用于生成多模态数字图像的方法和系统与流程
本发明总体上涉及图像合成,并且更具体地,涉及利用神经网络生成多模态数字图像。
背景技术:
成对图像生成是指生成两种不同模态的一对对应图像,如具有不同属性的面部、采用不同字体的字符,或者彩色图像与对应深度图像。多模态图像生成是指生成一对或更多对不同模态的对应图像。多模态图像的生成具有广泛的应用。例如,多模态图像可以应用于为电影和计算机游戏呈现新颖的对应图像对。例如,在u.s.7876320中描述的方法合成两个或更多个面部图像,或者至少一个面部图像和一个面部图形或面部动画,从而创建虚构的面部图像。
许多方法使用不同模态的图像之间的一对一对应关系来生成多模态数字图像。这些方法的示例包括深度多模态boltzmann法和耦合字典学习法。一些方法可以使用物理模型来生成两种不同模态的对应图像,如图像超分辨或图像去模糊。然而,在一般情况下,确定不同模态图像之间的一对一对应关系是具有挑战性的。
因此,需要在不依赖于训练数据中的不同模态之间的一对一对应关系的情况下生成多模态数字图像。
技术实现要素:
本发明的一些实施方式提供了为生成数字图像的不同模态而联合训练的一组神经网络。例如,一个实施方式提供一组神经网络,所述一组神经网络可以呈现不同模态的一组对应图像,而不需要存在数字图像的不同模态之间的一对一对应关系。
一些实施方式基于以下认识:当神经网络被独立训练以生成数字图像时,所生成的数字图像不相关。然而,通过例如在联合训练期间在神经网络上强制权重共有约束,可以训练神经网络以生成多模态数字图像。例如,一个实施方式利用为生成数字图像的第一模态而训练的第一神经网络和为生成数字图像的第二模态而训练的第二神经网络来生成多模态数字图像。所述第一神经网络的结构和层数与所述第二神经网络的结构和层数相同。而且,所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数相同的参数,并且所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数不同的参数。
这样,所述神经网络的相同结构和数量以及一些参数的相同值强制所生成数字图像中的一些共性,而所述神经网络的其它参数的不同值强制所述模态的差异。例如,在一个实施方式中,所述第一神经网络和所述第二神经网络中的一些层具有相同参数以生成所述数字图像的高级特征,而所述第一神经网络和所述第二神经网络中的其它层具有不同参数以生成所述数字图像的低级特征。典型地讲,所述低级特征从所述高级特性得出。例如,所述高级特征可以是对图像中的对象的类型和配置的描述,而所述低级特征可以是基于对象的类型和配置确定的对象边缘。
因此,一个实施方式公开了一种用于生成多模态数字图像的计算机实现的方法。所述方法包括:利用第一神经网络处理矢量,以生成所述数字图像的第一模态;以及利用第二神经网络处理所述矢量,以生成所述数字图像的第二模态,其中,所述第一神经网络的结构和层数与所述第二神经网络的结构和层数相同,其中,所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数相同的参数,并且其中,所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数不同的参数。所述方法的步骤利用处理器来执行。
