一种基于动态规划方法实现数据去重装置及方法与流程
本发明涉及信息数据处理领域,具体涉及一种基于动态规划方法实现数据去重装置及方法。
背景技术:
客户资料、商家信息是企业决策的基础,如果企业对客户资料、商家信息掌握不全、不准,就会判断失误,决策就会出现偏差,同时,如果企业无法制定出正确的经营战略和策略,客户关系就会破裂,出现客户流失。所以,企业必须全面、准确、及时地掌握客户的信息,才能够有针对性地开展经营活动,从而使企业的营销成本降到最低。
客户资料、商家信息是各个公司核心数据,商家信息的数据质量对业务开展至关重要。
商家信息的来源很多,典型的包括采编维、外部数据获取、网络爬取等。正因如此,对于数据质量的把控难度较高。
典型的数据质量问题包括:数据不全、数据有误、数据重复等,其中,数据重复问题一直是困扰日常业务开张的因素之一。举例说明:“名典咖啡朱雀店”与“名典咖啡(朱雀大街店)”二者实为一家店面,但系统却存在不同的记录。
为了解决以上问题,本发明提出了一种基于动态规划方法实现数据去重装置及方法,借助智能的方法来排查这样的错误,从而有效地解放人工维护,可以大大提高数据稽核的效率,进而提升数据的质量。
技术实现要素:
本发明的目的是提供一种基于动态规划方法实现数据去重装置及方法,信息的相似度匹配方法很多,常见的有字符串拆分与匹配法、文本分词法等。但大部分对于海量数据处理都没有明显的优势,算法的效率与资源开销一直是阻碍方法普适性的关键。信息相似度匹配的基本思想是判别两项信息之间的重复程度,重复程度越高,则说明相似度越大,反之,表示越小。
本发明提供了如下方案:
一种基于动态规划方法实现数据去重装置,包括数据排序单元,数据分组单元,数据清洗单元,数据相似度分析单元,数据输出单元;数据排序单元用于将数据进行排序并传送给数据分组单元,数据分组单元用于对数据排序单元传送的数据分编成数据组,将数据组传送给数据清洗单元,数据清洗单元用于在数据组内提取source和traget进行清洗得到清洗后数据,将清洗后数据传送给数据相似度分析单元,数据相似度分析单元用于将清洗后数据进行相似度分析,经过多次数据清洗和相似度分析得到合格数据并发送给数据输出单元,数据输出单元将合格数据输出。
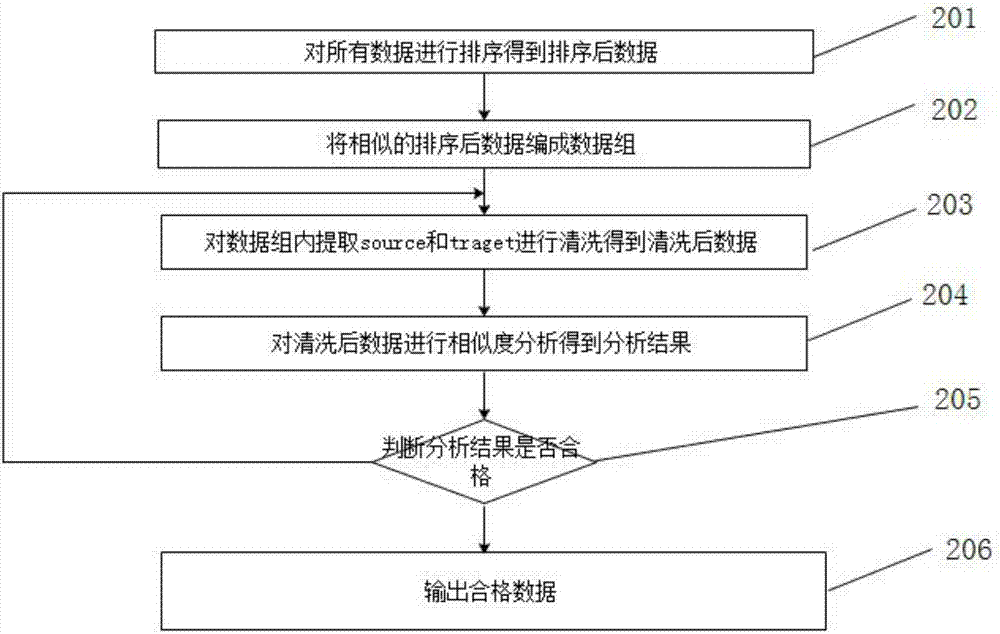
一种基于动态规划方法实现数据去重方法,包括步骤:
(1)对所有数据进行排序得到排序后数据;
(2)将相似的排序后数据编成数据组;
(3)对数据组内提取source和traget进行清洗得到清洗后数据;
(4)对清洗后数据进行相似度分析得到分析结果;
(5)判断分析结果是否合格,合格执行下一步,不合格执行步骤(3);
(6)输出合格数据。
进一步的,步骤(1)中所有数据为同一区域的所有数据。
进一步的,步骤(3)中对数据组内提取source和traget进行清洗得到清洗后数据,其过程如下,
a、将source和target以一个字符为单位进行拆分,放入数组source[]和target[];
b、判断source[1]和target[1],如果相同,不进行操作,不记录字符串相似度cost;如果不同,对source[]进行插入,替换或者删除操作,并记录字符串相似度cost;
c、判断source[2]和target[2],如果相同,不进行操作,不记录字符串相似度cost;如果不同,对source[]进行插入,替换或者删除操作,并记录字符串相似度cost;
d、重复c、d的步骤直至最后,输出source和target的字符串相似度cost。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明的一种基于动态规划方法实现数据去重装置及方法,大大降低人工匹配相似度信息,减少人工成本,提高工作效率,也保证数据质量准确性、一致性、标准性、完整性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种基于动态规划方法实现数据去重装置及方法的结构示意图;
图2为本发明一种基于动态规划方法实现数据去重装置及方法的流程图;
