一种针对Gzip压缩数据的过滤方法及系统与流程
本发明属于计算机
技术领域:
,具体涉及一种针对gzip压缩数据的过滤方法及系统。
背景技术:
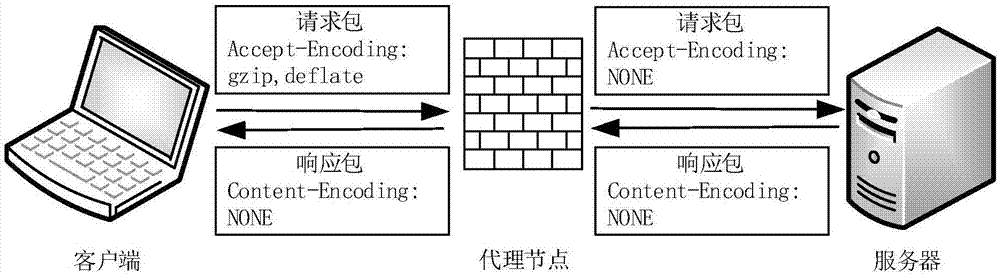
:模式匹配技术是入侵检测系统和网络应用防火墙的关键技术之一,但是随着信息时代的发展,模式匹配技术面临新的问题:数据量急剧增加,网络流复杂多变,匹配的实时性不能满足等。所以面对复杂多变的网络数据,模式匹配技术的性能需要进一步提升。为了不断提升网络带宽,除了提高硬件传输能力以外,压缩数据传输逐渐被重视起来。http压缩是指将web文本数据在服务器压缩后发送给浏览器的传输方式。目前,yahoo!、google、youtube、baidu、腾讯等知名网站都使用http压缩传输的传输方式。在2017年,根据alexa网站的前1000万网址的流量统计,有71.4%的网站使用了http压缩传输,目前仍然呈现上升趋势。http压缩传输过程如图1所示,首先,客户端发送http请求给服务器,其中注明accept-encoding字段,表示可以接受的压缩方式;其次,客户端接受请求,将请求的文本文件压缩;再次,返回http报文,添加压缩数据,附带content-encoding字段,表示压缩方式;最后,客户端接受数据,解压并渲染给用户。在常见的web文本(html,css,javascript)中存在大量的相同标签和语句,所以http报文压缩后可以达到非常好的效果;根据实验测试,web文本压缩后可以减少70%以上的空间大小。在http1.1协议中,可以使用gzip、deflate等压缩算法。其中gzip压缩算法是http压缩的常用算法,占到了98.9%左右。gzip,全称是gnuzip,是一种文件压缩程序,作者是jean-loupgailly和markadler,于1992年公开发表。gzip是对delate的封装,包括两个部分:lz77压缩和哈夫曼编码压缩,其中lz77是主要部分。现有的多模式匹配算法过滤压缩数据是比较困难的。如图2a、图2b所示,面对http压缩数据,图2a的不做处理和图2b的拒绝接受都会带来安全隐患或者性能损耗。目前防火墙采用“解压+扫描”的方式对压缩数据进行过滤,如图2c所示。“解压+扫描”的方式处理http压缩流量的流程如下:当获取一个http数据包时,通过gzip解压,随后在解压后的数据上进行扫描。这种方式存在很多问题:首先,“解压+扫描”将检测过程分为两个阶段,大大降低了检测的实时性;其次,如果可以将压缩文件全部解压,有“解压炸弹”的风险,即解压率过大,导致解压过程大量占用内存和cpu使用率。例如,如果文本是1gb的比特位都是1,压缩后仅为1mb左右,那么在解压过程中必然占用大量的内存空间和cpu运算,发生“解压炸弹”。更重要的是,lz77算法通过减少重复数据的方式压缩文本数据,结合压缩数据的性质和模式串匹配算法的特点,可以跳跃一些数据,提高匹配速度;而“解压+扫描”的方式完全忽略了压缩数据的特性。压缩匹配是解决这一问题的有效途径,压缩匹配是指针对压缩数据进行模式匹配时,通过不解压或者局部解压的方式,对压缩数据进行模式匹配。压缩匹配算法通过利用压缩匹配的特点提高对压缩数据的匹配效率。综上所述,目前防火墙通过“解压+扫描”的方式处理http压缩流量,即当获取一个http数据包时,通过gzip解压,随后在解压后的数据上进行扫描。这种方式存在很多问题:1.“解压+扫描”将检测过程分为两个阶段,大大降低了检测的实时性;2.如果将压缩文件全部解压,有“解压炸弹”的风险,即解压率过大,导致解压过程大量占用内存和cpu使用率;3.增加了解压部分,导致整体时间过高,过滤性能下降。技术实现要素:本发明的目的在于提出一种针对gzip压缩数据的过滤方法,根据gzip压缩数据的特点,并结合kr(karp-rabin)多模式匹配算法,提升gzip压缩数据的过滤速度,同时提高处理的实时性和安全性。