另一实施方式公开了一种用于生成多模态数字图像的系统,该系统包括:至少一个非暂时性计算机可读存储器,该非暂时性计算机可读存储器存储为生成所述数字图像的第一模态而训练的第一神经网络和为生成所述数字图像的第二模态而训练的第二神经网络,其中,所述第一神经网络的结构和层数与所述第二神经网络的结构和层数相同,其中,所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数相同的参数,并且其中,所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数不同的参数;以及处理器,该处理器通过利用为生成所述数字图像的第一模态而训练的所述第一神经网络处理矢量,并且利用为生成所述数字图像的第二模态而训练的所述第二神经网络处理所述矢量来生成所述多模态数字图像,并且将所述多模态数字图像存储在所述存储器中。
又一实施方式公开了一种存储有指令的非暂时性计算机可读介质,所述指令在由处理器执行时执行以下步骤:利用为生成所述数字图像的第一模态而训练的第一神经网络处理矢量;以及利用为生成所述数字图像的第二模态而训练的第二神经网络处理所述矢量,其中,所述第一神经网络的结构和层数与所述第二神经网络的结构和层数相同,其中,所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数相同的参数,并且其中,所述第一神经网络的至少一层具有与所述第二神经网络的对应层的参数不同的参数。
附图说明
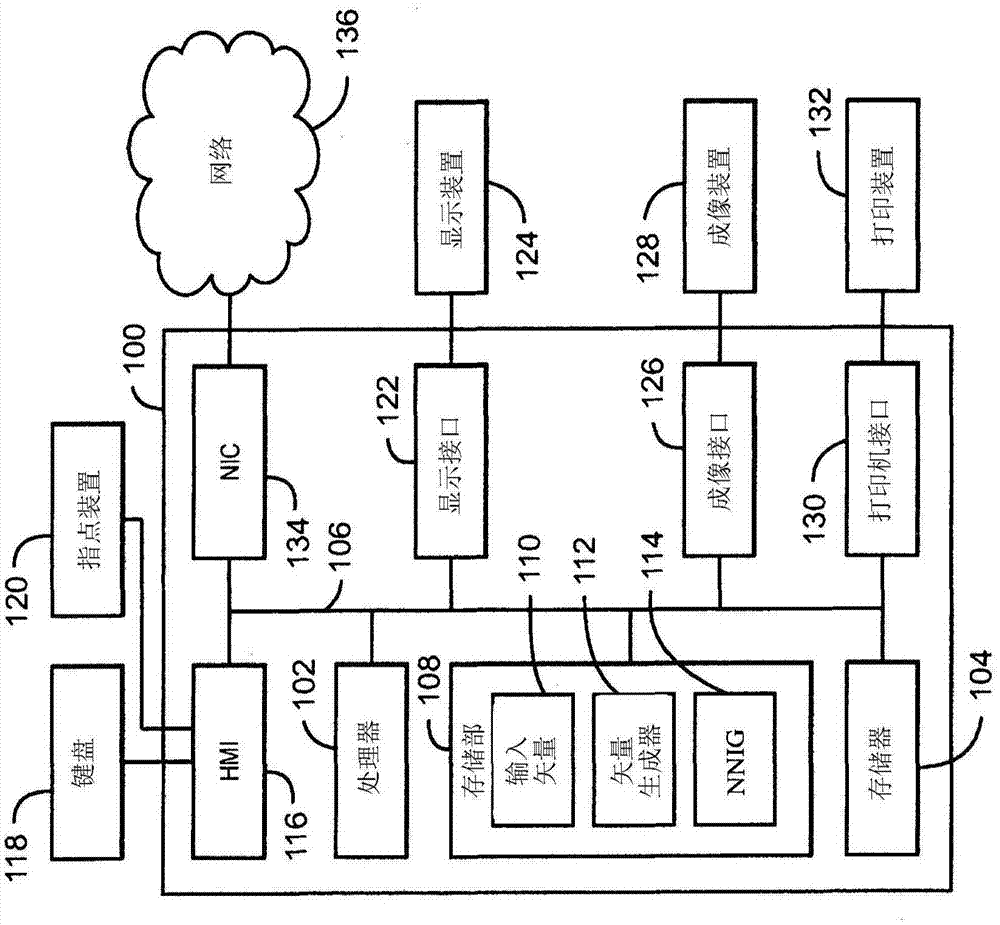
图1是根据本发明的一些实施方式的用于生成多模态数字图像的计算机系统的框图。
图2a是根据一个实施方式的用于生成多模态数字图像的计算机实现的方法的框图。
图2b是根据本发明一个实施方式的用于生成多模态数字图像的结构神经网络的示例性示意图。
图3是一些实施方式使用的神经网络的框图。
图4a是根据一些实施方式的耦合生成对抗网络(cogan)框架的示意图。
图4b是由一些实施方式强制实行的cogan中的权重共有约束的示例。
图5a是一些实施方式使用的神经网络训练的示意图。
图5b是根据一个实施方式的神经网络训练的伪代码。
图5c是根据一个实施方式的训练系统的框图。
图6a是根据一个实施方式的用于生成手写数字的多模态数字图像的生成子网络和判别子网络的结构的示例。
图6b是由图6a的神经网络生成的多模态数字图像的可视化。
图6c是由图6a的神经网络生成的多模态数字图像的可视化。
图7a是根据一个实施方式的用于生成不同属性的多模态面部图像的生成子网络和判别子网络的结构的示例。
图7b是由图7a的神经网络生成的多模态数字图像的可视化。
图7c是由图7a的神经网络生成的多模态数字图像的可视化。
图7d是由图7a的神经网络生成的多模态数字图像的可视化。
图8a是根据一个实施方式的用于生成包括彩色图像及其对应深度图像的多模态数字图像的生成子网络和判别子网络的结构的示例。
图8b是由图8a的神经网络生成的多模态数字图像的可视化。
图9是根据一些实施方式的模态变换的示例。
具体实施方式
图1示出了根据本发明的一些实施方式的用于生成多模态数字图像的计算机系统100的框图。如这里所使用的,多模态数字图像是具有不同模态的结构性数字数据。例如,多模态数字图像可以包括具有第一模态的第一图像和具有第二模态的第二图像。不同的模态可以表示形成数字图像的数据的不同样式或类型。具有不同模态的不同数字图像的示例包括彩色图像、深度图像以及热图像。在一些实施方式中,数字图像是一种格式或不同格式组合的结构性数字数据。例如,数字图像可以包括图像、视频、文本以及声音中的一个或组合。
