从不同的源收集熵的制作方法
本申请要求2016年9月16日提交的美国临时申请no.62/395961和2016年8月19日提交的美国临时申请no.62/377488的权益,这些申请的全部内容出于所有目的通过引用并入在此。本申请总体上涉及电数字数据处理,具体地涉及采集熵以用于对随机数或伪随机数发生器播种(seed)或其他目的的技术。
背景技术:
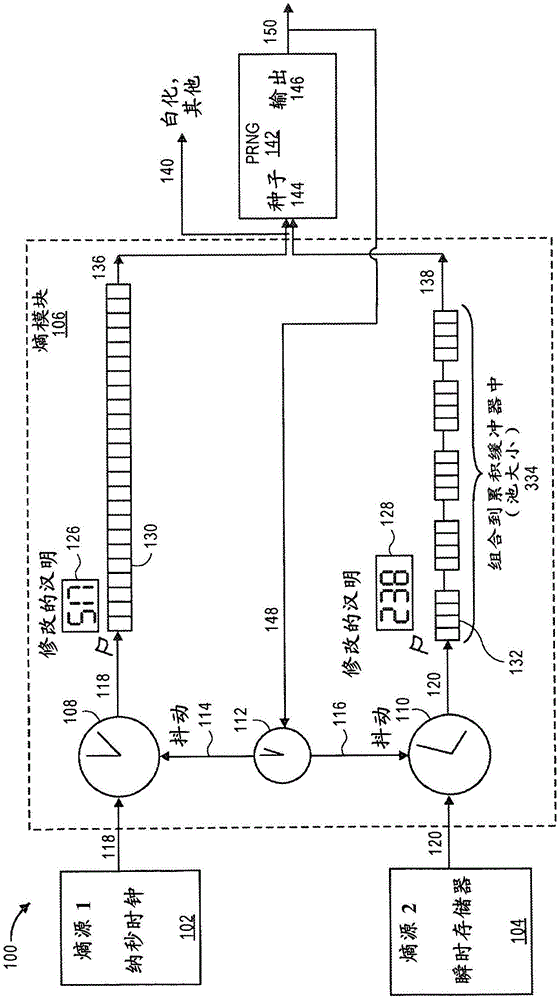
:openssl熵模型在一些领域中被认为是较弱的。在其目前状态下,它将在任何新的联邦信息处理标准(fips)证书上导致无熵警告。而且,国家标准技术局(nist)对作为fips验证的一部分的熵源更感兴趣,并且很可能的是在未来的某个时刻将强制执行合理的熵模型。值得注意的是,一些平台(尤其是操作系统)上的openssl的熵比其他平台上的openssl的熵好得多。特别是oracle融合中间件和数据库组织在各种平台上通常需要高级别的安全性。openssl中的改进的熵也可以有益于其他组织。在fips模式下,openssl没有内熵(internalentropy)。它完全依赖于提供其全部熵的托管应用。虽然存在察看一些东西已经被提供的检查,但是openssl本身并不关注熵的质量,并且不对内部的伪随机数发生器(prng)重新播种——这些作为问题留给用户。由于用户变化,供应的熵的质量也将变化。有可能用户将没有足以适当地评价熵源的时间或专门知识。在fips模式之外,openssl从/dev/urandom读取32个字节(256个比特)的熵,并且使用该熵作为内部prng的种子。名义上,它永远不对prng重新播种,但是用户可以调用应用编程接口(api)来这样做。ntst将/dev/urandom评为提供零熵,但是在实践中它应比什么都没有要好些。openssl在其整个寿命内具有单个全局伪随机数发生器——不管连接的数量或线程的数量如何。这意味着openssl在prng被危机的情况下几乎不提供前向安全性。相比之下,其他tls(传输安全层)包维护了许多个随机数发生器(每个随机数发生器是从全局随机数发生器播种的),这提供这样的保护。openssl版本1.1尝试在内部产生某个熵,但是它是在自组织(adhoc)的基础上,并且似乎没有做出对产生的数量或质量进行定量的尝试。熵模型的其余部分与openssl版本1.0相比没有变化。因为openssl的默认熵模型不重新播种并且没有隔离其伪随机数发生器流,所以危及prng的攻击者可以破坏所有的后续连接。理论上,资源充足的攻击者可以存储加密的通信,花费一年的时间来破坏秘密通信的第一部分,然后能够从该点向前读取一切。这样的情报滞后在其预期的保密寿命内可能是良好的。换句话说,重新播种可能是前向保密所必需的。在本领域中需要prng的更好的、更多熵的播种以用于加密和其他应用。技术实现要素:总体上描述了用于在计算装置中为伪随机数发生器和熵的其他消费者产生熵的方法、装置和系统。多个软件计时器被设置为重复地触发计时器事件。每个计时器对应于不同的熵源,不管是硬件源、还是软件源。在计时器事件期间,从熵源收集或采集预定数量的比特。所述预定数量基于来自熵源的每个比特预期的熵量,并且可以从理论上推导或者凭经验测量。所述比特作为种子被呈送到伪随机数发生器。其他的一个熵源或多个熵源以相同的方式被轮询。可以基于伪随机数发生器的输出来使计时器的频率抖动。熵比特可以在以较大的组块发送到伪随机数发生器之前累积到缓冲器中。本申请的一些实施例涉及一种用于在计算装置中产生熵的方法。该方法包括:对于第一频率设置重复的第一计时器;对于第二频率设置重复的第二计时器;以第一频率从第一熵源收集预定数量的第一比特,所述预定数量基于可归于第一熵源的每个比特的熵量;将第一比特呈送给伪随机数发生器;以第二频率从第二熵源采集指定数量的第二比特,所述指定数量基于可归于第二熵源的每个比特的熵量;并且将第二比特呈送给伪随机数发生器。第一比特和第二比特可以用于对伪随机数发生器播种。第一频率和第二频率可以是彼此不同的。此外,它们可以是不同的,并且不是彼此的整数倍(即,谐波)。可以周期性地调整第一频率。可以基于伪随机数发生器的输出来对它进行调整。调整可以是加上或减去第一频率的高达5%。第一频率调整的周期性可以是随机化的。第一频率调整的周期性可以在5秒至60秒的范围内。可以基于伪随机数发生器的输出来周期性地调整第二频率。所述方法可以还包括:在收集时将第一比特接纳到累积缓冲器中;并且当累积缓冲器变满时,将第一比特从累积缓冲器呈送给伪随机数发生器,从而提供比单次收集的第一比特中更多的突发熵。所述方法可以还包括:计算连续的所收集的第一比特之间的汉明(hamming)距离;并且基于所计算的汉明距离超过最小值,将所收集的第一比特接纳到累积缓冲器中。所述方法可以包括:将连续收集的第一比特之间的汉明距离合计为归于累积缓冲器的内容的熵的累积值;并且将熵的累积值提供给伪随机数发生器。所述方法可以包括在下一次收集之前清空累积缓冲器。累积缓冲器可以是第一累积缓冲器,所述方法可以还包括:在采集时将第二比特接纳到第二累积缓冲器中,第二累积缓冲器具有与第一累积缓冲器的大小不同的大小;并且当第二累积缓冲器变满时,将第二比特从第二累积缓冲器呈送给伪随机数发生器。第一频率或第二频率可以选自由以下组成的组:每0.1287秒一次、每0.13秒一次、每0.1370秒一次、每0.15秒一次、每0.25秒一次、每0.715秒一次、每0.751秒一次、每0.753秒一次、每1.13秒一次、每1.27秒一次、每1.6626秒一次、每2秒一次、每2.222秒一次、每2.2427秒一次、每4.4秒一次、每4.9秒一次、每5.9秒一次、每9.81秒一次、每10.000秒一次、每11.913秒一次以及每15秒一次。第一熵源或第二熵源可以选自由以下组成的组:瞬时的或累积的中央处理单元(cpu)使用;物理的或虚拟的存储器使用;网络通信量;高分辨率时钟的最低有效时间值;输入/输出(io)统计;intelx86rdrand指令;intelx86rdseed指令;intel安腾(itanium)ar.itc寄存器;unix或linux/dev/random文件;unix或linux/dev/urandom文件;openbsd、solaris或linuxgetentropy系统调用;solaris或linuxgetrandom系统调用;microsoftwindowscryptgenrandom函数;linux/proc/diskstats文件;linux/proc/interrupts文件;linux/proc/meminfo文件;linux/proc/net/dev文件;linux/proc/timer_list文件;linux/s390/dev/prandom文件;bsdunix/dev/srandom文件;microsoftwindowswin_processes模块;以及用户接口信息源。所述方法可以包括通过伪随机数发生器基于第一比特或第二比特来产生随机数。第一计时器或第二计时器的设置可以包括进行系统调用。所述预定数量的第一比特的收集和所述指定数量的第二比特的采集可以在相应计时器的引发事件时发生。伪随机数发生器可以被配置为产生数字、字符和其他符号。一些实施例可以涉及一种用于在伪随机数发生器中播种熵的方法。所述方法可以包括:设置不同频率的异步计时器;根据异步计时器中的第一计时器从第一熵源收集预定数量的第一比特;计算连续的所收集的第一比特之间的汉明距离;基于汉明距离超过最小值,将第一比特接纳到第一累积缓冲器中;将连续收集的第一比特之间的汉明距离合计为归于第一累积缓冲器的内容的熵的累积值中;将第一累积缓冲器的内容呈送给伪随机数发生器;根据异步计时器中的第二计时器从第二熵源采集指定数量的第二比特;将第二比特接纳到第二累积缓冲器中,第二累积缓冲器具有与第一累积缓冲器的大小不同的大小;并且将第二累积缓冲器的内容呈送给伪随机数发生器。所述异步计时器可以具有不是彼此谐波的不同频率。所述方法可以包括使异步的计时器的频率抖动。还有的其他的实施例涉及执行上面提及的方法的系统以及采用或存储用于上述方法的指令的机器可读有形存储介质。本
发明内容并非意图标识要求保护的主题的关键的或必要的特征,也非意图孤立地用来确定要求保护的主题的范围。主题应参照本专利的整个说明书的适当的部分、任何一个或所有的附图以及每个权利要求来理解。附图说明图1例示了根据实施例的熵模块。图2例示了根据实施例的挫败偷听者。图3是根据实施例的序列图。图4是根据实施例的具有两个熵源采样频率的时序图。图5是例示了根据实施例的处理的流程图。图6是例示了根据实施例的处理的流程图。图7例示了其中可以实现本发明的各种实施例的示例性计算机系统。具体实施方式实施例涉及被设计为针对不同的一组平台整合许多熵源的框架的熵模块。所述实现仔细考虑了如何以安全的方式合并具有各种熵产生速率的多个源。所述设计平衡了对于大量质量熵的需求与对于良好性能和小的存储器占用空间的要求。它被设计为针对不同的一组平台整合许多熵源的框架。所述实现仔细考虑了如何以安全的方式合并具有各种熵产生速率的多个源。对于设计重要的是对于围绕熵的信任问题的考虑。附图图1例示了系统100中的熵模块。在熵模块106中,计时器108和110被设置为周期性地分别从第一熵源102或第二熵源104轮询或者以其他方式收集或采集熵(即,随机的比特或如本领域中已知的其他形式)。对于熵源的轮询的频率是彼此不同的。一个频率可以是在采集之间为0.751秒,另一个频率可以是在采集之间为3.3秒。当然可以提供多于两个的熵源。例如,可以对三个、四个、五个或十个、二十个或数百个熵源进行轮询。事件计时器可以与每个熵源相关联以使得代码执行为在计时器事件发生时从熵源接收数据。其中至少两个计时器的频率不是彼此的谐波。也就是说,一个计时器的频率不是另一个计时器的整数倍。例如,计时器可以为1/1.27秒和1/0.715秒的频率。然而,它们不是相差正好两倍的1/1.127秒和1/2.254秒。如果来自第一熵源102的熵118与来自第一熵源102的前一个熵相比的修改的汉明距离126(参看下文)小于阈值数,则当前的熵被拒绝。如果它大于或等于阈值,则当前的熵被作为比特130从第一熵源102接受。该熵在收集时立即被作为比特136转发给伪随机数发生器(prng)142。如果来自第二熵源104的熵120与来自第二熵源104的前一个熵相比的修改的汉明距离128小于阈值数(其可以不同于用于第一熵源的阈值数),则它被拒绝。否则,它被作为比特132接纳到累积缓冲器334中。只有在累积缓冲器334满了之后,累积缓冲器334才被作为比特138清仓到prng142。累积缓冲器在例如分配给缓冲器的整个存储器填满比特时可以是“满的”,计数越过某个数,指向下一个未使用的比特的指针超过指定的缓冲器大小,或者如本领域中已知的其他方式那样。