基于混合蝙蝠算法的支持向量机参数选择方法与流程
本发明属于人工智能与机器学习领域,涉及支持向量机(SupportVectorMachine,SVM)模型这一智能判别方法在参数选择方面的改进。
背景技术:
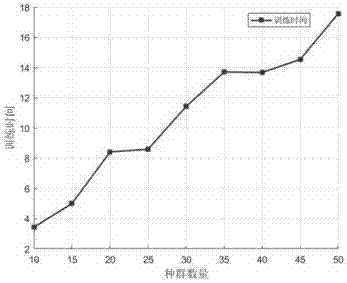
:支持向量机(SupportVectorMachine,SVM)是一种建立在计算学习理论的结构风险最小化原则和VC维理论的分类器。其主要思想是针对两类分类问题,在高位空间中寻找一个最优超平面作为两类的分割,以保证最小的分类错误率。相对于传统仅以最小化经验风险原则作为模型的分类器,SVM在处理小样本时可以有效避免过拟合现象,而且SVM对处理线性不可分的问题有很好的分类效果。在问世之后就受到了广泛的关注和应用,在机器学习和数据挖掘领域方面表现了良好的性能。但是,SVM在参数选择方面还有一定的问题,其中C和σ的取值对支持向量机的分类性能影响很大,许多学者应用智能算法优化参数。群体智能算法在SVM参数选择问题上取得了良好的结果。Chou和Chen使用遗传算法(geneticalgorithm,GA)优化SVM参数选择来预测纠纷发生的概率。缺点是操作比较繁琐,变异机制导致稳定性变差,计算量增大,训练时间较长。姜明辉等使用改进的PSO算法选取最合适的支持向量机参数,与GA相比,PSO算法没有GA中较为复杂的变异、变异等操作,仅利用个体经验和种群特征进行自适应调整,规则较为简单,收敛速度较快。但同时容易陷入局部最优解,导致收敛精度低和不易收敛等缺陷。Zhang等用蚁群算法(AntColonyOptimization,ACO)同时进行特征选取和参数选择进行智能故障诊断,也取得了良好的实验结果。然而这些算法都是优化基本支持向量机,即确定惩罚因子C和核函数σ两个参数,而基于不同损失的SVM有三个参数需要确定(两个惩罚因子和核函数),尚未有相关研究,需要对算法进行改进。本发明用一种智能优化算法,蝙蝠算法(BatAlgorithm,BA)与其改进算法来优化不同损失的SVM。蝙蝠算法是Xin-sheYang于2010年提出一种群体智能搜索算法,主要思想是模拟蝙蝠在捕食中的回声定位行为。蝙蝠算法具有模型简单、鲁棒性强、并行程度高等优点。自问世就收到广大学者的热切关注,其理论和应用经过近几年的发展也得到了很大的进步,已经被广大研究者普遍用于自然科学和工程实践中,如工程优化,模式识别、K均值聚类、特征选择和数据挖掘等领域中。蝙蝠算法拥有群体智能算法的长处,例如强大的全局搜索范围和较短的收敛时间,AlaaTharwat将其用于SVM参数选择,取得了良好的实验效果,但同时也存在一些群体智能算法共同的缺点,比如容易发生算法的早熟现象,求解精度达不到目标要求等。针对这种现象,引入差分进化算法中的交叉、选择和变异算子,从而增强算法的搜索能力,避免其过早地陷入局部最优解。进而利用改进BA算法优化SVM参数选择。技术实现要素:本发明采用的技术方案为基于混合蝙蝠算法的支持向量机参数选择方法,提出引入差分进化变异机制和基于两类误判率的新的适应度函数的混合蝙蝠算法进行SVM参数的选择。利用蝙蝠算法对参数进行优化搜索,并在优化搜索基础上引入差分进化算法对每次迭代过程中的蝙蝠位置进行交叉、选择和变异,从而增强算法的全局搜索能力,避免其过早地陷入局部最优解。即利用模型DEBA-SVM进行SVM参数选择。(1)基本蝙蝠算法蝙蝠具有简单易行,鲁棒性强的特点,可快速对SVM中惩罚因子C和核函数σ进行优化。设定义域为D维搜索空间,在t时刻蝙蝠i的速度及位置按照下面公式进行更新:其中和分别表示蝙蝠个体i在t和t-1时刻的飞行速度;和分别表示蝙蝠个体i在t和t-1时刻所处的位置,即对应SVM中一组惩罚因子与核函数的组合。