在自动聊天中推荐朋友的制作方法
人工智能(ai)聊天机器人正在变得越来越受欢迎,并且正在被应用到越来越多的场景中。聊天机器人被设计为模拟人类的对话,并且通过文本、语音、图像等与用户聊天。
技术实现要素:
以下提供本发明内容以介绍将在下文具体实施方式中进一步描述的一些概念。本发明内容不旨在标识所要求保护的话题的关键特征或者必要特征,也不旨在用于限制所要求保护的话题的范围。
本公开的实施例提出了一种用于在自动聊天中推荐朋友的方法。在聊天流中接收消息。从该消息中识别寻找朋友的意图。基于话题知识图谱,识别一个或多个推荐的朋友。在该聊天流中提供所推荐的朋友。
应该注意,上述一个或多个方面包括在下文充分描述且在权利要求书中特别指出的特征。以下描述和附图详细陈述了该一个或多个方面的某些说明性的特征。这些特征仅表示利用各方面原理的各种方式,而本公开旨在涵盖所有此类方面以及其等效物。
附图说明
以下将结合附图来描述所公开的各个方面,这些附图是用来说明而不是限制所公开的各个方面。
图1示出了根据一个实施例的聊天机器人的示例性应用场景。
图2示出了根据一个实施例的示例性聊天机器人系统。
图3示出了根据一个实施例的示例性聊天窗口。
图4a-4d中的每一个图示出了根据一个实施例的示例性聊天流。
图5示出了根据一个实施例的用于构建用户-话题知识图谱的示例性过程。
图6示出了根据一个实施例的用于构建用户-话题知识图谱的示例性过程。
图7示出了根据一个实施例的用于从图像生成文本的示例性神经网络。
图8示出了根据一个实施例的用户-话题知识图谱中的示例性用户-话题连接。
图9示出了根据一个实施例的用于在自动聊天中推荐朋友的示例性过程。
图10示出了根据一个实施例的用于在自动聊天中推荐朋友的示例性过程。
图11示出了根据一个实施例的用于在自动聊天中推荐朋友的示例性装置。
图12示出了根据一个实施例的示例性计算系统。
具体实施方式
以下将结合若干示例性实施方式来阐述本公开。应该理解,阐述这些实施方式仅仅是为了使本领域技术人员能够更好地理解并且从而实施本公开的实施例,而不代表对本公开的范围的任何限制。
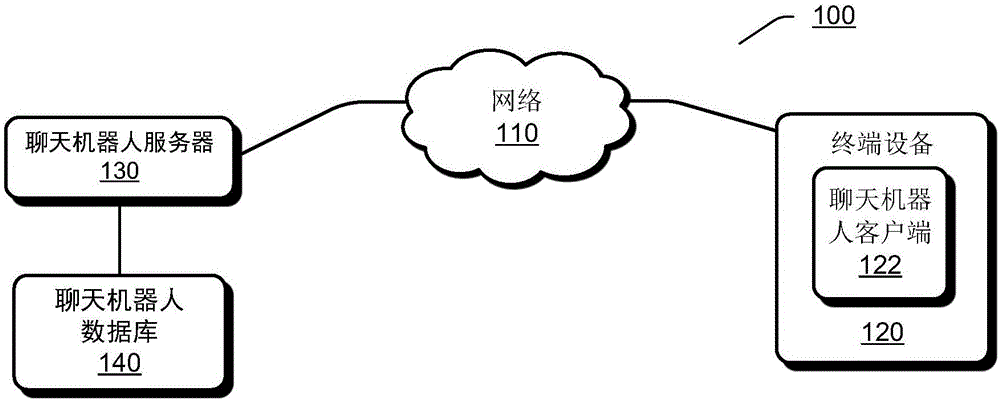
图1示出了根据一个实施例的聊天机器人的示例性应用场景100。
在图1中,网络110被应用于将终端设备120和聊天机器人服务器130互连。网络110可以是能够将网络实体互连的任何类型的网络。网络110可以是单个的网络或者是各种网络的组合。从覆盖范围方面来说,网络110可以是局域网(lan)、广域网(wan)等。从承载媒介方面来说,网络110可以是有线网络、无线网络等。从数据交换技术方面来说,网络110可以是电路交换网络、分组交换网络等。
终端设备120可以是能够执行连接到网络110、访问网络110上的服务器或网站、处理数据或信号等操作的任何类型的电子计算设备。例如,终端设备120可以是台式计算机、膝上型计算机、平板电脑、智能电话等。尽管在图1中仅示出了一个终端设备120,但是应该理解,不同数量的终端设备可能连接到网络110。
终端设备120包括可为用户提供自动聊天服务的聊天机器人客户端122。在一些实现中,聊天机器人客户端122可以与聊天机器人服务器130交互。例如,聊天机器人客户端122可以将用户输入的消息传输到聊天机器人服务器130,并且接收与来自聊天机器人服务器130的与该消息相关联的响应。然而,应该理解,在其他实现中,不与聊天机器人服务器130交互,聊天机器人客户端122也可以本地地生成针对用户输入的消息的响应。
聊天机器人服务器130可以连接到或包括聊天机器人数据库140。聊天机器人数据库140可以包括可由聊天机器人服务器130使用以生成响应的信息。
应该理解,图1中所示的所有网络实体均是示例性的,并且根据具体的应用需求,该应用环境100中还可以包括任何其他网络实体。
图2示出了根据一个实施例的示例性聊天机器人系统200。
聊天机器人系统200可以包括用于呈现聊天窗口的用户界面(ui)210。该聊天机器人使用该聊天窗口与用户进行交互。
聊天机器人系统200可以包括核心处理模块220。核心处理模块220被配置为用于在该聊天机器人的操作期间,通过与聊天机器人系统200的其他模块的协作提供处理能力。
核心处理模块220可以获得用户在该聊天窗口中输入的消息,并将该消息存储在消息队列232中。该消息可以是各种多媒体形式,例如文本、语音、图像、视频等。
核心处理模块220可以以先进先出的方式处理消息队列232中的消息。核心处理模块220可以调用应用程序接口(api)模块240中的处理单元来处理各种形式的消息。api模块240可以包括文本处理单元242、语音处理单元244、图像处理单元246等。
对于文本消息,文本处理单元242对文本消息执行文本理解,核心处理模块220进一步确定文本响应。
对于语音消息,语音处理单元244对语音消息执行语音到文本转换以获得文本句子,文本处理单元242对获得的文本句子执行文本理解,核心处理模块220进一步确定文本响应。如果确定要以语音的形式提供响应,则语音处理单元244对文本响应执行文本到语音转换以生成相应的语音响应。
对于图像消息,图像处理单元246对图像消息执行图像识别以生成相应的文本,核心处理模块220进一步确定文本响应。在某些情况下,图像处理单元246也可以用于基于文本响应获得图像响应。
此外,虽然未在图2中示出,但是api模块240还可以包括任何其他处理单元。例如,api模块240可以包括视频处理单元,用于与核心处理模块220合作以处理视频消息并确定响应。