在一些实施例中,来自熵模块的比特可以被转发140给白化算法(whiteningalgorithm),而不是用于prng142的种子存储器位置144。prng142输出146向各种使用(包括加密密钥产生、应用程序等)发送随机化比特150。prng输出146也作为随机比特148、按计时器112确定的间隔被轮询。随机比特148用于增加或减小计时器108和110或者以其他方式使计时器108和110抖动。抖动可以是加上或减去几个百分点,诸如±1%、2%、3%、4%、5%、7%、10%、15%、20%、25%、30%、33%或如本领域中作为计时器的“抖动”所理解的其他百分点。这使得熵源轮询计时器108和110的频率改变。随机比特被加到计时器的下一次轮询的时间或者被从计时器的下一次轮询的时间减去。prng的输出可以是数字789(来自0至32767的范围)。如果时间被抖动±12%的最大值,则下一个周期可以被调整((789/32767)*2-1)*012*norminal_interval_periodo图2例示了典型的使用情况下的挫败偷听者。熵源202被确定的实体危及。例如,基于硬件的熵发生器202的制造商可能已经给予了政府表明熵发生器稍有偏斜的数据。政府可以能够通过司法手段或其他手段来主动地迫使熵发生器偏斜。熵源204没有被危及。它可以由危及熵发生器202的、在政府管辖权之外的实体制造。熵源按计时器208和210设置的迥然不同的频率或周期被向prng242轮询。prng242被计算机260用来创建加密密钥252。加密密钥252用于对文档254进行加密。加密的文档254经由网络258发送给计算机262。计算机262使用解密密钥256对文档254进行解密。解密密钥256与加密密钥252可以是相同的或者可以是不相同的。尽管偷听者可以拦截网络258上的文档254,但是偷听者不能对该文档进行解码。加密密钥252是由来自prng242的随机比特构成的。但是在生成密钥时,prng242是部分从未被危及的熵源204播种的。即使加密密钥是由从被危及的熵源(诸如源202)产生的比特构成的,并且偷听者能够对文档进行解码,下一个加密密钥也不可能从被危及的源产生。因此,只破解了一个熵源的偷听者不能自由地且充分地清楚从计算机260发送的每一条消息。就如图所示的两个熵源来说,偷听者只能在来自未被危及的源204的种子被使用之前期待对来自计算机的消息进行解码。该种子向从那一刻起的处理增加了新的熵。偷听者必须花费时间和资源来危及另一个源。从多于两个的熵源采集熵可以进一步使偷听者的努力复杂化。增加熵源的数量将使偷听者必须危及的源的数量增加,从而降低被拦截的消息可以被读取的概率。使各种熵源的收集/采集计时器抖动将进一步使偷听者的任务复杂化。偷听者将难以知道每个熵源何时将被播种。如果加密密钥按每10秒加上或减去某个抖动的时间被改变,则在抖动时间内加密的任何消息或消息的一部分不保证被偷听者适当地解密。虽然在文本通信中可能容易知道消息何时没有被适当地解密,但是在比特图中的数字或细节的表格中确定可能更加困难。图3是关于系统300的序列图,其中从上到下对应于时间过去。在第一时间,源302将熵318a供应给熵收集器306。该熵作为种子336a被立即转发给prng342。按接下来的周期性时间间隔,以频率308,来自熵源302的熵318b、318c、318d、318e、318f、318g、318h等作为336b、336c、336d、336e、336f、336g、336h等被转发给prng342。与来自熵源302的熵收集结果交织的是来自熵源304的采集结果(即,其他收集结果)。在第一时间,熵源304将熵320a供应给熵收集器306。该熵被缓冲在累积缓冲器334中。按接下来的周期性时间间隔,以频率310,来自熵源306的熵320a、320b、320c、320d和320e被存储在累积缓冲器334中。当累积缓冲器334满了时,在当熵320e被接纳到累积缓冲器334中时的示例性情况下,缓冲器作为种子338被发送或推送到prng342。累积缓冲器334然后被清除或者被以其他方式重置。在事件源302被危及时,那么攻击者可以能够读取由prng342的输出加密的所有消息,直到来自未被危及的源304的熵被发送给prng342的时刻为止。也就是说,当种子338被推送(或拉取)到prng342时,基于prng342的输出的加密可能不再受挫。可以使用于频率308和310的周期性时间间隔抖动以使得它们不是精确地周期性的。相反,它们的周期性更混乱,以精确的周期性为中心。图4是根据实施例的具有两个熵源采样频率的时序图。第一计时器408的表示在该图的顶部示出。每一个前沿或下降沿表示计时器事件。按标称来说,第一计时器408在每一条垂直线处引发。在该图中,第一计时器408的脉冲按随机抖动414延迟或加速。延迟或加速的量被确定为伪随机数发生器的输出。第二计时器410的表示在该图的底部示出。按标称来说,第二计时器410在每一条垂直线(其处于与第一计时器408不同的非谐波频率)处引发。在该图中,抖动不仅被示为与标称周期的偏差,而且还被可替代地示为更大的或更小的“脉冲”宽度。“计时器”包括在许多流行的计算机操作系统中可设置为重复地引发或者引起事件的事件驱动的计时器。例如,可以通过代码用java创建计时器:importjava.util.timer;:timertimerl=newtimer();所得到的事件可以中断正常的进程,开始新的线程,或者要不然运行如本领域中已知的代码。“频率”与计时器相关联,并且是计时器在事件之间的标称周期的倒数。也就是说,freq=1/t。计时器可以被设置为每t秒重复。源熵模块从若干个源采集。对于下面的表格,针对每个平台,对最少三个源进行了测试,其中至少一个是快速的。此目标在所有的平台上都得以实现,并且对于几个平台是远远超过的。源的实现是模块化的,并且容易快速地添加新的源。例如,创建动态地加载和使用开源熵库libhavege的源仅花费几个小时的努力。播种除了熵源之外,还在初始化时间和在检测到fork(2)之后创建从若干个地点采集种子材料的模块。种子材料被馈送到熵池以便区分熵模块的不同实例。对于任何种子材料,不计算熵。源在哪里注释目录unix、linux关于易失性目录的dirent条目环境unix、linux文件unix、linux关注的文件的分类主机名全部的hrngx86kstat(2)solaris网络接口linux、solarisos熵源全部的默认的非阻塞源注册表window只有几个特定的值sysconf(3)unix、linuxsysinfo(2)unix、linux时间全部的当日时间或高速计时器用户id全部的uid、pid等灵活通过使用简单的配置系统,可以在初始化期间改变熵模块的行为。熵源和种子源可以被单独地启用或禁用。熵源可以使它们的调谐参数变化以改变熵产生的速率、降低系统负荷、改变内部缓冲器大小或者更新估计的熵质量。示例应用将熵模块整合到应用中所需的改变的可能最小程度的线程化的例子是:#include<nse_entropy.h>#include<time.h>#include<math.h>#include<pthread.h>staticvoid*nse_entropy(void*a){nse_entropysourcesources=(nse_entropysource)a;for(;;){constdoubled=nse_entropy_update(sources);if(d>0)usleep(1e6*d);}returnnull;}intmain(intargc,char*argv[]){pthread_tnse_thread;nse_entropysourcesources=nse_entropy_new(null,&rand_add,&rand_bytes);…pthread_create(&nse_thread,null,&nse_entropy,sources);…pthread_cancel(nse_thread);nse_entropy_free(sources);return0;}如果模块被整合到openssl中,则向外面对api可以被进一步简化。整合到openssl中可以提供熵模块或派生物作为openssl分布的一部分包括在内,以便帮助改进互联网的安全性。熵模块将需要几个改变来将它整合到openssl中:·当前的api使用nse和nse前缀作为用于全局符号的命名空间。这些可能必须被改变以符合openssl命名规范。·所述模块可能必须被修改为使用openssl的内部效用函数,而不是它自己的。主要的效用函数是存储器位置和配置管理,这二者都被设计为类似于openssl接口。·一些硬件抽象可能需要被更新以使用openssl的等同物。·所述模块可能需要被整合到openssl构建基础设施中。·钩子(hook)可能需要被放到位以使得所述模块被openssl周期性地服务。fips状态该模块被设计为考虑fips标准。已经针对支持的平台进行广泛的数据收集,并且让输出进行第一稿sp800-90b熵测试。这些测试的结果然后被反馈回到熵源调谐参数中。设计考虑软件熵模块的设计应顾及三个主要的考虑:1.openssl熵模块中的现有限制;2.安全性原则;以及3.机器资源。openssl限制安全性在设计软件模块时可以观察两个引导的安全性原则以提供高质量熵:提供多样性并且适当地聚合。这二者可能都是提供值得信任的且安全的熵馈送所必需的。提供多样性第一条原则是更多的源是更好的。仅依赖于一个源意味着只有一个源需要被危及以便破坏熵系统。就良好熵的两个源来说,破坏它们中的一个不会使熵系统的操作劣化。适当地聚合第二条原则是熵在被发送给openssl的prng之前应被缓冲到合理大小的团块中。这里的根本原因是,一次涓滴几个比特的熵将使得攻击者可以经由暴力猜测来延长openssl的伪随机数发生器的危及。通过缓冲熵并且一次释放相对较大的量,这是不可行的。资源影响最终的指导方针是不使用过量的中央处理单元(cpu)或存储器。熵子系统从来都不应独占cpu。它必须与系统的正在做用户的期望工作的其他部分一起很好地运作。为了缓解资源剥夺攻击,资源分派应在初始化时进行。这使不合时宜的分派失败的可能性降低,并且消除了正常操作期间的错误处理中的一些。此推论是,还应注意在分派的缓冲器的使用之后立即清除它们以便防止信息泄露的任何可能性。具体地说,熵缓冲器在其内容被转发到任何地方之后必须总是被清除。熵模块的概述一个目标是创建产生高质量熵并且周期性地对openssl重新播种的软件模块。所述模块必须能够在融合中间件组织所用的一组平台上一致地这样做。熵模块分两个阶段运行。1.初始化:在该阶段中,系统信息被搜集并转发给调用程序,并且用于区分类似的、但是不同的操作环境。