卷积神经网络中的结构学习的制作方法
本公开涉及计算网络,更具体地,涉及被配置为从数据学习分层表示的神经网络。
背景技术
神经网络涉及仿照可用于解决复杂计算问题的生物脑部处理的神经结构宽松建模的计算方法。神经网络通常被组织作为一组层,其中每层包括包含各种功能的互连节点的组。加权连接实现在网络内处理的功能,以执行各种分析操作。可以采用学习方法来构建和修改网络和网络内的连接器的相关权重。通过修改连接器权重,这允许网络随着时间的推移从过去的分析中学习,以改善未来的分析结果。
可以采用神经网络来执行任何适当类型的数据分析,但是特别适合应用于复杂的分析任务,诸如图案分析和分类。因此,这些技术的直接应用适合于例如实现机器视觉功能,诸如从数字成像设备捕捉的图像数据对特定对象和对象种类进行辨别和分类。
本领域中已知有许多类型的神经网络。深度神经网络是这样的一类神经网络,其中应用深度学习技术来实现非线性处理的多层级联(cascade)以执行分析功能。深度学习算法通过比浅层学习算法更多的层来变换输入。在每一层,信号由诸如人工神经元的处理单元变换,该处理单元的参数通过训练而学习。
卷积神经网络是这样的一类神经网络,其中网络中的连接模式受到生物视觉皮层功能的启发。通过网络构建视场,其中个体人工神经元对输入刺激的响应可以通过卷积运算在数学进行近似。
在现有技术中已经实现了卷积深度神经网络。lenet(lecun等,(1998))、alexnet(krizhevsky等,(2012))、googlenet(szegedy等,(2015))和vggnet(simonyan&zisserman,(2015))都是实现不同类型的深度神经网络的convnet架构的示例。这些模型是完全不同的(例如,不同的深度、宽度和激活函数)。然而,这些模型在一个关键方面都是相同的—每一个都是手工设计的结构,体现了建筑师对于手头的问题的见解。
这些网络遵循相对简单的配方,从卷积层开始,该卷积层学习与gabor滤波器相似的低水平特征或其某些表示。后面的层对诸如对象部分(脸部、汽车等的部分)的更高水平的特征进行编码。最后,在顶部,存在返回关于种类的概率分布。虽然这种方法在标签空间中为由受训练的网络产生的输出提供了一些结构,但问题是当设计和训练这些网络时很少使用这种结构。
已经提出了概率图形模型中的结构学习,其中用于深度卷积网络中的结构学习的常规算法通常落在以下两类中的一者中:使网络更小的那些和使网络更好的那些。一种提出的方法致力于采用难以控制的预训练网络并将其压缩到具有较小内存占用的网络中,因此需要较少的计算资源。这类技术遵循“师生”范式,其目标是创建一个模仿教师的学生网络。这意味着需要开始于oracle架构及其学习的权重—训练学生只能在稍后进行。当在非常大的数据集上提取专家(specialist)集合时,必须首先执行计算上昂贵的集合训练步骤。
feng等的“学习深度卷积网络的结构”是用于自动学习深度模型的结构的方面的技术的示例。该方法使用印度自助餐过程(indianbuffetprocess)来提出新的卷积神经网络模型以识别结构,其中在确定结构之后,执行修剪以创建网络的更紧凑的表示。然而,这种方法的一个缺点是层的数量保持静态,其中只有静态数量的层内的已知单个层通过结构学习方法被增强(augment)为或多或少的复杂。因此,该方法无法识别优化结构可能需要的任何新层。
因此,需要一种改进的方法来实现卷积神经网络的结构学习。
技术实现要素:
本发明的一些实施例涉及实现神经网络的结构学习的改进方法。该方法从网络开始,为网络提供具有标记数据的问题,然后检查该网络产生的输出结构。然后修改网络的架构以获得针对特定问题的更好的解决方案。这种方法不是让专家提出高度复杂和特定于域的网络架构,而是允许数据驱动将用于特定任务的网络架构。
根据一些实施例,可以通过以下方式来改进神经网络:(a)识别其结构中的信息增益瓶颈、(b)应用预测的结构以缓解瓶颈、以及最后(c)确定专家路径的深度。
