用于辅助机动车辆的驾驶员驾驶机动车辆的方法、驾驶员辅助系统以及机动车辆与流程
本发明涉及一种用于辅助机动车辆的驾驶员驾驶机动车辆的方法,其中,基于通过至少一个车辆侧相机从机动车辆的环境区域捕获的图像数据,创建环境区域的至少一个图像以用于在车辆侧显示装置上显示。此外,本发明涉及一种驾驶员辅助系统以及具有这种驾驶员辅助系统的机动车辆。
背景技术:
从现有技术中已知通过例如在车辆侧显示装置上显示由车辆侧相机系统捕获的机动车辆的环境区域来辅助机动车辆的驾驶员驾驶机动车辆。其中,环境区域的三维表示也越来越多地从所谓的第三人的角度显示在显示装置上。这样的第三人的角度从车辆外部的观察者、即所谓的虚拟相机的视角示出了机动车辆的环境区域以及机动车辆本身,并且呈现了对于驾驶员特别直观的环境区域的视图。为了创建第三人的角度,通常根据车辆侧相机系统的图像数据确定环境区域的图像,其给出的印象就好像它是由虚拟相机的位置中的真实相机捕获的。
由于通常只有车辆侧相机系统的图像数据可以用于创建第三人的角度,因此不可能捕获背离车辆侧相机系统从而在相机系统的捕获范围之外的、对象的侧面。因此,不能任意选择虚拟相机的位置,或者生成对驾驶员不直观的环境区域的图像,由此驾驶员不能可靠地估计当前交通状况或场景。
另外,可能发生的是,在配备有鱼眼镜头的相机的情况下,对象的尺寸感知取决于对象到机动车辆的位置。这还可能导致显示装置上的环境区域中的当前场景的非直观表示。此外,在组合或缝合各种相机的图像数据(例如,机动车辆的前端相机和横向相机的图像数据)时,当对象在相机的捕获范围之间变化从而在盲点内时,信息可能丢失。这种信息丢失也可能导致不正确地生成的环境区域的图像。
技术实现要素:
本发明的目的是提供一种解决方案,即如何可靠地捕获机动车辆的环境区域,使得可以辅助机动车辆的驾驶员驾驶机动车辆。
根据本发明,该目的通过根据相应独立权利要求的方法、驾驶员辅助系统以及机动车辆来解决。本发明的有利实施例是从属权利要求、说明书以及附图的主题。
在用于辅助机动车辆的驾驶员驾驶机动车辆的方法的实施例中,基于通过至少一个车辆侧相机从机动车辆的环境区域捕获的图像数据,环境区域的至少一个图像被创建用于在车辆侧显示装置上显示。特别地,基于图像数据标识环境区域中的另一车辆,并且在环境区域的至少一个图像中用车辆模型替换该另一车辆。
在用于辅助机动车辆的驾驶员驾驶机动车辆的方法中,基于通过至少一个车辆侧相机从机动车辆的环境区域捕获的图像数据,优选地创建环境区域的至少一个图像,以用于在车辆侧显示装置上显示。此外,基于图像数据标识环境区域中的另一车辆,并且在环境区域的至少一个图像中用车辆模型替换该另一车辆。
因此,借助于该方法可以实现驾驶员辅助系统,其辅助驾驶员驾驶机动车辆,使得环境区域的至少一个图像显示在车辆侧显示装置上。特别地,在车辆侧显示装置上显示环境区域的视频序列,通过该视频序列,机动车辆的驾驶员可以借助于显示装置几乎实时地感知环境区域。其中,优选地基于图像数据创建第三人的角度,其中通过确定与环境区域中的机动车辆间隔开的虚拟相机的姿势(pose)并从虚拟相机的视角确定所述至少一个图像,从第三人的角度在所述至少一个图像中表示具有机动车辆的环境区域。所述至少一个图像例如呈现在机动车辆的内部镜子中和/或中央控制台中的屏幕上和/或抬头显示器上。因此,图像示出了特别是根据车辆外部的观察者的视角的环境区域的三维表示。其中,机动车辆本身可以表示为图像中的模型。