核心处理模块220可以通过索引数据库250确定响应。索引数据库250可以包括多个索引项目,该多个索引项目可由核心处理模块220获取作为响应。索引数据库250中的索引项目可以包括纯聊天索引集合252和话题知识数据集合254。纯聊天索引集合252可以包括为用户和聊天机器人之间的闲聊而准备的索引项目,并且可以是利用来自社交网络的数据而建立的。纯聊天索引集合252中的索引项目可以是、也可以不是问答对的形式。问答对也可以被称为消息-响应对或者查询-响应对。话题知识数据集合254可以包括与各种用户和/或用户组相关的话题知识数据。该用户或用户组可以是聊天机器人系统200的用户或用户组,并且还可以是诸如社交网络平台的另一平台的用户或用户组。例如,社交网络平台可能是推特、微博等。该话题知识数据可以基于聊天机器人系统的用户日志数据生成,并且可以基于来自网络(例如,社交网络平台或诸如维基百科等知识型网站)的网络数据生成。知识数据库中的话题知识数据也可以被称为话题知识图谱。
核心处理模块220可以利用朋友寻求意图分类器260从用户发送的消息中识别是否存在寻找朋友的意图。核心处理模块220可以利用候选朋友排序器270基于话题知识图谱254为用户识别一个或多个推荐的朋友。候选朋友排序器270可以基于用户和潜在朋友(如个体用户和/或用户组)之间的排序得分识别一个或多个推荐的朋友。所识别的推荐朋友的信息可以被视为针对用户消息的响应。
可以将由核心处理模块220确定的响应提供给响应队列或响应高速缓存234。例如,响应高速缓存234可以确保在预定义的时间流中显示一系列响应。假设对于消息,存在由核心处理模块220确定的不少于两个响应,则可能需要为响应设置时间延迟。例如,如果玩家输入的消息是“你吃早饭了吗?”,可以确定两个响应,如第一个响应是“是的,我吃了面包”,第二个响应是“你呢?还觉得饿吗?”。在这种情况下,通过响应高速缓存234,该聊天机器人可以确保立即向该玩家提供该第一响应。进一步地,该聊天机器人可以确保在诸如1或2秒的时间延迟后提供该第二响应,使得该第二响应随该第一响应1或2秒之后提供给该用户。因此,响应高速缓存234可以管理将要发送的响应和用于每个响应的适当的时间。
可以将响应队列或响应高速缓存234中的响应进一步地传送到用户界面210,使得该响应可以在聊天窗口中显示给用户。
用户界面210可以在聊天机器人系统200中实现,并且还可以在另一个平台上实现。例如,用户界面210可以在第三方聊天应用上实现,例如连我、微信等。在任何一种情况下,与该聊天机器人有关系的用户和用户组被视为该聊天机器人系统的用户或用户组。
应该理解,图2中的聊天机器人系统200中示出的所有元素都是示例性的,并且根据具体的应用需求,可以省略一些所示出的元素,而一些其他元素也可能被包含在聊天机器人系统200中。
图3示出了根据一个实施例的示例性聊天窗口300。聊天窗口300可以包括呈现区域310、控制区域320和输入区域330。呈现区域310显示聊天流中的消息和响应。控制区域320包括用于用户执行消息输入设置的多个虚拟按钮。例如,用户可以选择通过控制区域320进行语音输入、附加图像文件、选择表情符号、建立当前屏幕的快捷方式等。输入区域330用于用户输入消息。例如,用户可以通过输入区域330键入文本。聊天窗口300还可以包括用于确认发送输入消息的虚拟按钮340。如果用户触摸虚拟按钮340,输入到输入区域330中的消息可以被发送到呈现区域310。
应该注意的是,在图3中示出的所有元素及其布局都是示例性的。根据具体的应用需求,图3中的聊天窗口中可以省略或添加某些元素,并且图3中的聊天窗口中的元素的布局也可以以各种方式改变。
图4a示出了根据一个实施例的示例性聊天流400a。在图4a中仅示出了ui的呈现区域310。在示例性聊天流400a中,聊天机器人响应于用户的消息或查询提供朋友推荐。
当用户输入消息“新朋友?”时,聊天机器人可以通过使用朋友寻求意图分类器260从该消息中识别寻找朋友的意图。朋友寻求意图分类器260可以是二元分类器,例如机器学习模型,其被训练成将查询分类为具有寻找朋友的意图或者不具有这样的意图。朋友寻求意图分类器260也可以是多元分类器,其被训练成将查询分类为具有寻找朋友的意图或者具有其他意图。
在从该消息中识别寻找朋友的意图之后,聊天机器人利用候选朋友排序器270基于话题知识图谱254为该用户找到推荐的朋友。话题知识图谱254包括用户或用户组中的每一个用户或用户组的各种话题信息的记录。
话题知识图谱254还可以包括与用户或用户组的话题的特定记录相关联的位置和/或时间信息。例如,如果用户发送消息,如“我每周二晚上在八中打篮球”,则从该消息获得的该话题的特定记录是“打篮球”或“篮球”,与该记录相关的时间信息是“每周二晚上”,与该记录相关的位置信息是“八中”。作为另一示例,时间信息可以是发送该消息的时间,而位置信息可以是测量位置,如在发送该消息时的gps位置。
话题知识图谱254还可以包括与用户或用户组的话题的特定记录相关联的兴趣度信息。兴趣度指示用户喜欢或讨厌该话题的程度。通过对从中获得话题知识的该特定记录的消息执行情绪分析(sa),可以获得兴趣度。以上述消息“我每周二晚上在八中打篮球”为例,关于这个消息的情绪分析结果可能是一个如0.8的值,其指示相对积极的情绪。例如,该情绪分析得分可能在[0,1]范围内,其中0.5指示中立,得分越低,情绪越消极,而得分越高,情绪越积极。再例如,情绪分析得分只有三个值,即0指示消极情绪,0.5指示中立情绪,1指示积极情绪。
话题知识图谱254包括当前用户已经提到的各种话题的记录以及可选地,与该记录相关的位置、时间和兴趣得分,因此,在话题知识图谱254中包含当前用户的在话题方面的简档。类似地,其他用户或用户组的话题方面的简档也包含在话题知识图谱254中。因此,聊天机器人可以利用候选朋友排序器270基于话题知识图谱254对该其他用户或用户组排序,以便找到推荐的朋友。特别地,候选朋友排序器270可以计算该当前用户和该其他用户或用户组之间的相似性得分,并且选择具有最高得分的用户或用户组作为该当前用户的推荐朋友。
