一种多任务卡口车辆以图搜图的系统及方法与流程
本发明涉及智慧交通领域,尤其涉及一种多任务卡口车辆以图搜图的系统及方法。
背景技术:
随着社会发展,智能交通领域中智能交通监控是当前非常重要的一个发展方向,目前我国已在城市道路上部署了大规模数量的电子警察和卡口系统。这些系统能够实时捕获车辆高清图片,并且识别分析出车牌号码,以及一部分车型信息(如车辆大小,颜色等)。但目前使用的卡口监控系统,车牌号码识别仍有10%左右的误识别、漏识别率。更重要的是,对于套牌车或故意遮掩拍照的违法车将无法进行识别。因此,通过车牌号码之外的车辆特征信息作为一个新的识别条件,从而在现有的交通监控系统找出这部分违法车辆。另一方面,一个城市中的所存储的卡口车辆图片往往数量在亿级以上,即使将图片成功转化成为特征向量,要快速精确的查询搜索相关特征依然是一大难点。因此本专利的研究这在现今的在现代交通监控和管理中有非常重要的研究意义和应用前景。
《一种基于多特征深度学习的车辆检测方法及装置》,申请号为201610952774.3中将车辆灰度信息,边缘检测信息作为特征进行训练来定位车辆,过程较为繁琐。并且利用三个不同方面的信息来进行定位,并没有全面包含车辆的信息。
《基于大数据的车辆检索及装置》,申请号为201610711333.4中利用多个特征标志区域进行级联检索,然而只有多个局部特征,没有全局的特征信息,并且流程较繁琐。《一种卡口车辆检索方法及其系统》,申请号为201610119765.6中采用各特征模块利用深度学习提取特征做相似度对比,包括你车牌号码,车标车型,车身颜色,年检标等,车牌号码不足以识别车牌遮挡的车辆,并且需要训练多个网络,也不具有全局特征。
《基于深度学习的车型识别模型构建方法及车型识别方法》,申请号为201610962720.5中利用深度学习进行车型识别,没有达到细粒度检索车辆的程度,不够精准。
技术实现要素:
本发明为克服上述的不足之处,目的在于提供一种多任务卡口车辆以图搜图的系统及方法,本发明利用深度神经网络建立多任务定位和多任务特征提取网络,分别定位和特征检测卡口车辆图像中的车辆、年检标和车灯三个部位,结合了全局和局部特征,损失函数采用softmax损失和三元组损失函数的损失函数来训练网络,最终加权结合局部特征向量和利用神经网络最后一层全连接层的全局特征向量作为车辆特征进行检索,检索采用改进的k-means算法找出K类,然后利用SVM形成哈希函数来进行汉明码编码,提高了检索速度,节省存储空间。
本发明是通过以下技术方案达到上述目的:一种多任务卡口车辆以图搜图的方法,包括如下步骤:
(1)获取卡口车辆图片后对图片进行处理与分类,并对卡口车辆图片集进行优化处理得到数据集;
(2)构建并训练获得基于深度神经网络模型的多任务定位网络,提取车辆图片中车辆、年检标、车灯和背景的位置区域信息;构建并训练获得基于深度神经网络模型的多任务特征提取网络,提取车辆、年检标、车灯位置区域的图像特征,获得车辆特征;
(3)基于车辆特征建立车辆特征的k-means聚类;
(4)利用K个二分类SVM训练哈希函数,提取样本特征码后放入哈希桶中;
(5)检索时将提取得到的待检测图片的车辆图片全局特征通过哈希函数转化为特征码,找到该特征码所对应的哈希桶并进行计算与排序,输出所对应的相似卡口图片。
作为优选,所述步骤(1)包括如下步骤:
(1.1)对获取到的卡口车辆图片人工标注车辆、车辆年检标、车灯位置的区域坐标信息和类别;
(1.2)分别截取卡口图片中的车辆、年检标、车灯位置区域;
