存储装置及其操作方法以及包括存储装置的计算系统与流程
本申请主张在2017年10月18日在韩国知识产权局提出申请的韩国专利申请第10-2017-0135435号的优先权,所述韩国专利申请的公开内容全文并入本申请供参考。在这里描述的本发明概念的实施例涉及一种半导体存储器,更具体地说是涉及一种存储装置、包括所述存储装置的计算系统以及所述存储装置的操作方法。
背景技术:
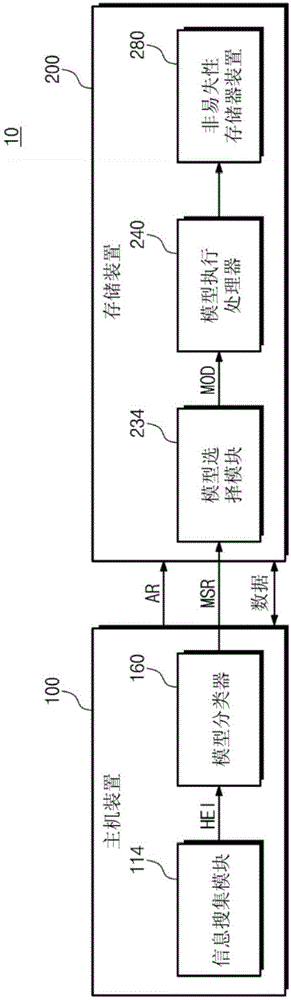
:存储装置可以包括非易失性存储器。由于具有非易失性存储器的存储装置即使在断电时也保持存储在其中的数据,因此存储装置可以用于长时间存储数据。存储装置可以用作各种电子装置中的主存储器,例如个人计算机或智能电话。在存储装置上执行数据读取和写入的模式可能根据用户的数据使用模式和使用数据的环境而有所不同。如果在存储装置上执行数据读取和写入的模式变化,则存储装置的操作性能可以变化。存储装置的制造商可以基于平均使用模式和使用环境为其内部操作(例如,写入和读取操作)设置算法。然而,这种算法无法为每个用户提供最佳操作性能。技术实现要素:本发明概念的至少一个实施例提供了为每个用户提供最佳操作性能的存储装置、包括所述存储装置的计算系统以及所述存储装置的操作方法。根据本发明概念的示例性实施例,一种存储装置包括:非易失性存储器装置,具有用以存储多个基于机器学习的模型的多个第一存储器区块以及经配置以存储用户数据的多个第二存储器区块;基于模型选择请求选择基于机器学习的模型的一个的控制器;加载与所选择的模型相关联的模型数据的处理器,并基于所选择的模型调度与非易失性存储器装置相关联的任务;以及基于调度的任务存取非易失性存储器装置的第二存储器区块的存储器接口。根据示例性实施例,一种计算系统包括主机装置和存储装置。主机装置包括第一控制器,其生成与计算系统相关联的主机环境信息,并且基于取决于主机环境信息的机器学习选择与存储装置相关联的模型,并将指示所选择的模型的模型选择请求发送到存储装置。存储装置包括:非易失性存储器,包括存储区块;第二控制器,其根据模型选择请求选择多个基于机器学习的模型中的一个;以及处理器,其执行所选择的模型以存取非易失性存储器装置。根据本发明概念的示例性实施例,存储装置的操作方法包括:存储装置的控制器选择从第一机器学习操作生成的存储装置的操作模型;控制器从外部主机装置接收存取存储装置的请求;控制器基于考虑存取请求和所选择的操作模型的第二机器学习操作来调度要在存储装置上执行的任务;并且,存储装置的处理器执行所调度的任务。附图说明通过结合附图进行的以下描述,可更详细地理解示范性实施例。图1是示出根据本发明概念的示例性实施例的计算系统的方块图。图2是示出根据本发明概念的示例性实施例的计算系统的操作方法的流程图。图3是示出根据本发明概念的示例性实施例的主机装置的方块图。图4是示出模型分类器生成模型选择请求的示例的流程图。图5是示出根据本发明概念的示例性实施例的存储装置的方块图。图6示出了能够在模型分类器、任务分类器或政策分类器中使用的示例性基于机器学习的分类器。图7示出了根据另一示例的基于机器学习的分类器,其能够在模型分类器、任务分类器或政策分类器中使用。图8是示出根据本发明概念的应用的主机装置的方块图。图9是示出根据本发明概念的示例性实施例的计算系统的操作方法的流程图图10是示出根据本发明概念的示例性实施例的计算系统的方块图。图11是示出根据本发明概念的应用的存储装置的方块图。图12是示出根据本发明概念的另一应用的存储装置的方块图。具体实施方式下面,将参考附图清楚地并且详细地描述本发明概念的示例性实施例,使得本领域普通技术人员能够实现本发明概念。图1是示出根据本发明概念的示例性实施例的计算系统的方块图。请参照图1,计算系统10包括主机装置100和存储装置200。在一个实施例中,主机装置100向存储装置200发送存取请求ar以在存储装置200中写入数据或从存储装置200读取数据。存取请求ar可以包括在从主机装置100发送到存储装置200的信号内。