基于多流LSTM的动作识别方法与流程
本发明涉及视频图像处理领域,具体涉及基于多流lstm的动作识别方法,用于对动作进行识别。
背景技术:
目前,动作识别方法可分为两类:一类是以传统机器学习为基础的方法,该类方法的核心是人工构建出描述动作属性的特征,然后训练分类器,最后进行动作分类;另一类是基于深度学习的方法,该类方法以目标为导向,通过数据训练,自动学习特征,往往具有更好的区分性。
传统动作识别方法的主要缺点是必须人工构建动作特征,且无法保证特征的区分效果。
目前,动作识别基于深度学习的方法主要有两类:一类是以rgb信息为输入,采用cnn(卷积神经网络)构架的方法;另一类主要以深度相机获取的人体骨架关节点数据为输入,采用基于lstm(长短期记忆)的rnn(循环神经网络)架构的方法。
基于深度学习的方法,训练模型所需的数据量较大,而实际可用的数据往往较少;基于cnn的方法主要获取动作的静态特性,无法获取动作的时序特性;基于lstm的方法虽获取了动作的时序特性,但无法萃取肢体变化所带来的动态特性,而动态特性在动作识别中具有重要的作用;动作的静态特性和动态特性在动作识别上各自具有优势和局限,目前采用的方法无法有效整合这两类特性,导致动作识别效率低、识别效果差。
技术实现要素:
本发明的目的在于:提供一种基于多流lstm的动作识别方法,解决了无法有效整合动作的静态特性和动态特性导致动作识别效率低、识别效果差的技术问题。
本发明采用的技术方案如下:
基于多流lstm的动作识别方法,包括以下步骤:
步骤1:利用深度相机对人体骨架关节点的坐标数据进行采集,得到由所述关节点表示的动作序列;
步骤2:对所述动作序列进行视角预处理,并利用特征提取模型a对视角预处理结果进行特征提取;
步骤3:对所述动作序列进行动态属性萃取,并利用特征提取模型b对动态属性萃取结果进行特征提取;
步骤4:利用特征提取模型c分别对所述视角预处理结果和动态属性萃取结果进行特征提取,并对提取的特征进行特征融合;
步骤5:分别利用所述步骤2和步骤3提取的特征以及步骤4中融合的特征进行动作识别;
步骤6:对所述步骤5得到的识别结果进行决策融合,最终得到动作的识别结果。
进一步的,所述特征提取模型a、特征提取模型b、特征提取模型c的获取方法如下:
s001:利用深度相机采集人体骨架关节点的坐标数据,得到训练样本;
s002:对所述训练样本进行视角预处理,以视角预处理结果为输入,构建三层lstm网络,并对所述三层lstm网络进行训练,得到特征提取模型a;
s003:对所述训练样本进行动态属性萃取,以动态属性萃取结果为输入,构建三层lstm网络,并对所述三层lstm网络进行训练,得到特征提取模型b;
s004:以视角预处理结果为输入,构建三层lstm网络;以动态属性萃取结果为输入,构建三层lstm网络;构建融合该步骤中两个三层lstm网络输出特征的特征融合框架;对该步骤中的两个三层lstm网络和特征融合框架进行联合训练,得到特征提取模型c。
进一步的,所述步骤2具体为:
s201:利用人体骨架关节点的坐标数据得到旋转矩阵,所述旋转矩阵公式如下:
rc'→h(t)=[s1s2s3]t(1),
其中,
s3=s1×s2(4);
t表示时间变量,h表示人体骨架坐标系,c表示相机坐标系,c'表示中间坐标系,
s202:计算每个关节点的3d坐标
其中,k表示人体关节点的序号,
s203:利用特征提取模型a提取步骤s202中视角预处理结果的特征。
进一步的,所述步骤3具体为:
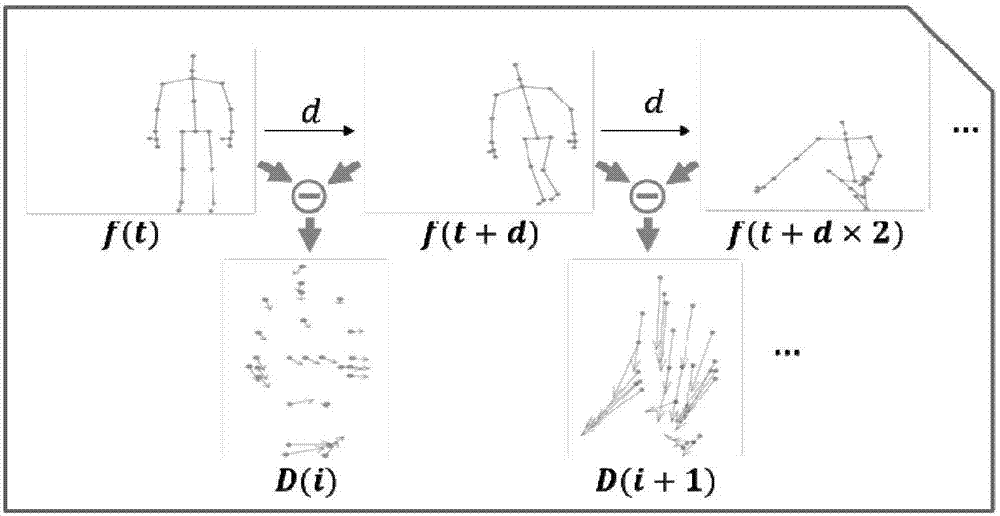
s301:对所述动作序列进行动态属性萃取,动态属性萃取为追踪每个关节点在两个固定时间间隔d间的位置变化信息,获得萃取结果f(t+d)-f(t)(6),其中,d表示固定时间间隔,f(t)表示在t时刻人体关节点的3d坐标;
s302:利用特征提取模型b提取步骤s301中动态属性萃取结果的特征。
进一步的,所述步骤4的具体内容如下:
s401:利用特征模型c分别对步骤2的视角预处理结果和步骤3的动态属性萃取结果进行特征提取;
s402:对步骤s401提取的特征进行特征融合,特征融合采用的公式如下:
其中,l代表融合输出的特征数量,