(1.3)将不同时间和地点的截取区域按照车牌进行分类得到数据集;(1.4)对卡口车辆图片进行添加噪声样本完成数据集的优化。
作为优选,所述多任务定位网络的训练步骤如下:
(i)将标注好的卡口图片分为车辆、年检标、车灯和背景四类,作为训练集;
(ii)基于训练集,使用深度神经网络提取特征,得到特征层;
(iii)采用固定分割窗口策略对特征层进行分割,完成候选框的提取,具体如下;
(iii.1)选取三个尺寸进行分割,分别按照2*2,3*3,5*5三个不同尺寸进行分割;
(iii.2)每个方格进行不同的长宽比变换进行尺度变换,长宽比分别为1:1、2:1、1:2三种不同的长宽比,则单个样本产生的候选框个数为(2*2+3*3+5*5+7*7)*5,即114个特征层候选框;
(iii.3)采用非极大抑制来融合上述候选框,消除候选框的重叠区域;
(iv)计算候选框的位置损失和类别损失,并按照1:1作为损失函数;(v)反复迭代循环训练网络至损失值不再减小为止,得到训练完后的多任务定位网络。
作为优选,所述步骤(iv)具体如下:
1)采用级联函数计算位置损失:
定位的原理是寻找预估目标和真实目标框之间的回归函数,其中i表示特征向量,记回归函数分别为fx(i),、fy(i)、fw(i)、fh(i),x、y、w、h表示盒子的中心坐标和宽高,x,xe,xt分别表示候选框,预测框和真实标定框的中心点x的坐标;
估计目标与真实目标之间的变换关系如下所示:
xt=w。fx(i)+xe
yt=wefy(i)+ye
则估计与真实目标的回归函数为:
同理滑窗和估计目标的回归函数为:
第一个回归损失函数:
其中M为:
另外计算真实目标与估计目标的损失,则第二个损失函数:
2)计算类别损失:
对于所有筛选框进行标定,当一个候选框完全包含标定区域且不属于标定区域的部分不超过候选框区域的5%时认为该候选框标定结果为目标类,否则为背景类,将所有候选框预测的类别作为softmax层的分类标签与真实标签进行对比;
softmax损失函数如下:
其中N表示样本个数,xi表示第i个样本,yi表示第i个样本的正确标签,f(xi)yi表示第i个样本的结果的第yi个输出,f(xi)j表示第i个样本的第j个节点的输出;
3)则总的损失函数为
作为优选,所述多任务特征提取网络的训练步骤如下:
(I)将卡口车辆数据集、年检标数据集、车灯数据集分别利用车牌进行分类;
(II)将三类数据集作为三个输入集同时放入深度神经网络;
(III)分别计算三个输入的softmax和三元组损失函数:
筛选三元组样本集:每个三元组数据集包括三个样本,分别为目标样本anchor,正样本pos,负样本neg,其中anchor和pos为同一类,anchor和neg为不同类,挑选原则为与目标样本相差大的同类样本和与目标样本相差小的不同类样本的组合,学习过程是使得尽可能多的三元组anchor和pos的距离小于anchor和neg的距离,距离均使用余弦距离:
cosineap+α<cosinean
其中,表示目标样本,表示正样本,表示负样本,目标cosineap表示目标样本和正样本之间的余弦距离,cosinean表示目标样本和负样本之间的余弦距离,α为一个正数,保证正样本与目标样本之间的距离小于负样本与目标样本之间的距离的一个常数;
三元组损失函数如下所示:
分别表示样本经过网络的输出编码;
softmax损失函数为
则总的损失函数为:
L=Lt+Ls;
(IV)反复迭代循环训练网络至损失值不再减小为止,得到训练完后的多任务特征提取网络。
