实体描述型标签挖掘方法、装置及终端设备与流程
本发明涉及计算机技术领域,尤其涉及一种实体描述型标签挖掘方法、装置及终端设备。
背景技术:
实体描述型标签是指刻画实体特性的、语义明确的词组序列。实体描述型标签挖掘,旨在从海量互联网文本中通过信息抽取技术挖掘高置信度的实体描述型标签数据。
目前的实体描述型标签挖掘方法多是通过结构化抽取的方式,对网页结构化数据进行类型抽取,以生成该结构化网页所属领域的描述型标签。这种方式,只适用于特殊领域、且标签维度单一。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本发明提出一种实体描述型标签挖掘方法,实现了从多维度对各个领域的实体描述性标签进行挖掘,提高了实体描述型标签挖掘领域的覆盖度及挖掘结果的准确性。
本发明还提出一种实体描述型标签挖掘装置。
本发明还提出一种终端设备。
本发明还提出一种计算机可读存储介质。
本发明第一方面实施例提出了一种实体描述型标签挖掘方法,包括:获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版;利用所述各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集;对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,其中,第二数据源的数据量,大于所述第一数据源的数据量;根据所述第二数据源中各数据,与所述各领域的第一描述型标签集中各描述型标签的匹配度,确定所述第二数据源中包括的第二描述型标签集;根据所述实体集中的各实体,与所述第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。
本发明实施例的实体描述型标签挖掘方法,在获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版后,首先利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集,然后对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,再根据第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签集,最后根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。由此,实现了从多维度对各个领域的实体描述性标签进行挖掘,提高了实体描述型标签挖掘领域的覆盖度及挖掘结果的准确性。
本发明第二方面实施例提出了一种实体描述型标签挖掘装置,包括:获取模块,用于获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版;第一处理模块,用于利用所述各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集;第二处理模块,用于对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,其中,第二数据源的数据量,大于所述第一数据源的数据量;第一确定模块,用于根据所述第二数据源中各数据,与所述各领域的第一描述型标签集中各描述型标签的匹配度,确定所述第二数据源中包括的第二描述型标签集;第二确定模块,用于根据所述实体集中的各实体,与所述第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。
本发明实施例的实体描述型标签挖掘装置,在获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版后,首先利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集,然后对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,再根据第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签集,最后根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。由此,实现了从多维度对各个领域的实体描述性标签进行挖掘,提高了实体描述型标签挖掘领域的覆盖度及挖掘结果的准确性。
本发明第三方面实施例提出了一种终端设备,包括:
存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如第一方面所述的实体描述型标签挖掘方法。