一些实施例通过利用网络旨在解决的数据/问题中的相关性来实现神经网络的结构学习,其中执行贪婪方法以从底部卷积层一直到完全连接的层找到信息增益的瓶颈。在一些实施例中,在初始时间点创建网络,并且当应用于指定任务时从网络生成一组输出,例如,应用于执行图像识别/对象分类任务。接下来,分析网络模型内的各个层以识别模型内最差表现的层。然后将附加结构注入模型中以改进模型的性能。特别地,在识别的垂直位置处将新专家层插入到模型中以增强模型的性能。不是仅具有一个通用路径来对多种类型的对象进行分类,而是可以添加第一新专家层以仅用于处理第一类对象的分类,并且可以添加第二新专家层以仅用于处理对第二类对象的分类。通过采取这一动作,随着时间的推移,这些专家组件(component)中的每一个都对其专业的专用领域非常了解,因为专家被迫学习有关分配给该专家组件的特定子域的广泛水平的细节。以这种方式,通过添加新层来改进模型,所述新层将直接处理与网络的其他部分相比被特别地识别作为次优的分类区域。同样的方法继续通过模型的其余部分来识别应该被修改和/或增强的任何附加层。
在某些实施例中,在网络的每个层处包括“损失”机制(例如,损失层、损失函数和/或成本函数)。代替仅具有单个顶级损失层,将附加的损失层添加到网络内的其他层,例如,深度神经网络在特征提取的中间和最后阶段具有多个损失层,其中每个损失层可以测量到达深度的那个点的网络的性能。可以在每个损失层处生成预测并将其转换为相应的混淆矩阵,形成包含网络的所有混淆矩阵的张量t。通过分析t的结构及其要素,目的是在深度和宽度(breadth)方面修改和增强网络的现存结构。为了一方面最大化功能共享并减少计算,另一方面提高准确性,目的是重构现存网络的结构。为此,该方法根据当前表现划分(partition)网络的深度和宽度。因此,在一些实施例中,例如通过计算不同层之间的点积来执行垂直分割。为了在深度上划分架构,一些实施例比较与相邻层处的连续损失函数估计对应的相邻子空间。另外,例如通过执行k路分叉(bifurcation)来执行水平分割。为了改善特定层的网络性能,其结构(例如,完全卷积的)可能需要增强。网络的一部分聚焦于一般知识(通才),而另一些则聚焦于于彼此之间具有高度相似性的小子集标签(专家)。由层i获取的知识将用于执行网络的第一水平划分。处理继续(例如,以递归方式),直到到达网络的顶部。此时,最终模型被存储到计算机可读介质中。
一些实施例涉及专家的深度学习。虽然已知通才的结构在一般知识上表现良好,但不能保证这种相同的结构在专家的任务可能需要更简单或复杂的表示的专家中表现良好。一些实施例允许每个专家的结构以数据驱动的方式经由深度式分割而偏离通才的结构。
可以在可选实施例中应用这些技术的其他变型。例如,对于每对分割(垂直或水平),可以重新训练网络以在给定路径处进行分类。可以在某些实施例中应用诸如通过凝聚聚类和/或分割技术以使该过程加速和/或完全避免它。此外,给定混淆矩阵ci及其划分k,可以对ci的k个部分中的每一个执行凝聚聚类以估计进一步的分割。这导致成本xu。成本xs是监督分组的成本,在网络的高级别处学习新的混淆矩阵。xu小于或等于xs+tau,其中tau是聚类误差的上限。
在一些实施例中,考虑卷积层对于完全连接(1x1卷积)的变化。如果在卷积层(甚至是完全卷积层,诸如在语义分割的情况下)之间需要分割,则不是改变层的线性尺寸(在这种情况下为fc),而是可以改变维度的深度以反映种类的数量(这是对fcn的扩展)。
可以使用每个路径的塌陷(collapse)或附加或垂直层、根据标签空间(labelspace)改变层的尺寸、和/或对检测和rnn的扩展(通过比较混淆以相同的方式展开)来产生进一步的变型和实施例。
