基于网络权重初始和最终状态差异的冗余权重去除方法与流程
本发明涉及模式识别和人工智能技术领域,具体涉及深度神经网络的加速与压缩方面。
背景技术:
近年来,深度神经网络(deepneuralnetwork,dnn)在计算机视觉、语音识别以及自然语言处理等多个领域取得卓越成效,并得到广泛应用。研究表明,dnn在特征提取方面具有出色的表现,网络层越深,其网络的表征能力越强。然而,由于网络层数的加深需要更多计算能力和存储资源的开销,因此难以在存储和计算资源有限的硬件设备上进行部署,尤其是移动设备。
网络模型参数包括网络权重和偏置,目前使用的训练方法所得到的网络模型通常包含大量冗余的参数。如何有效地解决dnn网络参数的冗余问题,至今已有不少的研究,主要可以分为三类:第一类是使用网络权重的量化值或者近似值替代原有权重的方法,第二类是变换网络结构方法,如使用全局平均池化的网络层来替换全连接层以减少神经网络的参数数量,第三类是网络剪枝方法。
lecun等人于1990年在advancesinneuralinformationprocessingsystems会议上发表的论文《optimalbraindamage》和hassibi等人于1993年在portugueseconferenceonartificialintelligence会议上发表的《secondorderderivativesfornetworkpruning:optimalbrainsurgeon》,均提出通过使用二阶导数或者hessian矩阵的信息来权衡网络的复杂度和训练集的误差,然而,随着网络的大型化和复杂化,难以计算每一个参数在hessian矩阵中二阶导数。
1997年,castellano等人在期刊ieeetransactionsonneuralnetworks发表论文《aniterativepruningalgorithmforfeedforwardneuralnetworks》中提出了一种迭代剪枝方法,该方法选择对所有模式输出能量最小的隐节点作为删除节点。引人关注的是,2015年,han等人在advancesinneuralinformationprocessingsystems会议上发表论文《learningbothweightsandconnectionsforefficientneuralnetwork》中提出了根据网络中层与层神经元间连接的重要性决定是否去除神经元间的连接,并保证原有网络性能几乎不下降。然而,关于网络剪枝阈值的确定和重要连接参数的选取问题,han等人没有给出有效的解决方法。
技术实现要素:
本发明的目的在于克服现有网络剪枝方法在剪枝阈值的确定和重要连接权重的选取方面的不足,提出了一种新的有效网络剪枝阈值的确定和重要连接权重的选取的方法。
本发明基于网络权重初始和最终状态差异的冗余权重去除方法是一种基于网络权重的初始状态和最终状态差异的重要网络连接权重的选取和冗余权重的去除方法。
本发明的目的通过下述技术方案实现:
基于网络权重初始和最终状态差异的冗余权重去除方法,包括如下步骤:
步骤1、先在网络模型训练之前保存其初始状态的网络权重,在训练结束后保存其最终状态的网络权重,分别对每层网络权重的初始状态和最终状态的分布信息进行直方图统计并进行曲线拟合,分别得到每层初始网络权重直方图拟合曲线ql和最终网络权重直方图拟合曲线
步骤2、根据初始网络权重直方图拟合曲线ql和最终网络权重直方图拟合曲线
步骤3、分别计算差值曲线fl在正阈值区间
步骤4、按照斜率从大到小依次选取正候选集rl中的点,将该点对应的横坐标的值作为正阈值
步骤5、将最终网络模型的第l层位于区间
步骤6、重复步骤1‐步骤5的操作,选取除l外的其它网络层的网络剪枝区间
步骤7、将最终网络模型位于网络剪枝区间
步骤8、将得到的已剪枝的网络模型进行再训练,并保持已剪枝的网络权重在再训练的过程中始终为0,得到剪枝和再训练的网络模型;