例如,如果机器上的两个进程的进程标识没有被添加到池,则它们可能具有相同的熵。然而,该初始化数据都不被认为是拥有任何熵。2.收集:在该阶段中,收集熵并转发给调用程序。每个熵源周期性地生成熵的比特。产生的质量和速度在源之间将会明显变化,这在设计中必须被考虑到。估计所产生的熵的质量,并且将其累积在每一资源缓冲器中。一旦在累积缓冲器中存在足够的估计的熵,它就被转发给输出高速缓冲,输出高速缓冲对熵进行白化和压缩。输出高速缓冲中的熵可以被调用应用请求,并且一旦高速缓冲满了,就还存在用于将过多的熵导出到输出高速缓冲或调用应用的溢出机制。这里对于一些实施例的重要的点是,每个熵源独立于所有的其他熵源作用,并且来自任何两个源的熵绝不混合,至少直到它准备好供应用使用为止。如稍后所详述的,这有助于缓解基于时序差异和质量差异的潜在攻击。熵模块设计考虑多样化多个独立的源使用调用程序用于前向保密的句柄重新播种每一个源具有不同的熵产生速率,并且确定适当的轮询间隔和何时推送到应用的池。性能:不使你的系统匮乏调节每个熵源周期性地生成熵的比特。产生的质量和速度在源之间将会明显变化,这在设计中应被考虑到。估计所产生的熵的质量,并且将其累积在每一资源缓冲器中。一旦在累积缓冲器中存在足够的估计的熵,它就通过使用提供的回调被转发给输出高速缓冲或调用应用的伪随机数发生器。在这些实施例中,每个熵源可以独立于所有的其他熵源作用,并且来自任何两个源的熵绝不混合,至少直到它准备好供应用使用为止。如稍后所详述的,这帮助缓解基于时序差异和质量差异的潜在攻击。熵模块还将包括基于经调谐的最小时序周期来对每个熵源的实际的执行进行处理。默认地,这表示固定的轮询间隔。调度程序必须确保所有的采集任务都不是在它们到期之前被执行的,它们以公平的且公正的方式运行,并且熵模块不消耗太多的cpu资源。熵模块的最后组件是可选的反馈循环,在该反馈循环中,来自输出高速缓存的经合并和白化的熵用于使时序间隔抖动。这不会提高所产生的熵的质量,但是它确实缓解了对否则完全确定性的产生时序的攻击。缺点是,这将在不同的源之间引入某个相关性。然而,熵是在白化阶段之后提取的,所以这看似是个不可能的攻击途径。在一些实施例中这里重要的一面是,熵模块出于这个目的应从应用提取远少于它正在供应的熵的熵以免它违背它自己的存在的理由。熵估计目前在数学上不可能证明数据的收集是随机的。然而,在一些情况下,可以自信地宣称数据的收集不是随机的。需要提供有多少熵在来自给定源的数据块中以及该源如何快速地递送熵的保守估计的方式。为了实现这个目标,我们从收集每一个源每一个平台的数据开始,然后我们使用几个熵估计工具来按给定的轮询间隔估计所收集的熵。轮询间隔是通过考虑平台的有限资源、根据什么适合于源而选择的。对于紧凑循环中的熵的轮询是低效的,并且将不会给予系统在轮询之间足以累积合理量的熵的时间。这样的直接后果是,熵估计限制将必须被加严,导致非常保守的界限。继而,这将需要花费更多的时间和资源来采集熵,导致系统资源的垄断。相反,我们以适度的速率收集熵,并且接受将被客户端的prng机制处理的某个量的自相关。所述模块将使用汉明距离度量的修改版本来验证比特正在改变并且正在以合理的速率这样做。该度量的输出将被用作对于自从前一个样本以后的改变量的估计器,并且将被用于限制从源可获得的宣称的熵。设计细节在呈现架构细节之前,存在一些值得明确提到和说明的更细的点。重新播种可能是必要的因为openssl只在启动时对其prng播种一次,所以为了前向安全性,重复的重新播种可能是必需的。此时,nse团队没有对openssl源代码库做出改变的许可,所以熵是通过使用播种的api周期性地将一些推送到openssl中而添加的。每个熵源将具有它自己的本地缓冲器,该本地缓冲器累积来自该源的熵,直到存在大量为止。累积的熵然后在单个块中被释放到openssl。只要至少一个源尚未被危及,这就防止了对伪随机数发生器的暴力攻击。下面提供细节。当每个可用的源采集的熵填充它们的本地缓冲器时,守护进程释放熵。这是通过调用在初始化期间提供给熵模块的回调来进行的。一般来说,这将是rand_add或fips_rand_addopensslapi调用。根据该模型,如果任何一个熵源抵抗攻击者,则一些保护仍在,因为质量熵仍被获得,并且一旦满了的缓冲器被释放到调用应用,攻击者就变成对应用的熵一无所知。它对所有的熵源和openssl本身进行危及以破坏该熵模型。由于性能原因,源应绝不阻止等待熵变为可用。相反,源应周期性地检查立即可用的任何熵并且将该熵推送到它们的内部池中。每个源的周期应是基于凭经验通过数据收集和统计分析而确定的熵进入的速率。通过使源的轮询周期不同并且绝大部分互质(co-prime),将实现一定程度的非周期性——尽管是在较长的时间间隔期间相当地可预测的一个周期性。采样中的非周期性不是必要的,然而,在两个或更多个显然断开的源事实上相关的情形下,这可能是有益的。初始化静止当系统启动时,如果它没有硬件随机性源或从前一次关闭没有存储熵,则该系统的熵状态一般是很差的。同样将适用于熵模块,并且没有立即的解决方案。所述系统将快速地变为其中熵可用的稳定的操作状态,所以重要的是在早期重新播种。嵌入式装置通常从几乎零熵的状态产生密钥和其他的密码资料,这导致不同装置上的重复的密码资料。为了部分地缓解这个脆弱性,可以使用若干个系统设置和配置来提供区分不同的主机和进程的初始变化。没有熵归于这些系统设置和配置。缓冲是好的如前面所指出的,将少量熵发送到系统池留下了暴力攻击的机会。例如,如果新的比特的位置是已知的,则将八个比特的熵添加到十六字节的池可以在28时间内被暴力破解,如果新的比特的位置是未知的,则将八个比特的熵添加到十六字节的池可以在28.128c8≈248时间内被暴力破解。这二者都比暴力破解整个池所需的2128时间容易得多。因为新的比特的位置是未知的,所以提供包含2128个比特的熵的池来防备这个攻击途径可能似乎并非是绝对必要的。然而,依赖于模糊处理来实现安全性是个陷阱,所以熵模块应防备新的比特的位置可能变为攻击者已知的可能性。在存在以截然不同的速率产生熵的源时,类似的问题出现:当高速率源受损时,低速率源被非熵数据淹没,并且其小的贡献变得易受如上面的暴力攻击。对于这个攻击途径的缓解是将来自每个源的熵缓冲到它自己的本地累积缓冲器中并且只有在累积缓冲器满了时才将熵释放到系统池。一些熵源有足够的速度和质量以至于它们不需要累积缓冲器。这些源应能够快速地、不成块地产生整个缓冲器的高质量熵。这样的源可以将它们的所收集的熵直接转发给调用应用,但是应进行调配来支持本地收集缓冲器,如果调用应用如此请求的话。白化和crngt熵源的白化作为随机比特流发生器的一部分可能是必要的,然而,提供这个不一定是熵模块的工作。不是包括白化服务和连续测试,而是可以依赖于调用应用来在熵已经被转发给它之后执行这些操作。就openssl来说,这些设施作为其伪随机数发生器模块的一部分是强制性的。使熵模块也承担它们将使无益的努力翻倍。如果远离openssl的后端以往是必需的,则可以添加可选的白化和crngt(连续随机数发生器测试)模块。每个熵源应避免尝试使其输出白化的措施,因为这样做只能降低生成的熵的质量——一般不可能仅经由白化创建更多的熵。混排和重排比特可以帮助在统计熵估计测试上得到更好的结果,但是它们通常不能增加底层熵,因此应被避免。将被许可的例外是使用一系列异或运算来将大的数据结构约简为更小的数据结构。时序抖动即使每个熵源限定了轮询周期(采样之间的间隔),全局配置也可以被设置为随机地将所有的轮询周期增加高达最大百分比。选项将从不缩短轮询周期,因此既不应减少获得的熵,也不应降低估计的产生速率和质量。然而,对于攻击者来说,将更难以做出熵源何时正好被采样以及它包含什么的确定。更详细的架构熵模块由总体管理模块和若干个熵源模块组成。管理模块熵模块的控制部分管理各种源,提供时序的排队机制,处理去往输出高速缓存或调用应用的熵转发,并且将默认设置供给各种熵源。初始化熵模块必须具有被干净地创建和部署的能力。api部分详述了用于调用应用的接口的详情。在内部,初始化代码必须对基于配置的定制化进行处理,呈送用于每个源的这些配置值,在各种熵源上迭代,并且调度所有的可执行熵源。最后,初始化代码应尝试从每个可用的源采集熵并且将此馈送给输出高速缓存或调用应用以使得某个量的熵不管多么小、都将是可用的。在内部,可以存在一个初始化接口——nse_seed_entropy_source,该接口尝试采集被视为无熵的、但是提供系统和进行之间的区分者的、系统相关的种子信息。该接口应在主要的库初始化期间被调用。熵源信息主模块将针对所有平台维护所有熵源的本地列表。它需要该列表来对模块进行初始化和部署。模块的实际执行将由时序的排队模块进行。主模块还必须构建和维护更具信息性的列表,这些列表可以被访问以查询哪些模块在初始化之前可能是可用的、哪些模块实际上是可用的、以及关于它们的其他信息。这两个列表都经由api调用而暴露。时序排队因为源正在半周期性地采集熵,所以有必要提供在需要时执行每个源的能力。这意指时序的队列。这将通过使用为提高效率而使用堆的优先级队列来实现。唯一可能需要的接口是:·创建新的无任务调度程序——nse_new_scheduler;·销毁调度程序和它所有的任务——nse_free_scheduler;·调度新的重复任务——nse_schedule;以及·如果第一任务到期,则执行第一任务——nse_run_schedule。因为熵采集操作本质上是重复性的,所以任务运行调用将在执行它之后重新调度任务。即使它最初并不是必需的,但是在队列在执行期间被修改的情况下仍将需要一定的注意。将不会做任何尝试来缓解由于任何模块的熵采集代码的物理运行时间而导致的偏斜。还注意到,没有显式的移除任务接口。将任务的调度间隔设置为零将在下一次它被执行之后有效地移除它。在采集回调中将间隔设置为零将立即移除它。附加的例程将由主管理模块(nse_time_skew_factor)提供,主管理模块基于当前的时间偏斜因子(timeskewfactor)来对源的调度间隔进行修改。该调用将通过时间排队而被用于使调度稍微抖动。抖动因子的实际确定将通过从输出高速缓存读取某个熵来进行。该熵用于产生在下一个时间周期内变为偏斜因子的统一的随机变量。对于每个熵源的每一次唤醒产生新的时间偏斜因子将是更好的,不过这将消耗来自调用应用的大量熵,这违背了熵模块的目的。调用应用负责定期地为熵模块服务,并且这种服务在时序的调度队列派发机制上提供相当瘦的包装器。熵池管理管理模块负责经由在创建时给予的回调来将熵块转发给输出高速缓存或调用应用。它还管理熵字节的每个源合并。这两种情况的接口从熵源的角度来讲是相同的,管理模块主要基于配置设置来决定何时将熵块发送到输出高速缓存或调用应用。