图中,1-数据排序单元,2-数据分组单元,3-数据清洗单元,4-数据相似度分析单元,5-数据输出单元。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于动态规划方法实现数据去重装置及方法,降低人工匹配相似度信息,减少人工成本,提高工作效率,也保证数据质量准确性、一致性、标准性、完整性。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例1:
一种基于动态规划方法实现数据去重装置,包括数据排序单元(1),数据分组单元(2),数据清洗单元(3),数据相似度分析单元(4),数据输出单元(5);数据排序单元(1)用于将数据进行排序并传送给数据分组单元(2),数据分组单元(2)用于对数据排序单元(1)传送的数据分编成数据组,将数据组传送给数据清洗单元(3),数据清洗单元(3)用于在数据组内提取source和traget进行清洗得到清洗后数据,将清洗后数据传送给数据相似度分析单元(4),数据相似度分析单元(4)用于将清洗后数据进行相似度分析,经过多次数据清洗和相似度分析得到合格数据并发送给数据输出单元(5),数据输出单元(5)将合格数据输出。
一种基于动态规划方法实现数据去重方法,包括步骤:
201、对所有数据进行排序得到排序后数据;
202、将相似的排序后数据编成数据组;
203、对数据组内提取source和traget进行清洗得到清洗后数据;
204、对清洗后数据进行相似度分析得到分析结果;
205、判断分析结果是否合格,合格执行下一步,不合格执行步骤(3);
206输出合格数据。
步骤201中所有数据为同一区域的所有数据。
步骤203中对数据组内提取source和traget进行清洗得到清洗后数据,其过程如下,
a、将source和target以一个字符为单位进行拆分,放入数组source[]和target[];
b、判断source[1]和target[1],如果相同,不进行操作,不记录字符串相似度cost;如果不同,对source[]进行插入,替换或者删除操作,并记录字符串相似度cost;
c、判断source[2]和target[2],如果相同,不进行操作,不记录字符串相似度cost;如果不同,对source[]进行插入,替换或者删除操作,并记录字符串相似度cost;
d、重复c、d的步骤直至最后,输出source和target的字符串相似度cost。
动态规划法-算法步骤与定义,具体步骤:
将同一区域的所有数据进行排序;
将相似的数据分成编成一组;
在组内提取source和target进行数据清洗;
清洗后的数据进行相似度分析,如果不合格再继续提取source和target进行数据清洗,直到数据相似度合格;
将结果进行重复判断,如果合格,输出结果,将这批数据剔除出来;如果不合格,此次操作无效;
假设
source=“招商银行之双榆树分行”;
target=“北京招商行双榆树路支行”。
len(source)=10;----source信息长度;
len(target)=11;---target信息长度;
source[i]---source信息子串,截取第1至第i个位置;
target[j]---target信息子串,截取第1至第j个位置;
d[i,j]=min(cost(source[i],target[j]))-信息串source[i]与信息串[j]之间的相似距离;
动态规划法-核心算法
具体步骤:
1、将source和target以一个字符为单位进行拆分,放入数组source[]和target[]
2、判断source[1]和target[1],如果相同,不进行操作,不记录字符串相似度cost;如果不同,对source[]进行插入,替换或者删除操作,并记录字符串相似度cost
3、判断source[2]和target[2],如果相同,不进行操作,不记录字符串相似度cost;如果不同,对source[]进行插入,替换或者删除操作,并记录字符串相似度cost
4、重复2、3的步骤直至最后,输出source和target的字符串相似度cost
动态规划法-示例演算
source=“招商银行之双榆树分行”;target=“北京招商银行双榆树路支行”。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!