图4a中示出了四位推荐的朋友。第一个项目<用户1,话题1,50%>,其指示对于话题1,如打篮球,用户1和当前用户具有相同或相似的兴趣,并且关于这个话题1,用户1和当前用户的匹配度或概率是50%。该概率可以是关于话题1的当前用户和用户1之间的相似性得分。
第二个项目<用户2,话题2,40%>,其指示对于话题2,如打网球,用户2和当前用户具有相同或相似的兴趣,并且关于这个话题2,用户2和当前用户的匹配概率是40%。
第三个项目<组1,话题3,30%>,其指示对于话题3,如电影,用户组1和当前用户具有相同或相似的兴趣,并且关于这个话题3,用户组1和当前用户的匹配概率是30%。例如,用户组1可以是电影话题组。
第四个项目<组2,话题2,30%>,其指示对于话题2,如打网球,用户组2和当前用户具有相同或相似的兴趣,并且关于这个话题2,用户组2和当前用户的匹配概率是30%。例如,用户组2可以是网球爱好者组。
应该理解,用户或用户组不限于聊天机器人系统的用户或用户组,并且可以是其他平台的用户或用户组,例如像推特、微博之类的社交网络。在这方面,跨平台的朋友推荐可以由聊天机器人实现。
用户1可以是用户的名称,也可以是到用户的链接。当前用户可以点击“用户1”元素以到达用于添加或请求用户1成为朋友的界面。例如,用户1可以是聊天机器人系统或第三方聊天系统(如连我或微信)的用户,并且当前用户可以发送与用户1成为朋友的请求。例如,用户1可以是诸如推特或微博等社交网络的用户,当前用户可以在该社交网络上添加用户1的订阅。类似地,组1可以是用户组的名称,也可以是到该组的链接。当前用户可以点击“组1”元素以到达用于加入组1的界面。
当前用户可以在聊天流中发送诸如“用户1”的文本消息或语音消息。响应于用户的该消息,聊天机器人可以打开用于添加或请求用户1成为朋友的界面。当前用户可以在聊天流中发送诸如“组1”的文本消息或语音消息。响应于用户的该消息,聊天机器人可以打开用于请求加入用户组1的界面。
图4b示出了根据一个实施例的示例性聊天流400b。
当用户输入“附近有人可以和我打网球吗?”的消息时,通过使用朋友寻求意图分类器260,聊天机器人可以从该消息中识别寻找朋友的意图。除了该意图以外,还从该消息中获得话题信息“打网球”和位置信息“附件”,其中,基于当前用户的当前物理位置,如gps位置等,可以确定该位置信息。句法和语义分析方法可用于从该消息中识别话题信息和位置信息。
然后,基于话题知识图谱254和位置信息,候选朋友排序器270识别针对该用户推荐的朋友。由于寻找推荐的朋友可能需要一个可感知的时间周期,聊天机器人可以输出闲聊,如“是的!打网球很有趣!处理中……”。
图4b中示出了四位推荐的朋友。第一个项目<用户1,位置1,50%>,其指示用户1有50%的概率可能在位置1与当前用户打网球。该概率可以是关于网球话题当前用户和用户1之间的相似性得分。第二个项目<用户2,位置2,40%>,其指示用户2有40%的概率可能在位置2与当前用户打网球。第三个项目<组1,位置3,30%>,其指示用户组1有30%的概率可能在位置3的当前用户打网球。第四个项目<组2,位置4,30%>,其指示用户组2有30%的概率可能在位置4与当前用户打网球。
图4c示出了根据一个实施例的示例性聊天流400c。
当用户输入“晚上有人可以打网球吗?”的消息时,通过使用朋友寻求意图分类器260,聊天机器人可以从该消息中识别寻找朋友的意图。除了该意图之外,还从该消息中获得话题信息“打网球”和时间信息“晚上”。句法和语义分析方法可用于从该消息中识别话题信息和时间信息。
然后,基于话题知识图谱254和时间信息,候选朋友排序器270识别针对该用户推荐的朋友。图4c中示出了四位推荐的朋友。第一个项目<用户1,位置1,时间1,50%>,其指示用户1有50%的概率可能与当前用户在位置1、时间1打网球。该概率可以是关于网球话题当前用户和用户1之间的相似性得分。第二个项目<用户2,位置2,时间1,40%>,其指示用户2有40%的概率可能与当前用户在位置2、时间1打网球。第三个项目<组1,位置3,时间2,30%>,其指示用户组1有30%的概率可能与当前用户在位置3、时间2打网球。第四个项目<组2,位置4,时间3,30%>,其指示用户组2有30%的概率可能与当前用户在位置4、时间3打网球。
图4d示出了根据一个实施例的示例性聊天流400d。聊天流400d涉及一组参与者,包括诸如用户a、用户b、用户c和聊天机器人的用户。该组参与者可以被称为兴趣组或用户组。在这个示例中,兴趣组的名称是“电影迷”。有各种兴趣组,如电影明星组、足球组、网球组、体育组、健身组、名人组、工作组,等等。
当用户a输入消息“有人看过‘日落之前’吗?”时,聊天机器人可以通过使用朋友寻求意图分类器260从该消息中识别寻找朋友的意图,并且可以从该消息中识别话题信息“日落之前”。
在一种情况下,如果在预定时间周期内没有用户对用户a的该消息做出响应,则聊天机器人可以基于话题知识图谱254和话题信息“日落之前”寻找当前兴趣组之外的新朋友。可以将该朋友推荐给用户a或当前组。
图4d中示出了四位推荐的朋友。第一个项目<用户1,50%>,其指示针对话题“日落之前”,用户1的匹配概率为50%。第二个项目<用户2,40%>,其指示针对话题“日落之前”,用户2的匹配概率为40%。第三个项目<组1,30%>,其指示针对话题“日落之前”,用户组1的匹配概率为30%。第四个项目<组2,30%>,其指示针对话题“日落之前”,用户组2的匹配概率为30%。