在又一个实施例中,在网络中可能存在太多层时,可以应用技术来识别,使得更少的层将对所需的处理任务是足够的。如上所述,可以可靠地向网络添加深度,并在给定足够的训练数据的情况下看到性能的改善。然而,这种性能的添加提升可能会导致flop和内存消耗成本增加。在一些实施例中,牢记该折衷,通过使用全有或全无(all-or-nothing)高速公路网络来对网络进行优化,该全有或全无高速公路网络通过二元决策(binarydecision)来学习网络中的给定计算层是否被使用。如果使用给定的计算块,则会产生惩罚。通过改变这个惩罚项,可以考虑使用目标架构来定制学习方法:嵌入式系统更喜欢比基于云的系统更精简的架构。
以下在说明书、附图和权利要求中描述了本发明的方面、目的和优点的进一步的细节。前面的一般性描述和下面的详细描述都是示例性和说明性的,并不意图限制本发明的范围。
附图说明
附图示出了本发明的各种实施例的设计和实用性。应该注意的是,附图未按比例绘制,并且在所有附图中相似结构或功能的元件由相同的附图标记表示。为了更好地理解如何获得本发明的各种实施例的上述和其他优点和目的,将通过参考其特定实施例来呈现上面简要描述的本发明的更详细描述。应理解,这些附图仅描绘了本发明的典型实施例,因此不应认为是对其范围的限制,本发明将通过使用附图的附加特征和细节进行描述和说明,其中:
图1示出了可以在本发明的一些实施例中采用以实现关于神经网络的结构学习的示例系统。
图2示出了根据本发明的一些实施例的实现关于神经网络的结构学习的方法的流程图。
图3示出了根据一些实施例的实现关于神经网络的结构学习的方法的更详细的流程图。
图4a-4f示出了本发明的各种实施例。
图5a-5b示出了在网络可能存在太多层时进行识别的方法。
图6a-6d示出了各种实施例的一般ar系统组件选项。
图7描绘了可以在其上实现本发明的一些实施例的计算机化系统。
具体实施方式
本发明的一些实施例涉及实现关于神经网络的结构学习的改进方法。该方法从网络开始,为网络提供具有标记数据的问题,然后检查该网络产生的输出结构。然后修改网络的架构以获得针对特定问题的更好的解决方案。这种方法不是让专家提出高度复杂和特定于域的网络架构,而是允许数据驱动将用于特定任务的网络架构。
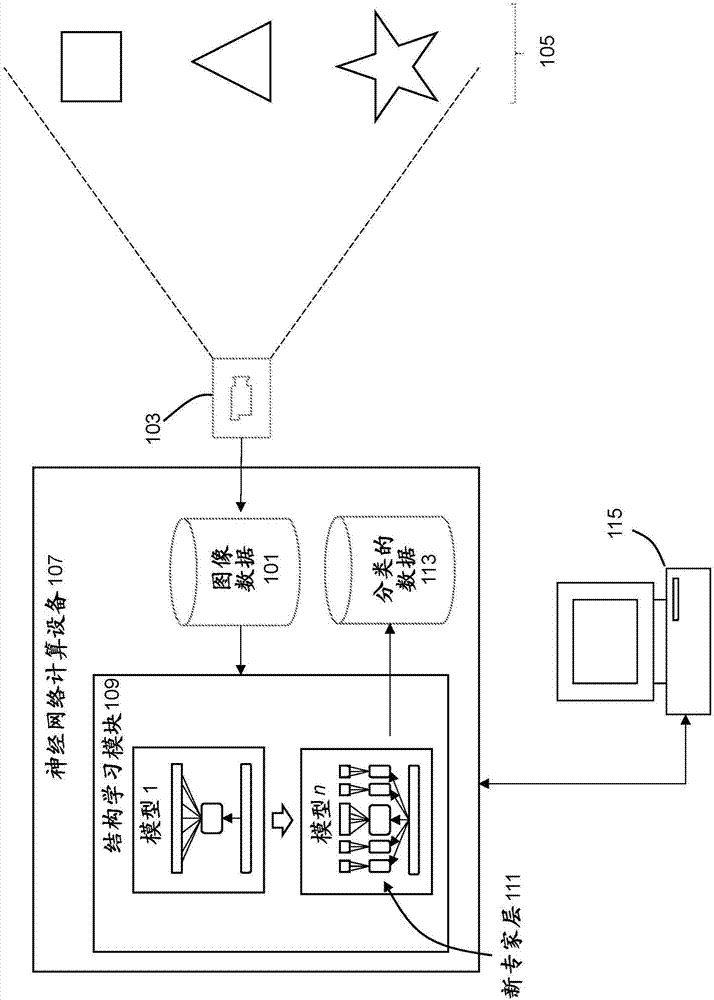
图1示出了可以在本发明的一些实施例中采用以实现关于神经网络的结构学习的示例系统。该系统可以包括与计算系统107或115交互并操作计算系统107或115以控制系统和/或与系统交互的一个或多个用户。该系统包括可用于操作神经网络计算设备107或用户计算设备115、与神经网络计算设备107或用户计算设备115交互或实现神经网络计算设备107或用户计算设备115的任何类型的计算站。这种计算系统的示例包括例如服务器、工作站、个人计算机或连接到网络化的或基于云的计算平台的远程计算终端。计算系统可以包括一个或多个输入设备,用于用户提供对系统活动的操作控制,诸如鼠标或键盘以操纵指向对象。计算系统还可以与显示设备相关联,诸如显示监视器,用于到计算系统的用户的控制接口和/或分析结果。
在一些实施例中,该系统用于实现计算机视觉功能。这样,系统可以包括一个或多个诸如相机103的图像捕捉设备以捕捉系统操作的环境中的一个或多个对象105的图像数据101。图像数据101和/或任何分析结果(例如,分类输出数据113)可以存储在一个或多个计算机可读存储介质中。计算机可读存储介质包括允许随时访问位于计算机可读存储介质上的数据的硬件和/或软件的任何组合。例如,计算机可读存储介质可以实现为由操作系统可操作地管理的计算机存储器和/或硬盘驱动器存储、和/或网络化存储设备中的远程存储,该远程存储诸如网络化连接存储(nas)、存储区域网络(san)或云存储。计算机可读存储介质还可以实现为具有在持久存储和/或非持久存储上的存储的电子数据库系统。