可用的调用是:·将原始字节的块添加到目的地——nse_add_entropy_pool;和·如果足够改变,则将数据添加到目的地——nse_copy_entropy_pool_if_sufficient。前一个调用在返回之前擦除传递给它的存储器。后一个调用在清除新的缓冲器之前将新的缓冲器拷贝到旧的缓冲器。基于文件的熵源为了便于用依赖于底层系统伪文件的熵源来进行帮助,将使若干个实用例程和支持例程变为可用的:·创建新的基于文件的熵源——nse_file_source;·销毁基于文件的熵源——nse_file_source;和·从基于文件的源获取熵——nse_get_file_source。用于getrandom(2)和getentropy(2)的包装器熵模块为getrandom(2)和getentropy(2)系统调用提供内部包装器。这些分别是nse_getrandom和nse_getentropy调用。它们这二者都返回添加到所传递的缓冲器的熵的字节数。对于不支持这些系统调用的系统,这些函数总是返回零。用于特定的硬件平台的助手函数存在以机器、平台和编译器独立的方式提供对于一些特定的硬件特征的访问权限的、可用的若干个函数。这些是:·对指令计时器进行检查——nse_have_instruction_counter;·如果可用的话,对指令计数器进行查询——nse_read_instruction_counter;·对伪随机数发生器硬件进行检查——nse_have_rdrand;·对真随机数发生器硬件进行检查——nse_have_rdseed;·对伪随机数发生器进行查询,如果可用的话——nse_rdrand;和·对硬件真随机数发生器进行查询,如果可用的话——nse_rdseed。即使后面的这四个表面上是x86特定的指令,也存在这些指令中的一些将被支持用于其他架构的可能性。熵源模块每个熵源提供三个接口调用:1.初始化2.终结化;以及3.采集。初始化是以下操作可能必需的:确定源是否适合于执行的主机,如果是,则分配源进行采集将需要的任何存储器,并且执行任何其他的初始化任务,包括将任何参数设置为非默认值。终结化可能需要清除任何所分配的存储器和通过初始化阶段创建的其他资源。采集调用实际上进行从操作系统搜集熵并且将这推出到管理模块用于累积或转发的工作。循环熵缓冲器所有的熵都累积在循环缓冲器中。数据通过使用异或运算而被逐字节地添加到这些缓冲器。这些缓冲器还应维护它们包含的熵的比特数的估计。因为估计原始数据中的熵的量是困难的,所以每个熵源将提供它自己的关于正被添加的熵的量的评价。单个的源可以利用它的附加知识来降低所涉及的统计的复杂度。缓冲器可以被创建、部署和清除。它们还可以使原始数据或熵数据被添加。两种数据添加调用之间的差异是熵数据还累积字节所包含的熵的测度,而原始数据将不累积该测度。还存在可用于以下操作的一些实用接口:·经由初始化时提供的回调将熵缓冲器的熵清仓到父应用(parentapplication);·确定缓冲器中的字节的数量;·获得指向缓冲器中的原始字节的指针;·将一个熵缓冲器的内容拷贝到另一个熵缓冲器;以及·计算两个熵缓冲器之间的修改的汉明距离。存储器分配动态存储器的所有分配都应在熵模块的创建期间发生。这有助于缓解资源匮乏攻击的影响。因为在模块的正常操作期间不存在存储器分配,所以都不会失败。为了部分地缓解力图确定用于熵数据的各种收集池的状态的攻击,所有的包含熵的存储器分配都应直接地或间接地被锁到存储器中。这通常将防止力图在迫使交换文件或分区被页出之后从该交换文件或分区读取这样的数据的攻击。然而,这通常将不会提供防御对于虚拟机的这种尝试的保护,并且它将不会提供防御其他存储器窥探攻击的保护。熵估计对于每个熵源的熵的估计主要将是使用nistsp800-90bpython脚本进行的。尽管存在更多的可用的辨识测试,但是它们需要收集明显多很多的熵数据,并且所用资源中的许多资源太慢以至于不能在合理的时间量内实现。理想地,每个熵源应以接近每字节八比特的熵水平通过nistiid测试。不幸的是,在没有白化的情况下,这对于所有的源都是不可能的,所以如通过非iid测试估计的较低水平的熵将在必要时被使用。这些较低质量的熵源强制执行各源熵池化。修改的汉明权重不是使用传统的汉明权重作为样本中的熵的估计器,而是将使用将大量比特反转看作低熵的修改的度量。这将通过在gf(2)上添加当前的样本和先前的样本、对结果及其补码这二者确定汉明权重并且使用较低的值来进行。下面包括的例子指示汉明度量提供并示出相同的情况下的修改的度量的输出的过高估计。虽然仍然过高估计实际的改变,但是修改的汉明度量这样做至一个降低的程度,因此是更保守的方法。这里,加上1将导致单个比特改变。这种情况考虑了所有的加法的一半。这里,加上1将导致两比特改变。这种情况考虑了所有的加1的加法的四分之一。这里,加上1导致五比特改变。汉明距离过高估计了改变。修改的汉明度量另一方面生成了更现实的结果。这是针对像其包括有正当理由的这种情况而言的。确定样本中的熵对于较慢运行和较低质量的源,将使用前一个样本和当前样本之间的距离来提供对宣称的熵和熵本身的估计上的两个限制。下限将是针对每个源指定的,如果度量没有指示至少这许多比特已经改变,则该源被视为在该间隔尚未改变,并且样本被忽视。基于对于已经改变的每个比特、也将预计尚未改变的假设,所用的熵估计将使计算的距离度量翻倍。上限约束每个样本可以宣称的熵的最大量。下限和上限将是针对每个熵源、基于经验数据设置的。如果可以从各种操作系统和架构获得足以使得每个源的采集间隔和熵质量可以被适当地调谐的数据,则应当能够放宽界限并且可能完全移除这些限制。在这些情况下,可以具有关于每个样本生成的比特数的可靠估计。apiapi来自单个头文件:#include″nse_entropy.h″来自熵模块的所有外部的接口都应具有以nse_开头的名称。所有内部的、但是公开的接口都应具有以nse_开头的名称。本地名称是无限制的,并且应被隐藏。版本信息来自于nse_entropy_version该常数保存熵模块版本号。它是以下格式的十进制无符号整数:vvvmmmmee。vvv是库版次,mm是大版次,mm是小版次,ee是额外/应急(extra/emergency)版次。初始化使用:nse_entropysourcense_entropy_initialise(nse_entropyreapersources,void(*overflow)(constvold*buf,intnum,doubleentropy));初始化函数设置所有的熵源,并且为进行中的使用做好一切准备。它还将提供某个初始播种来区分收获程序(reaper)的不同实例。它从传递的配置读取非默认的设置,这些设置可以在该调用返回时被立即删除。如果对于所述配置传递null,则将使用默认。一旦收获程序的输出高速缓存满了,溢出自变量就提供将熵推送到调用应用的熵池的回调。在正常操作中,该自变量可以是来自openssl的rand_add或fips_rand_add。该自变量可以是null,在此情况下,过大的熵被丢弃。熵的量是在调用该函数时以字节为单位测得的,在库的整个其余部分中,熵是以更自然的比特为单位测得的。尽管可以创建熵模块的多个实例,但是这样做是不鼓励的。有很好的理由相信由多个实例生成的熵流将是相关的。因此,两个或更多个实例可能不能生成任何多于一个的熵。获得熵使用:intnse_get_entropy(nse_entropyreaper,void*,size_t);intnse_get_entropy_nonblocking(nse_entropyreaper,void*,size_t);这些函数从内部的输出高速缓存得到熵并且将它放置到传递的缓冲器中。第一调用阻塞,直到整个熵请求可以得到满足为止。第二调用不阻塞,而是等待熵累积,并且部分返回是可能的。两个调用都返回拷贝的熵的字节的数量,或者在错误时返回-1。周期性地调用doublense_entropy_update(nse_entropysource);更新函数将以非阻塞的方式更新内部熵池,并且视可行程度将整个池传递给openssl。它返回直到需要服务的下一个熵事件的秒数。与返回值指示的频率相比更频繁地或不那么频繁地调用该函数是安全的,但是利用该值不允许调用程序在服务熵之间休眠。完成和销毁:voidnse_entropy_free(nse_entropysource);该函数销毁熵模块,释放所分配的存储器,并且将消费的所有资源都返回给操作系统。当你完成熵模块并且希望摆脱它时,调用该函数。这通常将是在程序终止时。迫使健康检查重新运行:voidnse_entropy_health_checks(nse_entropyreaper,intimmediate);该函数迫使健康检查上的功率重新运行。直到源已经完成这些检查,该源才将生成熵。这通常将花费数分钟到数小时的一些时间。如果中间自变量为非零,则能够快速地进行健康检查的相对较少的资源将被立即检查。这将短暂地延迟现在的执行,但是将阻止熵的产生的完全破坏。然而,熵收获将用减少的源运行,直到其余的熵源通过它们自己的健康检查为止。在收获程序再次以全功能运行之前可能要几个小时。查询和更新函数存在使得熵收获程序的行为可以被检查和修改的若干个查询和更新函数。在一些实施例中,修改可以仅在创建和初始化之间执行。检查可以在任何时间发生。默认设置适合于熵收获程序的大部分使用,这些api可能是不需要的。收获程序设置存在用于熵收获程序的若干个全局设置。这里将讨论访问api。缓冲器大小size_tnse_entropy_query_buffer_size(nse_entropyreaperer);voidnse_entropy_set_buffer_size(nse_entropyreaperer,size_ttarget);这些函数使得可以对收获程序设置理想的内部缓冲器大小。默认该大小为33个字节,并且熵的每个输出将尝试提供熵的33×8=264个比特。并非所有的熵源都可以提供这样的灵活性,但是大部分熵源提供这样的灵活性。输出高速缓存intnse_entropy_query_cache(nse_entropyreaperer,size_t*size,constchar**algoritm,double*rate);voidnse_entropy_set_cache(nse_entropyreaperer,intwhiten,size_tsize,constchar*algoritm,doublerate);这些函数控制输出高速缓存和白化。如果白化被启用,并且可选地输出熵高速缓存的大小以字节为单位并且摘要(digest)算法名称被使用,则前一个函数返回非零。后一个函数指定白化与否、指定输出高速缓存的大小(其可以为零)以及用于使输出白化的摘要的名称。如果对于摘要传递null,则将使用默认。速率参数指定当给熵做摘要时应进行的过采样的水平。