一种基于规则和数据网络融合的情感分析方法与流程
本发明属于自然语言处理领域,特别涉及中文文本情感分析方法,提供一种基于规则和神经网络融合的情感分析方法。
背景技术:
随着互联网技术的快速发展,互联网上(包括门户网站、电子商务网站、社交网站、音/视频分享网站、论坛、博客、微博等)产生了海量的、由用户发表的对于诸如人物、事件、产品等目标实体的评论信息。与客观性文本不同的是,这些主观色彩浓厚的评论信息蕴含着大众舆论对上述目标实体的看法,对潜在用户、商家以及政府部门等具有十分重要的参考价值。然而,如果采用人工方式对这些海量信息进行收集和分析,显然是成本高昂、低效和困难的。利用计算机对非结构化的文本评论进行分类和提取的文本情感分析技术应运而生。
目前,国内外使用最多的文本情感分析方式有多种,机器学习的情感分析,基于语义规则的情感分析以及构建神经网络模型情感分析方法。其中有监督和半监督的机器学习和神经网络方法中分类起的训练需要一定数量经过标注的训练样本,然而人工标注过程相当耗时费力,成本昂贵,无监督学习则是无需标注的。基于语义规则的文本倾向性研究中,研究者一般考虑词语,句子,段落和篇章等多个角度自底向上进行层次分析。通过规则计算情感词汇情感值,得到句子、段落以及篇章的整体情感值,从而获得最终的情感倾向信息。
传统的基于机器学习和深度学习情感分类和神经网络浅层模型会出现上下文语义缺失,而本方法利用情感语义规则计算评论得出情感得分以及统计情感词数目构建规则模型的特征向量,然后将该特征向量作为新特征融入LSTM(Long Short-Term Memory)神经网络模型特征中。最终,从而能更精确根据上下文语义进行情感分类。
技术实现要素:
本发明针对现有技术中均存在情感分析方法的不足,提供了一种基于规则和神经网络融合的情感分析方法,对中文文本进行更准确的判断。
本发明解决其技术问题所采用的技术方案具体包括以下步骤:
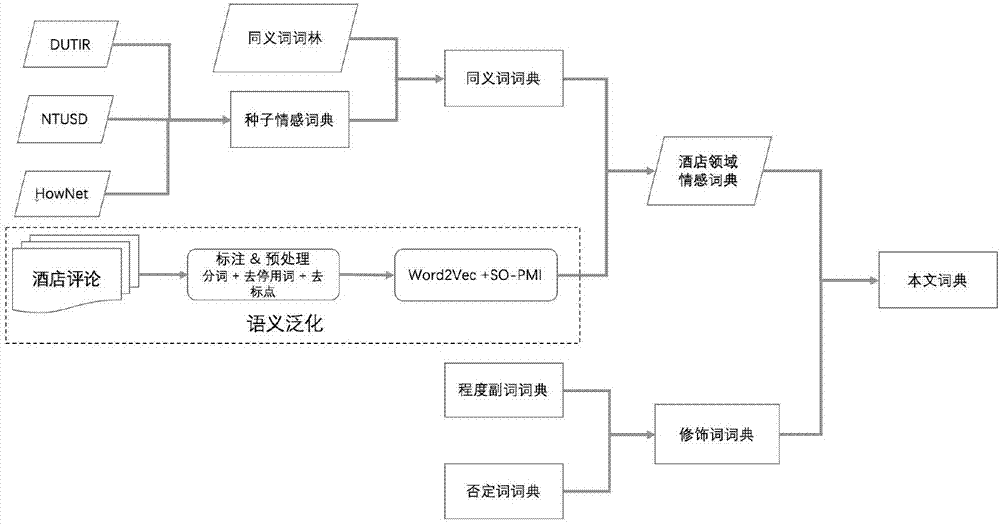
步骤1、获取关于目标对象一定数量的结构化评论组成待分析的语料库,根据权威机构提供的情感词典,结合语料库通过语义分析泛化得到情感词典,情感词典包含情感极限、情感程度以及修饰词词典,如图2所示;
步骤2、对情感词匹配和情感词关系预处理,将语料库进行分词、文本分析、匹配本体库和评论句子中情感词,标注情感词的情感信息以及上下文对应的依存关系。其中,情感信息包含词的情感强度、情感极性和情感词词性;
步骤3、情感计算和情感倾向判断;
根据评论中情感信息以及依存关系,结合系统规则进行情感值计算,得到情感得分。将情感得分和褒贬情感词数目作为新的特征采样,采用尾部嵌入到构建的特征向量中,建立LSTM模型进行情感训练和预测,得到最终情感倾向结果;
进一步地,根据步骤1所述情感本体库构建,具体步骤如下:
步骤1-1.使用网络机构中现有权威的情感本体库,去掉重复词之后作为原始本体库;
步骤1-2.从知网中下载同义词词林,将原始情感词典进行同义扩充;
步骤1-3.为了得到丰富的情感词典,引入word2vec工具,该工具能根据输入样本泛化推理得到和情感词语义相似的词。首先,情感分类评论进行去重和预处理噪点信息,之后对文本评论通过Jieba工具进行分词,得到构建情感词典的语料,利用连续词袋模型(CBOW)和负采样训练的算法进行训练。
连续词袋模型中,维度设置成50维,迭代次数为100词,之后得到词向量集合。在过程中,使用python版本word2vec中similar_by_word获取同义词林词典的近义词,通过余弦距离的绝对值进行衡量相似性(越接近1表示语义约相似)。例如计算词向量和词距离,公式如下:
SO_PMI定义了点互信息量的概念,用来计算两个词之间的语义相关性,两个词语原词w1和相似语义词w2的PMI公式为::
P(w1&w2)表示w1和w2共现的概率,P(w1)和P(w2)表示两个词各自出现的概率。通过计算,可以将两个词关系装换为三个状态:
关于点互信息(SO-PMI)的计算,选取经过同义词词典扩展的正面词和负面词作为基准词,用Pwords代表正面,Nwords代表负面两组词集合。这些词的情感倾向都非常明显,根据word2vec推理后的相似词w2分别与Pwords和Nwords互信息的差值赋予情感倾向。SO-PMI(w)公式为:
SO-PMI(w2)=ΣPword∈PwordsPMI(w2,Pword)-ΣNword∈NwordsPMI(w2,Nword) (4)
在一般情况下0作为SO-PMI的阈值,所以结果分为:
进一步的,步骤2所述的对情感词匹配和情感词关系预处理,本专利将原词w1和相似语义词w2相关且情感相同的词赋予相同的情感倾向和相同情感程度,并加入到情感词典中。
步骤2-1.利用分词工具和自定义用户词典进行分词,然后结合哈工大句法分析平台,将评论转换为tri-gram形式,组成语义依存关系队列。
步骤2-2.语义依存关系队列包含每个词的位置、词性标注以及前词后词的位置关系,能充分定位情感词的位置以及该情感词所修饰的名词;
2-2-1.通过匹配情感本体库,定位情感词的情感初始极性以及程度修饰权值。
2-2-2.得到情感词的位置信息,将情感词抽取出来构建情感词的特征列表。特征列表包含情感词的位置、情感极性和权值。
进一步地,根据步骤3情感计算和情感倾向判断,具体步骤如下:
步骤3-1.针对步骤2-1得到语义依存关系队列,构建本体库中匹配情感词信息,使用短语情感倾向评估法来近似计算评论的情感得分,得到褒贬情感词数。
步骤3-2.采用LSTM模型对文本情感极性评论进行最终分类。
对语料库中已标记过的评论进行训练,80%的评论作为训练集,20%的评论作为测试集。训练集的具体处理如下:
首先通过分词,删除停用词;
其次从步骤2-2中匹配情感词,并赋予情感词的权重;
然后将步骤3-1中的情感得分,褒贬词数形成的特征组合尾部嵌入到步骤1-3得到的句子向量空间集合,拼接步骤如下:
设第k个句子sk=(w0,w1,…,wi),其中wi为句子k中的第i个词。针对词语中wi本专利通过word2vec训练通过得到w1词的特征向量其中k表示向量维度。利用规则模型得到情感得分和情感信息向量Rk=(score,pcount,ncount),句子特征向量的组合规则模型得到的向量嵌入词向量得到,假设组合后的向量为xi=(γ0,γ1,…,γd),其中d为维度,特征融合公式如下:
其中,d,k满足以下关系d=k+3,然后根据神经网络模型架构流程图3建立标准LSTM模型,再进行分类得到最终评论情感倾向。
本发明有益效果如下:
文本特征粒度不局限于词间向量,同时包括句子级别。
情感分类融入了规则和情感词的维度,规则是基于句法语义,包括强度副词和倒置词,可以提高情感分析的精确度,而且规则的情感得分计算包含了更精确的情感信息。
融合的特征向量同样满足神经网络分类模型的对特征的需求,也能让模型在自我训练的时候学到更多的情感特征。
附图说明
图1为本发明情感分析方法的总体流程图。
图2为本发明构建情感本体库的对应流程。
图3为本发明神经网络模型架构流程图
具体实施方式
下面结合附图和实施例对本发明作进一步说。
如图1-3所示,一种基于规则和神经网络融合的情感分析方法,具体包括以下步骤:
步骤1、获取关于目标对象一定数量的结构化评论组成待分析的语料库,根据权威机构提供的情感词典,结合语料库通过语义分析泛化得到情感词典,情感词典包含情感极限、情感程度以及修饰词词典,如图2所示;
步骤2、对情感词匹配和情感词关系预处理,将语料库进行分词、文本分析、匹配本体库和评论句子中情感词,标注情感词的情感信息以及上下文对应的依存关系。其中,情感信息包含词的情感强度、情感极性和情感词词性;
步骤3、情感计算和情感倾向判断;
根据评论中情感信息以及依存关系,结合系统规则进行情感值计算,得到情感得分。将情感得分和褒贬情感词数目作为新的特征采样,采用尾部嵌入到构建的特征向量中,建立LSTM模型进行情感训练和预测,得到最终情感倾向结果;