数字图像的不同模态通常形成表示相同或至少相似结构信息的不同类型的不同图像。为此,形成多模态数字图像的不同模态的图像是相关的。例如,数字图像的第一模态可以是以一种样式描画的文本的第一图像,而数字图像的第二模态可以是以不同样式描画的同一文本的第二图像。例如,数字图像的第一模态可以是人戴眼镜时的面部的第一图像,而数字图像的第二模态可以是该人不戴眼镜时的同一面部的第二图像。例如,数字图像的第一模态可以是包括用于表示场景的每个像素的颜色信息的图像,而数字图像的第二模态可以是包括用于表示同一场景的每个像素的深度信息的图像。
计算机系统100包括被配置成执行所存储的指令的处理器102以及存储可由处理器执行的指令的存储器104。处理器102可以是单核处理器、多核处理器、计算集群,或者任何数量的其它配置。存储器104可以包括:随机存取存储器(ram)、只读存储器(rom)、闪速存储器或任何其它合适的存储器系统。处理器102通过总线106连接至一个或更多个输入和输出装置。
计算机系统100包括用于生成多模态数字图像的神经网络图像生成器(nnig)114。nnig114是利用为生成多模态数字图像而训练的一组神经网络(例如,第一神经网络和第二神经网络)实现的。例如,第一和第二神经网络可以接受相同的输入并生成多模态数字图像,其中,第一神经网络生成数字图像的第一模态,而第二神经网络生成数字图像的第二模态。nnig114可以存储在系统100的存储器中。
计算机系统100还可以包括适配于存储由nnig114使用的补充数据和/或软件模块的存储装置108。例如,存储装置108可以存储由nnig114使用以生成多模态数字图像的输入矢量110。另外或另选地,存储装置108可以存储用于生成矢量110的矢量生成器112。例如,矢量生成器112可以利用处理器102或任何其它合适的处理器来实现。矢量110可以具有不同值甚或任意值。例如,矢量生成器112可以利用概率分布来随机生成矢量的元素。存储装置108还可以存储nnig114的结构和参数。存储装置108可包括:硬盘驱动器、光学驱动器、拇指驱动器、驱动器阵列,或其任何组合。
计算机系统100内的人机接口116可以将系统连接至键盘118和指点装置120,其中指点装置120可以包括鼠标、轨迹球、触摸板、操纵杆、指点棒、针笔或触摸屏等。计算机系统100可以通过总线106链接至适配为将系统100连接至显示装置124的显示接口122,其中,显示装置124可以包括计算机监视器、摄像机、电视机、投影仪或移动装置等。
计算机系统100还可以连接至成像接口126,成像接口126适配于将系统连接到成像装置128。成像装置128可以包括摄像机、计算机、扫描仪、移动装置、网络摄像头或其任意组合。打印机接口130也可以通过总线106连接至计算机系统100,并适配于将计算机系统100连接至打印装置132,其中,打印装置132可以包括液体喷墨打印机、固体墨水打印机、大型商业打印机、热敏打印机、uv打印机或热升华打印机等。网络接口控制器134适配于通过总线106将计算机系统100连接至网络136。多模态数字图像可以在显示装置、成像装置和/或打印装置上呈现。多模态数字图像可以通过网络136的通信信道传送,和/或存储在计算机的存储系统108内以供存储和/或进一步处理。
图2a示出了根据本发明一个实施方式的用于生成多模态数字图像的计算机实现的方法的框图。该方法利用第一神经网络240处理220矢量210以生成数字图像的第一模态225,并且利用第二神经网络250处理230矢量210以生成数字图像的第二模态235。该方法可以利用nnig114来执行,并且利用计算机系统100的处理器(例如,处理器102)来执行。