神经网络计算设备107包括结构学习模块109,以将原始模型1修改为改进的模型n,其中模型n是可能的多个迭代过程的结果,以修改模型内的层。模型n优选地包括知识的深度和宽度,基本上是专家的混合。该模型应该理解粗种类之间的差异,同时理解跨各种域的细致种类的差异。为实现这些目标,必要时将新专家层111添加到模型中。这种系统的设计由仅在需要时添加资源的约束控制。简单地通过使网络任意地更深和更宽来扩展网络因计算约束而不能实现缩放(scale),因此本方法避免了对额外的规范化技巧的需要。
图2示出了根据本发明的一些实施例的实现关于神经网络的结构学习的方法的流程图。本方法通过利用网络旨在解决的数据/问题中的相关性来实现神经网络的结构学习。描述了一种贪婪的方法,该方法从底部卷积层一直到完全连接的层找到信息增益的瓶颈。不是仅简单地任意地使架构更深,而是仅在需要时添加附加的计算和电容。
在131处,在初始时间点创建网络。可以使用任何合适的方法来创建网络。例如,可以使用常规的alexnet或googlenet方法来生成网络。
接下来,在133处,当应用于指定任务时,例如,执行图像辨别/对象分类任务,从网络生成一组输出。例如,假设许多人和动物在环境中,以及所分配的任务是分析图像数据以对可在环境中观察到的不同人和动物类型进行分类。模型的每一层都为该层内执行的活动提供某些输出。输出具有某些结构,可以对其进行检查以确定正在解决的分类问题中的种类之间的关系。
在135处,分析网络模型内的各个层以识别模型内的最差表现层。例如,假设具有十层的模型,其中来自层1至层3和层5至10的层各自提供10%的分类准确性的改进,但层4仅提供1%的改进。在这种情况下,层4将被识别为最差表现层。
接下来,在137处,将附加结构注入模型中以改善模型的性能。特别地,在识别的垂直位置处将新专家层插入到模型中以增强模型的性能。
为了解释本发明实施例的这个方面,假设该模型旨在执行如图4a所示的环境中的人和动物的分类。这里,图像捕捉设备捕捉不同人(例如,女人401、男人403和孩子405)的图像。另外,环境包括多个动物(例如,猫407、狗409和鼠411)。进一步假设现有模型能够成功地将人(401、403、405)与动物(407、409、411)区分开,但似乎更难以将不同的人彼此区分或将不同类型的动物彼此区分。如果对能够从网络(例如,oracle网络)学习的实际结构进行检查,则显然网络包括正在进行的预测之间的学习依赖性。然而,在传统的深度学习架构设计中,没有使用这一点。如果更接近观察这种结构,系统明显正在学习实际上在视觉上彼此相似的概念(concept)。参考图4b,示出了3d种类的示例散点图,以示出关于完全训练的alexnet的预测的示例结构,该完全训练的alexnet被聚类成多个组。点之间的距离对应于概念之间的视觉相似性。这里,可以看出,存在关于人物对象的点的第一紧密聚类和关于动物对象的点的第二紧密聚类。正是这种现象可能导致模型难以区分一个人与另一个人或一个动物与另一动物。
在本发明的一些实施例中的这种情况下,不是仅具有一个通用路径来对所有这些类型的对象执行分类,而是可以添加第一新专家层以仅用于解决人的分类以及可以添加第二新专家层以仅用于解决动物的分类。因此,一个专家(人物专家层)将被分配来处理图4b中的图表的部分413的数据,而第二专家(动物专家层)将被分配来处理图4b中的部分415的数据。通过采取这一动作,随着时间的推移,这些专业组件中的每一个都对其专业的专用领域非常了解,因为专家被迫学习有关分配给该专业组件的特定子域细节的广泛水平。以这种方式,通过添加新层来改进模型,所述新层将直接解决与网络的其他部分相比被特别地识别作为次优的分类区域。
该相同过程继续通过模型的其余部分以识别应该被修改和/或增强的任何附加层。因此,在139处做出处理是否已到达网络的顶部的确定。如果是,则在141处完成模型。如果不是,则该过程返回到133以继续该过程,直到到达网络的顶部。