存取请求ar可以包括写入命令或读取命令作为示例。主机装置100包括信息收集模块114和模型分类器160。信息搜集模块114可以搜集主机装置100的环境信息。例如,信息搜集模块114可以搜集诸如用户使用主机装置100的趋势、在主机装置100中执行的应用程序或进程的存取模式、主机装置100中的存储器的存取模式、或者主机装置100的工作负载,并且可以输出所搜集的信息作为主机环境信息hei。例如,工作负载可以指示在给定时段期间由主机装置100的处理器执行的指令的数目。例如,应用程序的存取模式可以指示在给定时段期间执行的进程的序列。例如,存储器的存取模式可以指示在给定时段期间存取(读取或写入)的存储器位置的序列。在一个实施例中,信息搜集模块114是由主机装置100的处理器执行的计算机程序。在另一实施例中,信息搜集模块114由包括一个或多个硬件计数器、逻辑电路和寄存器的控制器实现。例如,逻辑电路可以控制硬件计数器以计数在给定时段期间由处理器执行的指令的数目以生成工作负载值。例如,逻辑电路可以设置寄存器以指示在给定时段期间存取的应用程序或存储器位置的序列以生成存取模式。模型分类器160基于主机环境信息hei选择于主机装置100存取存储装置200的模型。例如,模型分类器160可以基于主机环境信息hei选择预定义模型的一个。在一个实施例中,模型分类器160包括作为机器学习的结果而创建的分类器,并且通过使用分类器来选择模型。模型分类器160将指示所选择的模型的模型选择请求msr发送到存储装置200。存储装置200包括模型选择模块234、模型执行处理器240(例如,中央处理单元,数字信号处理器等)和非易失性存储器装置280。模型选择模块234取决于模型选择请求msr选择模型。在一个实施例中,主机装置100向存储装置200发送包括模型选择请求msr的信号。模型选择模块234可以在模型执行处理器240上加载所选择的模型的模型数据mod。在一个实施例中,模型选择模块234是由存储装置234的处理器执行的计算机程序所实现。在一个实施例中,模型选择模块234由逻辑电路、存储多个模型中的每个模型的模型数据mod的存储器或寄存器以及输入具有指示模型的信号的多路复用器所实现,其中模型选择请求msr作为控制信号施加到多任务器以使信号中的一个输出到逻辑电路,并且逻辑电路将相应的模型数据mod加载到模型执行处理器240上。模型执行处理器240从模型选择模块234接收模型数据mod。模型执行处理器240通过执行模型数据mod来执行所选择的模型。例如,模型执行处理器240可以基于所选择的模型来调度与来自主机装置100的存取请求相对应的任务,以及用于管理存储装置200的后台任务或前台任务。后台任务是在后台运行而无需用户介入的计算机程序(例如,登入、系统监视、调度、用户通知等)。例如,模型数据mod可以包括作为机器学习的结果而创建的分类器。模型执行处理器240可以基于机器学习和由所选择的模型分配的优先级或权重来调度各种任务。在一个实施例中,分类器是可执行程序的,其被配置为将数据分类为多个不同分类中的一个。非易失性存储器装置280是可根据模型执行处理器240调度的任务来存取。非易失性存储器装置280可以包括各种非易失性存储器装置中的至少一种,诸如闪存存储器装置、相变随机存取存储器(phasechangerandomaccessmemory,pram)装置、铁电随机存取存储器(ferroelectricrandomaccessmemory,fram)装置或电阻随机存取存储器(resistiverandomaccessmemory,rram)装置。图2是示出根据本发明概念的示例性实施例的计算系统10的操作方法的流程图。参照图1和图2,在操作s110中,主机装置100的模型分类器160对主机环境信息hei执行基于机器学习的分类,并基于分类结果选择模型。例如,模型分类器160可以选择与存储装置200相关联的存取模型。在操作s120中,主机装置100的模型分类器160将指示所选择的模型的模型选择请求msr发送到存储装置200。