一些实施方式基于以下认识:当神经网络被独立训练以生成图像时,所生成的图像不相关。然而,通过在神经网络中强制权重共享约束,并按每个模态给出足够的训练图像,可以联合训练多个神经网络以生成多模态数字图像。
图2b示出了被训练以生成数字图像的第一模态的第一神经网络240的结构和被训练以生成数字图像的第二模态的第二神经网络250的结构的示例性示意图。第一神经网络的结构(例如,层数和层间连接)与第二神经网络的结构相同。另外,第一神经网络中的至少一层具有与第二神经网络中的对应层的参数相同的参数。然而,第一神经网络中的至少一层具有与第二神经网络中的对应层的参数不同的参数。在图2b的示例中,示出了层231、232、233、234、235及236。对应层231、232及233具有相同的参数,而对应层234、235及246具有不同的参数。
典型地讲,具有相同参数的层是用于实施图像的高级特征的顶层。例如,这两个网络被联合训练,同时为第一神经网络和第二神经网络中的若干顶层实施相同的参数。这样,所述网络的相同结构和相同参数强制所生成图像中的一些共性,而所述网络中的至少一些层的不同参数实施不同的模态。例如,在一个实施方式中,第一和第二神经网络中具有相同参数的层生成数字图像的高级特征,并且第一和第二神经网络中具有不同参数的层生成数字图像的低级特征。典型地讲,所述低级特征由所述高级特性导出。例如,所述高级特征可以是对图像中的对象的类型和配置的描述,而所述低级特征可以是基于所述对象的类型和配置确定的对象的边缘。
耦合生成对抗网络(coupledgenerativeadversarialnet)
本发明的一些实施方式使用耦合生成对抗网络(cogan)框架来训练nnig114,其可以呈现多模态数字图像,而不需要存在训练数据集中的一对一对应关系。该框架基于用于图像生成的生成对抗网络(gan)。cogan框架包括至少一对gan。
训练每个gan以在一个域中生成图像,并且cogan的框架强制每个gan生成至少在一个方面彼此相关的不同图像。例如,通过强制解码两个gan中的高级信息来共享网络连接权重的层,这两个gan以相同的方式解码高级语义。然后,解码低级可视信息的层将共享语义映射至不同模态的图像,以针对每种模态混淆判别子网络(discriminativesubnetwork)。通过在生成子网络中强制权重共享约束,并在每个域中给出足够的训练图像,训练cogan以获得多种模态中的对应关系。
为此,在一些实施方式中,利用对抗训练过程来训练第一神经网络和第二神经网络中的至少一个或两者。例如,第一神经网络中的第一生成子网络和第一判别子网络以及第二神经网络中的第二生成子网络和第二判别子网络可以进行联合训练以最小化极小极大目标函数(minimaxobjectfunction)。
生成对抗网络
图3示出了由一些实施方式用于训练nnig114的gan的框图。gan框架包括两个子网络,生成子网络301和判别子网络302。生成子网络301的目的是根据随机输入305(例如,矢量210)合成或生成类似于训练图像310的图像300。判别子网络302的目的是区分303图像310与合成图像300。生成子网络和判别子网络二者可以实现为多层感知器,即,前馈神经网络或多层卷积神经网络。
从形式上看,设dgan为训练数据集,其中,x从数据分布x:px中抽取每个样本x。设z为维度d的随机矢量。在一个实施方式中,z从多维均匀分布抽取z。另选实施方式使用不同的分布,如多维正态分布。设g和f分别是生成子网络和判别子网络。函数g采取z作为输入,并输出具有与x相同支持的随机矢量g(z)x。将g(z)的分布表示为pg。函数f估计输入从px抽取输入的概率。值得注意的是,在x来自px时,f(x)=1,而在x来自pg时,f(x)=0。