可以采用该方法来修改和改进任何现有的卷积神经网络的架构。通过遵循本公开的发明方法,可以通过以下方式改进任何神经网络:(a)识别其结构中的信息增益瓶颈、(b)应用预测的结构以缓解瓶颈、以及最后(c)确定专家路径的深度。
图3示出了根据一些实施例的实现关于神经网络的结构学习的方法的更详细的流程图。出于该流程的目的,假设已经根据诸如alexnet或googlenet的任何合适的方法创建了网络(例如,单片网络)。
在151处,在网络的每个层处包括“损失”机制(例如,损失层、损失函数和/或成本函数)。损失机制对应于函数,该函数将事件或值映射到与神经网络内的处理相关联的成本或误差值的表示。如图4c所示,不是仅具有单个顶级损失层421,而是将附加的损失层423添加到网络内的其他层。因此,该图显示了在特征提取的中间和最后阶段具有多个损失层的深度神经网络的示例,其中每个损失层测量直到该深度点的网络的性能。回想一下,目标是通过修改其架构以最好地适应任务来增强和修改网络架构以尽可能地解决给定的问题。因此,该方法分析在整个网络中的各个损失层处形成的预测,并基于各个损失层之间的混淆对神经元激活进行分组。
如图4d和4e所示,在每个损失层处生成预测并将其转换为相应的混淆矩阵(如图4d所示),形成包含网络的所有混淆矩阵的张量t,该网络例如oracle网络(如图4e所示)。通过分析t及其要素的结构,目的是在深度和宽度方面修改和增强网络的现存结构。
为了说明,让ci作为种类和损失层i的混淆矩阵,然后:
其中ai是损失层i的相关度(affinity)矩阵,di是对角矩阵,li是图表laplacian,以及
一方面为了最大化特征共享并减少计算,另一方面又为了提高准确性,目的是重构现存网络的结构。为此,该方法根据当前性能划分网络的深度和宽度。
因此,在153处,例如通过计算不同层之间的点积来执行垂直分割。为了在深度上划分架构,一些实施例使用以下等式比较与相邻层处的连续损失函数估计对应的相邻子空间:
这里,
令φ是i和i+1的所有连续对的向量,其中φi=φ(i,i+1)。最接近零的φi的值表示层i和i+1之间的最低信息增益。因此,argmin(φ)是单片架构的最佳初始分割。在深度上分割架构有助于特征共享,同时识别冗余点(零信息增益)。
在155处,例如通过执行k路分支来执行水平分割。为了改进特定层的网络性能,其结构(例如,完全卷积)可能需要增强。网络的一部分聚焦于一般知识(通才),而另一些则聚焦于彼此之间具有高度相似性的小子集标签(专家)。由层i获取的知识将用于执行网络的第一水平划分。
形式上,给定ci,如上所述,根据每个等式(1)、(2)和(3)计算li。通过分析图表拉普拉斯算子li的前导特征值来确定特征间隙(eigengap),以确定新路径(专家)的数量。原始数据被投射到li的顶部n个前导特征向量上;在rn中,数据进一步聚类为k个种类,其中k等于特征间隙。在图4b中示出了这种投影和分组的示例。该过程将导致如图4f所示的架构的修改,其示出了在第一分割之后的网络407。
一旦建立了第一分割,则将所有新路径视为原始网络。应用分割过程,直到不再分割标签或达到100%的准确度。
在157处,上述处理继续(例如,以递归方式)直到到达网络的顶部。此时,最终模型存储在计算机可读介质中。
本公开的该部分涉及专家的深度学习。虽然已知通才的结构在一般知识上表现良好,但不能保证这种相同的结构在专家的任务可能需要更简单或复杂的表示的专家中表现良好。一些实施例允许每个专家的结构以数据驱动的方式经由深度式分割而偏离通才的结构。
考虑到进一步分割,令l={l1,l2,...,ln}为一组完全连接的层。l中的层li被认为是产生输出y。可以将其应用于其输入的变换写为y=σ(f(x)),其中σ()应用非线性,诸如relu和f(x)=wx,其中w是学习的维度权重矩阵mxn,x是到具有nx1维度的该层的输入。为了执行分割,该方法将li的变换分解为y=σ1(g(σ2(h(x))),其中σ1()和σ2()是激活函数,g(x)=w1x,h(x)=w2x,其中w1具有nxn的维度,w2具有mxn的维度。该方法选择:
σ1(x)=σ(x)(6)
σ2(x)=ix(8)
这里,w=uσvt是w的svd因式分解,i是单位矩阵。通过这种改变,层li的变换不变。为了增加li的学习表示的复杂性,可以将σ2设置为非线性激活函数,诸如relu。然而,添加这种非线性导致li的学习表示的突然变化,并且可能导致网络从头开始重新学习它的大部分内容。替代地,可以插入prelu非线性并将其单个参数a初始化为1,该单个参数a等于等式8中的i。这为专家提供了在该层引入新的非线性的平滑机制。
给定层组l,可以独立地将上述策略应用于每个层li,并且贪婪地选择提供训练损失的最佳改进的分割。该过程可以递归地重复到我们的层组lnew={l1,l2,...,ln,ln+1}。
可以在可选实施例中应用这些技术的其他变型。例如,对于每对分割(垂直或水平),可以重新训练网络以在给定路径处进行分类。可以在某些实施例中诸如通过凝聚聚类和/或分割应用技术以使其加速和/或完全避免它。此外,给定混淆矩阵ci及其划分k,可以对ci的k个部分中的每一个执行凝聚聚类以估计进一步的分割。这导致成本xu。成本xs是监督分组的成本,在网络的高水平上学习新的混淆矩阵。xu小于或等于xs+tau,其中tau是聚类错误的上限。
在一些实施例中,考虑卷积层对于完全连接(1x1卷积)的变化。如果在卷积层(甚至是完全卷积层,诸如在语义分割的情况下)之间需要分割,则不是改变层的线性尺寸(在这种情况下为fc),而是可以改变尺寸的深度以反映种类的数量(这是fcn的扩展)。
可以使用每个路径的塌陷或添加或垂直层、根据标签空间改变层的尺寸、和/或对检测和rnn的扩展(通过比较混淆以相同的方式展开)来产生进一步的变型和实施例。
在又一个实施例中,在网络中可能存在太多层时,可以应用技术来识别,使得更少的层将对所需的处理任务是足够的。如上所述,可以可靠地向网络添加深度,并在给定足够的训练数据的情况下看到性能的改进。然而,这种性能的添加提升可能会导致flop和内存消耗成本增加。在一些实施例中,牢记该折衷,通过使用全有或全无高速公路网络来对网络进行优化,该全有或全无高速公路网络通过二元决策来学习网络中的给定计算层是否被使用。如果使用给定的计算块,则会产生惩罚。通过改变这个惩罚项,可以考虑使用目标架构来定制学习方法:嵌入式系统更喜欢比基于云的系统更精简的架构。
该实施例所解决的问题是确定在关于给定问题x给定计算预算的情况下使网络多深。通过使用全有或全无高速公路网络的方法,高速公路网络引入混合矩阵来学习如何在与当前计算块的输出混合之前变换自前一层的跳跃连接(skipconnection)。考虑以下等式:
y=f(x,wi)+wsx(10)
残差(residual)网络可以在使用恒等映射(identitymapping)来组合跳跃连接方面找到成功。虽然恒等映射不太具有代表性,但它更有效,更容易优化:
y=f(x,wi)+x(11)
替代地,当前的方法通过单个标量α来参数化混合矩阵,该标量α对计算块的输出进行选通(参见图5a):
y=αf(x,wi)+x(12)
当α=0时,y=x并且输入简单地传递到输出。当α=1时,(eqn12)变为(eqn10)并且残差单元用于计算。
图5a示出了关于具有全有或全无高速公路连接的网络的图表501。在该图中,计算块被馈入输入,然后通过残差连接(元素级加法(elementwiseaddition))结合(join)。在加法之前,计算块的输出由学习参数α缩放,该学习参数α惩罚该计算块的使用。这种损失描述如下。
执行学习以确定是否使用计算块。期望在α参数上施加先验(prior),α参数控制深层网络中给定层的行为,并且与模型参数及其目标函数一起优化该参数。在训练期间,期望鼓励关于α的二元决策,以独立地为每个深度选择0或1。如果计算块被学习以被跳过,则可以在推断时间处简单地从模型中移除该计算块。
