对大样本组的高效标注的制作方法
本发明总体上涉及用于标注批量样本的计算机实施的方法。特别地,本发明涉及这样的方法:在其中人工标注被用于标注样本当中的基础实例和特殊实例而其余样本被机器标注。
背景技术:
随着互联网和社交媒体的普及,数字对象快速生成。这些数字对象通常为多媒体,例如视频、图像、音频文件、文本和其组合。对数字对象的标注提高了其可搜索性。通过标注,数字对象被标注有用于描述数字对象的元数据,例如一个或多个关键词。尽管通过标注使得在包含大量数字对象的库中搜索期望的对象高效,但是标注大量的数字对象就其本身来说是一个技术挑战。
通常,机器学习算法被用于分类数字对象以进行标注。智能认知系统需要初始分类器训练。初始用于训练分类器的数字对象首先通过人工标注而被手动标注。人工标注无疑是一个耗时的高成本过程。在标注时减少人工工作是可取的。更具体地,从数字对象库中选择较少量的数字对象来进行人工标注以训练分类器是可取的。然而,大多数现有的标注技术(例如cn104142912a、cn102999516a和us2010/0076923a1中提出的技术)针对另一方面——在可利用的训练样本已经被标注的假设下增加分类器的标注准确性。技术领域中存在对减少或最小化被选择用于人工标注的数字样本的数量的技术的需要。
技术实现要素:
本发明的第一方面是为了提供一种用于标注批量原始样本的计算机实施的方法。
在所述方法中,从所述批量中选择原始样本的第一子集进行人工标注以产生人工标注的样本。所述第一子集通过在最小化所述第一子集的熵均和所述批量的熵均之间的差的方式优化所述第一子集来确定。原始样本的任意集合的熵均通过平均属于前述集合的原始样本的熵值来计算。在获得人工标注的样本之后,从所述批量中去除属于选择的第一子集的原始样本。人工标注的样本被用作训练数据以配置用于标注输入样本以产生标注的输出样本的至少一个标注过程。在配置之后的标注过程用于标注所述批量中剩余的任何原始样本。
优选地,人工标注的样本还被用作训练数据以配置用于验证标注的输出样本的标注准确性的检查过程。此外,对所述批量中剩余的任何原始样本执行标注和检查过程。标注和检查过程包括下述步骤。通过标注过程对所述批量中剩余的单独的原始样本进行标注以产生单独的机器标注的样本。通过检查过程验证单独的机器标注的样本的标注准确性。如果单独的机器标注的样本的标注被验证为是准确的,则从所述批量中去除单独的原始样本;否则,丢弃单独的机器标注的样本。可选的步骤是为单独的原始样本生成验证结果。验证结果包括单独的原始样本、单独的机器标注的样本和单独的机器标注的样本是否准确的指示。如果在执行标注和检查过程之后所述批量非空,则执行更新过程。
在更新过程的一个实施方式中,从所述批量中选择原始样本的第二子集进行人工标注以产生额外的人工标注的样本。在获得额外人工标注的样本之后,从所述批量中去除属于选择的第二子集的原始样本。额外的人工标注的样本被用作额外的训练数据以更新标注过程和检查过程。如果在执行更新过程之后所述批量非空,则重复标注和检查过程。
在更新过程的另一实施方式中,根据在标注和检查过程中获得的一个或多个验证结果来更新标注过程和检查过程。特别地,一个或多个验证结果的全部或部分被用作额外的训练数据以更新标注过程和检查过程。在完成更新过程之后,重复标注和检查过程。
本发明的第二方面是为了提供一种用于标注原始样本的组的计算机实施的方法。所述方法包括聚类所述组中的原始样本以便将所述组分割成原始样本的一个或多个聚类。根据在本发明的第一方面中阐述的方法的任一实施方式来标注原始样本的每个聚类。
如下文的实施方式所示意地公开了本发明的其他方面。
附图说明
图1描绘了根据本发明的标注批量原始样本的流程图。
图2a和2b提供了说明标注所述批量原始样本的处理流程的示例,其中图2a描绘了第一轮处理而图2b描绘了第二轮处理。
具体实施方式
