文本处理比较方法以及装置与流程
本发明属于信息处理技术领域,尤其是涉及一种文本处理比较方法以及设备。
背景技术:
因为工作特殊性,只能由人工检出文件夹差异内容,和原版本库资源文件比较,需要确认内容是否缺失,如果有确实并指出缺失内容。版本库提交内容较多,提交记录多达上千,上万次,每次需要单独取出这些文件,有可能造成遗漏缺失,人工校对,花费时间较多。
在中国专利文献CN101582081A公开了一种数据比对的方法及装置,该方法具体包含以下处理步骤:(1)采集原始数据,生成比对数据和被比对数据;(2)将比对数据读入内存;(3)逐条读取被比对数据,与内存中的比对数据比较,输出比较结果。
上述公开的技术方案首先采集原始数据,生成比对和被比对的两部分数据,进行比对时先将比对数据读入内存,然后逐条读取被比对数据,与内存中的比对数据比较,偷出比较结果。如此,原始数据经过处理生成比对和被比对数据,将比对数据读入内存,逐条读取被比对数据,与内存中的比对数据比较,可以提高了数据比对效率。
但是采用上述专利文献中公开的技术方案并不适用于检测人工检出文件夹是否有差异内容。
技术实现要素:
本发明要解决的技术问题是,提供一种用于检测人工检出文件夹是否有差异内容,且比对效率高的文本处理比较方法。
为解决上述技术问题,本发明采用的技术方案是:该文本处理比较方法,其特征在于,包括以下步骤:
(1)在搜索路径位置,填入文件夹路径,获取人工检出文件夹内所有的文件夹和文件的全路径和文件名称,并产生存储形成第一文本数据;
(2)获取提交日志信息,并将获取到的提交日志信息记录形成第二文本数据;
(3)比较第一文本数据与第二文本数据,核查是否有缺失差异内容;
(4)输出比对结果。
通过对人工检出文件夹内所有的文件夹和文件的全路径和文件名称进行处理,形成第一文本数据,以及对于从版本库获取的提交日志信息进行处理形成第二文本数据,通过全部由软件工具来完成,软件工具可以采用现有的,简化测试人员工作方式,更直接准确的看到检测数据,以到达减少人力成本,时间成本,减少误差的目的;最后对比两份数据对比差异,如果无差异内容,说明人工检出文件内容完整无误。有差异内容需要再次检出人工检出文件夹内容。
优选的方案是,在所述步骤(1)中,填入文件夹路径后,点击搜索文本按钮,通过递归算法,获取人工检出文件夹内所有的文件夹和文件的全路径和文件名称,并产生存储于final.txt文本中形成第一文本数据。
优选的方案是,在所述步骤(2)中,所获取的提交日志信息为svn版本提交日志信息,记录在svn.txt文件中,同时选择对应的版本信息,点击整理svn按钮,进行字符串分割处理及重排序,形成第二文本数据。
优选的方案是,在所述步骤(2)中,所获取的提交日志信息来自于版本库,版本库提交日志因提交路径多文件多,通过正则表达算法,排除无用文件及重复文件记录,具体排除文件规则,要根据实际项目需求添加。
优选的方案是,在所述步骤(3)中,根据所述第一文本数据中的人工路径名称数据,以及所述第二文本数据中的日志名称数据,进行比较,核查是否有缺失差异内容。
本发明要解决的另一个问题是,提供一种用于文本处理比较的装置,包括:
第一处理单元,用于存储将从搜索路径位置填入文件夹路径,获取到的人工检出文件夹内所有的文件夹和文件的全路径和文件名称,并产生存储形成第一文本数据;
第二处理单元,用于存储获取到的提交日志信息,并将获取到的提交日志信息记录形成第二文本数据;
比较单元,将第一文本数据中的每项文本数据信息与第二文本数据中的文本数据信息进行比较;
结果输出单元,输出差异信息并标记。
附图说明
下面结合附图和本发明的实施方式进一步详细说明:
图1是本发明文本处理比较方法的流程示意图;
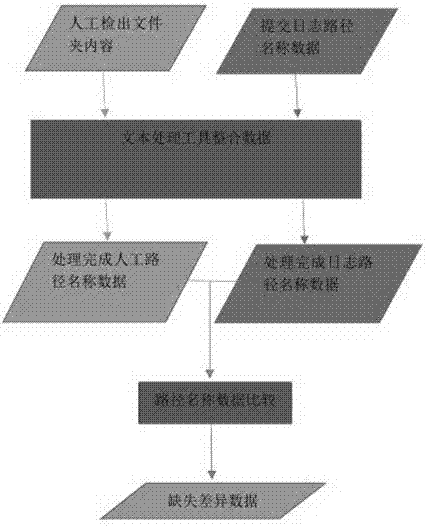
图2是本发明文本处理比较方法的具体操作流程图;
图3是本发明的用于文本处理比较的装置结构示意图。
具体实施方式
如图1所示,本发明的文本处理比较方法包括以下步骤:
(1)在搜索路径位置,填入文件夹路径,获取人工检出文件夹内所有的文件夹和文件的全路径和文件名称,并产生存储形成第一文本数据;
(2)获取提交日志信息,并将获取到的提交日志信息记录形成第二文本数据;
(3)比较第一文本数据与第二文本数据,核查是否有缺失差异内容;
(4)输出比对结果。
具体的操作流程如图2所示,针对人工检出文件夹内容、提交日志路径名称数据分别采用文本处理工具整合数据,形成处理完成人工路径名称数据的第一文本数据,以及处理完成日志路径名称数据的第二文本数据,再将二者进行路径名称数据比较,得出缺失差异数据结果。
另外,在所述步骤(1)中,填入文件夹路径后,点击搜索文本按钮,通过递归算法,获取人工检出文件夹内所有的文件夹和文件的全路径和文件名称,并产生存储于final.txt文本中形成第一文本数据。
在所述步骤(2)中,所获取的提交日志信息为svn版本提交日志信息,记录在svn.txt文件中,同时选择对应的版本信息,点击整理svn按钮,进行字符串分割处理及重排序,形成第二文本数据。
在所述步骤(2)中,所获取的提交日志信息来自于版本库,版本库提交日志因提交路径多文件多,通过正则表达算法,排除无用文件及重复文件记录,具体排除文件规则,要根据实际项目需求添加。
在所述步骤(3)中,根据所述第一文本数据中的人工路径名称数据,以及所述第二文本数据中的日志名称数据,进行比较,核查是否有缺失差异内容。
如图3所示,用于文本处理比较的装置,包括:
第一处理单元,用于存储将从搜索路径位置填入文件夹路径,获取到的人工检出文件夹内所有的文件夹和文件的全路径和文件名称,并产生存储形成第一文本数据;
第二处理单元,用于存储获取到的提交日志信息,并将获取到的提交日志信息记录形成第二文本数据;
比较单元,将第一文本数据中的每项文本数据信息与第二文本数据中的文本数据信息进行比较;
结果输出单元,输出差异信息并标记。
上面结合附图对本发明的实施方式作了详细的说明,但是本发明不限于上述实施方式,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!