低于单位一的值被忽视。默认设置是使用默认算法(sha512)、1024字节缓冲器和过采样速率2白化的。时间偏斜intnse_entropy_query_time_skewer(nse_entropyreaperer,double*int,double*per);voidnse_entropy_set_time_skewer(nse_entropyreaperer,intenbl,doubleint,doubleper);前一个调用查询时间偏斜器模块的状态。如果时间偏斜被启用,则它返回非零。另外,如果传递的指针不是null,则间隔(以秒为单位)和百分比偏斜也被返回。第二个调用使得时间偏斜器模块可以被配置。启用的设置也被施加,但是以秒为单位的间隔和百分比设置只有在传递的值为非负时才被施加。默认地,时间偏移是以12秒的间隔和5%的偏斜启用的。健康检查intnse_entropy_query_health_checks(nse_entropyreaperer);voidnse_entropy_sethealth_checks(nse_entropyreaperer,intenable);如果启动和连续的健康测试将被运行,则前一个函数返回非零。第二个调用使得测试可以被启用。默认地,健康检查被禁用。冗长度intnse_entropy_query_verbose(nse_entropyreaperer)voidnse_entropy_set_verbose(nse_entropyreaperer,intlevel);第一个函数查询收获程序正在运行的冗长度级别。级别越高,其输出越冗长。第二个调用使得冗长度级别可以被指定。零级别(默认)意味着没有冗长的输出。所有的其他的级别都是未定义的。源设置unsignedintnse_entropy_source_count(void);constchar*nse_entropy_source_query_name(unsignedint);intnse_entropy_source_query_usable(nse_entropysource,unsignedint);这些查询函数返回关于各种原始熵源的信息。熵源的数量可以使用nse_entropy_source_count调用来查询。每个源的名称可以使用nse_entropy_source_name调用来访问,对于范围外的索引返回null。为了检查源是否正被使用,在初始化完成之后,进行nse_entropy_source_query_usable调用。如果讨论中的源正被使用,则该函数返回非零。活跃的源intnse_entropy_source_query_active(nse_entropyreaperer,unsignedintn);voidnse_entropy_source_set_active(nse_entropyreaperer,unsignedintn,intactive);这些函数使得可以确定和设置源的活跃标记。活跃的源将在初始化时被启动,不过并非所有活跃的源都一定在每个机器上是可用的,所以可以使活跃的源不可使用。nse_entropy_source_query_usable调用用于确定后者。缓冲器大小size_tnse_entropy_source_query_buffer_size(nse_entropyreaperer,unsignedintn);voidnse_entropy_source_set_buffer_size(nse_entropyreaperer,unsignedintn,size_tbs);这些函数允许确定源的收集缓冲器的大小和进行查询。对于大部分源,收集缓冲器可以是任意大小,不过对于一些源,收集缓冲器是不可变的,经由这些调用做出的任何改变将被忽视。池大小signedintnse_entropy_source_query_pool_size(nse_entropyreaperer,unsignedintn);voidnse_entropy_source_set_pool_size(nse_entropyreaperer,unsignedintn,signedintpool_size);这些函数允许可以针对每个源指定熵池缓冲器大小。池大小为零意味着没有额外的缓冲级。负的池大小使所述系统基于全局目标缓冲器大小和源的熵质量来计算池大小。正的池大小将被用作收集缓冲器和输出白化级之间的次要着陆点。熵质量doublense_entropy_source_query_entropy_quality(nse_entropyreaperer,unsignedintn);voidnse_entropy_source_set_entropy_quality(nse_entropyreaperer,unsignedintn,doublequality);这些调用使得从源输出的质量输出可以被查询和修改。质量参数是范围[0,1]内的实数。值为0意味着每个比特没有熵,值为1意味着每个比特满熵。并非所有的源都使用质量参数作为它们的隐含的熵的测度,下面的限值也可以用于这个目的。调度间隔doublense_entropy_source_query_scheduling_interval(nse_entropyreaperer,unsignedintn);voidnse_entropy_source_set_scheduling_interval(nse_entropyreaperer,unsignedintn,doubleinterval);调度间隔是熵源的采样之间的标称时间。每个源通常将具有它自己的唯一的调度间隔。这些函数使得特定的源的调度间隔可以被查询和更新。熵限值voidnse_entropy_source_query_entropy_limits(nse_entropyreaperer,unsignedintn,unsignedint*low,unsignedint*high);nse_entropy_source_set_entropy_limits(nse_entropyreaperer,unsignedintn,unsignedintlow,unsignedinthigh);一些熵源限制它们在更新时将接受的熵的量。具体地说,已经改变的比特的数量必须至少是低阈值,并且它被修整到高阈值。这些调用使得这些限值被查询和指定。在前一个调用中,指针变量中的任何一个可以是null,在这种情况下,该参数不被返回。后一个调用使得限值可以被调整。对限值传递零值使设置不改变。快速健康检查intnse_entropy_source_query_fast_health_checks(nse_entropyreaperer,unsignedintn);如果指定的熵源能够快速路径启动健康检查,则该查询函数返回非零。能够进行快速路径健康检查的源将是立即可用的。不能的源必须在它可以对进行中的熵收集做出贡献之前缓慢地产生所需的4096个样本。播种在初始化时,收获程序尝试采集低熵系统区分信息。用于此的源可以被选择性地或全局地禁用。与所有的初始化参数一样,它们只可以在收获程序初始化之前被修改。全局播种设置intnse_entropy_query_seed(nse_entropyreaperer);voidnse_entropy_set_seed(nse_entropyreaperer,intstate);前一个调用查询当前播种状态。非零返回值指示播种将被执行。后一个调用使得播种可以在状态是非零时被全局启用,或者在状态为零时被禁用。默认地,播种被启用。查询种子源intnse_entropy_seed_count(void);constchar*nse_entropy_seed_name(unsignedintn);前一个调用返回可用的种子源的数量。后一个调用返回指定编号的种子的名称。如果参数在范围之外,则它返回null。激活种子源intnse_entropy_seed_query_active(nse_entropyreaperer,unsignedintn);voidnse_entropy_seed_set_active(nse_entropyreaperer,unsignedintn,intenable);如果指示的种子当前是活跃的,则前一个调用返回非零。后一个调用使得指示的种子可以被启用或禁用。默认地,所有的种子源都被启用。如何使用所述模块熵模块被设计为简单地、非侵入性地整合到另一个应用中。它可以在被它自己的线程服务时最佳地操作,不过它在没有问题的非线程化的环境下也将工作。还可以在单个进程内创建熵模块的多个实例,每个馈送不同的熵池。然而,不存在关于所得输出的相关性的保证。线程化为了从单独的线程服务熵子系统,应存在沿着此思路的代码:#include<math.h>#include<time.h>#include<nse_entropy.h>…nse_configconfig=nse_config_new();…nse_entropysourcesources=nse_entropy_new(config,&openssl_add_function,null)nse_config_free(config);if(sources==null)fail;…for(;;){constdoubled=nse_entropy_update(sources);if(d>0){structtimespects;ts.tv_sec=trunc(d);ts.tv_nsec=1e9*(d-ts.tv_sec);nanosleep(&ts,null);}}…nse_entropy_free(sources);非线程化为了在非线程化的环境中使用熵模块,相同的调用需要如线程例子那样进行,但是这些需要被整合到应用的事件循环中。没有必要履行从nse_entropy_update返回的等待时间,你有自由比平时或多或少地调用该函数,但是它必须被定期调用。最小的代码集为:#include<nse_entropy.h>…nse_entropysourcesources=nse_entropy_new(null,&rand_add,&rand_by5es);…/*inyourmainloop*/while(nse_entropy_update(sources)==0);…nse_entropy_free(sources);该代码不基于从nse_entropy_updat返回的时间休眠,所以它将可能是非常低效的。小工作线程化例子代码调用代码可以完全避免nse_config子系统,并且改为依赖于默认:推荐1.熵守护进程应在可能馈送到内核中的地方运行。守护进程的确切选择是留待指定的。理想地,几个将并行运行。2.应在cpu中支持硬件随机数源,但是默认禁用它们。