本文在说明书和随附的权利要求书中使用了下述定义。“样本”的意思是数字对象。数字对象是在计算机环境中的非实体数字内容。在大多情况下,数字对象是多媒体内容,例如视频、图像、音频文件、文本或文本文件或其组合。“原始样本”的意思是未被标注或仅被预标注的原样本。“预标注”在下述意义上不同于“标注”。对于未被标注的原始样本,原始样本不包含与原始样本关联的任何标注消息。原始样本即原样本。对于被预标注的原始样本,原样本与第一标注消息关联以形成原始样本但是第一标注消息将通过某个标注过程被第二标注消息取代。第一标注消息可以被用作例如至标注过程的输入以便在标注描述方面改进第一标注消息并且从而产生第二标注消息。在一个特定示例中,第一标注消息由人工检视以在人工标注中用对于原始样本更准确的描述来准备第二标注消息。“标注的样本”的意思是通过标注原始样本而得到的作为结果的样本。标注的样本通过将标注消息与原始样本中的原样本关联而形成。通常,标注的样本是标注有标注消息的原样本,或者标注的样本由数据结构来表示,所述数据结构至少包括作为一个字段的原样本和作为另一字段的标注消息。对于标注的样本,其可以被分类为人工标注的样本或机器标注的样本。“人工标注的样本”的意思是通过原始样本的人工标注而获得的标注的样本。“机器标注的样本”的意思是其标注消息整个地由计算机处理来确定的经标注的样本。
本发明的第一方面是为了提供一种用于标注批量原始样本的计算机实施的方法。在所述方法中,选择所述批量的子集用于人工标注。在对所述子集的选择中,人工标注仅关注原始样本的基础实例和特殊实例,而机器标注用于标注其余原始样本,从而有利地最小化或至少减少用于人工标注的样本的数量。发明人已经发现可以根据每个原始样本的熵值来识别基础实例和特殊实例。借助图1来示意所述方法,图1描绘了标注批量原始样本105的流程图。
所述方法的示例性实施例详述如下。
在步骤110中,从所述批量105中选择原始样本的第一子集。一般地,为所述第一子集选择所述批量105中预先确定的比例数量的原始样本。然而,并非总是这种情况,例如,当由于资源限制需要用于人工标注的原始样本的数量具有上界时。所述第一子集中的原始样本用于人工标注以产生人工标注的样本(步骤115)。在步骤110中,原始样本的所述第一子集有利地通过在最小化所述第一子集的熵均和所述批量的熵均之间的差的方式优化所述第一子集来确定。原始样本的任意集合的熵均通过平均属于前述集合的原始样本的熵值来计算。通过下列四个步骤获得单独的原始样本的熵值。
第一,将单个的原始样本分成多个组成元素{yj}。所述组成元素属于相同类型的特征。作为示意性示例,对于分别为文本、图像、视频和音频信号的四个样本,对应的特征类型可以分别被选择为词、子图像、关键帧和音频信号的时间/频率分量。
第二,从{yj}识别相异的组成元素{xi},以使得{yj}中的每个元素都可以在{xi}中找到。
第三,根据{yj}中等于xi的一个或多个组成元素的数量来估计xi的概率p(xi)。特别地,将p(xi)估计为xi在组成元素{yj}上出现的相对频率。
第四,将单独的原始样本的熵值计算为:-σip(xi)logbp(xi),其中b为底数。实际上并且优选地,在公开的方法的实现方式中,使用了b=2。
下面提供了用于示意计算单独的原始样本的熵值的示例。考虑为字符串“cathatbat”的样本。所述字符串可以被当作数据集合{cat,hat,bat}。特征类型被选择为英语字母。因此,样本的每个组成元素均为英语字母。要注意,字符串中的空格被排除在组成元素之外。由此得出,将样本分成9个组成元素{c,a,t,h,a,t,b,a,t},当作上面的{yj},其中j=1,…,9。存在5个相异的组成元素{a,t,c,h,b},当作上面的{xi},其中i=1,…,5。通过计算:对于“a”的p(x1)被估计为p(x1)=3/9=1/3;对于“t”的p(x2)被估计为1/3;并且对于“b”的p(x5)被估计为1/9。字母“a”的熵通过-p(x1)log2p(x1)=0.52来计算,字母“b”的熵通过-p(x5)log2p(x5)=0.35来计算。