进一步地,根据步骤1所述情感本体库构建,具体步骤如下:
步骤1-1.使用网络机构中现有权威的情感本体库,去掉重复词之后作为原始本体库;
步骤1-2.从知网中下载同义词词林,将原始情感词典进行同义扩充;
步骤1-3.为了得到丰富的情感词典,引入word2vec工具,该工具能根据输入样本泛化推理得到和情感词语义相似的词。首先,情感分类评论进行去重和预处理噪点信息,之后对文本评论通过Jieba工具进行分词,得到构建情感词典的语料,利用连续词袋模型(CBOW)和负采样训练的算法进行训练。
连续词袋模型中,维度设置成50维,迭代次数为100词,之后得到词向量集合。在过程中,使用python版本word2vec中similar_by_word获取同义词林词典的近义词,通过余弦距离的绝对值进行衡量相似性(越接近1表示语义约相似)。例如计算词向量和词距离,公式如下:
SO_PMI定义了点互信息量的概念,用来计算两个词之间的语义相关性,两个词语原词w1和相似语义词w2的PMI公式为::
P(w1&w2)表示w1和w2共现的概率,P(w1)和P(w2)表示两个词各自出现的概率。通过计算,可以将两个词关系装换为三个状态:
关于点互信息(SO-PMI)的计算,选取经过同义词词典扩展的正面词和负面词作为基准词,用Pwords代表正面,Nwords代表负面两组词集合。这些词的情感倾向都非常明显,根据word2vec推理后的相似词w2分别与Pwords和Nwords互信息的差值赋予情感倾向。SO-PMI(w)公式为:
SO-PMI(w2)=ΣPword∈PwordsPMI(w2,Pword)-ΣNword∈NwordsPMI(w2,Nword) (4)
在一般情况下0作为SO-PMI的阈值,所以结果分为:
进一步的,步骤2所述的对情感词匹配和情感词关系预处理,本专利将原词w1和相似语义词w2相关且情感相同的词赋予相同的情感倾向和相同情感程度,并加入到情感词典中。
步骤2-1.利用分词工具和自定义用户词典进行分词,然后结合哈工大句法分析平台,将评论转换为tri-gram形式,组成语义依存关系队列。
步骤2-2.语义依存关系队列包含每个词的位置、词性标注以及前词后词的位置关系,能充分定位情感词的位置以及该情感词所修饰的名词;
2-2-1.通过匹配情感本体库,定位情感词的情感初始极性以及程度修饰权值。
2-2-2.得到情感词的位置信息,将情感词抽取出来构建情感词的特征列表。特征列表包含情感词的位置、情感极性和权值。
进一步地,根据步骤3情感计算和情感倾向判断,具体步骤如下:
步骤3-1.针对步骤2-1得到语义依存关系队列,构建本体库中匹配情感词信息,使用短语情感倾向评估法来近似计算评论的情感得分,得到褒贬情感词数。
步骤3-2.采用LSTM模型对文本情感极性评论进行最终分类。
对语料库中已标记过的评论进行训练,80%的评论作为训练集,20%的评论作为测试集。训练集的具体处理如下:
首先通过分词,删除停用词;
其次从步骤2-2中匹配情感词,并赋予情感词的权重;
然后将步骤3-1中的情感得分,褒贬词数形成的特征组合尾部嵌入到步骤1-3得到的句子向量空间集合,拼接步骤如下:
设第k个句子sk=(w0,w1,…,wi),其中wi为句子k中的第i个词。针对词语中wi本专利通过word2vec训练通过得到w1词的特征向量其中k表示向量维度。利用规则模型得到情感得分和情感信息向量Rk=(srore,pcount,ncount),句子特征向量的组合规则模型得到的向量嵌入词向量得到,假设组合后的向量为xi=(γ0,γ1,…,γd),其中d为维度,特征融合公式如下:
其中,d,k满足以下关系d=k+3,然后根据神经网络模型架构流程图3建立标准LSTM模型,再进行分类得到最终评论情感倾向。
- 还没有人留言评论。精彩留言会获得点赞!