基于翻转概率的前向离散神经网络样本选择方法及其装置与流程
本发明涉及前向离散神经网络设计时的学习样本的选择方法及其装置,尤其涉及可有效提高神经网络分类效率的基于翻转概率的学习样本选择方法及其装置,属于智能科学与技术中的机器学习领域。
背景技术:
前向离散神经网络是一种网络输出和中间层的激活函数的输入输出都是离散值的一类神经网络,其网络输入可以是连续值。在设计离散神经网络分类器时,训练样本的标记一般是由专家来完成的,这往往要花费大量的金钱和时间代价。以往选择需要标记的样本时,一般是从已获得的无标号样本中随机抽取的。这样训练出一个分类器往往需要大量的标记过的样本,需要花费很大的人力物力,而且容易使得训练时间延长。
样本挑选技术是将无标记的样本经过某种准则的筛选,得到的样本使用人工进行标记。这些标记的样本加入到训练集中。分类器经过这些训练集样本的训练,能更好地改进其性能。样本挑选技术的关键是如何构造一个好的筛选准则,使得使用尽量少的标记样本得到尽量好的分类器分类性能。
样本挑选算法中比较有影响的筛选准则主要有:1)不确定性采样准则:在这个准则中,设计者认为根据信息论的知识,样本的香农熵越大说明样本所含的信息量越大。选择信息量越大的样本对改进分类器的性能越好。而样本的熵越大说明这个样本的类别越不确定,故名不确定性采样。在这个指导思想下又衍生出很多种算法,比如选择各个类别后验概率差最小算法等等。2)委员会机器准则:使用已有的训练集利用不同的复杂度训练出一族分类器,由这一族分类器对未标记的样本分别进行分类,挑选这些分类器分类标号最不确定的样本。3)期望误差减少法:这种算法以减少分类误差为准则挑选样本。相对来讲这个算法对减少分类误差最为直接,也比较容易理解。但这种算法复杂度特别高,对于很多比较复杂的问题不适用。上述这些准则都能应用到神经网络分类器中。
以上筛选准则大致上集中在样本的不确定性或者分类器的误差方面。本发明提供一种基于翻转概率的前向离散神经网络样本选择方法及其装置,以期实现较好的筛选效果。
技术实现要素:
发明目的:本发明的首要目的在于提供一种以前向离散神经网络翻转概率为基准的学习方法及其装置,从而有效提高离散神经网络分类器的分类性能。
技术方案:一种基于翻转概率的前向离散神经网络样本选择方法,包括以下步骤:
1)从未经标记的训练样本中随机选取一小部分样本进行标记以形成训练样本集;
2)利用训练样本集训练神经网络,得到经过训练的分类器;
3)计算未经标记的样本在已有分类器下的翻转概率,并按照翻转概率从大到小排序,根据需求,利用翻转概率取得一批在已有分类器中翻转概率相对大的样本;
4)将所得翻转概率大的样本加入到已有训练样本集中,得到新的训练样本集,并利用新的训练样本集训练神经网络,得到新的分类器;
5)利用测试样本集对步骤4)得到的新的分类器进行测试,若测试结果满足用户要求则结束样本选择,若所述测试结果不满足用户要求则回到步骤3),重复步骤3)~5),直到分类器性能达到要求为止。
本发明的另一目的在于提供一种基于翻转概率的前向离散神经网络样本选择装置,所述装置包括:
训练样本集形成模块,其请求用户从未经标记的训练样本中随机选取一小部分样本进行标记以形成训练样本集;
训练模块,其利用已有训练样本集训练神经网络,得到经过训练的分类器;
判定模块,其计算未经标记的样本在已有分类器下的翻转概率,根据计算结果挑选出一批在已有分类器中翻转概率大的样本;
训练样本集更新模块,其将判断模块挑选出的翻转概率大的样本加入到已有训练样本集中,得到新的训练样本集;
测试模块,利用测试样本集对得到的分类器进行测试。
本发明具有如下有益效果:
(1)本方法在选择训练样本时采用了一种新颖的样本挑选方法,相对于被动学习算法而言,所需选择标记的训练样本数量大大减少,降低了标记样本所耗费的时间和代价,且有效提高了前向离散神经网络的分类效果。
(2)根据本发明的样本选择方法及其装置提出了一种基于前向离散神经网络翻转概率的有效样本选择方法,通过挑选翻转概率大的样本点,来寻找在其周围信息丰富的样本点,这些样本点往往对训练分类器是重要的。通过这样的方法可以有效减少需要标记样本点的数量,减少标记的代价并提高分类器的性能。
附图说明
图1为madaline神经网络结构图;
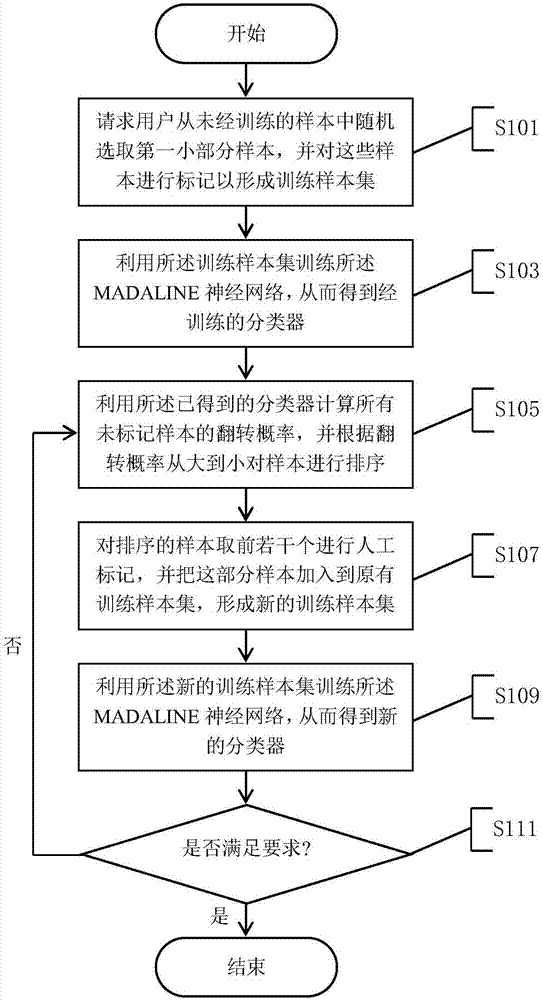