作为优选,所述步骤(2)提取车辆特征具体为:将待检索图片输入训练好的多任务定位网络,得到卡口车辆,年检标和车灯三个位置的坐标信息;并将定位出的三个位置截取出来输入多任务特征提取网络,分别提取出三个位置的特征向量,得到三个1000*1维的特征向量,存储作为该车辆的特征集。
作为优选,所述步骤(3)的具体步骤如下:
(3.1)随机选择K个质心点;
(3.2)采用余弦相似度计算每个特征量到K个质心点的距离,将其指派到距离最近的质心,形成K个类别簇;余弦相似度计算如下所示:
其中,Xi代表特征X中的第i个值,Yi代表特征Y中的第i个值;(3.3)计算每个簇的中心点作为新的质心;
(3.4)循环执行步骤(3.2)与(3.3),直到所有簇心的余弦相似度和小于I时停止循环,I为预设的阈值;某簇心的余弦相似度计算公式如下:
(3.5)若属于一个簇的特征总数大于N个时,对这个簇的数据执行步骤(3.1)-(3.4),直到每一个最底部的子簇内部的特征数都小于等于N。
作为优选,所述步骤(4)的具体步骤如下:
(4.1)将k-means聚类后的数据按聚类分为k类;
(4.2)k类样本集分别记为{X1,X2,…,Xk},取其中一个样本集Xi作为正样本,其余{X1,X2,…,Xi-1,Xi+1,…,Xk}集合作为负样本;
(4.3)将正负样本作为线性二分类的SVM分类器的正负样本进行训练,正样本Xi的标签为1,负样本标签为为0,得到该样本的分类权值矩阵Wi;
(4.4)依次将k类样本中每类样本集作为正样本,其余剩余的作为负样本,训练k个二分类SVM分类器,权值矩阵分别为W1,W2,…,Wk;(4.5)将W1,W2,…,Wk组成权值矩阵[W1W2…Wk]作为用来生成编码的矩阵函数,即哈希函数;
(4.6)将所有车辆样本的全局特征值按照行进行排列,如下所示:
(4.7)求解样本全局特征矩阵和哈希函数矩阵的内积来生成车辆样本的二进制特征编码,如下所示:
其中,哈希编码每行都是K位二值数,由此,m个样本都转化为哈希码;
(4.8)将样本哈希码记为H1,H2,…,Hm,利用K-mean将特征码按照距离聚类为M类,然后按照聚类结果直接划分为M段,每段为一个哈希桶;并将样本特征码分散放入哈希桶中。
作为优选,所述步骤(5)具体如下:
(5.1)将提取到的车辆特征通过哈希函数转化为汉明特征码,并找出该特征码所属的哈希桶;
(5.2)将该特征码与该哈希桶下的所有特征进行余弦相似度计算,并按距离从小到大对特征进行排序,选取前100个进行下一步筛选;(5.3)计算待检索卡口车辆图片的全部特征向量与该100个车辆的全部特征向量的加权距离,并按距离从小到大对特征进行排序;加权距离计算公式如下:
0.8cosine(x1,ci1)+0.1cosine(x2,ci2)+0.1cosine(x3,ci3) (0≤i≤99)
其中x1是指全局特征码,x2,x3指的是卡口车辆的全局特征,年检标特征和车灯特征,ci1,ci2,ci3分别指的是第i个检索库中卡口车辆图片的全局特征码,年检标特征和车灯特征;
(5.4)根据排序完的特征顺序,输出特征所对应的卡口图片。
一种多任务卡口车辆以图搜图的系统,包括:特征区域定位模块、特征提取模块、图片索引模块和图片上传模块,特征区域定位模块、特征提取模块、图片索引模块、图片上传模块依次连接;
其中特征区域定位模块和特征提取模块都包括卡口车辆,车年检标和车前灯三个部位的处理;提取出来的三个部分的特征向量组合作为卡口车辆的特征向量,经过PCA降维后,再经过改进的加权K-means检索算法进行检索,最终将检索到的相似车辆上传。
