一种考虑交叉的仓库网络中在线零售商的仓库选址方法与流程
本发明属于供应链领域,具体涉及一种考虑交叉的仓库网络中在线零售商的仓库选址方法。
背景技术
近年来,全球范围内在线市场的兴起,为在线购买产品和服务的顾客提供了整个在线形式的开发、营销、售卖、传送、服务等过程。确实,在线交易为顾客和零售商提供了方便和有效的方式。然而,在线零售商必须提高他们的供应链网络以提供更好的服务。供应链管理的目标是在保证最好的服务质量前提下,以最低的花费最短的时间传送货物,这是在线零售业务成功之本。在一个成功的供应链系统的开发中,设计有效的仓库选址策略。
目前的选址策略都是依据该领域专家的经验,及考虑了不同优化目标的混合整数优化模型来解决选址问题,然而在大型供应链网络中,混合整数优化模型无法较好的被扩展,因此需要启发式的近似的解决方案。
大数据、数据挖掘技术的出现,以及被收集的细粒度的供应链数据提供了一种仓库选址新颖的方式。
因此,设计良好有效的可扩展的适应于大的供应链在线零售网络仓库选址策略本申请人致力于解决的问题。
技术实现要素:
本发明的目的是考虑使用大数据、数据挖掘,提供了一种设计良好有效的可扩展的适应广泛的供应链在线零售网络仓库选址策略,尤其是一种考虑交叉的仓库网络中在线零售商的仓库选址方法。
在本发明中以最小化总成本为目标,成本包括供应商与仓库之间的运输成本、仓库与顾客之间的快递运输成本以及仓库与仓库之间的运输成本。本发明通过销量预测模型和在线市场销售需求的客户物流服务估算法来完成仓库选址;即提出了一个e&m聚类算法以最少的计算成本动态地优化仓库位置;另外,通过层次聚类的方法进一步减少了计算成本。
本发明解决其技术问题所采用的技术方案具体如下:
本发明所采用的技术方案包括如下步骤:
步骤1、给定顾客位置的集合、客户物流满意度的相关特征、顾客购置能力的相关特征。基于给定的特征和集合,利用人工神经网络(ann)方法预测一年内的产品销量需求。
其中,客户物流满意度的相关特征包括运输时间、交付时间、损坏率;顾客购置能力的相关特征包括人口密度、平均收入、就业率。
步骤1-1、销量预测模型的层输入:
第k+1层的单元i由第k层的输出αk得到的,α0是特征向量
α0(i)=fi(公式2)
其中,α0是网络输入,
第k+1层的单元i是通过一个sigmoid激活函数映射得到的。
步骤1-2、销量预测模型的训练:
为了降低销量预测模型的预测误差,该销量预测模型需要通过训练得到训练集中输入输出对
步骤2、通过minlp模型来构建仓库选址中的总成本(参见公式5),同时通过带有距离权重的e&m算法来解决优化仓库选址问题,接着通过层次聚类方式对问题大小进行归约,具体如下:
步骤2-1、通过带有距离权重的e&m算法,快速地对最小化总成本问题(即公式5)获得一个全局最优的结果。
最小化总成本问题定义:
给定一个供应商协调器、顾客协调器和顾客需求集合,选择一组仓库的集合和顾客分配到各个仓库的策略,以最小化总成本,参看公式(1):
式中:swj是供应商与仓库j之间的运输成本,wci,j是仓库j与顾客i之间的快递传输成本,
wcandi代表候选的仓库,pi代表第i个顾客的包裹需求,ij代表需要发往仓库j的总的包裹需求,c代表客户总需求的集合,k代表固定的仓库的个数,yjm代表仓库m的二进制决策变量,yjn代表仓库n的二进制决策变量。