x*是蝙蝠种群中当前的全局最优解,频率fi为蝙蝠个体i在搜索目标时发出的脉冲频率,定义如下:fi=fmin+(fmax-fmin)β(3)β∈[0,1]是均匀分布中的一个随机向量。fmax和fmin分别是脉冲频率的最大值和脉冲频率的最小值,根据问题域的规模进行调整。初始时每个蝙蝠都被随机分配一个在[fmin,fmax]均匀分布的频率值。对于局部搜索而言,每当有新的最优解出现,每只蝙蝠都会根据公式(4)在最优解附近随机产生一个新的坐标:∈是位于[-1,1]的一个随机值,At是t时刻所有蝙蝠响度的平均值。此时响度Ai和脉冲频度ri也会随着迭代的进行被不断更新,由公式(5)和公式(6)给出。其中,是初始脉冲频度,为蝙蝠个体i在t时刻的脉冲频度。和分别是蝙蝠个体i在t和t-1时刻的脉冲音强;γ和α均为[0,1]之间的正实数,分别是脉冲频度和脉冲响度的衰减系数,使γ=α。脉冲频度和响度只有产生新解的时候才会被重新生成,这也表明所有的蝙蝠都会在飞行过程中逐渐向最优解靠拢。对于目标函数f(x),目标变量X=(x1,x2,…,xn)T的优化问题,优化方法的流程实现如下:S1.1参数初始化,具体包括:设置种群规模即蝙蝠数目;算法迭代次数;初始化每只蝙蝠的脉冲音量脉冲发射频度按照公式(3)产生脉冲频率fi,随机初始化种群位置S1.2按照公式(1)~(2)更新每只蝙蝠的速度和位置S1.3所有蝙蝠个体都需要生成一个位于[0,1]之间均匀分布的随机数rand(0,1),rand(0,1)代表在[0,1]内均匀分布上随机产生的一个实数,若满足条件rand(0,1)>rit,则按照公式(4)在当前最优蝙蝠个体位置附近进行小范围的扰动从而生成新的位置,并对其进行越界规范化处理;S1.4计算所有蝙蝠的适应度值并排序,找出当前的最优解和最优值;S1.5对每个蝙蝠个体产生再生成一个均匀分布的随机数rand(0,1),若就认可公式(3)中产生的扰动位置,并根据公式(5)和(6)更新和S1.6最后找出当前全局最优解,并验证当前全局最优解是否满足跳出循环条件,若满足条件则跳出循环输出最优解位置,否则转入S1.3。(2)差分进化变异机制基本蝙蝠算法在求解优化问题的初期收敛速度较快,后期由于缺乏变异机制,整个蝙蝠种群在向最优位置靠近的过程中逐渐丧失了多样性和差异性,容易导致算法陷入某个局部最优解,最终影响BA-SVM模型优化效果。所以针对基本BA算法存在的不足,把差分进化(DifferentialEvolution,DE)算法中变异、交叉和选择机制融入到基本BA算法中,提出新的模型DifferentialEvolutionBatAlgorithmOptimizeSVM(DEBA-SVM)算法。模型中每次迭代过程结束后,蝙蝠位置xi(t)没有径直进入下一轮迭代过程,而是在种群个体位置之间进行变异、交叉等操作得到新的蝙蝠位置后再进入下一次迭代。蝙蝠算法演化过程与遗传算法类似,存在变异、交叉和选择三个环节。算法主要流程如下:令xi(t)为第t代的第i个个体,种群规模为NP。则xi(t)=(xi1(t),xi2(t),…,xin(t)),xi(t)∈[Xmin,Xmax],[Xmin,Xmax]是搜索空间。实现过程如下:S2.1初始化种群:设初始时间t=0,在d维空间上随机初始化生成NP个蝙蝠位置xi(t),i=1,2,...,l,l为蝙蝠群体规模;S2.2变异过程:对种群中每个个体xi(t)而言,从种群中随机选择3个个体:xa(t)、xb(t)、xc(t),且a≠b≠c≠i,且a,b,c∈{1,2,…,NP}。F为缩放因子,F∈[0,2]。按照公式(3)vi(t)=xa(t)+F(xb(t)-xc(t))(7)生成变异个体vi(t)。若则令vi(t)=Xmin+rand(0,1)*(Xmax-Xmin)。S2.3交叉过程:交叉操作在个体向量的分量上进行,可以增加种群的多样性。