由于“b”的熵低于“a”的熵,所以在该情况下我们说字母“b”比字母“a”的信息量少。暗示就是,如果给出字母“b”作为输入的一部分,则可以推断所述输入非常可能是词“bat”。在另一方面,如果给出字母“a”作为输入的一部分,则不知道输入为何。此外,词的熵是所述词的字母的单独的熵的和。整个数据集合的熵均是字符串中的所有词的熵的和再除以词的数量(在该示例中为3)。如果使用图片作为另一样本,则可以将所述图片转换为灰度图片并且将其划分成小块(即子图像)。当每块足够小时,图片的每个小块可以被当做殇计算中词的字母。
在选择第一子集中最小化第一子集和所述批量105之间的熵均差的优点证明如下。单独的原始样本的熵值是该样本的信息量的度量。通过在所述批量的所有可能的候选子集上找到第一子集的熵均和所述批量105的熵均之间的差被最小化或相对小的第一子集,第一子集和所述批量105的信息量有可能接近。由此得出,所述第一子集有可能包含代表所述批量105中所有原始样本的原始样本。由此得出,基于这些代表性原始样本和因此产生的人工标注的样本的机器学习和分类器训练较不可能是误导的。这些代表性原始样本形成上述的“基础实例”。
在步骤115中获得人工标注的样本之后,从所述批量105中去除属于选择的第一子集的原始样本。从所述批量105中去除这些原始样本仅是这些原始样本已经被标注并且不需要机器标注的指示。
人工标注的样本被用作训练数据以配置用于标注输入样本以产生标注的输出样本的至少一个标注过程(步骤120)。配置之后的标注过程在步骤140中用于标注批量105’中剩余的任何原始样本。(代替105使用参考标号105’以便指示当与在开始时的原始批量105相比时,批量105’的大小可能已经被减小)。通常,所述标注过程使用机器学习算法来分类输入的样本。所述机器学习算法可以从命名实体识别(ner)分类器、支持向量机(svm)分类器和神经网络选择。在技术领域中,存在使用基于语言学语法技术以及统计模型(即,机器学习)的ner系统。手工的基于语法的系统一般获得较佳的精度,但是要以较低的检索率和富有经验的计算语言学家数月的工作为代价。统计ner系统一般需要大量的手动标注的训练数据。半监管的方法可用于避免一部分标注工作。在技术领域中已经使用许多不同的分类器类型来执行机器学习的ner,其中条件随机场是典型选择。
一般地,在步骤110中使用选择过程以从所述批量105中选择原始样本的所述第一子集。
在选择过程的一个实施方式中,从所述批量105中选择原始样本的候选子集。然后计算所述候选子集中每个原始样本的熵值。从而通过平均属于候选子集的原始样本的熵值来计算候选子集的熵均。类似地计算原始样本的所述批量105的熵均。通过迭代,在最小化所述候选子集的熵均和所述批量105的熵均之间的差的方向上迭代地改进或完善所述候选子集。最后,在一定数量的迭代之后由所述候选子集给出所述第一子集。迭代的数量可以是预定的数量。替代地,当熵均的增量减小小于某个预定阈值时可停止迭代。
在选择过程的另一个实施方式中,从所述批量105中选择原始样本的多个候选子集。所述候选子集可以相互不重叠或重叠。对于每个单独的候选子集,计算单独的候选子集中的每个原始样本的熵值。通过平均属于单独的候选子集的原始样本的熵值来计算单独的候选子集的熵均。类似地计算所述批量105的熵均。最后,在所有候选子集当中,将具有最接近批量105的熵均的熵均的特定候选子集选择为所述第一子集。
所述方法的额外实施例详述如下。
期望的是通过步骤140中的标注过程生成的机器标注的样本的标注准确性被验证以使得在标注中不准确的那些机器标注的样本能够被识别从而被丢弃。除了具有用于标注输入的样本以产生标注的输出样本的标注过程之外,优选地还使用用于验证标注的输出样本的标注准确性的检查过程。特别地,在步骤115中生成的人工标注的样本也被用作训练数据以配置检查过程(步骤130)。所述检查过程可使用选自ner分类器、svm分类器和神经网络的机器学习算法。替代地,所述检查过程可以使用基于正则表达式的算法。在再一个选项中,标注过程和检查过程使用相同的基于阈值的机器学习算法但是利用不同的阈值。