minlp模型的劣势在于需要提前设置候选的仓库,需要在满足公式5的条件下,获得全局最优,此寻优过程非常慢,很难应用于大型的交叉网络中。
本发明利用e&m聚类算法来求得各个成本的权重。
①e(estimation)假设仓库位置已经确定,估计每一个顾客被分配到的指定仓库,使得物流成本最低,来求得快递运输成本的参数,即zij,具体计算如下:
其中,li代表客户,dc代表仓库到顾客的单元成本,ds代表仓库与仓库之间的单元成本,d代表距离,s0代表供应商,wj代表仓库,xi表示通过公式1标准话后的顾客i的变量;
②m(maximization)。①步骤结束后,根据固定的顾客分配,重新计算仓库的位置以让物流成本最低,来求得仓库运输成本的参数,即yj。最优的仓库位置需满足
其中,li代表客户,dc代表仓库到顾客的单元成本,ds代表仓库与仓库之间的单元成本,c代表客户的集合,w代表仓库的集合。
步骤2-2、通过一个自底向上的基于层次聚类的顾客需求对问题大小进行归约,从而减少仓库选址问题的复杂度。具体的:
2-2-1.计算两个顾客的相似距离sd(i1,i2):
式中:
2-2-2.更新邻居矩阵sd:
邻居矩阵sd存储了任意两个顾客之间的相似距离sd(i1,i2),选择相似距离最短的两个顾客之后,用一个新顾客替换选中的这两个顾客,具体的:
①计算新顾客的带有权重的需求中心点cnew:
②将新顾客需求中心点cnew带入邻居矩阵sd,替换选中的这两个顾客;
③重新计算新顾客与被替换的两个顾客相关的顾客之间的相似距离,并将计算后的相似距离带入邻居矩阵sd,从而完成此次邻居矩阵sd的更新,同时为下一次融合更新做准备。
本发明的有益效果是:
本发明利用大数据及数据挖掘技术,以及被收集的细粒度的供应链数据提供了一种仓库选址新颖的方式。供应链智能选址算法能够为客户选择最佳的仓库物流解决方案,其带来的成本控制可以使供应链中的任何企业受益。它能快速、准确、有效的降低仓储运输成本,增强企业领导者的决策能力,优化企业供应链管理,降低管理成本,提升企业在行业竞争力。
附图说明
图1为本发明示意图。
图2为本发明实施例效果图。
图3为本发明实施例最优的仓库选址和客户分配示意图。
图4为本发明实施例聚类后的被融合在一起的顾客的平均需求分布图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图1所示,
步骤1、给定顾客位置的集合、客户物流满意度的相关特征、顾客购置能力的相关特征。基于给定的的特征和集合,利用人工神经网络(ann)方法预测一年内的产品销量需求。
其中,客户物流满意度的相关特征包括运输时间、交付时间、损坏率;顾客购置能力的相关特征包括人口密度、平均收入、就业率。
步骤1-1、销量预测模型的层输入:
第k+1层的单元i由第k层的输出αk得到的,α0是特征向量
α0(i)=fi(公式2)
其中,α0是网络输入,
第k+1层的单元i是通过一个sigmoid激活函数映射得到的。
步骤1-2、销量预测模型的训练:
为了降低销量预测模型的预测误差,该销量预测模型需要通过训练得到训练集中输入输出对
步骤2、通过minlp模型来构建仓库选址中的总成本(参见公式5),同时通过带有距离权重的e&m算法来解决优化仓库选址问题,接着通过层次聚类方式对问题大小进行归约,具体如下:
步骤2-1、通过带有距离权重的e&m算法,快速地对最小化总成本问题(即公式5)获得一个全局最优的结果。
最小化总成本问题定义:
给定一个供应商协调器、顾客协调器和顾客需求集合,选择一组仓库的集合和顾客分配到各个仓库的策略,以最小化总成本,参看公式(1):
式中:swj是供应商与仓库j之间的传输成本,wci,j是仓库j与顾客i之间的交付成本,
wcandi代表候选的仓库,pi代表第i个顾客的包裹需求,ij代表需要发往仓库j的总的包裹需求,c代表客户总需求的集合,k代表固定的仓库的个数,yjm代表仓库m的二进制决策变量,yjn代表仓库n的二进制决策变量。
如果仓库位置都固定,则计算每一个顾客被分配到的指定仓库,使得物流成本最低,具体计算如下:
其中,li代表客户,dc代表仓库到顾客的单元成本,ds代表仓库与仓库之间的单元成本,d代表距离,s0代表供应商,wj代表仓库,xi表示通过公式1标准话后的顾客i的变量。
如果顾客分配都固定,则被重新计算仓库的位置以让物流成本最低,计算参看公式(5)。
步骤2-2、通过一个自底向上的基于层次聚类的顾客需求对问题大小进行归约,从而减少仓库选址问题的复杂度。具体的:
2-2-1.计算两个顾客的相似距离sd(i1,i2):
式中:
2-2-3.更新邻居矩阵sd:
邻居矩阵sd存储了任意两个顾客之间的相似距离sd(i1,i2),选择相似距离最短的两个顾客之后,用一个新顾客替换选中的这两个顾客,具体的:
①计算新顾客的带有权重的需求中心点cnew:
②将新顾客需求中心点cnew带入邻居矩阵sd,替换选中的这两个顾客;
③重新计算新顾客与被替换的两个顾客相关的顾客之间的相似距离,并将计算后的相似距离带入邻居矩阵sd,从而完成此次邻居矩阵sd的更新,同时为下一次融合更新做准备。
实施例:
参看图2-图4,本发明实施例
数据集:2012年中国电子商务公司小也的3488727条事物记录。来自于371个大城市的一百多万个客户。
问题:如何将这些客户分配到仓库及仓库如何选址。
步骤1:顾客需求的分布预测
为了优化ann的参数并防止过拟合,原始的371个城市被随机分成三部分。第一部分是全集的60%用来训练,第二部分是全集的15%用来进行交叉验证,第三部分是全集的15%用来测试。如图2所示,代表的是各个部分和整体的预测的性能。从图中可以看出ann网络的有效性。
步骤2.仓库选址
对于每一个指定的k,首先运行本发明提出的e&m算法找到一个最优的仓库位置,然后在最优的解决方案周围建立80个候选的仓库。在每两个候选的仓库之间的最小距离设置为50英里。最好的解决方案是找到仓库的候选使得minlp模型建立的公式中(公式5)的总成本最低。然而,随着候选仓库数目的增加,问题的复杂度逐渐加深,因此不可能一一尝试每一个候选以使得总成本最小。图3所示表明了最优的仓库选址(图中的星星表示)和客户分配(不同的点的颜色代表被分配到的仓库),图3中a部分表示的是两个仓库,图b部分表示的是三个仓库,图c部分表示的是四个仓库。
步骤3.计算优化
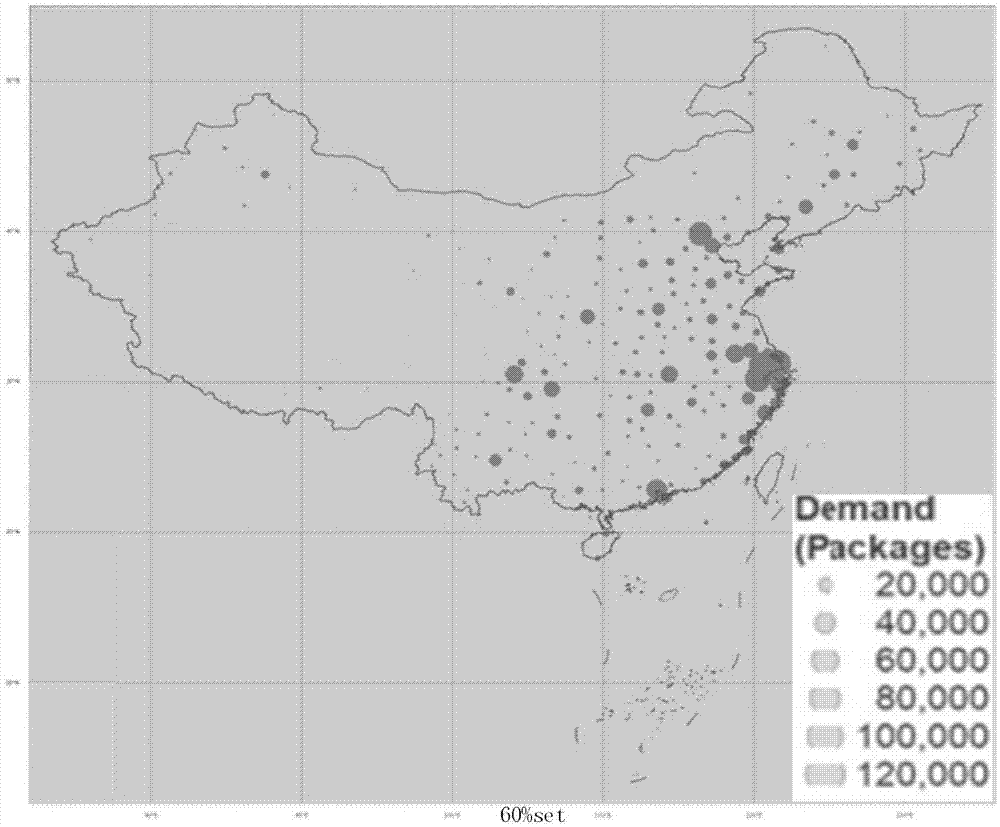
通过将客户进行层次聚类,使得问题再一次被简化。通过设置不同的阈值将371个城市进行聚类,减少到总大小的80%,60%,40%,图4所示代表聚类后的被融合在一起的顾客的平均需求分布。
- 还没有人留言评论。精彩留言会获得点赞!