用户a或另一用户,例如用户b或c,可以基于推荐的朋友进行操作。例如,用户a可以输出文本或语音消息让聊天机器人邀请用户1和/或用户2加入当前组,或让聊天机器人邀请用户a到组1和/或组2。例如,用户a可以点击多个推荐的朋友中的一个推荐的朋友以到达通信界面或达到用于添加朋友的界面,邀请相应的用户1或2加入当前组,或请求加入相应的组1或2。应该理解,基于推荐的朋友而进行的任何合适的操作都在本公开的范围之内。
图5示出了根据一个实施例的用于创建用户-话题知识图谱的示例性框架。
如502所示,两种数据,网络数据和用户日志,可被用于创建用户-话题知识图谱。用户数据包含用户发送到聊天机器人系统的文本和图像。网络数据也包含与另一个平台(如推特和微博等社交网络)的用户相关的文本和图像。该网络数据还可以包含来自基于知识的网站(如维基百科)的数据。例如,社交网络的大v用户通常是名人,可以从该社交网络获得针对该大v用户的用户-话题知识数据,并且可以从基于知识的网站(如维基百科)获得关于该大v用户的额外知识。来自社交网络和基于知识的网站的知识数据都可以用于为特定用户构建用户-话题知识图谱。应该理解,可能只有用户数据被用于创建知识图谱。应该理解,用户数据可以是用户日志数据,并且可以周期性地或实时地执行该知识图谱的创建或更新。
在504,图像可被转换为描述该图像的文本消息。可以在图像处理模块246处执行该转换。在一个实现中,利用递归神经网络(rnn)-卷积神经网络(cnn)模型从图像生成文本消息。
在506,对用户数据或网络数据的文本或从图像生成的文本进行预处理。在一个实现中,该预处理可以包括句子分割和词语分割、词性(pos)标注、名词短语提取、命名实体识别(ner)。
句子分割利用诸如句号、问号、感叹号等标点符号将文档分隔成一组句子。词语分割通过在词语以及标点符号之间添加例如空格符号,以便将他们分隔开。词性(pos)标注用于为该句子中的词语添加pos标签。然后,给定标注了pos的序列或句子,可以使用一组启发规则执行名词短语提取过程以识别名词短语。然后,ner过程可用于识别该序列或句子中的命名实体,命名实体可以是人的名字、位置、组织和描述时间戳或时间周期的短语。例如,在图6中,对于句子“我是两年前把吉娃娃带回家的”,“吉娃娃”被识别为狗的名字,“家”是一个位置名,“两年前”是以年为单位的时间戳。
在预处理阶段采用的句子/词语分割、pos标注、名词短语提取、ner中的每一项都可以通过使用现有技术来实现。然而,应该理解,在预处理阶段中的这些处理的组合可以有效地从句子中提取必要的信息,以便构建用户-话题知识图谱,该用户-话题知识图谱也对与该话题相关的时间和位置信息敏感。
在508,可对句子进行代词和普通名词的指代消解。以图6中示出的用户日志数据610为例,对用户日志数据“玲奈,你喜欢吉娃娃吗?”,“太好了,我家里有一个。我是两年前把他带回家的。”,可以在508进行预处理,以获得文本“玲奈,你喜欢吉娃娃吗?”,“太好了,我家里有吉娃娃。”和“我是两年前把吉娃娃带回家的。”,如630所示。
被称为指代消解模型的机器学习模型可以被训练,以便针对一个给定的代词,如“他”、“她”等,或者针对一个给定的普通名词,如“导演”、“cvp”等,计算候选命名实体的概率。
假设wi是一个命名实体,如在620所示的句子中的“吉娃娃”,wj是另一个名词短语,如在620所示的句子中的“一个”,指代消解模型的任务是确定wi和wj是否具有相似的意义或指向相同的实体。在一个实现中,在该指代消解模型中使用以下特征。
通过使用这些特征,可以计算该两个词语之间的相似性得分,并且可以获得二元结果,其表明该两个词语是否指相同的实体。应该理解,更多或更少的特征可以被用于该指代消解模型。
如图6的630所示,该指代消解模型可以识别代词“一个”和“他”指向相同的实体“吉娃娃”,因此,代词“一个”和“他”被命名实体“吉娃娃”所替代。
在510,可以对文本序列或句子执行句法和语义解析处理,以获得句子的句法依存结构和语义角色标注。图6中的640示出了句子的句法依存结构和语义角色标注的一个示例,其中,该结构和标注由圆弧表示。
在514,可以从句子中提取话题知识。以640处所示的句子为例,从句子“太好了,我家里有吉娃娃”的文本中获得话题“家里有吉娃娃”或“吉娃娃”,位置信息“家”,而时间信息被识别为在该自动聊天中该句子被发送的时间。例如,如图6的650中所示,该时间是2017年。应该理解,该时间可以是更精细的单位,例如月、日、小时、分钟等。从句子“我是两年前把吉娃娃带回家的”的文本中获得话题“带吉娃娃回家”或“吉娃娃”、位置信息“家”以及时间信息“两年前”。例如,从上述时间2017年减去2年,得到这一项话题信息的时间是2015年,如图6的650中所示。
在512,可以对该句子执行情绪分析(sa)以评价用户对包含在该句子中的话题的态度。该sa得分指示用户的态度,可以被称为兴趣度。该sa得分可以在[0,1]范围内,其中0.5指示中立,该得分越低,情绪越消极,而该得分越高,情绪越积极。例如,针对所示出的句子“太好了,我家里有吉娃娃”,可以获得诸如0.8的sa得分。另一方面,针对句子“实际上我不喜欢吉娃娃”,可以获得诸如0.1的sa得分,其指示对包含在该句子中的话题的负面兴趣。在一个实现中,在514处该sa得分可以被用作知识数据的元素。
如图6的650所示,针对用户a可以获得元组格式的用户-话题知识数据,即,<用户a,2015年,家,吉娃娃,带回,0.8>,<用户a,2017年,家,吉娃娃,在,0.8>。除了话题信息以外,如“吉娃娃,带回,家”,“吉娃娃,在,家”,还有位置信息,如“家”,时间信息“2015年”,“2017年”,和兴趣度信息“0.8”。