其中,所述至少一个图像特别地基于机动车辆的所谓的全景(surroundview)相机系统的图像数据来创建,其中全景相机系统例如可以具有分布在机动车辆上的多个相机。此外,机动车辆例如可以包括前端相机、后端相机以及两个后视镜相机。其中,相机可以配备有所谓的鱼眼镜头,通过该鱼眼镜头可以增加相应相机的捕获范围。例如通过组合或缝合图像数据,从该图像数据生成环境区域的至少一个图像。其中,可以特别提供的是,第三人的角度可以由机动车辆的驾驶员通过例如由驾驶员预设的环境区域中的虚拟相机的姿势来改变,其中在图像中从第三人的角度表示具有机动车辆的环境区域。此外,驾驶员可以例如选择多个预定姿势中的一个,因此选择虚拟相机的位置和方位,和/或例如通过手势操作自由地选择虚拟相机的姿势。
基于图像数据,另外可以例如通过对象识别算法识别另一车辆。其中,另一车辆特别地是接近机动车辆的车辆。该另一车辆例如可以从前方接近机动车辆以通过机动车辆。现在可以用代表真实车辆的模型(特别是三维模型或3d模型)替换该另一车辆。此外,与该另一车辆相关联的图像数据可以例如被标识或提取,并且被描述该另一车辆的模型的图像数据替换。换句话说,这意味着实际捕获的该另一车辆未在所述至少一个图像中显示在显示装置上,而是车辆被建模。因此,将表示该另一车辆的人工生成的部分图像区域插入到环境区域的所述至少一个图像中。其中,可以为位于机动车辆的环境区域中的多个另一车辆确定模型,并将模型插入到环境区域的所述至少一个图像中。
三维模型具有可以完全定义的优点,因此可以从所有视角表示该模型。因此,可以有利地自由选择虚拟相机的姿势,使得如果另一车辆例如在某些区域中在至少一个相机的捕获范围之外,则也可以完全表示和描述该另一车辆。因此,借助于模型,背离至少一个车辆侧相机的另一车辆的一侧也可以是可视的。也可以预设或控制模型的尺寸。因此,可以防止该另一车辆以不真实的尺寸显示,并且可以防止例如在具有鱼眼镜头的相机的情况下根据该车辆对机动车辆的位置突然不规则地改变其在视频序列中的尺寸。因此,通过在图像中用该另一车辆的3d模型替换该车辆,可以在显示装置上的场景内呈现具有正确尺寸比的另一车辆的当前交通状况的直观图像。因此,驾驶员可以可靠地感知环境区域并正确地评估交通状况。
其中,可以提供的是,如果由于确定的虚拟相机的姿势该另一车辆位于虚拟相机的虚拟捕获范围之外和/或如果由于确定的虚拟相机的姿势该另一车辆至少在某些区域中在所述至少一个车辆侧相机的捕获范围之外,则将该另一车辆的模型插入到所述至少一个图像中。因此,根据该实施例,如果该另一车辆被虚拟相机从一个视角“捕获”,其中通过该视角不能基于真实相机的图像数据生成该另一车辆的表示,则特别地插入该另一车辆的模型。例如,如果要通过虚拟相机的所选择的姿势在显示装置上表示由于例如背离车辆侧相机而不在真实相机的捕获范围内的、该另一车辆的区域,这可能发生。现在,为了在这种姿势的情况下仍然能够提供该视角,使用可以从期望的视角呈现的该另一车辆的模型。可替换地或另外地,如果通过所选择的视角在图像中没有看到另一车辆并且因此该另一车辆的图像数据未包含在用于创建图像的图像合成中,则也可以提供该模型。因此,可以有利地预设虚拟相机的任何姿势,从而可以生成环境区域的任何真实视图。
特别优选地,一旦该另一车辆到机动车辆的距离低于预定阈值,则确定该另一车辆到机动车辆的距离并且在环境区域的图像中用该模型替换该另一车辆。例如,可以基于图像数据本身和/或通过车辆侧距离传感器(例如,雷达传感器、超声波传感器和/或激光雷达传感器)来获取距离。这意味着在图像中表示捕获的车辆直到车辆到机动车辆的距离低于阈值。在低于阈值时,用模型替换该另一车辆。该实施例在具有盲点和/或具有带鱼眼镜头的相机的相机系统中特别有利,因为在这种情况下,该另一车辆的正确表示取决于车辆到机动车辆的位置。因此,一旦车辆具有不再能够确保该另一车辆的正确表示的到机动车辆的位置,就将表示该另一车辆的模型插入到图像中。