本发明的有益效果在于:(1)深度神经网络的语义表现能力强,本发明通过深度神经网络提取的全局能够很好的诠释目标车辆的整体特性;(2)建立基于深度神经网络的多任务定位网络进行车辆,年检标,车灯三个区域的定位,建立基于深度神经网络的多任务特征检测网络分别检测同时检测车辆,车年检标和车灯三个区域的特征向量;基于改进的边缘盒检测技术以及级联损失函数的方式来训练网络建立,方法简单;(3)采用softmax损失和三元组损失函数共同作为深度神经网络的损失函数,相较于传统的只有单一损失函数的训练机制,本方法有利于区分不同类间大的差别和细微的差别;(4)采用车年检标和车灯两个具有车辆特征代表性的部位进行局部特征提取,相较于传统的单一利用局部特征或者全局特征进行检索的方法,精确性更好;(5)利用基于k-means的算法,优化了样本分类;(6)利用基于二分类SVM算法形成哈希函数进行检索,加快了检索速度,减少存储所需内存。
附图说明
图1是本发明系统结构示意图;
图2是本发明方法的训练网络流程示意图;
图3是本发明方法的车辆特征提取流程示意图;
图4是本发明的建立车辆特征的k-means聚类流程图;
图5是本发明方法的特征码生成流程示意图。
具体实施方式
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
实施例:如图1所示,一种多任务卡口车辆以图搜图的系统,主要包括四个模块,分别是定位模块,特征提取模块,索引模块和图片上传模块,其中定位模块和特征提取模块都包括卡口车辆,车年检标和车前灯三个部位的处理。提取出来的三个部分的特征向量组合作为卡口车辆的特征向量,经过PCA降维后,再经过改进的加权K-means检索算法进行检索,最终将检索到的相似车辆上传。
一种多任务卡口车辆以图搜图的方法,包括如下步骤:
步骤1、数据集准备:
(1)车辆图片人工标注车辆,车年检标,车灯位置的区域坐标信息和类别;
(2)分别截取卡口图片中的车辆、年检标、车灯位置区域;
(3)将不同时间和地点的截取区域按照车牌进行分类;
(4)对图片进行添加噪声样本优化样本集。
步骤2、训练网络:
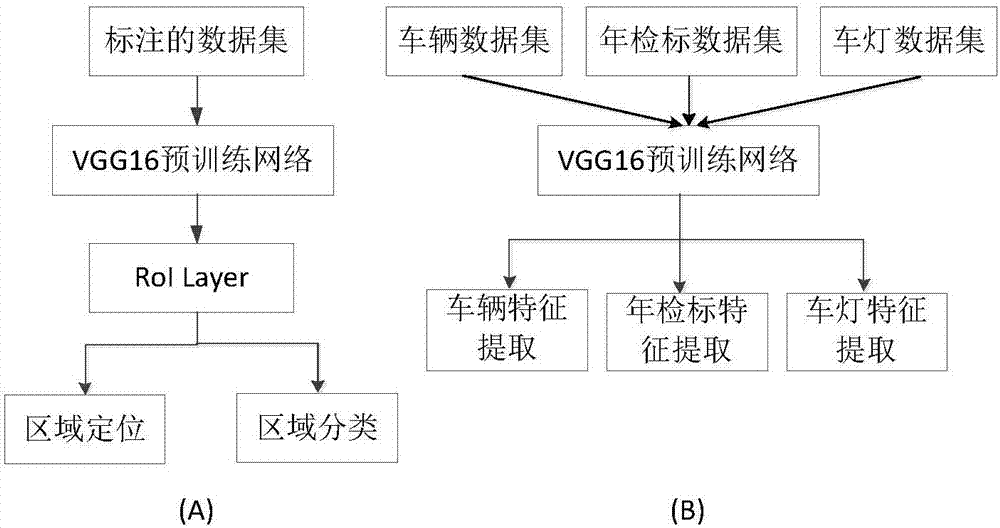
训练的网络分为两个部分,如图2的(A)和(B)所示,分别为多任务定位网络的训练和多任务特征提取网络的训练;两个多任务网络是基于深度神经网络的,深度神经网络有Alexnet网络,vgg网络,GoogleNet网络等,
进一步地举例:两个多任务网络都是基于vgg16的,定位网络利用vgg16在imagenet数据集上的预训练模型的前13个卷积层和四个池化层的权值参数直接调用,然后加上RoI(region of ineterst)层,RoI主要用于产生与图片中的区域块对应的特征层,两个全连接层和定位层(全连接层加Regression Loss层,用于产生区域坐标)加分类层(全连接层加SoftmaxLoss层,用于标识区域类别);特征提取网络基于vgg16在imagenet数据集上的预训练模型的前13个卷积层和五个池化层以及前两个全连接层的的权值参数直接调用,后面分别有三个分类层(全连接层加SoftmaxLoss层)来分别实现卡口车辆,卡口车辆年检标,卡口车辆前车灯的特征提取。关于vgg16网络的结构如表1所示:
表1