步骤9、若剪枝和再训练的网络模型在测试数据集的准确度比最终网络模型的小于预设值,则停止操作,并保留剪枝和再训练的网络模型,否则,进行下一步操作;
步骤10、计算每层最终网络权重与初始网络权重变化幅度,通过比较网络权重变化幅度与
网络模型的初始状态表示网络模型首次在数据中训练的初始化状态,此时的网络模型命名为初始网络模型,该状态的网络权重是由相应的网络权重生成函数生成,并没有经过任何数据集训练学习的网络权重,而将初次训练结束后的网络模型命名为最终网络模型,最终状态的网络权重是经过在数据集训练中不断更新和调整生成的网络权重,其中,初始网络模型和最终网络模型的网络结构是相同,仅是层与层之间的连接参数是不同。
为进一步实现本发明目的,优选地,步骤1中,所述的网络模型为深度学习框架caffe中的lenet‐5网络模型。
优选地,步骤1中,所述的初始状态的网络权重是由相应的网络权重生成函数随机生成的值,表示在网络模型训练前网络权重的初始值。
优选地,步骤1中,所述的最终状态的网络权重是网络模型经过在数据集训练中不断更新和调整生成的网络权重;步骤5、步骤7和步骤9中,所述的最终网络模型是步骤1中训练结束后对应的网络模型,最终网络模型的网络权重是步骤1中的最终状态的网络权重。最终状态的网络权重与数据集中的信息有联系,主要体现在网络模型对数据的特征提取和分类能力。
优选地,步骤1中,所述的曲线拟合是在对每层网络权重的初始状态和最终状态的分布信息进行直方图统计基础上,利用核密度估计方法对直方图的轮廓进行拟合,得到相应的拟合曲线。
优选地,步骤8中,所述的再训练是对已在训练数据集中得到训练的网络模型进行再次训练,重新更新和调整网络模型中层与层之间连接,其中层与层之间连接的参数包含网络权重和网络偏置。
优选地,步骤8中,所述的保持已剪枝的网络权重在再训练的过程中始终为0是通过设置与第l层网络权重数量同样大小的网络权重去除标志符maskl实现,maskl是记录该层某个网络权重是否去除的标志位,通过与该层网络权重中的对应位置相乘,实现每层网络权重的去除。
优选地,步骤9中,所述的预设值的取值范围为[0.5%,2%]。优选预设值的取值1%。
优选地,步骤10中,所述的比较网络权重变化幅度与
(1)
(2)
(3)
(4)
优选地,步骤10中的权重变化幅度系数α的选取先设置α=mean(abs(w′l))/std(w′l),其中mean(abs(w′l))和std(w′l)分别表示该层最终网络权重绝对值的均值和权重的标准差,判断剪枝后网络是否达到预设标准,若是,则直接保存剪枝后的网络模型,否则,按照从1向0以步长β逐次递减的方式调整权重变化幅度系数α,直到剪枝后网络达到预设标准为止,其中步长β的取值范围为(0,1)。优选β的取值0.1。
本发明网络模型是深度神经网络模型,比传统神经网络更多层的神经网络模型,其主要由输入层、输出层、多个不同的隐藏层,以及层与层之间的连接组成,输入层是将数据的输入于网络模型,输出层是用于网络模型的运算结果输出,隐藏层是除输入层和输出层以外的其他网络层,不同类型的隐藏层对数据具有不同的运算功能,而层与层之间连接的参数包含网络权重和网络偏置,可知网络模型是由不同网络层组成的网络结构和层与层之间的连接参数构成。
本发明相对于现有网络剪枝技术具有如下的优点及效果:本发明创新性地利用网络权重的初始和最终状态的直方图差异进行网络剪枝阈值的确定,并在此基础上,提出以网络权重变化幅度大小的方式进行优化选取。本发明能够充分利用网络重要连接权重与其权重大小和权重变化幅度有关的性质,在基本保证网络原有准确度的条件下,实现网络重要连接权重的选取和冗余权重的去除,有利于后续深度神经神经网络的压缩和加速,解决深度学习网络对设备计算能力和存储要求较高、难以在存储和计算资源有限的硬件设备,尤其是移动设备上进行部署的问题。
附图说明
图1是本发明基于网络权重初始和最终状态差异的冗余权重去除方法的流程框图。