基于对用户-话题知识数据中的兴趣度或sa得分因素,针对相同或相似话题具有相同或相似态度(无论是积极的还是消极的)的两个用户可以被给于较大权重,用于对他们的匹配率排序;而另一方面,针对相同或相似话题具有相反态度(一个是积极的,而另一个是消极的)的两个用户可以被给于较小权重,用于对他们的匹配率排序。
基于在用户-话题知识数据中的位置和/或时间因素,针对相同或相似话题具有相同或相似的时隙和/或位置的两个用户可以被给于较大权重,用于对他们的匹配率排序。例如,从用户日志数据610生成在650示出的两个元组或记录,尽管两者都与同一话题“吉娃娃”有关,其中在该两个元组中提供不同的时间信息。这使得用户匹配对于话题知识图谱的时间因素是敏感的。对于话题知识图谱的位置因素,这个原理是类似的。因此,从用户的用户数据中获得的话题知识元组或记录形成了该用户的在话题、话题相关的时间信息、话题有关的位置信息、话题相关的情绪信息方面的简档。
应该理解,本公开不限于包括如上所述的各种元素的元组格式,每个元组包括更多或更少元素是可行的。
结合图5以上描述了基于用户数据构建用户-知识图谱。也可以使用网络数据通过图5中的过程获得用户-知识数据。
该网络数据可以包括在如推特或微博的第三方平台中的用户的用户日志数据。实质上这种网络数据也可被称为用户数据。并且,可以基于第三方平台用户数据为这样的第三方平台构建用户-话题知识数据。然后,可以通过使用这个用户-话题知识数据执行跨平台的朋友推荐。
网络数据还可以包括关于某个特殊用户(例如名人)的用户数据。通过图5中的过程从这种网络数据中获得的用户-话题知识数据,可被用作用于这样的用户的补充用户-话题知识数据,以便丰富该用户的在话题知识方面的简档。
例如,假设弗兰克是社交网络上的大v用户,通过图5中的过程基于该社交网络上的用户日志数据,可以获得针对该用户的用户-话题知识图谱。此外,由于弗兰克是一个有名的人,可以从基于知识的网站获得关于弗兰克的一般知识。该一般知识内容的示例可以是“弗兰克1966年出生于山西太原”,“弗兰克在12岁时被大学录取”,以及“弗兰克毕业于中国科学技术大学”,通过图5中的过程从这些一般知识内容中可以获得用户-话题知识元组,如<1966年,山西太原,弗兰克,出生,0.5>,<1978年,中国科学技术大学,弗兰克,加入,0.5>,<1982年,中国科学技术大学,弗兰克,毕业,0.5>。可以为该用户弗兰克补充所生成的用户-话题知识元组,其可以有助于基于话题、话题相关的时间和位置将该用户弗兰克推荐给另一个用户。
图7示出了根据一个实施例的示例性图像-文本转换模型。
该模型被实现为cnn-rnn模型。这个cnn-rnn网络背后的基本思想是在潜在语义空间中将文本句子和图像进行匹配,其中该句子通过rnn被投射到一个密集向量空间,而该图像通过cnn被投射到另一个密集向量空间。
cnn712是深度cnn,其将图像作为输入,并且将该图像投射到密集向量空间。该cnn的输出是在该密集向量空间中代表图像特征714的向量。可以利用现有技术,如alexnet深度cnn网络,实现用于将图像投射到密集向量空间的该深度cnn712。
rnn734是深度rnn,其将图像向量714作为输入,并且循环地生成描述该图像的句子。示例性的rnn包括嵌入层1722,嵌入层2724,循环层716,多模式层728,softmax层730。该图像向量被输入到多模式层728,嵌入层2的输出被输入到多模式层728和循环层726,循环层726的输出被输入到多模式层728。在层的顶部示出的示例性数字128、256、512表示在各层中的向量的维度。应该理解,其他维度值是可适用的。通过对密集向量空间中的向量进行矩阵运算实现从一个层到另一个层的投射。对于本领域技术人员,基于所示出的rnn中的层的连接进行矩阵运算是显而易见的。
用于该cnn-rnn模型的训练数据是<图像,句子>对,其中,该图像被视为该cnn-rnn模型的输入,而该句子被视为该cnn-rnn模型的输出。
如图7中所示,吉娃娃的图像710被输入到cnn中,在732循环地生成句子“坐在粉红色地毯上的一个如此可爱的吉娃娃”。该解码过程(句子生成过程)如下所述。
步骤1:将该图像输入到深度cnn712中,针对该图像获得密集向量714。初始输入词720是一个句子开始标志“<s>”,其用w0来表示,并且被输入到rnn734中并被转换成密集向量。
步骤2:该图像的密集向量714被发送到rnn网络的多模式层728,softmax函数730被用于计算在目标词汇集合中的词语的概率p(w1|w0,图像),然后具有最大概率的词语a被识别为下一词w1732。
步骤3:该图像向量和先前生成的部分句子,即词语w1,被作为输入以生成下一词w2。该softmax函数730被用于计算在目标词汇集合中的词语的概率p(w2|w1,w0,图像),然后具有最大概率的词语b被识别为下一词w2732。
重复步骤3将图像向量714和先前生成的部分句子作为输入,以便生成具有最高概率p(wi|w1,……,wi-1,图像)的下一词wi,其中,wi是下一词语候选,w1到wi-1是已生成的作为历史的词语。当表示句子终止的</s>符号被生成时,该生成过程停止。
应该理解,图7的cnn-rnn的具体结构是用于说明本公开,而本公开不限于此。可能针对cnn-rnn的结构做出合理的修改,并且合理的修改可适用于本公开。
图8示出了根据一个实施例的知识图谱的示例性的主动更新过程。
当一个用户a的一个话题事件,如在图6的650处所示的与话题“吉娃娃”相关的两个元组,被收集并上传到用户-话题知识图谱时,执行转移动作,其从当前用户a开始,经由当前话题a,到现有知识图谱中的其他用户和/或用户组。