通过类推的方式,gan框架对应于极小极大二元博弈(minimaxtwo-playergame),并且可以通过求解下式来联合训练生成子网络和判别子网络:
其中,值函数vgan由下式给出
vgan(f,g)=ex:px[-logf(x)]+ez:pz[-log(1-f(g(z)))]。(2)
使用具有随机梯度下降的反向传播算法来训练网络f和g。在一些实施方式中,通过交替以下两个梯度更新步骤来求解式(1):
步骤1:
步骤2:
其中,θf和θg分别是网络f和g的可学习网络参数,λ是学习速率,并且上标t指示梯度更新的迭代次数。
如果赋予f和g足够的容量和足够的训练迭代次数,分布pg趋同于px。即,根据随机种子z,网络g可以合成图像g(z),其与从真实数据分布px抽取的相似。为此,在训练之后,生成子网络301可以形成nnig114的一部分。
耦合生成对抗网络
图4a示出了根据一些实施方式的cogan框架。cogan包括一对生成对抗网络:gan1和gan2。各个生成性对抗网络具有可以合成多个图像的生成子网络和可以对输入信号是真实图像还是合成图像进行分类的判别子网络。gan1和gan2的生成子网络由g14011和g24012表示,而gan1和gan2的判别子网络由f14021和f24022表示。所述子网络可以实现为多层感知器。
生成子网络4011被训练为根据输入矢量305生成第一模态的图像3001,并且生成子网络401被训练为根据输入矢量305生成第二模态的图像3002。为了便于训练,判别子网络4021区分4031图像3001与第一模态的训练图像311。类似地,判别子网络4022区分4032图像3002与第一模态的训练图像312。
图4b示出了耦合生成性对抗网框架中的权重共享约束的示例。在cogan框架中,生成子网络g1和g2的底层420(即,对应于高级语义信息的层)的权重被约束为具有相同的权重,即,相同的参数。在该示例中,对应于判别子网络f1和f2的高级语义信息的顶层410的权重被共享。
值得注意的是,在训练阶段期间主要甚或独占地使用生成子网络和判别子网络。在训练生成子网络之后,可以丢弃判别子网络,并且生成子网络成为第一神经网络240或第二神经网络250。
这种权重共享方案强制gan1和gan2合成成对的对应图像,其中,在两个图像共享相同的高级语义信息但具有不同的低级实现的意义上来定义对应关系,诸如图像及其旋转或者人带眼镜时面部或者同一人不带眼镜时的面部。例如,cogan可以用于合成图像及其旋转或者合成有眼镜的面部和没有眼镜的同一面部。通过简单地添加更多gan,可以扩展cogan框架以处理多个模态的联合图像生成。
生成子网络
设ddgan为训练数据集,其中,从第一模态的数据分布
在一个实施方式中,g1和g2两者被实现为多层感知器并且可以表达为
其中,
通过多层感知操作,生成子网络逐渐将信息从更抽象的概念解码成更具体的细节。底层对高级语义信息进行解码,而顶层对低级细节信息进行解码。应注意,该信息流不同于用于分类任务的判别性深度神经网络。在判别子网络中,底层提取低级特征,而顶层提取高级特征。
因为不同模态的对应图像共享相同的高级语义信息,所以一些实施方式强制g1和g2的底层420具有相同结构并共享权重。即,
其中,k是共享层的数量。这种权重共享约束强制由生成网络g1和g2以相同方式解码高级信息。一些实施方式不对顶层施加额外约束。允许所述约束以学习按各个模态的最佳方式来具体化高级语义信息。