虽然这些源非常快并且可能生成巨大量的熵,但是一些人关于它们的可信度。将由终端用户决定他们是否将对黑盒子源投入他们的信任。3./dev/random和/dev/urandom这二者如果可用的话,都应被支持。/dev/random由于其阻塞性默认将被禁用,但是对于其中有足够的硬件熵可用的系统应被启用。相反,/dev/urandom由于其更高的产生速率默认将被使用,不过没有熵将被计数为来自该源,除非被调用应用超控。在支持调用的系统上,getentropy(2)和getrandom(2)将被以相同的方式分别用作/dev/random和/dev/urandom的替代者。熵源熵守护进程提供若干个不同的单独熵源,这些熵源各自生成转发给openssl进行混合和白化的熵池。每个源具有使得可以对它们的行为进行精细的调谐和大批改变的几个选项。一旦池包含足够的熵,它就被转发给openssl,并且熵估计以entropyquality参数为倍数减小。全局的cpu信息该源基于可用的cpu(一个或多个)状态信息返回熵。这对于solaris、hp-ux和aix系统是有用的。它对其他装置不做任何事。linux改为使用/proc/timer_list和/proc/interrupts源。这里的可变参数是凭经验确定的,其默认值基于托管操作系统:osbuffersizeintervalmaxentropyminentropypoolsizeaix51.1338150hp-ux51.1338150solaris51.1338150这里的数字全都是相同的。这意味着进一步的系统特定的调谐可能是必需的。目前,单个操作系统的不同版本被相同地处理。如果未来的数据指示这是不理想的,则可能需要特化。存储器信息该源是针对aix和freebsd平台定义的,并且检查瞬时的物理存储器使用和虚拟存储器使用。linux使用/proc/mominfo源来采集类似的信息。参数默认描述enable是是否使用该源entropyquality可变的记入熵池的每个比特的熵interval可变的采集之间的秒数poolsize可变的本地熵累积池的大小这里的可变参数是凭经验确定的,其默认值基于托管操作系统:osentropyqualityintervalpoolsizeaix7.504.936freebsd0.005.9115221单个操作系统的不同版本可以被相同地对待。如果未来的数据指示这是不理想的,则可能需要特化。目前的情况是,该源对于freebsd机器没有表现为是值得的。然而,该数据是来自另外的空闲的虚拟机上的未提炼的部分收集。存在很多供向前改进的范围。网络信息分段网络该源是针对freebsd平台定义的,并且检查网络接口上的通信量统计。linux使用/proc/net/dev源来采集类似的信息。时间分段时间该源基于高分辨率时钟返回熵。它在所有的平台上都是有用的,并且所用时钟在每个平台上是变化的。在所有平台上,该源每次采样发出单个字节。参数默认描述enable是是否使用该源entropyquality可变的记入熵池的每个比特的熵interval可变的采集之间的秒数poolsize可变的本地熵累积池的大小这里的可变参数是凭经验确定的,其默认值基于托管操作系统:osentropyqualityintervalpoolsizeaix7.800.137033freebsd7.500.128733hp-ux7.800.137033linux7.500.128733solaris7.800.137033windows6.181.662633其他6.002.242799目前,单个操作系统的不同版本被相同地对待。如果数据指示这是不理想的,则可能需要特化。其他行是用于不支持clock_gettimc(2)系统调用、因此改为退回到较低分辨率的gettimeofday(2)的系统的。io针对aix、hp-ux、solaris和windowns定义。linux改为使用/proc/diskinfo源。参数默认描述buffersize可变的每次收集和发送的熵的字节enable是是否使用该源entropyquality1记入熵池的每个比特的熵interval可变的采集之间的秒数maxentropy可变的每次收集可以记入的最大熵量minentropy可变的低于此熵量,我们忽视收集poolsize可变的本地熵累积池的大小这里的可变参数是凭经验确定的,其默认值基于托管操作系统:osbuffersizeintervalminentropymaxentropypoolsizeaix310.00021469hp-ux310.00038114solaris1411.913116294目前,单个操作系统的不同版本被相同地对待。如果数据指示这是不理想的,则可能需要特化。prng针对intelx86平台、使用rdrand指令定义。它由于对于rdrand指令的担心而默认被禁用。这些担心有两个方面:有可能指令不产生质量熵,尽管宣称产生质量熵,并且有可能指令作为其操作的一部分而危及池中的现有熵。然而,这到目前为止是机器上可用的最快的熵源,所以如果你对熵的要求非常高并且你不关心熵的黑盒子性质,则启用该源。参数默认描述buffersize8每次收集和发送的熵的字节enable否是否使用该源entropyquality1.00记入熵池的每个比特的熵fasthealth是可以快速开启针对该源执行的健康测试interval0.15采集之间的秒数poolsize40本地熵累积池的大小hrng针对intelx86平台、使用rdseed指令定义。它由于对于rdseed指令的担心而默认被禁用。与对于rdrand的担心完全相同。出于像我们正在做的那样对用于prng的熵池播种的目的,rdseed较于rdrand是推荐的。因此,如果一个将被启用,则rdseed较于rdrand应是优选的。指令计数器该模块只有在安腾和sparc平台以及具有tsc指令的x86处理器上才可能是有用的。安腾的itc和x86的tsc寄存器这二者提供指令周期计数器。在存在操作系统和其他任务时,这用低阶比特来提供适度量的熵。参数默认描述enable是是否使用该源entropyquality0.975记入熵池的每个比特的熵fasthealth是可以快速开启针对该源执行的健康测试interval可变的采集之间的秒数poolsize可变的本地熵累积池的大小这里的可变参数是凭经验确定的,其默认值基于托管操作系统:osintervalpoolsizeia640.1334sparc0.2534x860.1334目前,单个操作系统的不同版本被相同地对待。如果数据指示这是不理想的,则可能需要特化。/dev/random源从unix和linux内核读取熵池。因为该池通常是阻塞的,所以默认将是非常低频次地读取仅非常少量的熵。如果主机系统被配置为经由该源(例如,经由硬件随机数发生器或haveged)提供很多质量熵,则可以明显增大缓冲器大小,并且减小间隔。参数默认描述buffersize1每次收集的熵的字节enable否是否使用该源entropyquality1.00记入熵池的每个比特的熵interval15采集之间的秒数poolsize33本地熵累积池的大小/dev/urandom该源在linux和unix系统上提供伪随机数发生器。因为关于作为该源的基础的熵池的质量没有保证,所以它不被记入供应任何熵。参数默认描述buffersize33每次收集的熵的字节enable否是否使用该源entropyquality0.00记入熵池的每个比特的熵interval2采集之间的秒数poolsize0本地熵累积池的大小,零意味着没有本地累积/dev/srandombsd特定的源从内核读取熵池。因为这个池通常是阻塞的,所以默认将是非常低频次地读取仅非常少量的熵。如果主机系统被配置为经由该源(例如,经由硬件随机数发生器或haveged)提供很多质量熵,则可以明显增大缓冲器大小,并且减小间隔。参数默认描述buffersize1每次收集的熵的字节enable否是否使用该源entropyquality1.00记入熵池的每个比特的熵fasthealth否可以在针对该源执行的健康测试上快速提供动力interval15采集之间的秒数poolsize33本地熵累积池的大小/dev/prandom该源在linux/s390系统上提供伪随机数发生器。因为关于作为该源的基础的熵池的质量没有保证,所以它不被记入供应任何熵。参数默认描述buffersize1每次收集的熵的字节enable否是否使用该源entropyquality0.00记入熵池的每个比特的熵fasthealth否可以快速开启针对该源执行的健康测试interval2采集之间的秒数poolsize0本地熵累积池的大小,零意味着没有本地累积getentropy该源是在openbsd、solaris和linux上可用的gententropy(2)系统调用。getrandom该源是在solaris和linux上可用的getrandom(2)系统调用。它从与/dev/random和/dev/urandom源相同的熵池提取。参数默认描述buffersize33每次收集的熵的字节enable否是否使用该源entropyquality0.00记入熵池的每个比特的熵interval2采集之间的秒数poolsize0本地熵累积池的大小,零意味着没有本地累积cryptgenrandom该windows源仅使用cryptgenrandom密码质量随机数发生器。参数默认描述buffersize33每次收集的熵的字节enable否是否使用该源entropyquality0.00记入熵池的每个比特的熵interval2采集之间的秒数poolsize0本地熵累积池的大小,零意味着没有本地累积/droc/diskstats使用磁盘io子系统统计的linux特定的源。参数默认描述buffersize16每次收集的熵的字节enable是是否使用该源entropyquality1.00记入熵池的每个比特的熵interval3.3采集之间的秒数maxentropy9每次收集可以记入的最大熵量minentropy2低于此熵量,我们忽视收集poolsize560本地熵累积池的大小/proc/interrupts使用cpu中断统计的linux特定的源。这里的可变参数是凭经验确定的,并且其默认值基于托管处理器架构:处理器buffersizemaxentropypoolsizearm169560s39072924other819260目前,处理器的不同版本被相同地对待。如果数据指示这不是理想的,则可能需要特化。/proc/meminfo使用系统存储器系统的linux特定的源。