本发明的目的还在于提出一种针对gzip压缩数据的过滤系统,用于执行该方法,为达到上述目的,本发明采用如下技术方案:一种针对gzip压缩数据的过滤方法,其步骤包括:将gzip压缩数据进行哈夫曼解码,得到lz77压缩数据;初始化缓存窗口、状态窗口以及kr多模式匹配算法的哈希表结构,对所述lz77压缩数据进行kr搜索,获取flag信息;如果所述lz77压缩数据是ascii码,则将正常字符加入到所述缓存窗口的一位置上,设置记录匹配状态在该缓存窗口位置的值为0,对该记录匹配状态的搜索位置的flag进行判断;如果所述lz77压缩数据是指针类型,找到起始位置并将该起始位置的某一长度的子串复制到所述缓存窗口的一位置上,同时将对应的flag状态也复制到记录匹配状态中,再从该缓存窗口的位置开始扫描所述长度;如果未扫描的剩余子串长度大于该记录匹配状态在该缓存窗口位置的绝对值,则保留该缓存窗口位置的值,否则将该值设为0,对该记录匹配状态的搜索位置的flag进行判断;对所述flag进行判断包括:如果flag大于0,则直接获取成功匹配的信息;如果flag等于0,则进行kr多模式匹配算法匹配;如果flag小于0,则直接获取未成功匹配的信息;根据对所述flag判断的结果更新所述搜索位置和所述缓存窗口的位置的值。进一步地,所述初始化缓存窗口是将所述缓存窗口位置的值设为模式串最大长度值,将搜索位置置0。进一步地,所述初始化状态窗口是将记录匹配长度置0。进一步地,所述初始化kr多模式匹配算法是指根据模式串哈希值将其放入哈希表中。进一步地,所述kr搜索的步骤包括:根据目标字符串前一最小长度的子串的哈希值定位到哈希表中的位置;如果该位置为空,则搜索结束,返回0;如果该位置存在模式串,则将模式串逐一与目标字符串进行比较,如果命中,则记录命中信息并返回匹配成功的字符串最小长度;如果未命中,则将最大匹配长度与所述最小长度进行比较,如果前者大于或等于后者,则返回最长匹配长度的相反数,否则返回0。进一步地,所述指针用(length,distance)表示,其中distance表示重复字符串位置,长度在1~215之间,length表示字符串长度,长度在3~258之间。进一步地,所述kr多模式匹配算法为:对哈希表中每个模式串截取相同长度m作为关键子串;通过计算关键子串的哈希值,插入到哈希表中相应位置;在匹配时,截取目标文本长度为m的子串,计算其哈希值;如果根据该计算的哈希值在哈希表中命中,则逐一检查各子串是否匹配成功。进一步地,所述缓存窗口、记录匹配状态长度均为215。进一步地,对所述缓存窗口的剩余字符进行kr搜索。进一步地,重复对所述lz77压缩数据进行kr搜索,并根据所述lz77压缩数据是ascii码或指针类型进行flag判断,以重复更新所述搜索位置和所述缓存窗口的位置的值。一种针对gzip压缩数据的过滤系统,包括存储器和处理器,该存储器存储计算机程序,该程序被配置为由该处理器执行,该程序包括用于执行上述方法的各步骤指令。本发明取得的技术效果为:1.定义匹配状态flag,利用flag的数值和正负表示匹配过程的匹配信息;2.改进kr搜索方式,使其在搜索过程中返回有效的flag信息;3.通过利用gzip压缩数据存在大量重复子串的特点,将重复子串的flag匹配信息记录下来提供给后面的使用,从而减少匹配次数,实现跳跃匹配,提高匹配速度。在算法性能测试中,本发明可以跳跃约41.5%的目标数据,匹配速度较原始kr算法提升了77%,有效解决了gzip压缩数据的匹配难题附图说明图1是http压缩传输过程示意图。图2a至图2c是防火墙处理http压缩流量的三种方式示意图。图3是kr多模式匹配算法哈希表结构图。图4是本发明的一种针对gzip压缩数据的过滤方法流程图。图5是lz77压缩数据关系图。图6是构造的kr搜索数据结构图。具体实施方式为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。gzip压缩数据由原始数据经lz77编码和哈夫曼编码组成,本发明主要针对gzip压缩数据中的lz77编码部分。lz77压缩算法主要针对字符数据,通过固定一个窗口大小,如果新的字符串已经存在窗口中,则将窗口中对应的字符串的位置和长度记录下来,使用指针(length,distance)表示,其中distance表示重复字符串位置,length表示字符串长度,从而达到压缩文本的目的。在gzip中,窗口大小固定为32kb,所以distance长度在1~32768(215)之间,而length的取值在3~258之间。例如以下方框所示的lz77压缩数据实例,给定字符串“<!doctypehtml>\n<htmlid”,其中“\n”表示换行,则压缩后表示为“<!doctypehtml>\n<(4,7)id”,其中(4,7)表示从前面距离为7的位置开始长度为4的字符串。