本发明第四方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,当所述程序被处理器执行时实现如第一方面所述的实体描述型标签挖掘方法。
附图说明
本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明一个实施例的实体描述型标签挖掘方法的流程图;
图1A是本发明一个实施例的确定各领域的第一描述型标签集的示例图;
图2是本发明另一个实施例的实体描述型标签挖掘方法的流程图;
图2A是本发明一个实施例的实体描述型标签挖掘系统的框架图;
图3是本发明一个实施例的实体描述型标签挖掘装置的结构示意图;
图4是本发明另一个实施例的实体描述型标签挖掘装置的结构示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
具体的,本发明各实施例针对目前的实体描述型标签挖掘方法,多是通过结构化抽取的方式,对网页结构化数据进行类型抽取,以生成该结构化网页所属领域的描述型标签,这种方式,只适用于特殊领域、且标签维度单一的问题,提出一种从多维度对各个领域的实体描述性标签进行挖掘的实体描述型标签挖掘方法。
图1是本发明一个实施例的实体描述型标签挖掘方法的流程图。
如图1所示,该实体描述型标签挖掘方法包括:
步骤101,获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版。
其中,本发明实施例提供的实体描述型标签挖掘方法的执行主体,为本发明实施例提供的实体描述型标签挖掘装置,该装置可以被配置在任何终端设备中,以进行实体描述型标签的挖掘。
其中,各领域分别对应的核心词组,包括各领域分别对应的一个或多个核心词。比如,电影领域对应的核心词组可以包括“寻龙诀”、“惊悚”、“爱情”、等等核心词;旅游领域对应的核心词组可以包括“景点”、“门票”、“车票”、“旅馆”等等核心词。
第一句法依存模板,可以通过分析语言单位内成分之间的依存关系揭示其句法结构。其中,第一句法依存模板可以为以下模板中的一个或多个:主谓关系(subject-verb,简称SBV)模板、动宾关系(verb-object,简称VOB)模板、定中关系(attribute,简称ATT)模板、“的”(DE)字模板、并列关系(coordinate,简称COO)模板等等。
具体的,可以通过计算机设备或人工等任意方式,对各领域的数据源进行统计,以确定各领域分别对应的核心词组及各核心词分别对应的第一句法依存模板。
步骤102,利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集。
其中,第一数据源中包括各领域的数据,具体的,可以包括用户的检索日志及网页标题。比如,“北京适合情侣逛的景点有哪些”、“北京适合新手的滑雪场有哪些”、“与盗墓有关的小说有哪些”等等。
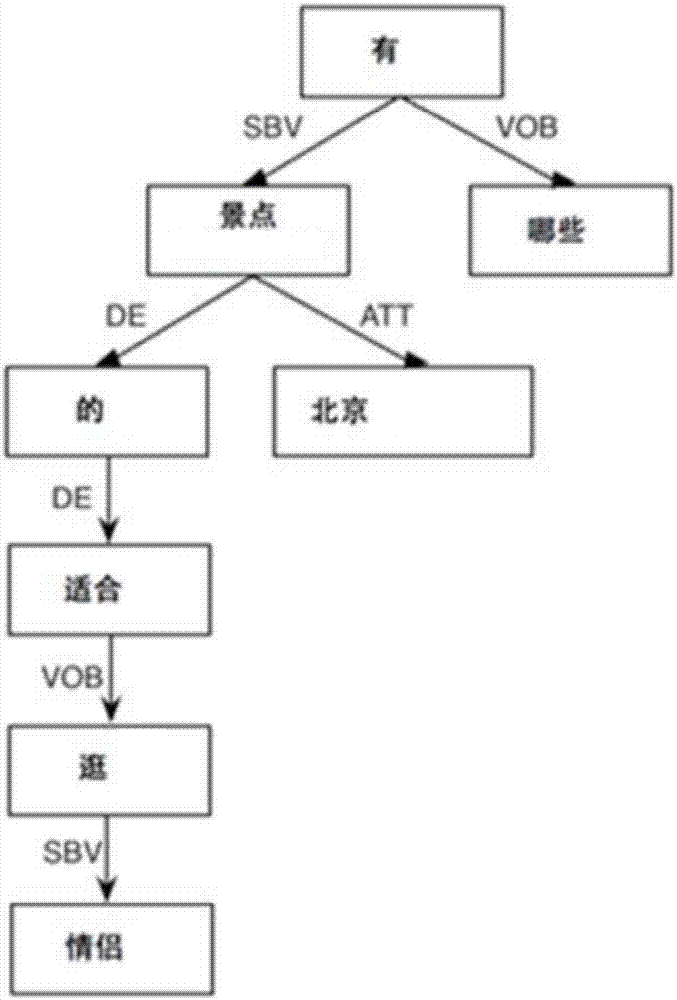
举例来说,假设利用旅游领域的核心词“景点”及第一句法依存模板,对第一数据源中的“北京适合情侣逛的景点有哪些”进行匹配处理,如图1A所示,可以确定旅游领域的一个描述型标签“适合情侣逛”。类似的,通过利用影视领域的核心词“电影”及第一句法依存模板,对第一数据源中的“最近适合儿童看的电影有哪些”进行匹配处理,可以确定电影领域的一个描述型标签“适合儿童看”。
步骤103,对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,其中,第二数据源的数据量,大于第一数据源的数据量。
其中,第二数据源中可以包括网页数据库。
具体的,可以通过实体链指技术(主要特征为实体热度特征、实体类别先验概率特征等),确定第二数据源中包括的实体集。
在一种可能的实现形式中,在对第二数据源中的各数据进行识别处理之前,还可以对第二数据源中的各数据进行预处理,以生成待识别数据,从而可以对待识别数据进行识别处理,确定第二数据源中包括的实体集。即,在步骤103之前,还可以包括:
将第二数据源中的各数据进行文本分割、噪音过滤处理,生成待识别的数据。
可以理解的是,第二数据源中的各数据为页面级别的数据,在本发明实施例中,可以将超文本标记语言(html)格式的网页解析为句子集合,从而将页面级别的各数据分割成句子级别的数据,同时可以过滤掉噪音节点、例如注释节点、样式节点、脚本节点、以及边框中的节点,进而生成待识别的数据。
具体的,文本分割主要是根据文件对象模型(DocumentObjectModel,简称dom)节点信息和文本中的标点符号。其中,dom节点表示节点前后内容关联性较弱,例如dom节点可以是用于切分的div、br、p等元素。标点符号主要指标明句子结尾的标点,例如句号、问好、叹号等。