参数默认描述buffersize可变的每次收集和发送的熵的字节enable是是否使用该源entropyquality1.00记入熵池的每个比特的熵interval1.27采集之间的秒数maxentropy可变的每次收集可以记入的最大熵量minentropy2低于此熵量,我们忽视收集poolsize可变的本地熵累积池的大小这里的可变参数是凭经验确定的,并且其默认值基于托管处理器架构:处理器buffersizemaxentropypoolsizearm1631520其他137572目前,处理器的不同版本被相同地对待。如果数据指示这不是理想的,则可能需要特化。/proc/nct/dev使用网络接口统计的linux特定的源。这里的可变参数是凭经验确定的,并且其默认值基于托管处理器架构:处理器buffersizemaxentropypoolsizearm921188其他58195目前,处理器的不同版本被相同地对待。如果数据指示这不是理想的,则可能需要特化。/proc/timerlist使用内核计时器统计的linux特定的源。参数默认描述buffersize19每次收集和发送的熵的字节enable是是否使用该源entropyquality1.00记入熵池的每个比特的熵interval0.753采集之间的秒数maxentropy22每次收集可以记入的最大熵量minentropy2低于此熵量,我们忽视收集poolsize285本地熵累积池的大小windows进程信息该windows特定的源读取当前执行的进程中的一些(不一定是全部),并且从每个中提取时序、存储器大小和io细节以创建其熵。用户接口信息在windows平台上,考虑使用用户接口的各种方面(比如光标位置和当前聚焦的窗口)的源。在无头服务器上,这种源可以不生成有意义的熵。然而,在工作站上,它能够生成某个熵。因为它必须以人类的速度操作,所以产生速率将很低。该源最后被移出考虑,因为对它生成的熵的产生速率和质量进行量化是极其困难的。尝试了对该源进行分析,并且在一周的数据收集之后,生成了小于64千字节的原始数据,该原始数据不足以生成有意义的统计。在没有质量的合理估计的情况下,模块必须保守地假定源正在生成零熵。非常慢的、没有生成可信的熵的源最多是边缘的。因此,决策不包括这样的源。种子源初始播种从所述系统的各部分征求信息,并且将它们推送到熵缓冲器中。这些通常不是良好的熵源,但是它们对区分装置确实起作用。为了对此进行说明,我们假定在这个阶段期间接收到零熵。真实的熵源还将在初始化期间用来试图具有某个熵,但是它们通常可能花费一定时间才变得有效。unix种子源·sysconf(_sc_child_max)·sysconf(_sc_stream_max)·sysconf(_sc_open_max)·sysconf(_aes_os_version)·sysconf(_sc_cpu_version)·sysinfo(si_machine)·sysinfo(si_release)·sysinfo(si_hw_serial)·file:/etc/passwd·file:/etc/utmp·file:/tmp·file:/var/tmp·file:/usr/tmp·file:getenv(“nsrandfile”)length=getenv(“nsrandcount”)·file:/dev/urandom·processenvironment·hostname·pid·ppid·gid·egid·uid·euid·date/timewindows种子源·globalmemorystatus·getlogicaldrives·getcomputername·getcurrentprocess·getcurrentprocessid·getcurrentthreadid·getvolumeinformation·getdiskfreespace·registryseedkey种子源的配置配置系统允许更大的且更耗时的种子源通过在种子部分中设置值而被选择性地禁用。一般来说,无需更改对于种子源的默认设置。还存在若干个不能被禁用的轻量级快速种子源。这些包括当日时间、高速计时器、系统的主机名称、各种系统和进程id。系统还包括linux。内核熵源若干个不同的源可用于采集直接输入到操作系统的熵池中的熵。有益的是运行这些源中的一个或几个以提供超出内核通常提供的附加熵源。具有更多的源是没有害处的,它们可能恰好有帮助。这些源的资源利用都较低。havegehavege借助于高速计时器从未知的和可知的内部cpu状态获得熵。如果进程可以被成功地启动,则这应被用作所有平台上的熵源。我们可以经由/dev/random或者经由去往进程的直接管道来获取馈送。一般来说,前者是更好的替代方案,因为它对需要它的系统上的一切都提供熵。目前,对于x86、ia64、powerpc、ibms390和sparc,havege是直接支持的。在其他平台上,它将退回到使用gettimeofday(2),gettimeofday(2)仍将是起作用的,但是不太可能如此高效率。已经引发了对于havege的如下扩展部分的担心,该扩展部分使输出白化,使得不管基础质量如何,它与真实的熵都是不可区分的。来自testu01的crush测试和bigcrush测试能够区分修改的havege的输出和当在采样大小为109个字节的情况下交付的纯熵。修改将高速计时器替换为返回常数的函数。结论是扩展没有生成密码质量白化。然而,havege正在扩展它从计时器接收的熵。对于每个32字节的输出,havege算法对计时器进行一次采样。而且,计时器接连快速地采样,因此对于每个2.4比特的样本生成相对较低的熵。因此,输出的每个字节拥有比0.0625个比特略多的熵。cpu抖动随机数发生器cpu抖动随机数发生器以与havege类似的原理工作,它依赖于现代cpu的复杂的、隐藏的内部状态来提供时序抖动,该时序抖动然后被用于生成熵。这两者之间的主要差异是,havege主动地尝试运行代码和数据高速缓存、分支预测器和转译后备缓冲器。相反,cpu抖动随机数发生器被动地测量内部cpu状态。turridturbid从音频装置上的浮动输入产生熵。基于johnson-nyquist噪声,它具有可证明的最低级别的熵。我们不从这个守护进程接受直接输入,相反,我们将依赖于它在/dev/random中推送熵。推荐的是,该守护进程在所有的具有未使用的音频输入的系统上运行。失败的话,其他的浮动音频输入熵源之一应被使用,如果可能的话。maxwellmaxwell在短暂的休眠之后从时序抖动产生熵。它是非常轻量级的、保守地设计的,并且将产生的熵输出到/dev/random。该源尝试使它输出的比特混合和白化,这可能会使已存在的真正的熵模糊。推荐的是,该守护进程或另一个基于时间抖动的源在所有的合适的系统上运行。randomsoundrandomsound如上面的trubid那样从浮动的音频输入采集熵。然而,不尝试对得到的最小级别的熵进行量化。当然,仍将存在可证明的最小级别,但是提供给内核的估计并非基于数学基础。时钟随机性采集守护进程时钟随机性采集守护进程使用不同的物理高频时钟之间的波动来产生熵。考虑到每个时基将抖动(可认为独立地抖动),这可以是比单个时间源更好的熵源。用于该守护进程的源代码似乎失踪了,并且该项目可以认为死掉了。音频熵守护进程音频熵守护进程是像randomsound和turbid那样使用浮动的模拟音频输入的另一个源。像randomsound那样,不尝试从理论上对正在产生的熵的最小数进行量化。计时器熵守护进程计时器熵守护进程在休眠期间使用时序抖动来生成熵,很像maxwell那样。该守护进程比maxwell更轻量级,并且不尝试通过进行小的计算来使事情更活跃,相反它仅使用通过gettimeofday(2)采样包装的100μs休眠。视频熵守护进程视频熵守护进程使用来自视频捕捉装置的帧之间的差异作为其熵源。熵的质量将取决于视频捕捉的回转以及捕捉是模拟的、还是数字的。理想地,去调谐后的模拟捕捉将被使用,但是随着数字电视机变为主导,这样的硬件不太可能达到与音频输入相同的商品级别。噪声噪声熵源通过白化和混合步骤使用各种中断源(按键、磁盘io...)的高分辨率时序。该源完全是用x86汇编代码编码的,并且被写为用于dos系统的装置驱动程序。它很可能太老以至于不能实用。通过操作系统的源下面列出了每个操作系统的主要熵源和次要熵源。上面详述了关于对于每个源的单独配置的更特定的细节。linuxsolaris主要的高速计时器/dev/random或getentropy(2)次要的内核io统计内核cpu状态被禁用的rdrand(x86特定的)rdseed(x86特定的)windows主要的cryptgenrandom次要的queryperformancecounterio统计进程时序信息用户接口数据当前的进程被禁用的rdrand(x86特定的)rdseed(x86特定的)其他unix主要的系统熵源高分辨率计时器次要的io信息存储器使用数据cpu统计实时时钟术语表流程图图5是例示了根据实施例的处理500的流程图。所述处理可以由计算机在处理器中执行指令或者以其他方式来实现。在操作501中,设置用于第一频率的重复的计时器。在操作502中,设置用于第二频率的重复的第二计时器,第二频率不同于第一频率,并且在这种情况下,不是第一频率的谐波。在操作503中,以第一频率从第一熵源收集预定数量的第一比特,所述预定数量是基于可归于第一熵源的每个比特的熵量。在操作504中,将第一比特呈送给伪随机数发生器。在操作505中,以第二频率从第二熵源采集指定数量的第二比特,所述指定数量是基于可归于第二熵源的每个比特的熵量。第一比特和第二比特可以用于对伪随机数发生器播种。在操作507中,基于伪随机数发生器的输出来周期性地调整第一频率和/或第二频率。图6是例示了根据实施例的处理600的流程图。所述处理可以由计算机在处理器中执行指令或者以其他方式来实现。在操作601中,设置彼此不同的频率的异步计时器,在这种情况下,这些频率不是彼此的谐波。在操作602中,根据异步计时器中的第一计时器从第一熵源收集预定数量的第一比特。在操作603中,计算连续的所收集的第一比特之间的汉明距离。在操作604中,基于汉明距离超过最小值,将第一比特接纳到第一累积缓冲器中。在操作605中,将连续收集的的第一比特之间的汉明距离合计为归于第一累积缓冲器的内容的熵的累积值。在操作606中,将第一累积缓冲器的内容呈送给伪随机数发生器。在操作607中,根据异步计时器中的第二计时器从第二熵源采集指定数量的第二比特。在操作608中,将第二比特接纳到第二累积缓冲器中,第二累积缓冲器具有与第一累积缓冲器的大小不同的大小。在操作609中,将第二累积缓冲器的内容呈送给伪随机数发生器。计算设备图7例示了可以实现本发明的各种实施例的示例性计算机系统700。系统700可以用于实现上述计算机系统中的任何一个。如图所示,计算机系统700包括经由总线子系统702与若干个外围子系统通信的处理单元704。