通过结合标注过程和检查过程二者,形成了标注和检查过程160并且对在所述批量105’中剩余的任何原始样本执行标注和检查过程160。标注和检查过程160包括下述步骤。通过标注过程对所述批量105’中剩余的单独的原始样本标注以产生单独的机器标注的样本(步骤140)。通过检查过程验证单独的机器标注的样本的标注准确性(步骤150)。可选地,在步骤150中生成单独的原始样本的验证结果151。验证结果151的一个用途是在稍后将会详述的更新过程中。验证结果151包括单独的原始样本、单独的机器标注的样本和单独的机器标注的样本是否准确的指示。如果在步骤150中单独的机器标注的样本被验证为在标注中是准确的,则从所述批量105’中去除单独的原始样本,否则,丢弃单独的机器标注的样本(步骤155)。要注意,丢弃单独的机器标注的样本暗示需要重新标注所述单独的原始样本。对批量105’中的所有原始样本执行标注和检查过程160。之后,出于方便通过参考标号105”指示需要重新标注的批量的剩余的原始样本。
如果批量105”非空,则执行更新过程。本文中提供有更新过程的两个选项。
在更新过程的第一个选项171中,通过再次执行步骤110来从所述批量105”中选择原始样本的第二子集。优选地,用于选择所述第一子集的选择过程也用于选择所述第二子集。通过再次执行步骤115,原始样本的所述第二子集用于人工标注以产生额外的人工标注的样本。遵循上述提及的识别基础实例的方法,可以发现在第二子集中的原始样本是上述的“特殊实例”。额外的人工标注的样本被用作额外的训练数据以分别在步骤120和130中更新标注过程和检查过程。在获得额外人工标注的样本之后,从所述批量105”中去除属于选择的第二子集的原始样本。如果在完成更新过程之后所述批量105’(在对所述批量105”执行步骤110之后)非空,则对于批量105’重复标注和检查过程160。如果在完成更新过程之后所述批量105’为空,则其意味着在执行步骤110的过程中原先在所述批量105”中的所有原始样本都已经被选择用于人工标注。如果原先在所述批量105”中的原始样本的数量已经非常低(例如,小于预定的小整数,例如2),则会发生这种情况。
在更新过程的第二个选项172中,首先获得具有一个或多个验证结果的收集152,其中每个验证结果为单独的验证结果151。收集152中一个或多个验证结果的全部或部分被选择并且被直接用作额外的训练数据以更新标注过程和检查过程。在所述更新过程中不涉及人工标注。这样,更新过程的第二个选项172相对于第一选项171具有这样的优点:在机器标注的整个过程中不需要人员待命进行人工标注。
评效批量原始样本105的标注质量是可能的。通过用标注和检查过程160处理属于选择的第一子集的原始样本并且然后用人工标注的样本检查一个或多个验证结果的收集152来获得所述批量105的标注质量。出于这样的优点:即在标注所述批量105’中的原始样本之前确定是否可能需要对标注和检查过程160进行进一步改进,评效优选在通过人工标注的样本初始配置标注过程和检查过程之后马上执行。如果发现需要进一步改进,可以扩展原始样本的第一子集,并且重复执行人工标注115并且在步骤120、130中配置标注过程和检查过程。
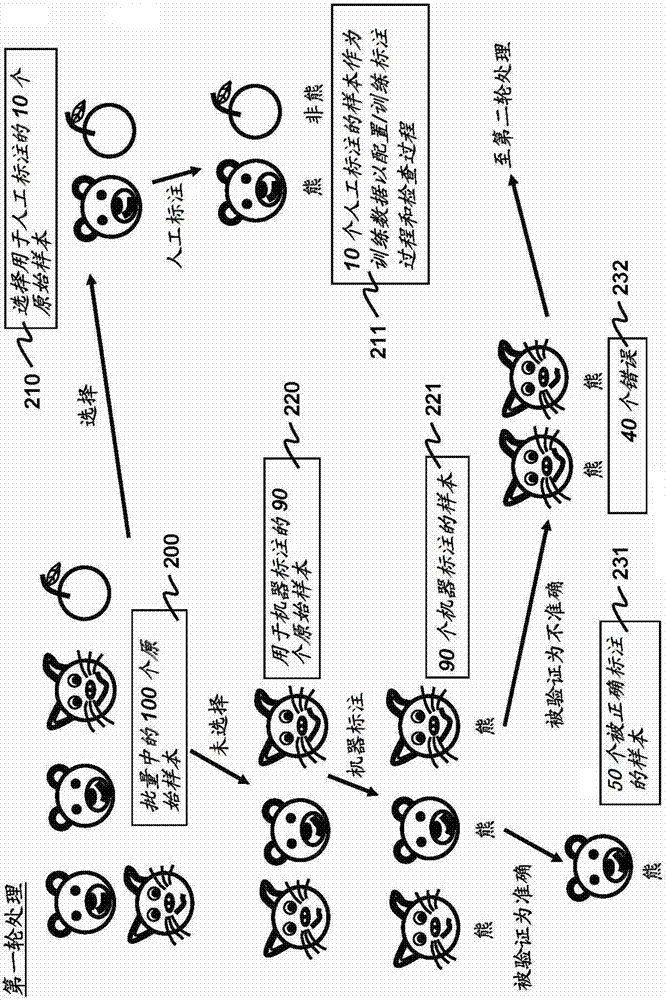
通过考虑标注100个原始样本(作为批量原始样本105)的情况,提供了用于示意所公开的方法的执行的一个示例。出于示意的目的,假设所述100个原始样本没有被预标注,使用更新过程的第一个选项171,并且两轮处理足以标注所有100个原始样本。对于更新过程的第二个选项172的方法的执行是类似的并且不再重复。图2a和2b分别描述了用于第一和第二轮的处理的流程。