判别子网络
判别子网络的推导类似于针对生成子网络的推导。设f1和f2为gan1和gan2的判别子网络,它们可以被实现为多层感知器:
其中,
判别子网络将输入图像映射至概率得分,估计该输入是从训练数据分布中抽取出的概率。针对这些子网络,判别子网络的底层提取低级特征,而顶层提取高级特征。因为输入图像是以两种不同的模态实现相同的高级语义,所以一些实施方式强制判别子网络f1和f2具有相同的顶层410,这是通过经由下式共享两个判别子网络的顶层的权重来实现
其中,l是共享层的数量。
训练
通过类推的方式,cogan的训练也对应于由下式给出的受约束的极小极大博弈
其中,值函数vdgan为
在该博弈类推中,存在两队,每队有两个选手。生成子网络g1和g2形成一队并一起工作,以合成两个不同模态的一对对应图像,从而混淆判别子网络f1和f2。另一方面,判别子网络尝试将从相应模态的训练数据分布中抽取的图像与从相应生成子网络抽取的图像区分开。该协作根据权重共享约束建立。与gan框架类似,可以通过利用交替梯度更新方案的反向传播算法来实现生成子网络和判别子网络的训练。
在cogan博弈中,有两队,每队有两个选手。生成子网络g1和g2形成一队并一起工作,以按两个不同模态合成一对对应图像,从而分别混淆判别子网络f1和f2。判别子网络尝试将从相应模态的训练数据分布中抽取的图像与从相应生成子网络中抽取的图像区分开。该协作根据权重共享约束建立。与gan框架类似,可以通过利用交替梯度更新的反向传播算法来实现生成子网络和判别子网络的学习。
图5a示出了本发明一些实施方式所使用的神经网络训练的示意图。训练510使用不同模态的图像501和502的训练集来生成nnig的参数520。值得注意的是,图像501不必对应于图像502。通常来说,训练人工神经网络包括:考虑到训练集,向人工神经网络应用训练算法(有时称为“学习”算法)。训练集可以包括一组或更多组输入以及一组或更多组输出,其中,每组输入对应于一组输出。训练集中的一组输出包括当对应的一组输入被输入至人工神经网络并接着按前馈方式操作人工神经网络时希望该人工神经网络生成的一组输出。训练神经网络涉及计算参数,例如,与人工神经网络中的连接相关联的权重值。
图5b示出了根据本发明一个实施方式的训练510的伪代码。在cogan培训期间,独立地从边缘分布中抽取训练样本,以便不依赖于来自其中一对一对应关系可用的联合分布的样本。这样,cogan训练生成子网络,所述生成子网络可以按对应关系合成数字图像的不同模态,但预先没有对应关系。从边缘学习联合分布的能力可以在很大程度上减轻用于成对图像生成的训练数据收集的负担,因为即使获取两个不同模态的对应图像也可能非常困难。
图5c示出了根据本发明一个实施方式的训练系统的框图。该训练系统包括通过总线22连接至只读存储器(rom)24和存储器38的处理器。该训练系统还可以包括用于向用户呈现信息的显示器28以及多个输入装置,输入装置包括键盘26、鼠标34以及可以经由输入/输出端口30附接的其它装置。还可以附接其它输入装置,诸如其它指点装置或语音传感器或图像传感器。其它指点装置包括:平板计算机、数字小键盘、触摸屏、触摸屏覆层、轨迹球、操纵杆、光笔、拇指轮等。i/o30可以连接至通信线路、磁盘存储部、输入装置、输出装置或其它i/o设备。存储器38包括显示缓冲器72,显示缓冲器72包含用于显示屏的像素强度值。显示器28周期性地将显示这些值的像素值从显示缓冲器72读取到显示屏上。像素强度值可以表示灰度级或颜色。