其中,多任务定位网络的训练过程如下,这里采用传统的vgg深度学习网络和基于改进的边缘盒检测技术以及级联损失函数的方式来训练网络:
步骤2.1.1将标注好得卡口部分区域分为四类,分别是卡口车辆,年检标,车灯和背景四类;
步骤2.1.2训练集使用vgg16的前14层(前13个卷积层和fc1层)提取特征,得到特征层;
步骤2.1.3提取候选框,对特征层进行分割,将原来的滑动窗口策略改为固定分割窗口策略,提高速率。
(1)选取三个尺寸进行分割,分别按照2*2,3*3,5*5三个不同尺寸进行分割;
(2)每个方格进行不同的长宽比变换进行尺度变换,长宽比分别为1:1、2:1、1:2三种不同的长宽比,则单个样本产生的候选框个数为(2*2+3*3+5*5+7*7)*5,即114个特征层候选框;
(3)候选框可能有重叠区域,因此采用非极大抑制来融合上述候选框;
步骤2.1.4计算候选框的位置损失和类别损失按照1:1作为损失函数。
计算位置损失采用级联函数计算位置损失:
(1)最终的定位是寻找预估目标和真实目标框之间的回归函数,其中i表示特征向量,记回归函数分别为fx(i),fy(i),fw(i),fh(i),x,y,w,h表示盒子的中心坐标和宽高,x,xe,xt分别表示候选框,预测框和真实标定框的中心点x的坐标,其他三个值也一样。
估计目标与真实目标之间的变换关系:
xt=wefx(i)+xe (1)
yt=wefy(i)+ye (2)
则估计与真实目标的回归函数为:
同样滑窗和估计目标的回归函数为:
第一个回归损失函数:
其中M为:
另外计算真实目标与估计目标的损失,则第二个损失函数:
计算类别损失过程如下:
对于所有筛选框进行标定,当一个候选框完全包含标定区域且不属于标定区域的部分不超过候选框区域的5%时认为该候选框标定结果为目标类,否则为背景类,将所有候选框预测的类别作为softmax层的分类标签与真实标签进行对比。
softmax损失函数:
公式(10)中N表示样本个数,xi表示第i个样本,yi表示第i个样本的正确标签,f(xi)yi表示第i个样本的结果的第yi个输出,f(xi)j表示第i个样本的第j个节点的输出。
则总的损失函数为
步骤2.1.5反复迭代循环训练网络至损失值不再减小为止,将训练完后的网络模型保存起来。
多任务特征提取网络的训练过程如下:
步骤2.2.1将卡口车辆数据集,年检标数据集,车灯数据集分别利用车牌进行分类;
步骤2.2.2将三类数据集作为三个输入集同时放入网络;
步骤2.2.3分别计算三个输入的softmax和三元组损失函数;
筛选三元组样本集:每个三元组数据集包括三个样本,分别为anchor(目标样本),pos(正样本),neg(负样本),其中anchor和pos为同一类,anchor和neg为不同类,挑选原则为与目标样本相差较大的同类样本和与目标样本相差较小的不同类样本的组合,学习过程是使得尽可能多的三元组anchor和pos的距离小于anchor和neg的距离,在这里距离均使用余弦距离。
cosineap+α<cosinean (14)
如上所示公式,表示目标样本,表示正样本,表示负样本,目标cosineap表示目标样本和正样本之间的余弦距离,cosinean表示目标样本和负样本之间的余弦距离,α为一个正数,保证正样本与目标样本之间的距离要小于负样本与目标样本之间的距离的一个常数。
三元组损失函数:
公式(4)中分别表示样本经过网络的输出编码。
softmax损失函数如公式(10)所示你,为Ls。
则总的损失函数为:
L=Lt+Ls (16)