如图8中所示,当当前用户a的话题a被添加到用户-话题知识图谱中时,可以从该话题a转移到该用户-话题知识图谱中已经存在的其他用户,例如所示出的用户1到组5。针对这个话题,在诸如用户1到组5的这些用户相对较长时间内都处于非活动状态的情况下,这个转移动作的目的是再次激活这些用户。
在一个转移动作的实现中,用户-话题知识图谱中具有相同话题a的用户和/或用户组中的一部分被选择,并且其对于话题a是否仍然有意见的软问题被发送到所选择的用户和/或用户组。对该用户/组的选择可以是随机的选择。对该用户/组的选择可能不被执行,而该软问题被发送到在该用户-话题知识图谱中具有相同话题a的所有用户/组。
当从被触发的用户或用户组接收到响应于该软问题的消息时,通过图5中的过程,基于该消息可以获得针对该用户或用户组的话题知识,并且通过附加该用户或用户组的新获得的话题知识,可以更新该用户-话题知识图谱。
当未能从被触发的用户或用户组接收到响应于该软问题的消息时,在用户-话题知识图谱中与该被触发的用户或用户组的话题a相关的时间信息可以被检查。如果该时间信息指示对于这个话题a,该用户已经很长时间(例如像一年或六个月的阈值)不处于活动的状态,则可以从该用户-话题知识图谱中将这个被触发的用户的话题a的记录删除。在一个实现中,时间信息可以是与该被触发的用户或用户组相关的话题a的记录被生成的时间。例如,如果该生成时间距离当前时间已经超过一年,则可将与该被触发的用户或用户组相关的话题a的这个纪录删除。
如图8中所示的对用户的这种主动触发可以帮助更新该用户-话题知识图谱,并且帮助构建将用于适时的新朋友推荐的相对较新的用户-话题知识图谱。
此外,从所选择的用户到他们的除话题a以外的话题(如话题b)执行深度传播。如图8所示,话题a和话题b通过用户4链接。话题a和话题b具有越多的用户链接,则话题a和话题b在用户-话题知识图谱谱中具有越紧密的关系,并且因此,话题a和话题b的关系被给予更高的得分。如图所示,话题a和话题b之间的链路经由一个用户,并且基于这样的单用户链接的数量可以计算关系得分。也可能是基于多用户链接的数量计算该关系得分,其中,两个话题之间的一个链接中的用户越多,则在计算这两个话题的关系得分时该链接被给予的权重越小。
通过在用户-话题知识图谱中的话题之间的深度传播,可以构建或者更新话题关系知识图谱。该话题关系知识图谱描述了用户-话题知识中的每一对话题之间的关系。由于每个话题与多个用户相连接,所以通过链接两个话题,该话题关系知识图谱隐含地连接了两组用户。该话题关系知识图谱可以是元组的格式。元组的一个示例是<话题1,话题2,关系得分>。
元组的另一个示例是<话题1,话题2,关系,得分>。该关系元素可以是默认值,其指示一般关系,例如经由用户建立的以上所讨论的关系。
在一些其他实现中,该关系可以指两个话题之间的特定关系。例如,话题a“食品”和话题b“苹果”可以是父-子关系,话题a“足球”和话题b“篮球”可以是兄-弟关系。可以基于预定义的话题-关系规则来实现两个话题之间的特定关系。在一个示例中,在计算两个话题的关系得分时,可以将额外的权重给予两个话题的特定关系。例如,相对于以上所讨论的一般关系,兄-弟关系可以被给予额外的权重,并且父-子关系可以被给与比兄-弟关系更大的额外的权重。
已经描述了对话题知识图谱254的构建和更新。话题知识图谱254包括用户-话题知识图谱和话题关系知识图谱。该用户-话题知识图谱包括元组,例如<用户,话题,兴趣度,时间,位置>,其中,该用户元素可以是用户名或用户标识,并且该用户元素也指用户组。该话题关系知识图谱包括元组,例如<话题1,话题2,关系,得分>。应该理解,一些元组可以不必包括所有元素,并且实际上,在一个元组中的或多或少的元素可以适用于本公开。
图9示出了根据一个实施例的用于为特定用户推荐朋友的示例性过程。
在910,聊天机器人在聊天流中接收来自用户的消息。该聊天流可以只涉及该聊天机器人和该用户,或者可以涉及群聊中的一组用户。例如,该消息可以是如图4a到图4d中示出的那些消息。
在920,通过使用朋友寻求意图分类器260,聊天机器人确定该消息中是否存在寻求朋友的意图。如果从消息中识别出朋友寻找意图,该过程进行到930。
在930,该聊天机器人从该消息中识别话题、时间和/或位置信息。有可能从该消息中识别不到任何话题、时间或位置信息。
在940,通过利用候选朋友排序器270,聊天机器人基于该话题知识图谱254对潜在的用户排序。对用户的排序可能也是基于在930处从该消息中提取的话题、时间和/或位置信息。
通过训练使用梯度提升决策树(gbdt)算法的成对学习排序(ltr)模型,可以实现候选朋友排序器270。话题知识图谱的元组<用户,话题,兴趣度,时间,位置>和<话题1,话题2,关系,得分>被用作这个排序模型的输入。给定发送该消息的特定用户(用户a),该ltr模型计算特定用户a和其他用户和用户组中的每一个用户和用户组之间的相似性得分。概率[0,1]被输出,作为每个用户或用户组(用户b)的相似度得分。各种特征被用于ltr模型的gbdt算法。
可用于gbdt的一个特征是链接用户a与候选用户b的最短路径的长度。在此处和下面的段落中,用户b指的是用户或用户组b。图8中示出了两个用户之间的路径。该最短路径越长,用户b被给予的权重越小。
可用于gbdt的一个特征是用户a和用户b之间共享的话题的数量。用户a和用户b之间具有的共享话题越多,用户b被给予的权重越大。
可用于gbdt的一个特征是用户a和用户b之间的共享话题的累积关系得分。例如,用户a和用户b之间有多个共享话题,话题关系知识图谱中提供的该多个话题中的每两个话题的关系得分被累积。累积的关系得分越高,用户b被给予的权重越大。