文本过滤主要会进行站点级别(基于站点价值)、统一资源定位符(Uniform Resource Locator,简称url)级别(基于页面分类等)、文本级别(基于关键词、文本长度、文本质量等)的层层过滤。
需要说明的是,网页数据库中,可能存在单句不完备的网页类型,例如,问答网站中,实体多出现在问题中,描述型标签多出现在答案中。为此,在本发明实施例中,还可以对网页的标题和正文进行拼接处理,以提高确定第二数据源中包括的实体集时的召回率。
步骤104,根据第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签集。
具体的,可以预先设置匹配阈值,当第二数据源中包括的某个词组序列,与步骤102中确定的各领域的第一描述型标签集中,任一描述型标签的匹配度大于预设的匹配阈值时,则将第二数据源中的该词组序列,确定为第二描述型标签集中的一个描述型标签。
具体实现时,可以基于以下多种方法,将第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签进行匹配,以确定第二数据源中包括的第二描述型标签集。
方法一标签全匹配方法
具体的,可以直接在第二数据源的各数据中,对第一描述型标签集中的各描述型标签进行多句法依存模版全匹配,即第二数据源中的某个词组序列与第一描述型标签集中的任一描述型标签的匹配度为100%时,则将第二数据源中的该词组序列,确定为第二描述型标签集中的一个描述型标签。
方法二重要词语匹配方法
具体的,可以忽略诸如虚词等不重要的词语,只在第二数据源的各数据中,对第一描述型标签集中各描述型标签的重要词语进行匹配,即第二数据源中的某个词组序列与第一描述型标签集中的任一描述型标签的匹配度不必为100%,只需大于预设的匹配阈值,即可将第二数据源中的该词组序列,确定为第二描述型标签集中的一个描述型标签。
比如,第一描述型标签集中包括描述型标签“适合情侣逛”,而第二数据源中“适合情侣的”、“适合情侣玩”,与第一描述型标签集中包括的“适合情侣逛”的匹配度均大于预设的匹配阈值,则可以确定“适合情侣的”、“适合情侣玩”为第二描述型标签集中的描述型标签。
步骤105,根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。
具体的,步骤105可以包括:
步骤105a,根据各第二描述型标签与各实体的相关性,对第二描述型标签集进行更新。
其中,第二描述型标签为第二描述型标签集中的描述型标签。各实体为步骤103中确定的实体集中的各实体。
具体的,可以预先设置相关性阈值,然后采用特征抽取和模型预测方法,确定单句中的,各实体与各第二描述型标签的相关性,并将与任一实体的相关性小于预设的相关性阈值的第二描述型标签,从第二描述型标签集中去除,以对第二描述型标签集进行更新。
其中,本发明实施例所用的特征可以分为标签相关特征、词法句法特征、否定词相关特征、多句型输入相关特征几大类。另外,为了保证模型的通用性,所有选用的特征都是语义无关的。
由于本发明实施例所选用的特征有些是比较基础的特征,如依存关系,所以在模型选择方面所选用的模型为比较复杂的随机森林模型,方便对基础特征进行进一步抽象。
具体的,上述采用特征抽取和模型预测,确定实体集中的各实体与各第二描述型标签是否相关的方法,在处理噪音较大或文本复杂的情况时,具有泛化性强,准确率高等优点。
进一步的,根据单句中的,各实体与各第二描述型标签的相关性,确定更新后的第二描述型标签集后,还可以利用一些外部数据,对上述更新后的第二描述型标签集进行大数据整体校验,来修正更新后的第二描述型标签集,从而提高更新后的第二描述型标签集的置信度。
具体的,可以通过基于统计结果校验(如正例比例判断、卡方校验等)、基于知识库信息校验(例如对于某一类目的重要属性,如小说类目的作者,可以使用知识库信息校验)、基于语义校验(比如在同一个实体相关的所有描述型标签中,判断是否包含反义词或互斥标签的情况)、基于用户数据校验等策略,进行大数据整体校验,以提高更新后的第二描述型标签集的置信度。
步骤105b,对更新后的第二描述型标签集进行归一化处理,确定实体描述型标签集。
具体的,对更新后的第二描述型标签集进行归一化处理后,即可得到实体描述型标签集。具体的对更新后的第二描述型标签集进行归一化处理的方法,与上述步骤102中对各领域的第一描述型标签集进行归一化处理的方法相同,此处不再赘述。
需要说明的是,第二描述型标签集,包括所有领域的描述型标签,从而实体描述型标签集,包括所有领域的实体描述型标签。