在残差网络中,连续层通常具有小映射,其中所学习的残差函数通常具有小响应,表明恒等映射提供合理的预处理。这表明在(方程10)中的恒等映射与恒等层之间的转换(反之亦然)不应导致目标函数的灾难性变化。因此,本方法在α参数上引入分片式平滑损失函数,该α参数在不同深度处对计算块的输出进行选通。
另外,期望对α参数上的损失函数进行参数化,使得对于不同的场景,对使用更多计算的模型分配更高的惩罚。在诸如智能手机的轻型嵌入式平台的情况下,人们可能希望在选择层时受到高惩罚。在云计算平台的情况下,可能不需要使用计算块的这种惩罚。给定这些标准,可以使用图5b中所示的分片式平滑多项式/线性函数,其可以通过以下过程被参数化:
ifx<0.:
y=(np.absolute(x)*self.steepness)
elifx>1.:
y=(x-1.)*self.steepness++self.peak*0.125
elifx<0.5:
y=-self.peak*(x**2.-x)
else:
y=-self.peak/2.*(x**2.-x)+self.peak*0.125
对于图5b中所示的峰的各种选择,给予模型变化的使用惩罚。
增强现实和计算系统架构
上述技术特别适用于虚拟现实和增强现实系统的机器视觉应用。本发明的神经网络分类装置可以独立于ar系统来实现,但是仅出于示例性目的,下面的许多实施例关于ar系统进行描述。
公开了用于各种计算机系统的分类和辨别的装置、方法和系统。在一个实施例中,计算机系统可以是头戴式系统,其被配置为便于用户与各种其他计算机系统(例如,金融计算机系统)交互。在其他实施例中,计算机系统可以是固定装置(例如,商家终端或atm),其被配置为便于用户进行金融交易。下面将在ar系统(例如,头戴式)的背景下描述各种实施例,但是应当理解,本文公开的实施例可以独立于任何现有和/或已知的ar系统使用。
现在参考图6a-6d,根据各种实施例示出了一些一般的ar系统组件选项。应该理解的是,尽管图6a-6d的实施例示出了头戴式显示器,相同的组件也可以包含在固定的计算机系统中,不应将图6a-6d视为限制。
如图6a所示,头戴式装置用户60被描绘为佩戴框架64结构,框架64结构耦接到位于用户60眼睛前方的显示系统62。根据所需的安全水平,框架64可以永久地或临时地耦接到一个或多个用户识别(identification)特定子系统。扬声器66可以被耦接到所描绘的配置中的框架64并且位于用户60的耳道附近。在可选的实施例中,另一扬声器(未示出)位于用户60的另一耳道附近以提供立体声/可塑形声音控制。在一个或多个实施例中,用户识别装置可以具有显示器62,该显示器62可操作地(诸如通过有线引线或无线连接)被耦接到本地处理和数据模块70,本地处理和数据模块70可以以各种配置安装,诸如被固定地附到框架64上、被固定地附到如图6b描绘的实施例所示的头盔或帽子80上、被嵌入头戴耳机内、可拆卸地附到如图6c描绘的实施例所示的以背包式配置的用户60的躯干82、或可拆卸地附到如图6d描绘的实施例所示的以带耦接式配置的用户60的臀部84。
本地处理和数据模块70可以包括功率有效的处理器或控制器以及诸如闪速存储器的数字存储器,这两者都可用于辅助处理、高速缓存和存储数据。可从可以可操作地耦接到框架64的传感器捕捉该数据,所述传感器诸如为图像捕捉设备(诸如相机)、麦克风、惯性测量单元、加速度计、罗盘、gps单元、无线电设备和/或陀螺仪。可选地或另外地,可以使用远程处理模块72和/或远程数据储存库74而被获取和/或处理该数据,这些数据可以在这样的处理或检索之后被传送到显示器62。本地处理和数据模块70可以诸如经由有线或无线通信链路可操作地耦接76、78到远程处理模块72和远程数据储存库74,使得这些远程模块72、74可操作地彼此耦接并且可用作本地处理和数据模块70的资源。