按照公式(8),对第t代蝙蝠种群个体xi(t)和其中间变异种群个体vi(t)进行个体间交叉操作:其中CR∈[0,1]为交叉概率,,randi(1,d)产生一个在[1,d]内均匀分布的随机整数,j=1,2,…,d,d为搜索空间维度。这种交叉策略保证变异个体vi(t)至少贡献一个维度的分量给向量ui(t)。S2.4选择操作:判断个体ui(t)的适应度函数值是否优于xi(t)适应度函数值决定是否产生新一代个体xi(t+1);fit(x)代表适应度函数,此处的目标函数是求最小的适应度值。(5)反复执行步骤S2.2至S2.4直到达到算法的迭代次数或者所要求的求解精度,然后输出最优解。DE最突出的特点是变异操作,根据个体之间的差分信息生成随机扰动量,使得算法具有自适应性和适度的变异性。在算法过程前期,种群中的个体差异度较大,产生的扰动量也比较大,此时变异操作使算法能够在更大搜索空间内进行探测,拥有很强的广度探索能力。而在蝙蝠算法运行到后期,种群中的个体差异度变小,产生的随机扰动量也比原来小从而使算法具有较强的局部开采能力。在自适应变异操作的帮助下,差分算法在求解多项问题上(例如多目标优化,函数求极值)具备独到的长处。(3)DEBA-SVM模型构建DEBA-SVM模型分为三个部分。1)蝙蝠算法:通过蝙蝠算法生成若干个蝙蝠位置,每只蝙蝠的位置都对应一组支持向量机模型参数(C1,C2,σ),其中C1、C2为SVM中的惩罚因子,σ是核函数,并且不断向最优组合的位置靠近。2)支持向量机分类模型:以蝙蝠位置(C1,C2,σ)作为入口参数训练模型,对数据集进行10-折交叉验证得到适应度值。3)差分进化过程:在每次蝙蝠算法迭代过程结束之后,插入差分进化过程对蝙蝠种群的位置进行变异、交叉和选择操作,增强种群的多样性,避免陷入局部最优。DEBA-SVM算法具体步骤如下:S3.1初始化蝙蝠种群;S3.2计算蝙蝠种群个体的适应度(此处指SVM的分类准确率),找出当前的最优解和最优值;S3.3利用公式(1)至(3)更新蝙蝠的脉冲频率、飞行速度和位置;S3.4根据公式(4)在当前最优蝙蝠个体位置附近进行小范围的扰动从而生成新的位置,并对其进行越界规范化处理;S3.5如果满足条件且就接受新解并对脉冲频度和响度进行更新;S3.6更新蝙蝠种群的最优解和最优值;S3.7利用DE算法对蝙蝠种群个体进行变异、交叉和选择操作;S3.8完成此次迭代,检查是否满足算法结束条件,如果不满足就转至S3.2。与常见的模型如GS-SVM、GA-SVM、PSO-SVM等相比,DEBA-SVM模型运行速度快,优化效果好,分类精度高。附图说明图1:DEBA-SVM总体设计图。图2:蝙蝠数量对分类错误率的影响。图3:蝙蝠数量对训练时间的影响。图4:种群迭代次数对分类错误率的影响。图5:种群迭代次数对训练时间的影响。具体实施方式实验平台配置如下:CPU型号IntelCorei5-4590,内存大小8GB,操作系统64位Window7和Matlab2017b。本文利用UCI机器学习数据库中的Iris(鸢尾花数据集),Ionosphere(电离层数数据集),Liver-disorders(肝损伤数据集)、Breastcancer(乳腺癌数据集)和Sonar(声纳数据集)进行实验验证。数据集详情特征如下:表1实验数据详情数据集维数样本数量类别数Iris41503Ionosphere343512Liver-disorders63452Breastcancer136832Sonar602082参数的调节和设计一个良好的算法本身一样重要,下面先研究差分进化蝙蝠算法的相关取值再与其他参数选择算法做比较。(1)蝙蝠算法参数设置我们需要足够多的蝙蝠数量去探索整个样本空间,但是太多的蝙蝠同时又会增加训练时间。所以这里研究蝙蝠数量pop对分类错误率和训练时间的影响。