在操作s130中,存储装置200的模型选择模块234在模型执行处理器240上加载所选择的模型的模型数据mod。如果完全选择(改变)模型,则在操作s140中,主机装置100将存取请求发送到存储装置200。例如,存取请求可以包括写入请求,读取请求或修整请求。修整请求可以允许主机装置100向存储装置200通知已删除文件的信息。在一个实施例中,修整请求通知存储装置200不再考虑使用存储装置200的哪些区块,因此可以在内部删除它们。在操作s150中,存储装置200的模型执行处理器240取决于所选择的模型执行存取请求。例如,模型数据mod可以包括基于机器学习的任务分类器。模型执行处理器240可以基于来自主机装置100的存取请求或存储装置200的多个环境信息来执行任务分类。模型执行处理器240可以基于分类结果来调度存取任务(例如,将数据写入存储器或从存储器读取数据的任务)、后台任务或与非易失性存储器装置280相关联的前台任务。图3是示出根据本发明概念的示例性实施例的主机装置100的方块图。参照图1和图3,主机装置100包括处理器110、电源模块120、调制解调器130、存储器140、输入和输出模式数据库150、模型分类器160和装置接口170。处理器110包括应用模块111和信息搜集模块114。应用模块111可以执行使用存储装置200的各种应用程序112和进程113。应用模块111可以根据用户的请求或处理器110的内部时间表自动驱动,并且不需要与模型的选择相关联。应用程序112或进程113生成用于存取存储装置200的第一存取请求ar1。例如,第一存取请求ar1可以包括对存储装置200的读取、写入或修整请求。可以将第一存取请求ar1发送到装置接口170。信息搜集模块114执行与模型的选择相关联的任务。信息搜集模块114包括电源监测器115、用户配置寄存器116、输入和输出监测器117,以及应用程序和进程监测器118。电源监测器115、用户配置寄存器116、输入和输出监测器117以及应用程序和进程监测器118分别搜集第一主机环境信息hei1、第二主机环境信息hei2、第三主机环境信息hei3和第四主机环境信息hei4并向模型分类器160提供第一主机环境信息hei1至第四主机环境信息hei4作为主机环境信息hei。电源监测器115从电源模块120搜集与主机装置100的电源相关联的信息,作为第一主机环境信息hei1。下表1示出了电源监测器115搜集的主机装置100的第一主机环境信息hei1的示例。例如,电源监测器115可以从电源模块120检索表1的一行或多行。表1中电源类型指示主机装置100是由ac电源还是dc电源供电。表1中的电池位准表示向主机装置100提供电力的电池的充电百分比。表1中的计数表示主机装置100在前一时间段期间进入低功率模式的次数。例如,如果计数为2,则主机装置100在前n秒期间已进入两次低功率模式。表1中的持续时间表示在前一时段期间主机装置100维持低功率模式的时间量。例如,如果持续时间是3并且持续时间的单位是秒,则主机装置100维持低功率模式3秒。表1用户配置寄存器116存储由用户配置的信息。用户配置寄存器116可以存储默认的操作偏好。用户配置寄存器116还可以存储关于用户在存储的操作趋势中优选的操作趋势的信息。用户配置寄存器116可以提供关于操作趋势的信息作为第二主机环境信息hei2。用户配置寄存器116存储由用户配置的信息。下表2示出了由用户配置寄存器116搜集的第二主机环境信息hei2的示例。例如,表2中的环境类型可以指示存储装置所属的装置的类型(例如,主机装置100)。表2中以性能为中心的参数可以衡量用户对性能的感兴趣程度(例如,在高工作频率下操作)。表1的低功率中心参数可以指示用户对节省功率的兴趣。表2中以可靠性为中心的参数可以指示用户对可靠数据的感兴趣程度。例如,如果参数的值高,则主机装置100可以在存储装置200上存储冗余的数据副本和/或存储具有错误更正码的数据。表2输入和输出监测器117监视主机装置100存取存储装置200的特性,并提供监视结果作为第三主机环境信息hei3。