对kr多模式匹配算法的简要介绍如下:kr多模式匹配算法需要维持一个哈希表,由于各个模式串长度不同,所以需要对每个模式串截取相同的部分作为关键子串。如图3所示,模式串为“13567”“914817”“4576385”和“2754”,关键子串长度m为4,关键子串取“1356”“4817”“5763”和“2754”;对通过计算关键子串的哈希值,插入到哈希表中相应位置。在匹配过程中,首先截取目标文本长度为m的子串,随后计算其哈希值,如果在哈希表中命中,再逐一检查是否匹配成功。本发明主要针对lz77的数据特性,结合kr多模式匹配算法,提出了一个针对gzip压缩数据的过滤方法,如图4所示。lz77压缩数据有两种数据形式,一种是ascii码,另一种是指针(length,distance),后者表示该位置有一个重复的子串,从而达到压缩数据的目的。所以本发明主要思想是将重复子串的匹配信息记录下来提供给后面的使用,从而减少匹配次数,提高匹配速度。在lz77算法需要维持一个固定长度的窗口作为缓存,帮助寻找最长的重复子串。在gzip压缩数据中,将窗口固定长度为215,如图5所示,在窗口内可以通过指针(length,distance)找到到重复子串。在本算法中,增加一个相同长度的flag_windows,其中flag表示该位置的匹配状态,flag的绝对值表示“安全长度”,若flag为正,表示该位置有一个长度为flag绝对值的模式串匹配成功;若flag为负,则表示该位置在flag绝对值的长度内与模式串不可能匹配成功。若flag为0,表示此处未记录下任何状态。算法变量说明:windows:缓存窗口,长度为215;flag_windows:记录匹配状态,长度为215;w:缓存窗口的一位置;search:搜索位置;m_max_len:模式串最大长度;m_min_len:模式串最小长度;kr搜索算法:输入:长度为m_max_len的目标字符串输出:匹配状态1.根据目标字符串前m_min_len长度的子串的哈希值定位到哈希表中的位置;2.若该位置为空,则返回0,算法结束;否则,转第3步;3.若该位置存在模式串,则逐一与字符串进行比较,若命中,记录命中信息,返回匹配成功的字符串最小长度;若未命中,则将最大匹配长度与m_min_len比较,若其大于或等于m_min_len,则返回最长匹配长度的相反数,否则返回0。本实施例的一个针对gzip压缩数据的过滤方法的具体流程为:1.对gzip压缩数据进行预处理:将gzip压缩数据进行哈夫曼解码,得到lz77压缩数据;2.初始化缓存窗口和状态窗口,包括将flag_windows置0,获取lz77数据,初始化长度为m_max_len的缓存窗口,令w为m_max_len,search为0。3.初始化kr多模式匹配算法的哈希表结构;4.获取lz77数据,若是ascii码,则转第5步;若是指针类型,则转第6步;否则,转第7步;5.如果遇到正常的字符,将其加入windows的位置w处,flag_windows的w处置0;同时对flag_windows的search位置的值flag进行判断:如果flag大于0,则此处有成功匹配,直接获取匹配信息;如果flag等于0,则此处没有可用信息,进行kr算法匹配;如果flag小于0,则表示此处没有匹配成功,不进行kr搜索;对search和w进行更新(加1操作),跳转第4步;6.如果是指针(length,distance)类型,通过distance找到起始位置,并将该位置长度为length的子串复制到windows的w位置上,同时将对应的flag状态也复制到flag_windows中;然后从w位置开始,到w+length的位置止进行扫描:a)若剩余子串长度大于flag_windows在w位置的绝对值,那么此位置的状态有效;保留flag_windows在w位置的值,转第c步;b)否则此位置状态无效,将flag_windows在w的位置的值置为0;转第c步;c)对flag_windows的search位置的值flag进行判断:如果flag大于0,则此处有成功匹配,直接获取匹配信息;如果flag等于0,则此处没有任何可用信息,进行kr算法匹配;如果flag小于0,则表示此处没有匹配成功,不进行kr搜索;对search和w进行更新(加1操作);扫描完成后跳转到第4步;7.使用kr搜索windows缓存剩余字符,算法结束。