通过根据单句粒度的各实体与各第二描述型标签的相关性,对第二描述型标签集进行更新,并对更新后的第二描述型标签集进行海量数据的统计校验,以确定实体描述型标签集,提高了实体描述型标签挖掘的准确性。
另外,步骤103可以与步骤101同时进行,也可以与步骤102同时进行,只需在步骤105之前即可。
本发明实施例的实体描述型标签挖掘方法,在获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版后,首先利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集,然后对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,再根据第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签集,最后根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。由此,实现了从多维度对各个领域的实体描述性标签进行挖掘,提高了实体描述型标签挖掘领域的覆盖度及挖掘结果的准确性。
通过上述分析可知,可以在获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模板后,利用各核心词分别对应的第一句法依存模板,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集,从而在对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集后,即可根据第二数据源中的各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签,进而根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签。在实际运用中,利用各核心词分别对应的第一句法依存模板,对第一数据源中的各数据进行匹配处理,确定的各领域的第一描述型标签集中,可能包括同义的或质量较低的描述型标签,下面结合图2,针对上述情况进行具体说明。
图2是本发明另一个实施例的实体描述型标签挖掘方法的流程图。
如图2所示,该方法包括:
步骤201,获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模板。
步骤202,利用各核心词分别对应的第一句法依存模板,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集。
其中,上述步骤201-202的具体实现过程及原理,可以参照上述实施例的详细描述,此处不再赘述。
步骤203,对各领域的第一描述型标签集进行归一化处理,确定各领域更新后的第一描述型标签集。
可以理解的是,利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定的各领域的第一描述型标签集中,可能包括同义的描述型标签,比如“适合儿童”和“适合小孩”。为此,在本发明实施例中,还可以对各领域的第一描述型标签集进行归一化处理,以去除第一描述型标签集中的重复标签。
具体的,可以首先利用将词表征为实数值向量的文本深度表示模型Word2Vec,将第一描述型标签集中的各描述型标签进行向量化,然后采用具有噪声的基于密度的聚类方法(Density-Based Spatial Clustering of Applications with Noise,简称DBSCAN)进行聚类,在类簇内计算两两描述型标签的语义相似度来进行归一化处理,以对第一描述型标签集进行更新,确定各领域更新后的第一描述型标签集。
另外,步骤202确定的各领域的第一描述型标签集的质量可能较低,比如存在由截断导致的语义不明等。为此,在本发明实施例中,还可以对确定的第一描述型标签集中的各描述型标签进行过滤,以提高第一描述型标签集的质量。
具体的,可以利用色情黄反特征、句法模板二元语法(bi-gram)特征、实体词特征、时效性特征、统计频次特征等训练随机森林统一模型,来对第一描述型标签集中的各描述型标签进行过滤,以获取高质量的第一描述型标签集。
在一种可能的实现形式中,步骤201确定的各核心词分别对应的第一句法依存模板的覆盖率可能较低,从而利用第一句法依存模板,对第一数据源中各数据进行匹配处理,确定的各领域的第一描述型标签集的覆盖率可能较低。在本发明实施例中,还可以对获取的各核心词分别对应的第一句法依存模板进行扩展,并利用扩展的句法依存模板对第一数据源中的各数据进行匹配处理,以使确定的第一描述型标签集中的描述型标签更丰富。即,在步骤202之后,还可以包括:
利用第一描述型标签集,对第一数据源进行筛选处理,获取包含第一描述型标签集中各描述型标签的文本集;
对文本集中各文本进行句法分析,分别确定各描述型标签在所各文本中对应的第二句法依存模版;
若任一描述型标签对应的第二句法依存模版类型与其对应的第一句法依存模版类型不同,则利用第二句法依存模版对第一数据源中的各数据进行匹配处理。
具体的,可以利用第一描述型标签集,从第一数据源中,筛选出包含第一描述型标签集中各描述型标签的文本集。或者,为了提高筛选出的文本集的覆盖率,也可以预先设置一个阈值,然后从第一数据源中,筛选出包含某词组序列的文本集,其中,该词组序列与第一描述型标签集中任一描述型标签的匹配度大于预设阈值。然后通过对文本集中各文本进行句法分析,分别确定各描述型标签对应的第二句法依存模板。在任一描述型标签对应的第二句法依存模板类型,与确定该描述型标签时所用的第一句法依存模板类型不同时,则可以利用该第二句法依存模板对第一数据源中的各数据进行匹配,并将确定的各领域的描述型标签集补充到第一描述型标签集中,从而实现对第一描述型标签集的扩充。由此,通过利用扩展的第二句法依存模板对第一数据源中的各数据进行匹配,使得第一描述型标签集的覆盖率更高。
步骤204,将第二数据源中的各数据进行文本分割、噪音过滤处理,生成待识别的数据。
步骤205,对待识别的数据进行识别处理,确定待识别的数据中包括的实体集。
其中,第二数据源的数据量,大于第一数据源的数据量。
步骤206,根据待识别的数据,与各领域更新后的第一描述型标签集中各描述型标签的匹配度,确定待识别的数据中包括的第二描述型标签集。
步骤207,根据各第二描述型标签与各实体的相关性,对第二描述型标签集进行更新。
步骤208,对更新后的第二描述型标签集进行归一化处理,确定实体描述型标签集。
其中,上述步骤204-208的具体实现过程及原理,可以参照上述实施例的详细描述,此处不再赘述。
需要说明的是,步骤204和步骤205可以与步骤201同时进行,也可以与步骤202同时进行,只需在步骤207之前即可。
下面结合图2A所示的实体描述型标签挖掘系统框架图,对本发明实施例提供的实体描述型标签挖掘方法进行说明。
如图2A所示,实体描述型标签挖掘系统包括领域标签挖掘子系统和实体标签关联子系统。领域标签挖掘子系统的挖掘源包括用户的检索日志及网页标题,实体标签关联子系统的挖掘源包括网页数据库。
通过对用户的检索日志及网页标题进行领域候选标签挖掘及领域标签质量控制,可以挖掘出领域标签库,即本发明实施例的各领域的第一描述型标签集。在对网页数据库进行文本分割、噪音过滤等预处理后,可以将预处理后的数据与领域标签挖掘子系统挖掘出的领域标签进行标签匹配,确定第二描述型标签集。然后通过对实体识别过程识别出的各实体,及第二描述型标签集中各描述型标签进行相关性计算,即可根据相关性,确定实体标签对,即本发明实施例的实体描述型标签集。
本发明实施例的实体描述型标签挖掘方法,在获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版后,首先利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集,然后对各领域的第一描述型标签集进行归一化处理,确定各领域更新后的第一描述型标签集,再将第二数据源中的各数据进行文本分割、噪音过滤处理,生成待识别的数据,再对待识别的数据进行识别处理,确定待识别的数据中包括的实体集,再根据各第二描述型标签与各实体的相关性,对第二描述型标签集进行更新,最后对更新后的第二描述型标签集进行归一化处理,确定实体描述型标签集。由此,实现了从多维度对各个领域的实体描述性标签进行挖掘,提高了实体描述型标签挖掘领域的覆盖度及挖掘结果的准确性。
图3是本发明一个实施例的实体描述型标签挖掘装置的结构示意图。
如图3所示,该实体描述型标签挖掘装置包括:
获取模块31,用于获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版;
第一处理模块32,用于利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集;
第二处理模块33,用于对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,其中,第二数据源的数据量,大于第一数据源的数据量;
第一确定模块34,用于根据第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签集;
第二确定模块35,用于根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。