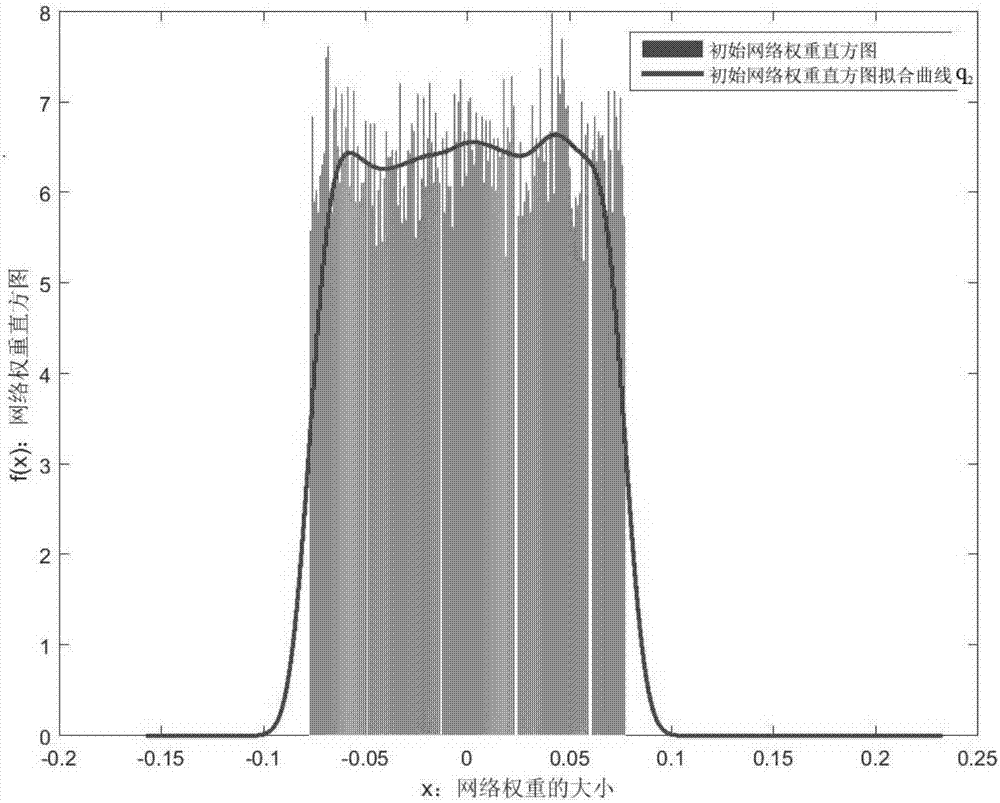
图2是lenet‐5初始网络在conv2层的网络权重直方图和其曲线拟和图。
图3是lenet‐5最终网络在conv2层的网络权重直方图和其曲线拟和图。
图4是lenet‐5初始和最终网络在conv2层的网络权重直方图曲线拟合图。
图5是lenet‐5初始和最终训练网络在conv2层的网络权重直方图的拟合曲线之间的差值曲线图。
具体实施方式
为更好地理解本发明,下面结合实施例及附图对本发明作进一步的描述,但本发明的实施方式不限于此。
下面以伯克利bvlc开发的深度学习框架caffe中的lenet‐5网络模型为实例进行详细的介绍和说明。lenet‐5网络模型是用于识别手写数字0到9的卷积神经网络,是早期卷积神经网络中最有代表性的网络模型之一,该网络模型在mnist数据集可达到99.20%准确度。lenet‐5网络模型共有7层(不包括输入层),每层都包含不同数量的网络连接参数。lenet‐5主要由2层卷积层、2层下抽样层、2层全连接层和1层输出层构成,其中只有卷积层和全连接层的连接参数需要在训练过程中更新和调整,其余的连接参数不需改变。网络模型中的2层卷积层的名字分别为conv1和conv2,它们的主要用于提取数据特征,卷积层conv1有20个卷积核,卷积层conv2有50个卷积核,它们每个卷积核的大小为5,滑动步长为1,网络权重的初始化方式为xavier。网络模型中的2层全连接层的名字分别为ip1和ip2,全连接层ip1有500个神经元,全连接层ip2有10个神经元,它们的网络权重初始化方式都设置为xavier,该网络权重的初始化方式生成的网络权重服从均匀分布。以上操作可直接通过深度学习框架caffe实现。
基于网络权重初始和最终状态差异的冗余权重去除方法,包括如下步骤:
本发明的具体实施流程框图如图1所示,第一步,先在lenet‐5网络模型的初次训练之前保存lenet‐5网络模型初始状态的网络模型,简称lenet‐5网络模型的初始网络模型。在初次训练结束后保存lenet‐5网络模型最终状态的网络模型,简称lenet‐5网络模型的最终网络模型。由于本发明是根据网络权重初始和最终状态的差异来去除冗余网络权重,因此初次训练主要是通过保存lenet‐5网络模型的初始网络模型和最终网络模型,来获得lenet‐5网络模型的初始和最终状态的网络权重,网络模型的初次训练可直接通过caffe实现。lenet‐5网络模型的初始状态网络权重是该网络模型首次在数据中训练时初始化状态的网络权重,该状态的网络权重是由网络权重初始方式xavier生成的,并没有经过任何数据集训练学习的。由于深度神经网络具有自动的学习能力,只需直接为其提供数据,让它自主去学习数据中的规律,具体就是利用附带正确标签的数据对其进行训练后,它们便可通过更新和调整层与层的每个连接来大幅改进效果,直到网络模型输出的预测结果尽可能与正确标签一致为止,因此lenet‐5网络模型的最终状态的网络权重是经过在mnist数据集训练中不断更新和调整生成的。其中lenet‐5的初始网络模型和最终网络模型的各个网络层都是一样的,仅是层与层之间的连接参数是不同的。
分别对lenet‐5网络模型中每层网络权重的初始状态和最终状态的分布信息进行直方图统计并进行曲线拟合。网络中的每层网络权重都是根据图1本实施例流程框图进行同样操作,因此下面只以lenet‐5网络模型中conv2层的网络权重为例进行详细的操作说明。conv2层是lenet‐5网络模型的第二层网络层,该层网络权重的初始化方式为xavier,即该层的初始网络权重的服从均匀分布,而该层的最终网络权重是网络模型经过充分训练和学习所得到的状态,conv2层的初始权重和最终权重的直方图分别如图2的最初网络权重的直方图和图3中的最终网络权重的直方图所示。通过分别对初始权重与最终权重的直方图进行曲线拟合,本实施例对权重直方图进行曲线拟合的方法是核密度估计,得到conv2层的初始权重的直方图拟合曲线q2与最终权重的直方图拟合曲线