这些外围子系统可以包括处理加速单元706、i/o子系统708、存储子系统718和通信子系统724。存储子系统718包括有形的计算机可读存储介质722和系统存储器710。总线子系统702提供让计算机系统700的各种组件和子系统如打算的那样彼此通信的机制。尽管总线子系统702被示意性地示为单根总线,但是总线子系统的替代实施例可以利用多根总线。总线子系统702可以是几种类型的总线结构中的任何一种,包括存储器总线或存储器控制器、外围总线以及使用各种总线架构中的任何一种的本地总线。例如,这样的架构可以包括工业标准架构(isa)总线、微信道架构(mca)总线、增强isa(eisa)总线、视频电子标准协会(vesa)本地总线以及外围组件互连(pci)总线,这些总线可以被实现为按照ieeep1386.1标准制造的mezzanine总线。可以实现为一个或多个集成电路(例如,常规的微处理器或微控制器)的处理单元704控制计算机系统700的操作。一个或多个处理器可以包括在处理单元704中。这些处理器可以包括单核或多核处理器。在某些实施例中,处理单元704可以被实现为一个或多个独立的处理单元732和/或734,其中,单核或多核处理器包括在每个处理单元中。在其他实施例中,处理单元704也可以被实现为通过将两个双核处理器合并到单个芯片中而形成的四核处理单元。在各种实施例中,处理单元704可以响应于程序代码来执行各种程序,并且可以维护多个同时执行的程序或处理。在任何给定时间,要执行的程序代码中的一些或全部可以驻留在(一个或多个)处理器704和/或存储子系统718中。通过合适的编程,(一个或多个)处理器704可以提供上述各种功能性。计算机系统700可以还包括处理加速单元706,处理加速单元706可以包括数字信号处理器(dsp)、专用处理器等。i/o子系统708可以包括用户接口输入装置和用户接口输出装置。用户接口输入装置可以包括键盘、指点装置(诸如鼠标或轨迹球)、合并到显示器中的触控板或触摸屏、滚动轮、点击轮、转盘、按钮、开关、小键盘、具有语音命令识别系统的音频输入装置、麦克风以及其他类型的输入装置。用户接口输入装置可以包括例如运动感测和/或手势识别装置,诸如使得用户能够使用手势和口头命令通过自然用户接口来控制输入装置(诸如microsoft360游戏控制器)并且与该输入装置进行交互的microsoft运动传感器。用户接口输入装置还可以包括眼睛姿态识别装置,诸如google眨眼检测器,其从用户检测眼睛活动(例如,在获取图片和/或做出菜单选择时“眨眼”),并且将眼睛姿态作为输入变换到输入装置(例如,google)中。另外,用户接口输入装置可以包括使得用户能够通过语音命令与语音识别系统(例如,导航器)进行交互的语音识别感测装置。用户接口输入装置还可以包括但不限于,三维(3d)鼠标、操纵杆或指点杆、游戏手柄和图板、以及音频/视觉装置(诸如扬声器、数字照相机、数字摄像机、便携式媒体播放器、网络摄像头、图像扫描仪、指纹扫描仪、条形码读取器3d扫描仪、3d打印机、激光测距仪和眼睛注视跟踪装置)。另外,用户接口输入装置可以包括例如医学成像输入装置,诸如计算机断层成像、磁共振成像、位置发射断层成像、医学超声诊断装置。用户接口输入装置还可以包括例如音频输入装置,诸如midi键盘、数字乐器等。用户接口输出装置可以包括显示子系统、指示器灯或非视觉显示器(诸如音频输出装置)等。显示子系统可以是阴极射线管(crt)、平板装置,诸如使用液晶显示器(lcd)或等离子体显示器、投影装置、触摸屏等的装置。一般来说,术语“输出装置”的使用意图包括用于将来自计算机系统700的信息输出到用户或其他计算机的所有的可能类型的装置以及机制。例如,用户接口输出装置可以包括但不限于,视觉地传达文本、图形和音频/视频信息的各种显示装置,诸如监视器、打印机、扬声器、耳机、汽车导航系统、绘图机、语音输出装置和调制解调器。计算机系统700可以包括存储子系统718,存储子系统718包括被示为当前位于系统存储器710内的软件元素。系统存储器710可以存储可加载在处理单元704上并且在处理单元704上可执行的程序指令以及在这些程序执行期间产生的数据。根据计算机系统700的配置和类型,系统存储器710可以是易失性的(诸如随机存取存储器(ram))和/或非易失性的(诸如只读存储器(rom)、闪存等)。ram通常包含处理单元704可立即访问的和/或目前正被处理单元704操作和执行的数据和/或程序模块。在一些实现中,系统存储器710可以包括多种不同类型的存储器,诸如静态随机存取存储器(sram)或动态随机存取存储器(dram)。在一些实现中,包含有助于在计算机系统700内的元件之间传送信息(诸如在启动期间)的基本例程的基本输入/输出系统(bios)通常可以被存储在rom中。以举例而非限制的方式,系统存储器710还例示了应用程序712、程序数据714和操作系统716,应用程序712可以包括客户端应用、web浏览器、中间层应用、关系数据库管理系统(rdbms)等。举例来说,操作系统716可以包括各种版本的microsoftapple和/或linux操作系统、各种市售的或unix类似的操作系统(包括,但不限于,各种gnu/linux操作系统、googleos等)和/或移动操作系统(诸如ios、phone、os、10os以及os操作系统)。存储子系统718还可以提供用于存储提供一些实施例的功能性的基本编程和数据构造的有形的计算机可读存储介质。当被处理器执行时提供上述功能性的软件(程序、代码模块、指令)可以存储在存储子系统718中。这些软件模块或指令可以由处理单元704执行。存储子系统718还可以提供用于存储根据本发明使用的数据的储存库。存储子系统700还可以包括可以进一步连接到计算机可读存储介质722的计算机可读存储介质读取器720。共同地以及可选地,结合系统存储器710,计算机可读存储介质722可以全面地表示远程的、本地的、固定的和/或可移除的存储装置加上用于暂时和/或更持久地包含、存储、发送和检索计算机可读信息的存储介质。包含代码或代码部分的计算机可读存储介质722还可以包括本领域中已知或使用的任何适当的介质,包括存储介质和通信介质,诸如但不限于,用用于存储和/或发送信息的任何方法或技术实现的易失性的和非易失性的、可移除的和不可移除的介质。这可以包括有形的非暂时性的计算机可读存储介质,诸如ram、rom、电可擦除可编程rom(eeprom)、闪存或其他存储器技术,cd-rom、数字多功能盘(dvd)或其他光学储存器,磁盒、磁带、磁盘储存器或其他磁性存储装置,或其他有形的计算机可读介质。当被指定时,这还可以包括非有形的暂时性的计算机可读介质,诸如数字信号、数据发送、或可以用于发送期望的信息并且可以被计算系统700访问的任何其他的介质。举例来说,计算机可读存储介质722可以包括对不可移除的非易失性的磁性介质进行读写的硬盘驱动器、对可移除的非易失性的磁盘进行读写的磁盘驱动器、以及对可移除的非易失性的光盘(诸如cdrom、dvd和blu-盘)或其他光学介质进行读写的光盘驱动器。计算机可读存储介质722可以包括但不限于,驱动器、闪存卡、通用串行总线(usb)闪速驱动器、安全数字(sd)卡、dvd盘、数字视频带等。计算机可读存储介质722还可以包括基于非易失性存储器的固态驱动器(ssd),诸如基于闪存的ssd、企业闪速驱动器、固态rom等、基于易失性存储器(诸如固态ram、动态ram、静态ram)的ssd、基于dram的ssd、磁阻ram(mram)ssd、以及使用dram和基于闪存的ssd的组合的混合ssd。磁盘驱动器及其相关联的计算机可读介质可以提供用于计算机系统700的计算机可读指令、数据结构、程序模块和其他数据的非易失性存储设备。通信子系统724提供与其他计算机系统和网络的接口。通信子系统724用作用于从计算机系统700接收数据并且将数据发送到计算机系统700的接口。例如,通信子系统724可以使得计算机系统700能够经由互联网连接到一个或多个装置。在一些实施例中,通信子系统724可以包括射频(rf)收发器组件、全球定位系统(gps)接收器组件和/或其他组件,其中rf收发器组件用于访问无线语音和/或数据网络(例如,通过使用蜂窝电话技术、高级数据网络技术(诸如3g、4g或edge(全球演进增强数据速率)、wifi(ieee802.11族标准、或其他移动通信技术、或它们的任何组合))。在一些实施例中,除了无线接口之外或者代替无线接口,通信子系统724可以提供有线的网络连接(例如,以太网)。在一些实施例中,通信子系统724还可以代表可以使用计算机系统700的一个或多个用户接收结构化的和/或非结构化的数据馈送726、事件流728、事件更新730等的形式的输入通信。举例来说,通信子系统724可以被配置为实时地接收来自社交网络和/或其他通信服务(诸如馈送、更新、web馈送(诸如丰富站点摘要(rss)馈送))的用户的数据馈送726、和/或来自一个或多个第三方信息源的实时更新。另外,通信子系统724还可以被配置为接收连续的数据流的形式的数据,该数据可以包括实时事件的事件流728和/或事件更新730(其本质上是连续的或无界的、没有明确结束)。产生连续的数据的应用的例子可以包括例如传感器数据应用、金融收报机、网络性能测量工具(例如,网络监视和通信量管理应用)、点击流分析工具、汽车交通监视等。通信子系统724还可以被配置为将结构化的和/或非结构化的数据馈送726、事件流728、事件更新730等输出到一个或多个数据库,所述一个或多个数据库可以与耦合到计算机系统700的一个或多个流传输数据源计算机进行通信。计算机系统700可以是各种类型之一,包括手持便携式装置(例如,蜂窝电话、计算平板、pda)、可穿戴装置(例如,google头戴式显示器)、pc、工作站、大型机、信息亭、服务器机架或任何其他的数据处理系统。由于计算机和网络的不断变化的性质,图中描绘的计算机系统700的描述仅意图作为特定的例子。许多其他的具有比图中描绘的系统多或少的组件的配置是可能的。例如,定制的硬件也可以被使用,和/或特定的元件可以用硬件、固件、软件(包括小应用程序)或组合来实现。此外,与其他计算装置(诸如网络输入/输出装置)的连接可以被采用。基于本文中提供的公开和教导,本领域的普通技术人员将意识到实现各种实施例的其他方式和/或方法。在前面的描述中,本发明的各方面是参照其特定的实施例描述的,但是本领域技术人员将认识到本发明不限于此。上述发明的各特征和方面可以单个地或联合地使用。此外,在不脱离说明书的更广泛的精神和范围的情况下,实施例可以被用在除了本文中描述的那些环境和应用之外的任何数量的环境和应用中。说明书和附图因此要被认为是说明性的而非限制性的。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1