优选地,确定该另一车辆的至少一个显著特征,并且取决于所述至少一个显著特征确定用于表示该另一车辆的模型。特别地,确定另一车辆的品牌和/或类型和/或颜色作为显著特征,并且确定表示车辆的品牌和/或类型和/或颜色的模型。换句话说,这意味着模型的外观适于该另一车辆。例如,创建模型使得其具有与实际车辆相同的颜色。此外,该另一车辆的所述至少一个显著特征可以例如借助于分类方法来确定,例如支持向量方法(svm-“支持向量机(supportvectormachine)”)和/或机器学习(特别是“深度机器学习”)。因此,在至少一个图像上表示的环境区域的交通状况或场景可以特别真实地配置用于机动车辆的驾驶员。因此,驾驶员不会被捕获的车辆与图像中的模型之间的变化干扰或混淆,因此可以集中于他的驾驶工作。
其中,可以提供的是,各个参考模型与预定参考特征相关联,并且参考模型之一被选择作为模型,并基于至少一个确定的显著特征被插入到至少一个图像中。这意味着具有各种参考模型的列表被记录在例如车辆侧存储装置和/或基于因特网的数据库中。其中,参考模型描述了某些品牌和/或模型和/或颜色的车辆。取决于所捕获的显著特征,然后对应的参考模型被选择并被插入到图像中。因此,可以以特别简单和快速的方式并且以低计算量来确定模型。因此,如果另一接近车辆例如低于到机动车辆的距离,则可以例如特别快速地响应,并且可以特别适合地将模型插入到图像中。其中,优选地首先在车辆侧数据库中搜索参考模型。如果对应的参考模型没有记录在车辆侧数据库中,则可以搜索车辆外部的数据库。然后可以下载记录在那里的参考模型并将其存储在车辆侧数据库中以供将来渲染(render)。
优选地,在图像数据中捕获描述该另一车辆处的至少一个显著特征的预定对象,并且基于该对象确定至少一个显著特征。这意味着例如不直接捕获该另一车辆的品牌和/或类型和/或颜色,而是唯一地描述该另一车辆的显著特征的对象。特别优选地,捕获具有该另一车辆的登记名称的官方牌照作为对象,并且基于登记名称确定该另一车辆的至少一个显著特征。显著特征可以例如通过例如基于因特网搜索车辆内部和/或车辆外部的数据库来确定,其中捕获的对象与相关联的显著特征被记录在数据库中。
这意味着该另一车辆的号牌或官方牌照例如通过对象识别或图案识别来捕获。数字和/或字母数字登记名称也可以例如借助于文本识别(ocr-“光学字符识别(opticalcharacterrecognition)”)捕获。可以在其中记录了与登记名称相关联的显著特征(例如,该另一车辆的品牌以及模型和颜色)的数据库中搜索该登记名称。此外,可以提供的是,至少一个特征(例如该另一车辆的颜色)被直接捕获并与数据库中记录的颜色进行比较。从而,可以检查记录在数据库中的登记名称的车辆是否对应于由至少一个车辆侧相机捕获的车辆。直接捕获的特征也可以用作输入变量,以用于机器学习算法。例如,该另一车辆的图像可以与牌照一起上传到服务器。因此,提供该另一车辆的替换视图以使得可以改进分类算法的性能。通过借助于文本识别来捕获登记名称,可以以特别快速的方式并且以很少的计算量来提取关于该另一车辆的多个信息,其中通过所述多个信息可以确定该另一车辆的真实且精确的模型。