可用于gbdt的一个特征是用户a和用户b之间的共享话题占与用户a和b链接的话题总数的比率。该比率是通过将他们的共享话题数量除以与a和b链接的话题总数计算的。该比率越大,用户b被给予的权重越大。
可用于gbdt的一个特征是与用户a和用户b链接的话题之间的最小/平均词到向量(word2vector)距离。该word2vector距离反映话题(例如“吉娃娃”和“博美”)之间的潜在语义相似度。该最小/平均word2vector距离越小,用户b被给予的权重越大。
可用于gbdt的一个特征是用户a和用户b之间的共享话题的最小时间距离。例如,对于一个吉娃娃的话题,如果用户a两天前上传了吉娃娃的图像,其中在知识图谱中的时间信息是用户a发送该图像的时间,而用户b在两天前谈到喜欢吉娃娃,其中在知识图谱中的时间信息是用户b发送该相关消息的时间,那么对于吉娃娃这个话题,他们的时间距离为0。该时间距离越小,用户b被给予的权重越大。
可用于gbdt的一个特征是用户a和用户b之间的共享话题的最小位置距离。例如,对于一个篮球的话题,如果用户a谈到了在操场a打篮球,而用户b谈到了在操场b打篮球,则该位置距离是操场a和操场b之间的距离。应该理解,该位置信息也可以是用户a和/或用户b在发送关于篮球的该消息时的gps位置。该位置距离越小,用户b被给予的权重越大。
可用于gbdt的一个特征是用户a和用户b之间的共享话题是否被这两个用户都支持或者被这两个用户都不支持。例如,如果兴趣度元素指示用户a和用户b对于该共享话题都具有积极情绪,或者如果兴趣度元素指示用户a和用户b对于该共享话题都具有消极情绪,则用户b被给予较大的权重。如果对于该共享话题,用户a具有积极的态度而用户b具有消极的态度,例如,用户a喜欢吉娃娃而用户b讨厌吉娃娃,则用户b被给予较小的权重。
可用于gbdt的一个特征是从当前消息中获得的话题。如果用户a和用户b之间的共享话题与从当前消息中获得的话题相同,则用户b被给予较大的权重。
可用于gbdt的一个特征是从当前消息中获得的时间与用户b的共享话题的时间之间的最小时间距离。对于用户a和用户b之间的共享话题,该最小时间距离越小,用户b被给予的权重越大。
可用于gbdt的一个特征是从当前消息中获得的位置和用户b的共享话题的位置之间的最小位置距离。对于用户a和用户b之间的共享话题,该最小位置距离越小,用户b被给予的权重越大。
可用于gbdt的一个特征是话题知识图谱的来源。对由网络数据导出的话题知识图谱给予折扣,以便解决由网络数据产生的知识图谱的噪声问题。例如,如果用户b的话题知识图谱是由网络数据导出的,则对用户b的得分给予折扣。
应该理解,不是所有上述特征都一定被用于gbdt,更多或更少的特征是可适用的,以便对用户排序。
尽管从用户a的消息中获得的话题信息在一个实现中被视为如上所讨论的特征,在另一个实现中该特征可能不被使用。也就是说,当该话题信息在930被识别时,该ltr模型可以仅遍历在用户-话题知识图谱中具有该话题信息的用户,而略过不具有该话题的用户。在这个实现中,在940对用户的排序实际上也考虑了从用户a的消息中获得的话题信息。
在950,具有最高排序得分的用户被选择作为当前用户a的推荐用户。
图10示出了根据一个实施例的在自动聊天中推荐朋友的过程100。
在1010,在聊天流中接收来自用户的消息。在1020,从该消息中识别寻找朋友的意图。在1030,基于话题知识图谱,识别一个或多个推荐的朋友。在1040,在聊天流中提供所推荐的朋友。该朋友包括个体用户和/或用户组。
在一个实现中,从该消息中识别话题信息、位置信息和时间信息中的至少一个。基于话题知识图谱、以及话题信息、位置信息和时间信息中的至少一个,识别该一个或多个推荐的朋友。
在一个实现中,在该聊天流中一同提供所推荐的朋友、以及话题信息、位置信息、时间信息和概率信息中的至少一个。
在一个实现中,该话题知识图谱包括用户-话题知识图谱,其包括用于用户和/或用户组中的每一个用户和/或用户组的用户或组信息、话题信息、兴趣度信息、位置信息和时间信息中的至少一部分。该位置信息与该话题的特定记录相关,该时间信息与该话题的特定记录相关。
该话题知识图谱还包括话题关系知识图谱,其包括话题之间的话题关系信息。
在一个实现中,基于用户数据和/或网络数据,为用户和/或用户组中的每一个用户和/或用户组生成用户-话题知识图谱。基于该用户-话题知识图谱,生成话题关系知识图谱。
在一个实现中,从用户数据和/或网络数据的文本消息中提取用户或组信息、话题信息、兴趣度信息、位置信息和时间信息中的至少一部分。
在一个实现中,从用户数据和/或网络数据的图像生成文本消息,然后,从该文本消息生成用户或组信息、话题信息、兴趣度信息、位置信息和时间信息中的至少一部分。
在一个实现中,通过rnn-cnn模型从该图像获得该文本消息。
在一个实现中,通过对该文本消息执行情绪分析,生成兴趣度信息。该情绪分析得分被用作兴趣度。
在一个实现中,用户话题知识图谱采用元组的形式,其中元组包括用户或组信息、话题信息、兴趣度信息、时间信息和位置信息中的至少一部分。话题关系知识图谱采用元组的形式,其中元组包括第一话题、第二话题、话题关系、得分中的至少一部分。
在一个实现中,从第一用户的消息中提取话题。该第一用户的话题被添加或上传到用户-话题知识图谱中。然后,将与该话题相关的问题发送给在用户-话题知识图谱中已经具有该话题的第二用户。从第二用户中的至少一部分获得应答。基于该第二用户的应答,更新用户-话题知识图谱。基于该更新的用户-话题知识图谱,更新话题关系知识图谱。
图11示出了根据一个实施例的用于在自动聊天中推荐朋友的示例性装置1100。