第二步,根据lenet‐5网络模型每层网络权重的初始状态和最终状态直方图在不同权重大小范围的差异变化判断每层网络重要和不重要连接权重的分布范围,从而分别确定每层网络剪枝正阈值
第三步,计算每层网络权重的初始状态与最终状态直方图拟合曲线的差值曲线fl。其中,conv2层网络权重的初始状态拟合曲线q2与最终状态直方图拟合曲线
第四步,分别对每层网络权重的差值曲线fl在各自对应区间正阈值区间
第五步,按照斜率从大到小依次选取正候选集rl中的点对应横坐标的值作为网络剪枝正阈值
第六步,重复上述步骤1‐步骤5,依次确定其它网络层的网络剪枝区间
第七步,保证lenet‐5的最终网络模型中各层位于网络剪枝区间
算法1:基于阈值的网络剪枝和再训练
初始化:
masklk=0
else
masklk=1
endif
剪枝和再训练:
第八步,将已剪枝网络进行重新训练,具体操作如算法1剪枝和再训练部分所示,剪枝后网络再训练的学习率设置为原来学习率的1/10,其余网络参数保持不变。表1给出了lenet‐5网络模型经过剪枝后各层权重的变化结果,表1第一列和第二列的数据是网络模型本身已有确定的网络结构参数,第一列表示网络模型中各层网络层layer的名称,第二列表示每层网络权重的个数或整个网络权重的个数。第三、四列分别每层网络剪枝负阈值
表1lenet‐5网络模型基于算法1的剪枝后权重变化结果
第九步,将letnet‐5网络模型的最终网络模型和它的已经过剪枝和再训练的网络模型分别在mnist数据集中测试数据集上进行准确度测试,并比较两者所得的准确度。letnet‐5网络的已经过剪枝和再训练的网络模型是将它的最终网络模型通过剪枝和再训练操作得到网络模型,两者的网络结构是相同,但它们的网络连接参数是不同。网络模型的准确度是指网络模型对数据集样本的预测结果与实际结果相同的频率,如letnet‐5网络模型的最终模型对mnist数据集中测试数据的某一样本的内容信息进行预测,判断其预测结果与样本的实际结果是否相同并统计相同的频率。当完成对测试数据的所有样本的测试后,最终得到网络模型的准确度。该过程的操作和结果可直接通过深度学习框架caffe完成和得到,具体结果如表2所示。由表2可知,剪枝再训练的letnet‐5网络模型在mnist数据集上的准确度可达99.28%,比最终网络模型的99.22%提高了0.06个百分点,表明该网络模型可在基本保持原有网络准确度条件下,实现去除网络冗余权重的效果,因此停止操作并保留该网络模型。
当剪枝和再训练后的网络模型的准确度比最终网络准确度下降超过预设值以上时,其中本实例的预设值设置为1%,本实施例进一步根据网络权重变化幅度大小优化重要连接权重的取舍,继续执行下一步操作。
表2lenet‐5基于算法1最终网络模型和剪枝再训练的网络准确度对比
第十步,计算每层网络的最终网络权重与初始网络权重之间的变化幅度,通过比较网络权重变化幅度与
算法2初始化步骤中,情况1表示当w′lk小于
本实施例通常首先设置α=mean(abs(w′l))/std(w′l),其中mean(abs(w′l))和std(w′l)分别表示该层最终网络权重绝对值的均值和权重的标准差,判断剪枝后网络是否基本保持最终网络准确度,若是,则直接保存剪枝后的模型,否则,按照从1向0以β=0.1的步长逐次递减的方式调整α。当α=1时,算法2等价于算法1,当α=0时,算法2不对网络进行剪枝操作。已剪枝网络进行重新训练的具体操作与第八步叙述算法1剪枝和再训练部分相同。
算法2:基于阈值和权值变化幅度的网络剪枝和再训练
初始化:casew′lkof
case1:
masklk=1
case2:
masklk=1
case3:
masklk=1
case4:
masklk=1
case5:
masklk=1
else
masklk=0
end
剪枝和再训练:
- 还没有人留言评论。精彩留言会获得点赞!