在本发明的改进方案中,该另一车辆的对象被插入到图像中并与描述该另一车辆的模型一起描绘。这意味着例如将官方牌照插入到模型中,因此用车辆侧显示装置上的环境区域的图像中的实际官方牌照来描绘该另一车辆的模型。因此,给驾驶员的印象是看到显示装置就好像不是模型,而实际车辆将在显示装置上表示。
可替代地或另外地,至少一个显著特征从该另一车辆无线地通信给车辆侧通信装置。该通信也称为车对车通信或car2car通信。此外,该另一车辆例如还可以将位置坐标(特别是gps数据)通信给机动车辆。因此,可以基于位置坐标和描述环境区域的环境地图来确定该另一车辆到机动车辆的位置,因此可以以与机动车辆相对应的位置将模型插入到图像中。
如果捕获该另一车辆相对于机动车辆的方位并且根据该另一车辆的方位确定图像中的模型的方位,则证明是有利的。可替换地或另外地,捕获至少一个环境条件,特别是照明条件,并且模型适于所述至少一个环境条件。通过捕获该另一车辆的方位,可以通过将模型插入图像中使得图像中的模型的方位与该另一车辆的实际方位一致来特别真实地确定图像。还可以确定照明条件。此外,例如可以捕获白天、街道照明和/或阴影投射。然后,改变模型,使其适于环境区域中当前存在的环境条件。然后,该模型例如对应地被照亮并且因此在环境区域中当前存在的照明条件中表示。
在该方法的有利实施例中,该另一车辆另外由与所述至少一个相机不同的传感器装置捕获。这种传感器装置例如可以是超声波传感器、激光雷达传感器和/或雷达传感器,其中借助于该传感器装置可以生成和更新描述环境区域的环境地图。由此,可以跟踪或追踪该另一车辆并将其登记在环境地图中,使得如果该另一车辆例如从至少一个相机的捕获范围消失并且对象(例如,官方牌照)不再可见,而仍然可以显示该另一车辆的3d模型。
此外,本发明涉及一种用于辅助机动车辆的驾驶员驾驶机动车辆的驾驶员辅助系统。根据实施例,驾驶员辅助系统具有用于从机动车辆的环境区域捕获图像数据的至少一个相机、用于创建环境区域的至少一个图像的评估装置和用于显示所述至少一个图像的显示装置。此外,评估装置可以适于基于图像数据标识环境区域中的另一车辆,并且在环境区域的所述至少一个图像中用车辆模型替换该另一车辆。优选地,驾驶员辅助系统具有用于从机动车辆的环境区域捕获图像数据的至少一个相机、用于创建环境区域的至少一个图像的评估装置和用于显示所述至少一个图像的显示装置。评估装置适于基于图像数据标识环境区域中的另一车辆,并且在环境区域的所述至少一个图像中用车辆模型替换该另一车辆。
根据本发明的机动车辆包括根据本发明的驾驶员辅助系统。特别地,机动车辆形成为轿车。
关于根据本发明的方法呈现的优选实施例及其优点对应地适用于根据本发明的驾驶员辅助系统和根据本发明的机动车辆。
通过“后方”、“前方”、“车辆纵轴”、“横向”、“外侧”、“右侧”、“左侧”等的指示,规定了观察者向机动车辆的车辆纵轴的方向看时给定的位置和方向。
从权利要求、附图和附图的描述中,本发明的其它特征是明显的。在说明书中上面提到的特征和特征组合以及下面在附图的描述中和/或仅在附图中示出的特征和特征组合不仅可以在相应指定的组合中使用,而且可以在其它组合中或单独地使用,而不脱离本发明的范围。因此,实施方式也被认为是由本发明所涵盖和揭示的,这些实施方式未在附图中明确示出并且被解释,而是由与所解释的实施方式的分离的特征组合产生并生成。实施方式和特征组合也被认为是公开的,因此不具有最初制定的独立权利要求的所有特征。此外,实施方式和特征组合被认为是公开的,特别是通过上面阐述的超出或脱离权利要求的关系中阐述的特征组合的实施方式。
附图说明
现在,基于优选实施例以及参考附图更详细地解释本发明。
示出了:
图1是根据本发明的机动车辆的实施例的示意表示;