存储器38包括:数据库90、训练器82、nnig114、预处理器84。数据库90可以包括:历史数据105、训练数据、测试数据92。数据库还可以包括来自使用神经网络的操作模式、训练模式或保留模式的结果。上面已经详细描述了这些部件。
存储器38中还示出了操作系统74。操作系统的示例包括:aix、os/2、dos、linux以及windows。存储器38中示出的其它部件包括设备驱动器76,设备驱动器76解释由诸如键盘和鼠标的装置生成的电信号。在存储器38中还示出工作存储区78。工作存储区78可以由存储器38中所示的任何部件使用。工作存储区可以由神经网络101、训练器82、操作系统74以及其它功能使用。工作存储区78可以在部件之间和部件内分区。工作存储区78可以被用于通信、缓冲、临时存储,或者在程序运行时存储数据。
示例
本公开中提供的若干示例例示了由一些实施方式利用cogan框架训练的nnig可以按完全无监督的方式生成不同种类的多模态数字图像,并且不依赖于训练数据中的不同模态之间的一对一对应关系。
数字的生成
图6a示出了根据一个实施方式的用于生成手写数字的多模态数字图像的生成子网络和判别子网络的结构610的示例。该实施方式使用训练数据集中的60000个训练图像来训练cogan以生成两个不同模态的数字,例如包括生成数字及其边缘图像和/或生成数字及其负像(negativeimage)。例如,第一模态可以包括手写数字图像,而第二模态可以包括它们的对应边缘图像。在图6b中示出了由一些实施方式生成的多模态数字图像的例子。在另一示例中,这两个模态分别包括手写数字图像和它们的负像。在图6c中示出了由一些实施方式生成的多模态数字图像的例子。
在图6a的示例中,两个生成子网络具有相同结构;两者都有5层,并且完全卷积。卷积层的步幅是分数的。子网络还采用批量归一化层(batchnormalizationlayer)和参数化整流线性单元层(parameterizedrectifiedlinearunitlayer)。除了负责生成图像输出的最后卷积层之外,生成子网络共享其它所有层的参数。判别子网络使用lenet的变体。针对判别子网络的输入是包含来自生成子网络的输出图像和来自两个训练子集的图像的多个批量(每个像素值被线性归一化成0到1)。一个实现使用自适应矩随机梯度下降(adam:adaptivemomentstochastic-gradientdescent)法来训练cogan达25000次迭代。
面部的生成
图7a示出了根据一个实施方式的用于生成具有不同属性的多模态面部图像的生成子网络和判别子网络的结构710的示例。该实施方式训练了几个cogan,其中每个都用于生成具有属性的面部图像和没有该属性的对应面部图像。训练数据集包括10177人、202599个面部图像。训练数据集涵盖了大的姿势变化和背景杂斑(backgroundclutter)。每个脸部图像都有40个属性,包括眼镜、微笑以及金色头发。具有属性的面部图像形成数字图像的第一模态;而没有该属性的那些面部图像形成第二模态。这两种模态中没有重叠的面部。在这个示例中,生成子网络和判别子网络都是七层深度卷积神经网络。
图7b示出了具有金色头发和深色头发的面部的多模态图像的例子。图7c示出了笑脸和非笑脸的多模态图像的例子。图7d示出了具有眼镜和没有眼镜的面部的多模态图像的例子。
一些实现在100维输入空间中随机采样两个点,并且随着从一点到另一点将所呈现的面部的变形可视化。值得注意的是,cogan生成成对的相应面部,类似于同一个人的具有不同属性的相应面部。随着在空间中行进,这些面部可以逐渐变形,例如,从一个人到另一个人。这种变形对于两种模态来说都是一致的,其验证了cogan框架。