测试种群数量10-50之间算法的表现。SVM使用LIBSVM工具箱实现,采用RBF作为核函数,C=[1,1000],γ=[0.01,100],采用10折交叉验证的方式对数据集进行训练和测试,取30次实验结果的平均数取30次实验结果的平均值。图2是基于Iris数据集的实验结果,可以看出随着参与训练蝙蝠数量的增加,得到的分类错误率逐渐减少,在蝙蝠种群数量达到25之后,算法的平均分类错误率不再下降。如图3所示,训练时间随着蝙蝠数量的增长也在同步增加。此外迭代次数也在一定程度上影响着模型的表现,所以接下来探讨迭代次数对分类错误率和训练时间的影响。迭代次数的测试范围是以5为步长,最小值取10,最大值取40,取30次实验结果的平均值,结果如图4所示。可以看出,随着种群进化代数的增加,分类错误率总体是在不断减小的,训练时间不断增长。当迭代次数到达一定程度之后,分类错误率趋于稳定。所以我们使用迭代次数为25。至于蝙蝠算法的其他参数,表2列出详细的参数取值。表2DEBA参数设置参数值频率(fmin,fmax)fmin=0,fmax=2脉冲频率(r0)0.5响度(A0)[1,2]种群数量(pop)30迭代次数(iter)25尺度因子(F)0.5交叉因子(CR)0.1(2)相关算法比较SVM基于LIBSVM工具箱实现,使用RBF作为核函数C=[1,1000],γ=[0.01,100]。这里我们将DEBA-SVM算法与网格搜索算法(GS-SVM),粒子群算法(PSO-SVM)和遗传算法(GA-SVM进行SVM参数选择实验,实验结果对比如表3所示。基于UCI数据库中的Iris,Ionosphere,Liver-disorders,Breastcancer和Sonar数据集进行验证,采用10折交叉验证的方式对数据集进行训练和测试取30次实验结果的平均数。表3分类结果由表3的实验结果可以看出,DEBA-SVM在所有的数据集上都产生了比GS-SVM和PSO-SVM要小的分类错误率。虽然网格搜索具有很好的可解释性和并行性,固定的搜索步长降低了计算时间却也同时限制了搜索范围。而对于PSO算法而言,则是因为它有很多固定的参数需要先行确定,相比而言,DEBA的参数例如脉冲响度A和脉冲频度r都可以在迭代过程中自适应的变化。所以DEBA-SVM能够自动地在搜索模式和勘探模式之间切换。所以DEBA算法相比PSO具有更快的收敛速度和寻优路径。此外在大多数的数据集上,DEBA-SVM不仅在分类准确率方面要比GA-SVM高,在结果稳定性方面也是强于GA-SVM的。DE算法进化后期,种群中个体之间的差异变小,结果趋于收敛,相比于遗传算法而言具有较强的局部搜索能力。此外,还将DEBA-SVM与BA-SVM的在分类错误率和训练时间方面进行了对比实验,结果如表4所示。表4DEBA-SVM与BA-SVM实验结果对比引入的差分进化过程毫无疑问会增加了算法的复杂性和变异性,所以DEBA-SVM的训练时间比BA-SVM要长,此外DEBA-SVM也可以比BA-SVM产生更稳定的结果分布,说明一定的变异机制可以增强算法的全局寻优能力。此外DEBA-SVM可以取得更低的分类错误率,分别降低了0.13%,0.18%,3.8%,0.19%和0.08%。总体来说,差分进化过程增加了10%左右的训练时间,在一些样本点数量较多的数据集,比如Breastcancer,增长了为15.26%。不过分类错误率的下降带来的收益远远超过略微增加的训练时间成本。综合上述实验,本发明在利用蝙蝠算法对参数进行优化搜索的基础上,引入差分进化算法对每次迭代过程中的蝙蝠位置进行交叉、选择和变异,增强算法的全局搜索能力,避免其过早地陷入局部最优解,进而利用DEBA优化SVM参数选择并取得了优异效果。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1