算法流程举例模式串:使用{“tom”,“http”,“html”,“fp”},基数使用256,根据模式串的ascii码构造如图5所示kr搜索结构。变量记录如下:windows:缓存窗口;flag_windows:记录匹配状态;w:缓存窗口的一位置;search:搜索位置;m_max_len:模式串最大长度,本例中为4;m_min_len:模式串最小长度,本例中为2;情景一:通过记录匹配成功信息跳跃字符目标数据:{“<!doctypehtml>\n<(4,7)id=”},其中\n表示换行字符流程如下:第一步:首先将窗口填满m_max_len长度的数据,search为0,w为4;在0位置进行一次kr搜索,将字符串“<doc”输入到kr搜索算法中,“<d”计算得到哈希值为60*256+67=15428,其中60和67分别为“<”和“d”的ascii码值,在哈希表中位置为15428mod5=3,未命中,所以0位置的flag记为0,标示此位置未有有效信息;继续更新w和search,当w到达位置13;此时search为9,搜索字符串为“html”通过搜索,可以找到与模式串“html”匹配,此时位置9的flag为4,标示此位置有一个长度为4的字符串成功匹配,当扫描到结尾时如下表所示:位置0123456789101112131415flag_windows0000000000400000windows<!doctypesphtml>\n注:sp表示空格,\n表示换行,下同。第二步:当w在位置17时,search为13,遇到指针(4,7),标示此位置有一个长度从此位置前方距离为7(即位置10)开始长度为4的字符串,即“html”;通过位置10的flag记录可以知道有一个长度为4的字符串匹配成功,而此时重复子串恰好是4,于是将w位置的flag位置为4,继续更新search位置的搜索状态。之后并无可以信息,正常更新与扫描即可。当search为17时,此时w为21,此时search发现flag位是4,说明此位置可以直接获取匹配状态(w在17时已经确认过了),继续更新位置和匹配信息,如下表所示:位置10111213141516171819202122232425flag_windows4000000400000000windowshtml>\n<htmlsp<id=情景二:通过记录匹配失败信息跳跃字符目标数据为:{“<!doctypehtm>\n<(4,6)<id=c”}第一步:search位置在10之前的状态与情景一相同,当search为10,此时w为14;当search进行kr搜索时,发现并未命中,但是可以得到字符串“htm>”在匹配过程中可以匹配的最大长度为3,则将flag_windows位置10记为-3,表示此位置可以匹配的最大长度为3。剩余记录结果如下表所示:位置0123456789101112131415flag_windows0000000000-300000windows<!doctypesphtm>\n<第二步:当w位置为16时,此时遇到指针(4,6),标示此位置有一个长度从此位置前方距离为6(即位置10)长度为4的字符串,即“htm>”,而位置10的标记为-3,表示此位置所能匹配的最长字符串长度为3,而重复长度为4,那么可以确定16位置没有命中,那么将16位置的状态记录为-3,等到search扫描;当search扫描到16位置时,可以看到标志位为-3,表示此位置可以确定没有匹配信息,那么可以直接跳过,不进行kr搜索。完整的状态记录如下表所示:位置10111213141516171819202122232425flag_windows-300000-3000000000windowshtm>\n<htm>sp<id=c方法性能比较实验环境:系统:ubuntu14.04cpu:1核intel(r)xeon(r)e5-2620v3内存:1gb实验数据:目标文本使用yahoo!网页50mb,压缩后数据大小为8.8mb,获取到的lz77数据为23.3mb;模式串使用snort集合中抽取的字符串。本发明方法与现有方法的比较如下表所示,其中跳跃率为跳跃字符数与总字符数的比值。由上表可知,本发明采用的方法所需解压、匹配时间少于现有方法的解压+kr算法,处理速度提升了(2.46-1.39)/1.39×100%=77%,跳跃率约为41.5%。以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1