b(x,y))
h(x,y)=h(x,y)+360,ifh(x,y)<0。
进一步的,所述步骤(4)中,神经网络的过程包括训练与识别,训练时,通过输入样本训练神经网络系统,识别时,通过该系统对于头部位置佩戴安全帽的情况进行识别。
进一步的,所述步骤(4)中,根据检出头部图像的hsv三个分量的阈值,对于该区域逐个像素进行标记,根据标记的不同,对于区域进行团块检测,将面积符合阈值且靠近头部区域上边缘的团块所代表的颜色,视做安全帽颜色。
相对于现有技术,本发明所述的一种基于视频的安全帽佩戴情况的检测方法具有以下优势:本发明提供了基于监控视频的安全帽佩戴情况的检测方法,用于检测工地出入口以及施工区域的安全帽佩戴状况,通过警报或上报监控中心方式进行协助,防止未佩戴安全帽或者佩戴安全帽颜色错误的人员,进入施工区域;基于运动目标检测以及特征判断的方法,降低了误报警的发生概率;使用颜色空间转换,能够帮助更好的提取特征,降低检测难度;不需要细微的图像信息,降低了对图像清晰度的要求,扩大了使用范围。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例所述的可变形的组件模型系统训练和识别过程的流程图;
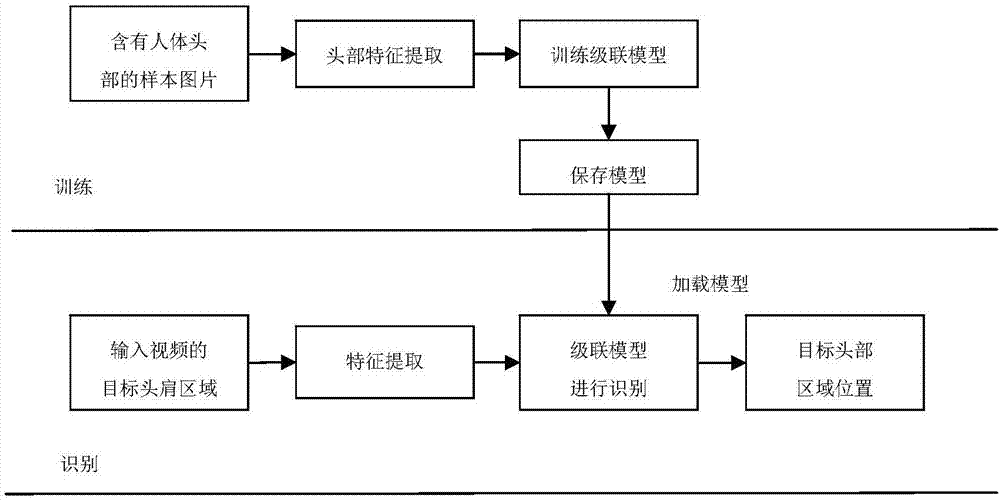
图2为本发明实施例所述的级联系统训练和识别过程的流程图;
图3为本发明实施例所的神经网络训练和识别过程的流程图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面将参考附图并结合实施例来详细说明本发明。
本发明提供一种基于视频的安全帽佩戴情况的检测方法,具体包括
(一)首先利用两帧图像的每个像素的灰度值进行差值计算,差值的绝对值大于阈值标记为前景像素;
|pt(x,y)-pt-1(x,y)|>threshold则(x,y)属于前景,否则为背景。
其中,pt(x,y)为t时间(x,y)坐标像素的值,pt-1(x,y)为t-1时间(x,y)坐标像素的值,threshold是判断阈值;
对前景图像进行团块检测,把相连的前景点进行目标融合,得到目标的候选区域。
(二)对于获得的候选区域通过可变形的组件模型系统检测,得到明确的目标头肩区域;
可变形的组件模型(dpm)系统的训练与识别如图1所示。其中,训练预测过程可以分为训练阶段和识别阶段两部分:
训练时,通过输入样本训练可变形的组件模型(dpm)系统;
识别时,通过该系统对于运动目标的头肩位置进行识别。
(三)对于得到的目标头肩区域,进行级联系统检测以获得目标头部区域,然后对于目标头部区域进行hsv颜色空间转换;
级联系统的训练与识别如图2所示。其中,训练预测过程可以分为训练阶段和识别阶段两部分:
训练时,通过输入样本训练级联系统
识别时,通过该系统对于头肩区域的头部位置进行识别。
对于确定的头部位置图像进行hsv颜色空间转换,转换方法如下
对于原始的yuv颜色空间,首先转换为rgb颜色空间:
r(x,y)=y(x,y)+1.402*(v(x,y)-128)
g(x,y)=y(x,y)-0.3441*(u(x,y)-128)-0.7141
*(v(x,y)-128)
b(x,y)=y(x,y)+1.772*(u(x,y)-128)
然后对于rgb颜空间,转换为hsv颜色空间:
v(x,y)=max(r(x,y),g(x,y),b(x,y))
h(x,y)=h(x,y)+360,ifh(x,y)<0。
(四)对于得到的hsv颜色空间下的头部区域,用神经网络对于头部区域图像进行分类判断,确定目标是否佩戴安全帽,随后通过hsv颜色空间,判断安全帽颜色;
神经网络的训练与识别如图3所示。其中,训练预测过程可以分为训练阶段和识别阶段两部分:
训练时,通过输入样本训练神经网络系统。
识别时,通过该系统对于头部位置佩戴安全帽的情况进行识别。
根据检出头部图像的hsv三个分量的阈值,对于该区域逐个像素进行标记,0表示黑色,1表示红色,2表示蓝色,3表示白色,4表示黄色,255表示其他颜色。根据标记的不同,对于区域进行团块检测,将面积符合阈值且靠近头部区域上边缘的团块所代表的颜色,视做安全帽颜色。
(五)输出头部区域以及安全帽佩戴检测结果。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!