例如,输入和输出监测器117可以监视主机装置100在先前的“n”秒期间存取存储装置200的特性(n是正整数)。下表3示出了输入和输出监测器117搜集的信息的示例作为第三主机环境信息hei3。表3的闲置时间参数可以指示主机装置100闲置的最后时间量(例如,未存取存储装置200)。表3的读取负载参数可以指示在前一时段期间主机装置100使用的读取带宽的百分比。表3的写入负载参数可以指示在前一时段期间主机装置100使用的写入带宽的百分比。表3的预期读取负载参数可以指示主机装置100预期在下一时段期间使用的读取带宽的百分比。表3的预期写入负载参数可以指示主机装置100预期在下一时段期间使用的写入带宽的百分比。表3的打开文件处理程序参数的数目可以指示打开以打开存储在存储装置200上的文件的文件处理程序或文件描述符的数目。表3应用程序和进程监测器118可以从输入和输出模式数据库150搜集关于应用程序112或在处理器110中执行的进程113的存取模式的信息。应用程序和进程监测器118可以将所搜集的信息提供为第四主机环境信息hei4。下表4示出了由应用程序和进程监测器118搜集的第四主机环境信息hei4的示例。表4例如,具有名称“wordprocessor”的应用程序可以执行具有名称为“word”的进程。作为示例,wordprocessor的平均读取负载在“0”和“100”之间可具有值“10”。平均读取负载可以指示在给定时段期间应用程序的读取密集程度。wordprocessor的平均写入负载在“0”和“100”之间可以具有值“30”。平均写入负载可以指示应用程序在给定时段期间的写入密集程度。wordprocessor的顺序读取比率可以在“0”和“100”之间具有值“70”。wordprocessor的顺序写入比率可以在“0”和“100”之间具有值“10”。例如,具有名称“mediaplayer”的应用程序可以执行具有名称为“player.exe”的进程。mediaplayer的平均读取负载可以是“70”,其平均写入负载可以是“10”,其顺序读取比率可以是“90”,并且其顺序写入比率可以是“80”。具有名称“filesharing”的应用程序可以执行具有名称为“torrent.exe”的进程。filesharing的平均读取负载可以是“50”,其平均写入负载可以是“80”,其顺序读取比率可以是“90”,并且其顺序写入比率可以是“90”。具有名称为“explorer”的应用程序可以执行具有名称为“explorer.exe”的进程。explorer的平均读取负载可以是“20”,其平均写入负载可以是“10”,其顺序读取比率可以是“40”,并且其顺序写入比率可以是“10”。在应用程序112或进程113中的特定应用程序/进程的模式信息未存储在输入和输出模式数据库150中的情况下,处理器110可以从服务器通过调制解调器130请求特定应用程序/进程的模式信息。在服务器不存在模式信息的情况下,输入和输出监测器117可以分析特定应用程序/进程存取存储装置200的模式。输入和输出监测器117可以将分析结果存储在输入和输出模式数据库150中,作为特定应用程序/进程的模式信息。例如,处理器110可以通过调制解调器130将特定应用程序/进程的模式信息上载到服务器。电源模块120可以向主机装置100供电。电源模块120可以包括电池或整流器作为示例。调制解调器130可以在处理器110的控制下通过有线或无线通信与外部装置通信。存储器140可以是处理器110的工作存储器或系统存储器。存储器140可以包括动态随机存取存储器(dynamicrandomaccessmemory,dram)。输入和输出模式数据库150可以包括关于输入和输出的模式的信息,其应用程序或进程通过所述模式存取存储装置200。输入和输出模式数据库150可以存储在非易失性存储器中。例如,输入和输出模式数据库150可以存储在存储装置200的非易失性存储器装置280中。