具体的,本发明实施例提供的实体描述型标签挖掘装置,可以执行本发明实施例提供的实体描述型标签挖掘方法,该装置可以被配置在任何终端设备中,以进行实体描述型标签的挖掘。
其中,上述第一数据源中包括用户的检索日志及网页标题;第二数据源中包括网页数据库。
在本申请实施例一种可能的实现形式中,上述第二确定模块35,具体用于:
根据各第二描述型标签与各实体的相关性,对第二描述型标签集进行更新;
对更新后的第二描述型标签集进行归一化处理,确定实体描述型标签集。
需要说明的是,前述对实体描述型标签挖掘方法实施例的解释说明也适用于该实施例的实体描述型标签挖掘装置,此处不再赘述。
本发明实施例的实体描述型标签挖掘装置,在获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版后,首先利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集,然后对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,再根据第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签集,最后根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。由此,实现了从多维度对各个领域的实体描述性标签进行挖掘,提高了实体描述型标签挖掘领域的覆盖度及挖掘结果的准确性。
图4是本发明另一个实施例的实体描述型标签挖掘装置的结构示意图。
如图4所示,在图3的基础上,该实体描述型标签挖掘装置,还包括:
第三处理模块41,用于对各领域的第一描述型标签集进行归一化处理,确定各领域更新后的第一描述型标签集;
第四处理模块42,用于利用第一描述型标签集,对第一数据源进行筛选处理,获取包含第一描述型标签集中各描述型标签的文本集;
分析模块43,用于对文本集中各文本进行句法分析,分别确定各描述型标签在所各文本中对应的第二句法依存模版;
第五处理模块44,用于在任一描述型标签对应的第二句法依存模版类型与其对应的第一句法依存模版类型不同时,利用第二句法依存模版对第一数据源中的各数据进行匹配处理;
第六处理模块45,用于将第二数据源中的各数据进行文本分割、噪音过滤处理,生成待识别的数据。
需要说明的是,前述对实体描述型标签挖掘方法实施例的解释说明也适用于该实施例的实体描述型标签挖掘装置,此处不再赘述。
本发明实施例的实体描述型标签挖掘装置,在获取各领域分别对应的核心词组,及各核心词分别对应的第一句法依存模版后,首先利用各核心词分别对应的第一句法依存模版,对第一数据源中的各数据进行匹配处理,确定各领域的第一描述型标签集,然后对第二数据源中的各数据进行识别处理,确定第二数据源中包括的实体集,再根据第二数据源中各数据,与各领域的第一描述型标签集中各描述型标签的匹配度,确定第二数据源中包括的第二描述型标签集,最后根据实体集中的各实体,与第二描述型标签集中各描述型标签的相关性,确定实体描述型标签集。由此,实现了从多维度对各个领域的实体描述性标签进行挖掘,提高了实体描述型标签挖掘领域的覆盖度及挖掘结果的准确性。
本发明第三方面实施例提出了一种终端设备,包括:
存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,当上述处理器执行所述程序时实现如前述实施例中的实体描述型标签挖掘方法。
本发明第四方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,当该程序被处理器执行时实现如前述实施例中的实体描述型标签挖掘方法。
本发明第五方面实施例提出了一种计算机程序产品,当所述计算机程序产品中的指令由处理器执行时,执行如前述实施例中的实体描述型标签挖掘方法。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现定制逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属技术领域的技术人员所理解。
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,"计算机可读介质"可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(RAM),只读存储器(ROM),可擦除可编辑只读存储器(EPROM或闪速存储器),光纤装置,以及便携式光盘只读存储器(CDROM)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!