图2是根据本发明的驾驶员辅助系统的实施例的示意表示;
图3a-图3e是视频序列的帧的示意表示;
图4是另一图像的示意表示;
图5是根据本发明的方法的实施例的示意表示;以及
图6是用于实现根据本发明的方法的实施例的系统架构的示意表示。
具体实施方式
在附图中,相同和功能相同的元件具有相同的附图标记。
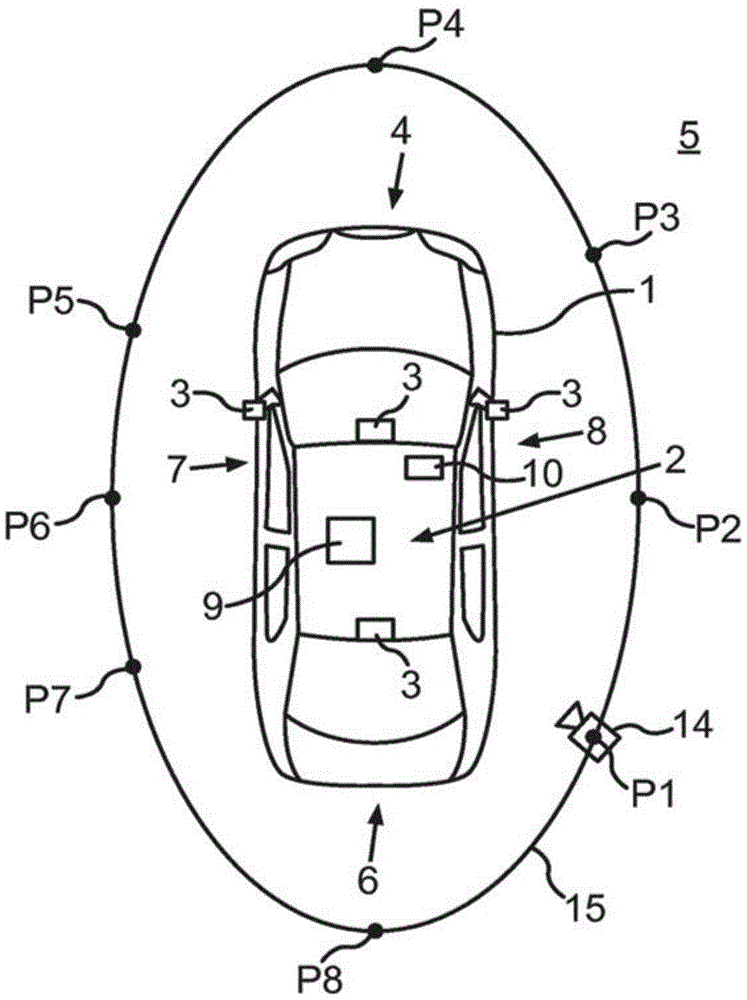
图1示出了机动车辆1,其在当前情况下形成为轿车。机动车辆1包括可以辅助机动车辆1的驾驶员驾驶机动车辆1的驾驶员辅助系统2。驾驶员辅助系统2具有至少一个车辆侧相机3,其适于从机动车辆1的环境区域5捕获图像数据。在当前情况下,驾驶员辅助系统2具有四个车辆侧相机3,通过该四个车辆侧相机3形成全景相机系统。其中,驾驶员辅助系统2包括:第一相机3,其附接到机动车辆1的前端区域4并且用于监视机动车辆1前面的环境区域5;第二相机3,其附接到机动车辆1的后端区域6并用于监视机动车辆1后面的环境区域5;第三相机3,其附接到机动车辆1的左侧7并且形成为监视机动车辆1之外的左侧的环境区域;以及第四相机3,其附接到机动车辆1的右侧8并且用于监视机动车辆1之外的右侧的环境区域5。例如,附接到侧面7、8的相机3可以附接到机动车辆1的后视镜,或者附接到机动车辆1而不是后视镜。相机3例如可以具有鱼眼镜头,通过该鱼眼镜头可以增加相应相机3的捕获范围。
在图2中另外示意性地示出的驾驶员辅助系统2可以另外具有评估装置9,评估装置9例如形成为视频处理器。视频处理器9用于处理由相机3捕获的图像数据并生成可以以视频序列的形式显示在车辆侧显示装置10上的图像。此外,驾驶员辅助系统2可以具有车辆侧存储装置11以及通信接口12。驾驶员辅助系统2可以经由通信接口12与车辆外部的装置13(例如,另一车辆或基于因特网的数据库)通信。
现在,为了辅助机动车辆1的驾驶员驾驶机动车辆1,视频序列以连续显示的图像b1、b2、b3、b4、b5的形式显示在车辆侧显示装置10上(参见图3a至图3e)。其中,环境区域5特别是从第三人的角度显示在图像b1至b5中。这意味着从外部观察者的视角显示环境区域5以及机动车辆1。此外,确定虚拟相机14的姿势p1、p2、p3、p4、p5、p6、p7、p8。这里,虚拟相机14的姿势p1至p8位于围绕机动车辆1延伸的椭圆轨迹15上,如图1所示。各个姿势p1至p8例如可以由机动车辆1的驾驶员借助于输入装置来选择。
其中,相机3的图像数据由视频处理器9处理,使得图像b1至b5从与所选择的姿势p1至p8(例如第一个姿势p1)中的虚拟相机14的相机视角相对应的视角产生。图3a至图3e示出了在时间上连续生成的视频帧或图像b1至b5。其中,基于图3a中的第一图像b1示出了机动车辆1的环境区域5,其中另一车辆16也位于图像b1中。该另一车辆16从前方接近机动车辆1并且具有到机动车辆1的第一距离。在图3b中,示出了在时间上在第一图像b1之后生成的第二图像b2。车辆16已经朝向机动车辆1移动并且具有与第一距离相比更小的到机动车辆1的第二距离。在图3c中,示出了在时间上在第二图像b2之后生成的第三图像b3。机动车辆16已经进一步朝向机动车辆1移动并且具有与第二距离相比更小的到机动车辆1的第三距离。在图3d中,示出了在时间上在第三图像b3之后产生的第四图像b4,在第四图像b4上车辆16已经接近机动车辆1到与第三距离相比更小的第四距离的点,从而在生成第四图像b4时,不真实地表示了机动车辆1与该另一车辆16之间的尺寸比。在根据图3e在时间上在第四图像b4之后生成的第五图像b5中,其中该另一车辆16具有与第四距离相比更小的到机动车辆1的第五距离,示出了该另一车辆16的这种不成比例的尺寸变化。这里,例如,不真实地表示的尺寸比例如出现在车辆16经过靠近机动车辆1的侧面7并且由此横向相机3和标尺不规则地改变。