rgb图像和深度图像的生成
图8a示出了根据一个实施方式的用于生成包括彩色图像及其对应深度图像的多模态数字图像的生成子网络和判别子网络的结构的示例。注意,所呈现的图像对具有两个不同模态。训练数据集具有rgbd图像,其具有由来自不同视点的传感器捕捉的300个对象的登记的彩色图像和深度图像。第一子集中的彩色图像用于训练gan1,而第二子集中的深度图像被用于训练gan2。两个子集中没有对应的深度图像和彩色图像。数据集中的图像具有不同的分辨率。
图8b示出了多模态彩色图像和深度图像的例子。所呈现的深度剖面平滑变形,类似于真实物体。
应用
除了为电影和游戏制作呈现多模态数字图像外,所公开的cogan框架能够应用于模态变换和模态自适应任务。设x1为第一模态的图像。模态变换任务是关于找到第二模态的对应图像x2,使得联合概率密度p(x1,x2)最大化。设l为测量两个图像之间的差异的损失函数。如果给定经训练的生成子网络g1和g2,该变换通过求解下式来实现
在找到z*之后,可以应用g2,以获得变换后的图像x2=g2(z)。
图9示出了根据一些实施方式的模态变换的示例。例如,图像910被变换成图像920,并且图像930被变换成图像940。通过利用欧几里得距离(l2损失)函数和有限记忆bfgs(l-bfgs或lm-bfgs)优化法来计算那些例子。
模态自适应涉及使以一种模态训练的分类器适应另一种模态。为此,一个实施方式将cogan框架用于无监督模态自适应任务。设d1和d2为任务a中使用的第一模态和第二模态的数字图像子集。假设d1中的图像的类别标签是已知的,但d2中的图像的类别标签是未知的。一个目标是使利用d1训练的数字分类器自适应以对第二模态的数字进行分类。可以通过联合求解在d1中使用图像和标签的第一模态的数字分类问题以及在d1和d2两者中使用图像的cogan学习问题来训练cogan。这生成两个分类器:针对第一模态的
另外或另选地,一个实施方式通过将混合美国国家标准和技术研究所数据库(mnist)测试图像变换成其对应的边缘图像来创建模态转换。随着应用c1来分类边缘图像,分类准确度因模态转换而降低至87.0\%。然而,在应用c2以对第二模态的图像进行分类时,获得了96.7\%的分类准确度。该准确度接近在第一模态中获得的准确度。这是令人惊讶的,因为第二模态中的标签以及两种模态之间的样本对应关系都未被使用。
本发明的上述实施方式可以按许多方式中的任一种来实现。例如,这些实施方式可以利用硬件、软件或其组合来实现。当按软件来实现时,软件代码可以在任何合适处理器或处理器集合上执行,而不管设置在单一计算机中还是分布在多个计算机当中。这种处理器可以被实现为集成电路,其中在集成电路组件中具有一个或更多个处理器。然而,处理器可以利用采用任何合适格式的电路来实现。
而且,本发明的实施方式可以被具体实施为已经提供了示例的方法。作为该方法的一部分执行的动作可以按任何合适方式来安排。因此,即使在例示性实施方式中被示出为顺序动作,也可以构造按与所例示相比不同的次序来执行动作的实施方式,其可以包括同时执行一些动作。
在权利要求书中使用诸如“第一”、“第二”的一般用语来修改权利要求元素不独立地暗示一个权利要求部件的任何优先级、优先权,或次序超过执行方法的动作的另一或临时次序,而是仅仅被用作用于区分具有特定名称的一个权利要求元素与具有相同名称(但供普通术语使用)另一元素的标记,以区分这些权利要求元素。
- 还没有人留言评论。精彩留言会获得点赞!