步骤2.2.4反复迭代循环训练网络至损失值不再减小为止,将训练完后的网络模型保存起来。
步骤3、特征提取,如图3所示,流程具体如下:
步骤3.1将待检索图片输入训练好的定位和分类网络,得到卡口车辆,年检标和车灯三个位置的坐标信息。
步骤3.2将定位出的三个位置截取出来输入特征提取网络分别提取出三个位置的特征向量,得到三个1000*1维的特征向量,和其类型(车辆,年检标或者车灯)一起存储起来作为该车辆的特征集。
步骤4、建立车辆特征的k-means聚类,流程如图4所示:
步骤4.1随机选择K个质心点。
步骤4.2采用余弦相似度计算每个特征量到K个质心点的距离,将其指派到距离最近的质心,形成K个类别簇。
余弦相似度计算如上所示。Xi代表特征X中的第i个值,Yi代表特征Y中的第i个值。
步骤4.3计算每个簇的中心点作为新的质心。
步骤4.4循环执行4.2,4.3步,直到所有簇心的余弦相似度和小于I时,停止循环。某簇心余弦相似度计算公式如下:
步骤4.5若属于一个簇的特征总数大于N个时,对这个簇的数据执行4.1-4.4步。
步骤4.6重复执行4.5步,直到每一个最底部的子簇内部的图片特征数都小于等于N。
步骤5、利用K个二分类SVM训练哈希函数,提取特征码,具体流程如图5所示:
SVM,支持向量机,线性二分类SVM通过分离超平面把原始样本集划分成两部分,训练SVM的过程就是寻找分类超平面的过程。
步骤5.1将k-means聚类后的数据按聚类分为k类。
步骤5.2k类样本集分别记为{X1,X2,…,Xk},取其中一个样本集Xi作为正样本,其余{X1,X2,…,Xi-1,Xi+1,…,Xk}集合作为负样本。
步骤5.3将正负样本作为线性二分类的SVM分类器的正负样本进行训练,正样本Xi的标签为1,负样本标签为为0,得到该样本的分类权值矩阵Wi。
步骤5.4依次将k类样本中每类样本集作为正样本,其余剩余的作为负样本,训练k个二分类SVM分类器,权值矩阵分别为W1,W2,…,Wk。
步骤5.5将W1,W2,…,Wk组成权值矩阵[W1W2…Wk]作为用来生成编码的矩阵函数,即哈希函数。
步骤5.6将所有车辆样本的全局特征值按照行进行排列。
步骤5.7求解样本全局特征矩阵和哈希函数矩阵的内积来生成车辆样本的二进制特征编码。
其中,哈希编码每行都是K位二值数,由此,m个样本都转化为哈希码。
步骤5.8将样本特征编码按照距离均匀划分为M段,每段为一个哈希桶。
将样本哈希码记为H1,H2,…,Hm,利用K-mean计算距离直接划分为M段。
步骤5.9将样本特征码分散放入哈希桶中。
步骤6、检索阶段:
步骤6.1将提取到的车辆特征通过哈希函数转化为汉明特征码。找出该特征码所属的哈希桶。
步骤6.2将该特征与节点下的所有特征进行余弦相似度计算,按距离从小到大对特征进行排序,选取前100个进行下一步筛选。
步骤6.3计算带检索卡口车辆全部特征向量与该100个车辆的全部特征向量的加权距离:
0.8cosine(x1,ci1)+0.1cosine(x2,ci2)+0.1cosine(x3,ci2)(0≤i≤99) (19)
其中x1是指全局特征码,x2,x3指的是卡口车辆的全局特征,年检标特征和车灯特征,ci1,ci2,ci3分别指的是第i个检索库中卡口车辆图片的全局特征码,年检标特征和车灯特征。按距离从小到大对特征进行排序。
步骤6.4根据排序完的特征,输出特征所对应的卡口图片。
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!