参考图2a,其描绘了第一轮处理。将100个原始样本200的批量分割成被选择用于人工标注210的第一多个的10个原始样本和用于机器标注220的第二多个的90个原始样本(对应于步骤110)。第一多个原始样本210被人工标注(对应于步骤115)以产生第三多个的10个人工标注的样本211。第三多个人工标注的样本211被用于训练标注过程(对应于步骤120)和检查过程(对应于步骤130)。在训练标注过程和检查过程之后,通过标注过程(对应于步骤140)机器标注第二多个原始样本220以产生第四多个的90个机器标注的样本221。通过检查过程处理第四多个机器标注的样本221以验证其中的每个机器标注的样本(对应于步骤150)。作为验证的结果,将第四多个机器标注的样本221分割成被确定为被正确地标注的第五多个的50个机器标注的样本231以及被确定为被错误地标注的第六多个的40个机器标注的样本232。第一轮处理结束,并且100个原始样本当中的60个被正确地标注。剩余的40个原始样本(共同对应于第六多个错误的机器标注的样本)形成待在第二轮处理中被处理的第七多个的40个原始样本240。第六多个错误的机器标注的样本232被丢弃。
参考图2b,其描绘了第二轮处理。将第七多个原始样本240分割成用于人工标注250的第八多个的4个原始样本和用于机器标注260的第九多个的36个原始样本(对应于步骤110的第二次执行)。人工标注第八多个原始样本250(对应于步骤115的第二次执行)以形成第十多个的4个额外的人工标注的样本251,所述第十多个的4个额外的人工标注的样本251被用作额外的训练数据以更新标注过程和检查过程(对应于步骤120和130)。在更新标注过程和检查过程之后,通过标注过程(对应于步骤140)标注第九多个原始样本260以给出第十一多个的36个机器标注的样本261。通过检查过程(对应于步骤150),第十一多个机器标注的样本261中的所有36个样本被确定为具有准确的标注。因此,获得了被确定为正确地被标注的第十二多个的36个机器标注的样本271。在第二轮处理结束时,已经标注了初始在批量200中的所有100个原始样本。100个标注的样本的集合由第三多个的10个人工标注的样本211、被确定为正确地被标注的第五多个的50个机器标注的样本231、第十多个的4个额外的人工标注的样本251以及被确定为正确地被标注的第十二多个的36个机器标注的样本271组成。
本发明的第二方面是为了提供一种用于基于根据第一方面在上面描述的方法来标注原始样本的组的计算机实施的方法。
再次参考图1。原始样本的组102需要被标注。组102中的原始样本在步骤180中首先被聚类以便将组102分割成原始样本的一个或多个聚类103。根据本发明的第一方面在上文公开的方法的任一实施方式来标注一个或多个聚类103中的每一个,其中原始样本的每个聚类被当作原始样本的批量105。
在步骤180中,可使用k均值聚类以聚类组102中的原始样本。
在实际的实现方式中,可以给组102中的每个原始样本提供预标注数据。通过包括单独的原始样本和其预标注数据来形成用于组102中单独的原始样本的数据结构。从而获得了用于组102中所有原始样本的多个数据结构。在步骤180中,可以执行对所述多个数据结构的k均值聚类以聚类组102中的原始样本。
在标注原始样本的单独的聚类中,在步骤110中选择的第一子集中的原始样本的数量通常为在前述单独的聚类中的原始样本的数量的预定比例。在一个选项中,所述预定比例对于所有一个或多个聚类103是唯一的。
本发明可以以其他具体形式实施,而不脱离其精神或实质特性。因此,本实施方式应该在在所有方面被视为是示例性的,而非限制性的。本发明的范围由随附权利要求限定,而不是由前述说明书限定,并且因此落入权利要求的等价物的意义和范围内的所有变化应该包含在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!