此外,在图4中,示出了机动车辆1和环境区域5的另一图像b6,其中图像b6已经从图像数据生成为由虚拟相机14以姿势p7捕获的图像b6。这里,虚拟相机14的相机视角对应于从机动车辆1后面的左侧到机动车辆1的观看方向。这里,示出了该另一车辆16在显示在显示装置10上的图像b6中不可见,因为该另一车辆16在虚拟相机14的虚拟捕获范围之外。为了防止这种情况以及图3d和图3e所示的车辆16的不正确缩放,在显示装置10上呈现的图像b4、b5、b6中表示车辆16的三维模型m,而不是车辆16。例如,如果该另一车辆16的距离低于预定阈值和/或该另一车辆16在虚拟相机14的虚拟捕获范围之外,则插入模型m。
为了确定模型m,可以执行一种方法,其实施例在图5中示例性地示出。其中,该方法可以用于机动车辆1的环境区域5中的多个另一车辆16。在图6中,示出了用于实现该方法的系统架构。此外,另一车辆16例如在布置在前侧的相机3的图像数据17中被标识。在图5中,另外以放大的方式示出了该另一车辆16的图像部分18。此外,基于图像数据17捕获该另一车辆16的显著特征35,然后基于显著特征35确定模型m。显著特征35可以是例如该另一车辆16的品牌、类型、颜色、制造年份、发动机类型等。其中,为了确定显著特征35,可以捕获该另一车辆16处的对象19。在本例中,对象19被配置为官方牌照20。在方法步骤21中,例如借助于对象识别,在图像数据17中识别官方牌照20。在另一方法步骤22中,识别登记指示器23。登记指示器23例如可以包括字母和数字的阵列,可以借助文本识别以简单快速的方式在图像数据17中识别登记指示器23。在另一方法步骤24中,这里,在车辆外部的装置13(诸如车辆外部的数据库25)中搜索与登记指示器23相关联的该另一车辆16的特征35。这里,车辆外部的数据库25是基于因特网的数据库。驾驶员辅助系统2例如可以经由通信接口12访问因特网32,并且因此可以访问车辆外部的装置13。
另外,在方法步骤26中,标识数据库25的条目,其中在条目中记录了与牌照20相对应的车辆16的特征35。数据库25的条目例如可以被下载并存储在车辆侧存储装置11中。基于该条目,在方法步骤27中确定描述并表示该另一车辆16的3d模型m。模型m可以例如以参考模型的形式记录在车辆外部的另一数据库33和/或车辆内部的存储装置11中,其中存储装置11也可以具有数据库34。
在方法步骤28中,然后可以将记录在数据库25中的车辆16的颜色与可以基于图像数据17确定的车辆16的实际颜色进行比较。这用于检查模型m是否实际与车辆16相对应并且正确地表示它。另外,基于图像数据17确定环境条件(例如,照明条件)。在模型m的渲染期间,可以在方法步骤29中考虑这些照明条件(例如,白天或夜晚的照明条件、阴影投射或街道照明)。在方法步骤30中,可以将官方牌照20另外插入模型m中,使得在步骤31中该另一车辆16的真实模型m可以被插入到图像b4、b5、b6中。
作为在数据库搜索至少一个特征35的替代或补充,机动车辆1还可以经由通信接口12,特别是经由car2car通信与该另一车辆16通信,使得该另一车辆16可以直接传输显著特征35(例如,机动车辆1的颜色、品牌等)。
- 还没有人留言评论。精彩留言会获得点赞!