在一个实施例中,远程处理模块72可以包括一个或多个相对强大的处理器或控制器,这些处理器或控制器被配置为分析和处理数据和/或图像信息。在一个实施例中,远程数据储存库74可以包括相对大尺寸的数字数据存储设施,该设施可以通过因特网或“云”资源配置中的其它网络配置而可用。在一个实施例中,在本地处理和数据模块中存储所有数据并且执行所有计算,从而允许从任何远程模块完全自主的使用。
在一些实施例中,类似于图6a-6d所描述的那些的识别装置(或具有识别应用的ar系统)提供了对用户眼睛的唯一(unique)访问。假定识别/ar设备与用户的眼睛重要地(crucially)交互以允许用户感知3d虚拟内容,并且在许多实施例中,跟踪与用户眼睛相关的各种生物特征(例如,虹膜图案、眼睛聚散度、眼睛运动、锥体和杆(rod)的图案、眼睛运动的图案等),所得到的跟踪数据可以有利地用于识别应用中。因此,这种对用户眼睛的前所未有的访问自然适用于各种识别应用。
图7是适合于实现本发明的实施例的示例性计算系统1400的框图。计算机系统1400包括总线1406或用于通信信息的其他通信机制,其使子系统和设备互连,诸如处理器1407、系统存储器1408(例如,ram)、静态存储设备1409(例如,rom)、磁盘驱动器1410(例如,磁的或光的)、通信接口1414(例如,调制解调器或以太网卡)、显示器1411(例如,crt或lcd)、输入装置1412(例如,键盘)和光标控制。
根据本发明的一个实施例,计算机系统1400通过处理器1407来执行特定操作,该处理器1407执行包含在系统存储器1408中的一个或多个指令的一个或多个序列。可以从诸如静态存储设备1409或磁盘驱动器1410的另一计算机可读/可用介质将这些指令读入到系统存储器1408中。在可选实施例中,可以使用硬连线电路代替软件指令或与软件指令组合以实现本发明。因此,本发明的实施例不限于硬件电路和/或软件的任何特定组合。在一个实施例中,术语“逻辑”应表示用于实现本发明的全部或部分的软件或硬件的任何组合。
本文使用的术语“计算机可读介质”或“计算机可用介质”是指参与向处理器1407提供指令以供执行的任何介质。这种介质可以采用许多形式,包括但不限于非易失性介质和易失性介质。非易失性介质包括例如光盘或磁盘,诸如磁盘驱动器1410。易失性介质包括动态存储器,诸如系统存储器1408。
计算机可读介质的常见形式包括例如软盘、柔性盘、硬盘、磁带、任何其他磁介质、cd-rom、任何其他光学介质、穿孔卡片、纸带、任何其他具有孔的物理介质、ram、prom、eprom、flash-eprom、任何其他存储器芯片或磁带盒、或计算机可以读取的任何其他介质。
在本发明的实施例中,执行指令序列以实践本发明是由单个计算机系统1400执行。根据本发明的其他实施例,通过通信链路1415(例如,lan、ptsn或无线网络)耦接的两个或更多个计算机系统1400可以彼此协调地执行实践本发明所需的指令序列。
计算机系统1400可以通过通信链路1415和通信接口1414发送和接收消息、数据和包括程序(例如,应用代码)的指令。接收的程序代码可以在接收时由处理器1407执行、和/或存储在磁盘驱动器1410或其他非易失性存储中以供稍后执行。计算机系统1400可以通过数据接口1433与外部存储设备1431上的数据库1432通信。
在前述说明书中,已经参考其特定实施例描述了本发明。然而,显而易见的是,在不脱离本发明的更广泛的精神和范围的情况下,可以对其进行各种变型和改变。例如,参考方法动作的特定顺序来描述上述方法流程。然而,可以改变许多所描述的方法动作的顺序而不影响本发明的范围或操作。因此,说明书和附图应被视为示例性的而非限制性意义的。
- 还没有人留言评论。精彩留言会获得点赞!