装置1100包括消息接收模块1110,用于在聊天流中接收来自用户的消息,意图识别模块1120,用于从该消息中识别寻找朋友的意图,朋友识别模块1130,用于基于话题知识图谱识别一个或多个推荐的朋友,以及朋友呈现模块1140,用于在聊天流中呈现所推荐的朋友。该朋友包括个体用户和/或用户组。
在一个实现中,装置1100包括消息信息识别模块,用于从该消息中识别话题信息、位置信息和时间信息中的至少一个。基于话题知识图谱、以及话题信息、位置信息和时间信息中的至少一个,朋友识别模块1130识别一个或多个推荐的朋友。
在一个实现中,朋友呈现模块1140在聊天流中关联地提供所推荐的朋友、以及话题信息、位置信息、时间信息和概率信息中的至少一个。
在一个实现中,话题知识图谱包括用户-话题知识图谱,其包括用于用户和/或用户组中的每一个用户和/或用户组的用户或组信息、话题信息、兴趣度信息、位置信息和时间信息中的至少一部分。该话题知识图谱包括话题关系知识图谱,其包括话题之间的话题关系信息。
在一个实现中,装置1100包括话题知识图谱生成模块,用于基于用户数据和/或网络数据,生成用于用户和/或用户组中的每一个用户和/或用户组的用户-话题知识图谱。基于用户-话题知识图谱,该话题知识图谱生成模块生成话题关系知识图谱。
在一个实现中,通过以下步骤,该话题知识图谱生成模块生成用于用户和/或用户组中的每一个用户和/或用户组的用户-话题知识图谱:从该用户数据和/或网络数据的文本消息中,提取用户或组信息、话题信息、兴趣度信息、位置信息和时间信息中的至少一部分;和/或从该用户数据和/或网络数据的图像生成文本消息,并且从该文本消息中提取用户或组信息、话题信息、兴趣度信息、位置信息和时间信息中的至少一部分。
在一个实现中,通过rnn-cnn模型从该图像获得文本消息。
在一个实现中,该话题知识图谱生成模块通过对该文本消息执行情绪分析来提取兴趣度信息。
在一个实现中,该话题知识图谱生成模块从第一用户的消息中提取话题,将该第一用户的该话题添加到用户-话题知识图谱中,将与该话题相关的问题发送到在用户-话题知识图谱中已经具有该话题的第二用户,从该第二用户中的至少一部分获得应答,并且基于该第二用户的应答,更新该用户-话题知识图谱。
在一个实现中,该话题知识图谱生成模块基于更新的用户-话题知识图谱更新该话题关系知识图谱。
应该理解,装置1100可以包括被配置为用于执行根据以上结合图1-10所述的本公开各实施例来执行任何操作的任何其它模块。
图12示出了根据一个实施例的用于在自动聊天中推荐朋友的示例性计算系统1200。
计算系统1200可以包括至少一个处理器1210。计算系统1200可以进一步包括与处理器1210连接的存储器1220。存储器1220可以存储计算机可执行指令,该计算机可执行指令在被执行时,使得处理器1210在聊天流中接收来自用户的消息,从该消息中识别寻找朋友的意图,基于话题知识图谱识别一个或多个推荐的朋友,并且在该聊天流中提供推荐的朋友。
应该理解,存储器1220可以存储计算机可执行指令,该计算机可执行指令在被执行时,使得处理器1210执行根据以上结合图1-11所述的本公开的实施例的任何操作。
本公开的实施例可以被实现在计算机可读介质中,如非易失性计算机可读介质。该非易失性计算机可读介质包括指令,该指令被执行时,使得一个或多个处理器执行根据以上结合图1-11所述的本公开的实施例的任何操作。
应该理解,以上所描述的方法中的所有操作都仅仅是示例性的,而本公开不仅限于该方法中的任何操作或者这些操作的执行顺序,并且应当涵盖与之具有相同或相似概念的所有其他等同物。
还应当理解,以上所描述的装置中的所有模块可以以各种方式来实现。这些模块可被实现为硬件、软件、或两者的组合。此外,任何这些模块都可以在功能上进一步被划分为子模块或被组合在一起。
结合各种装置和方法已经对处理器进行了描述。这些处理器可以使用电子硬件、计算机软件或其两者任意组合来实现。至于这些处理器是实现为硬件还是软件,取决于特定的应用以及施加在系统上的整体设计约束。举例来说,本公开提供的处理器、处理器的任何部分、或处理器的任何组合可以利用微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、可编程逻辑设备(pld)、状态机、门控逻辑、离散硬件电路、以及被配置成执行本公开所描述的各种功能的其他合适的处理组件来实现。本公开提供的处理器、处理器的任何部分、或处理器的任何组合的功能可以利用由微处理器、微控制器、dsp或其他合适的平台执行的软件来实现。
软件应当被宽泛地解释成意指指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、执行线程、流程、功能等。该软件可驻留在计算机可读介质上。计算机可读介质可以包括,例如,诸如磁存储设备(如硬盘,软盘,磁条)、光盘、智能卡、闪存设备、随机存取存储器(ram)、只读存储器(rom)、可编程rom(prom)、可擦除prom(eprom)、电可擦除prom(eeprom)、寄存器、或可移动磁盘的存储器。尽管在本公开中的各个方面中存储器被示为与处理器是分开的,但对于处理器来说,存储器可以在其内部(例如,高速缓存或寄存器)。
提供以上描述是为了使任何本领域技术人员均能实践其中所描述的各个方面。对于这些方面的各种修改对于本领域技术人员来说是显而易见的,此处定义的一般原理适用于其他方面。因此,权利要求并非旨在被限定于以上所描述的各个方面。本公开描述的各个方面中包含的各要素的为本领域普通技术人员当前或今后所知的所有结构上和功能上的等效方案以引用的方式被明确添加在此,并且旨在被权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!