图2为本发明具体实施方式的基于翻转概率的madaline神经网络样本选择方法流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
现以前向离散神经网络中的madaline神经网络为例,说明根据本发明的前向离散神经网络样本选择方法。然而,本领域的技术人员应理解,本发明不限于madaline神经网络,而是可以应用于其它前向离散神经网络。
madaline是一种全连接的前向神经网络,适用于目标的分类。madaline的结构如图1所示,它是一种三层前向离散网络:输入层ma由输入模式节点组成,xi表示输入模式向量的第i个分量(i=1,2,...,n);第二层是隐含层mb,它由m个节点bj(j=1,2,...,m)组成。第三层是输出层mc,它由p个节点ck(k=1,2,...,p)组成。
对于上述madaline神经网络的训练在这里采用标准mrii学习算法。
下面我们定义上述神经网络的翻转概率。
当神经网络训练完成后,它的映射关系也就确定了。设映射关系函数为f(x)(其中x为输入向量),定义
为该神经网络在输入x处的翻转概率。其中δ是一个每个元素在[-h,h]上服从均匀分布的随机向量,其中h是一个小的正数,经验取值为0.01~0.05。p是神经网络输出层的网元数;fi(x)为输出向量中第i个分量。
由翻转概率定义可以看出,神经网络在某一点的翻转概率可以度量神经网络在这一点周围变化的快慢。我们认为,周围变化快的样本点可以对神经网络的训练带来更多信息,因此更有价值。
如图2所示为本发明基于翻转概率的madaline神经网络样本选择方法流程图。
在步骤s101中,从未经标记的训练样本中随机选取一小部分样本,并对这些样本进行标记以形成训练样本集。
在具体实施中,上述一小部分一般不超过5%。
在步骤s103中,利用所述训练样本集训练所述madaline神经网络,从而得到经训练的分类器。
在步骤s105中,利用所述经训练的分类器计算所有未标记样本的翻转概率,并根据翻转概率从大到小对样本进行排序。
在步骤s107中,对排序的样本取前若干个进行人工标记,并把这部分样本加入到原有训练样本集,形成新的训练样本集。
在步骤s109中,利用所述新的训练样本集训练所述madaline神经网络,从而得到新的分类器。
在步骤s111中,利用测试样本集对步骤s109得到的新的分类器进行测试,若测试结果满足用户要求则结束样本选择,若所述测试结果不满足用户要求则回到步骤s105,重复步骤s105~s111,直到分类器性能达到要求为止。
为了尽快得到准确度较高的分类边界,通过步骤s111可以进入一个循环过程,每次对翻转概率较大的一部分样本进行人工标记,并将其加入训练样本集中,然后使用新的训练样本集训练出新的分类器。再用测试集对其测试,得到一个新的测试结果。如果该测试结果已经满足用户要求则停止样本选择和主动学习,反之,则进入下一轮的循环过程。
现描述根据本发明的基于翻转概率的madaline神经网络样本选择装置。
所述装置包括:
训练样本集形成模块,其请求用户从未经标记的训练样本中随机选取一小部分样本进行标记以形成训练样本集;
训练模块,其利用已有训练样本集训练madaline神经网络,得到经过训练的分类器;
判定模块,其计算未经标记的样本在已有分类器下的翻转概率,根据计算结果挑选出一批在已有分类器中翻转概率比较大的样本;
训练样本集更新模块,其将判断模块挑选出的翻转概率比较大的样本加入到已有训练样本集中,得到新的训练样本集;
测试模块,利用测试样本集对得到的分类器进行测试。
上述装置的工作过程是:
a、首先,训练样本集形成模块请求用户从未经训练的样本中随机选取一小部分样本
进行标记以形成样本训练集;
b、然后,训练模块利用所述样本训练集训练madaline神经网络,从而得到经过训练的分类器;
c、接着,判定模块计算未经标记的样本在已有分类器下的翻转概率,并根据计算结果挑选出一批在已有分类器中翻转概率比较大的样本;
d、接着,训练样本集更新模块将判断模块挑选出的翻转概率比较大的样本加入到已有训练样本集中,得到新的训练样本集;
e、接着,训练模块再利用新的训练样本集重新训练madaline神经网络,得到新的分类器;
f、最后,测试模块利用测试样本集对得到的新的分类器进行测试。若测试结果满足用户要求则结束样本选择,若测试结果不满足用户要求,则回到步骤c,重复步骤c~f,直到分类器性能达到要求为止。
- 还没有人留言评论。精彩留言会获得点赞!