进一步的,所述步骤5中动作识别具体为:将步骤2提取的特征、步骤3提取的特征和步骤4融合的特征分别依次输入各自的全连接层和softmax进行动作识别。
进一步的,所述步骤6中决策融合具体为:将所述步骤5得到的3个识别结果进行连乘,连乘结果所代表的类型就是最终动作识别的结果。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1.本发明整合了动作序列的静态特性和动态特性,动作识别的精度高,稳定性好;利用nturgb+d数据库的测试结果如下:采用传统的动作识别方法,精度在30%-80%之间,其中最优的方法是sta-lstm,精度约为80%;而采用本方案,动作识别的精度提高至86.6%。
2.采用视角预处理和构建人体动作动态属性萃取为基础的诱导方法,降低了深度学习框架的训练难度,使得训练所需的数据量较小,收敛速度快。
3.本发明能够识别更加复杂的动作类型,可以适应更复杂的应用场景。
附图说明
本发明将通过例子并参照附图的方式说明,其中:
图1是本发明的整体结构图;
图2是本发明构建的萃取动作序列动态属性的原理图;
图3是本发明中以多层权重为基础的特征融合结构图;
图4是本发明中特征融合的结构图。
具体实施方式
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
下面结合图1-4对本发明作详细说明。
基于多流lstm的动作识别方法,包括以下步骤:
步骤0:获取特征提取模型a、特征提取模型b、特征提取模型c;
具体如下:
s001:利用深度相机采集人体骨架关节点的3d坐标数据,得到训练样本;
s002:对所述训练样本进行视角预处理,以视角预处理结果为输入,构建三层lstm网络,并对所述三层lstm网络进行训练,得到特征提取模型a;
s003:对所述训练样本进行动态属性萃取,以动态属性萃取结果为输入,构建三层lstm网络,并对所述三层lstm网络进行训练,得到特征提取模型b;
s004:以视角预处理结果为输入,构建三层lstm网络;以动态属性萃取结果为输入,构建三层lstm网络;构建融合该步骤中两个三层lstm网络输出特征的特征融合框架;对该步骤中的两个三层lstm网络和特征融合框架进行联合训练,得到特征提取模型c。
步骤1:利用深度相机采集待识别目标的人体骨架关节点的3d坐标数据,得到由所述关节点表示的动作序列。
步骤2:对所述动作序列进行视角预处理,并对视角预处理结果进行特征提取;
具体为:
s201:利用人体骨架关节点的坐标数据得到旋转矩阵,所述旋转矩阵公式如下:
rc'→h(t)=[s1s2s3]t(8),
其中,
s3=s1×s2(11);
t表示时间变量,h表示人体骨架坐标系,c表示相机坐标系,c'表示中间坐标系,
s202:计算每个关节点的3d坐标
其中,k表示人体关节点的序号,
s203:利用特征提取模型a提取步骤s202中视角预处理结果的特征。
步骤3:对所述动作序列进行动态属性萃取,并对动态属性萃取结果进行特征提取;
具体为:
s301:对所述动作序列进行动态属性萃取,动态属性萃取为追踪每个关节点在两个固定时间间隔d间的位置变化信息,获得萃取结果f(t+d)-f(t)(13),其中,d表示固定时间间隔,f(t)表示在t时刻人体关节点的3d坐标;
s302:利用特征提取模型b提取步骤s301中动态属性萃取结果的特征。
步骤4:分别对所述视角预处理结果和动态属性萃取结果进行特征提取,并对提取的特征进行特征融合;
具体为:
s401:利用特征模型c分别对步骤2的视角预处理结果和步骤3的动态属性萃取结果进行特征提取;
s402:对步骤s401提取的特征进行特征融合,特征融合采用的公式如下:
其中,l代表融合输出的特征数量,
该公式的具体解释如下:(1)权重加成:对每一个特征里面的每一个元素,额外赋予一个可训练的加成权重
步骤5:分别利用所述步骤2和步骤3提取的特征以及步骤4中融合的特征进行动作识别;
具体为:将步骤2提取的特征、步骤3提取的特征和步骤4融合的特征分别依次输入各自的全连接层和softmax进行动作识别。
步骤6:对所述步骤5得到的识别结果进行决策融合,最终得到动作的识别结果;
具体为:将所述步骤5得到的3个识别结果进行连乘,连乘结果所代表的类型就是最终动作识别的结果。
- 还没有人留言评论。精彩留言会获得点赞!