例如,处理器110可以通过装置接口170向存储装置200发送存取请求,从而存取(或搜索)存储在存储装置200的非易失性存储器装置280中的输入和输出模式数据库150。作为另一示例,输入和输出模式数据库150可以存储在远程服务器中。在所述示例中,输入和输出模式数据库150不是本地存储在计算系统10中。处理器110可以通过调制解调器130向远程服务器发送存取请求,从而存取存储在远程服务器中的输入和输出模式数据库150。输入和输出模式数据库150可以存储关于在主机装置100中安装或未安装的应用程序或进程的模式的信息,或者在存取存储装置200的主机装置100中先前执行或未执行的进程的信息。例如,输入和输出模式数据库150可以指示在给定时段期间已经存取存储装置200的应用程序或进程的序列或者已经在存储装置200中存取的一系列数据。在一个实施例中,使用机器学习来创建模型分类器160。在一个实施例中,模型分类器160接收主机环境信息hei,并基于主机环境信息hei对适合于存储装置200的模型进行分类。模型分类器160将包括分类模型的信息的第一模型选择请求msr1发送到装置接口170。下表5示出了模型分类器160的分类结果的示例。标识符偏好特征预期负载结果(可能性)0性能为中心写入浓度10%1性能为中心读取浓度12%2性能为中心平衡57%3性能为中心最小或闲置2%4低功率为中心写入浓度2%5低功率为中心读取浓度1%6低功率为中心平衡2%7低功率为中心最小或闲置2%8可靠性为中心写入浓度5%9可靠性为中心读取浓度3%10可靠性为中心平衡2%11基于可靠性最小或闲置2%表5如表5所示,模型分类器160可分类性能为中心和平衡的可能性最高。模型分类器160可以将第一模型选择请求msr1发送到装置接口170,以便选择与以性能为中心和平衡相对应的模型。例如,平衡的预期负载可能意味着预期读取的数目等于写入的数目,或者预期用于执行读取的资源量与用于执行读取的资源量相同。如表5所示,模型分类器160可以通过使用存储在用户配置寄存器116中的用户的倾向作为第一元素(或主元素)来执行分类。模型分类器160可以通过使用除了用户的倾向之外的剩余环境信息作为第二元素(或附加元素)来执行分类。例如,模型分类器160可以用与处理器110分离的单独的半导体芯片来实现。例如,模型分类器160可以用半导体芯片实现,所述半导体芯片适合于执行基于机器学习的分类,例如现场可编程门阵列(fieldprogrammablegatearray,fpga),图形处理器(graphicsprocessor,gpu)或神经形态芯片。装置接口170从处理器110接收第一存取请求ar1,并从模型分类器160接收第一模型选择请求msr1。装置接口170可以从模型分类器160接收包括第一模型选择请求msr1的信号。装置接口170可以将具有在主机装置100内使用的格式的第一存取请求ar1和第一模型选择请求msr1分别转换为具有在主机装置100和存储装置200之间的通信中使用的格式的第二存取请求ar2和第二模型选择请求msr2。装置接口170将第二存取请求ar2和第二模型选择请求msr2发送到存储装置200。当第二存取请求ar2是读取请求时,装置接口170从存储器140读取与读取请求对应的数据,并将读取的数据发送到存储装置200。当第二存取请求ar2是写请求时,装置接口170将从存储装置200发送的数据存储在存储器140中。如上所述,主机装置100可以基于用户的趋势和主机装置100的环境来执行基于机器学习的模型分类。主机装置100可以通过第二模型选择请求msr2向存储装置200发送(例如,指示、建议或推荐)被分类为适合于存储装置200的模型。图4是示出模型分类器160生成第一模型选择请求msr1的示例的流程图。参照图3和图4,在操作s210中,模型分类器160对模型进行分类。例如,模型分类器160可以取决于预定时段执行分类。作为另一示例,模型分类器160可以取决于用户或外部装置的请求来执行分类。在操作s220中,模型分类器160确定所选择的模型(例如,具有最高可能性的模型)的可能性是否大于阈值。例如,阈值可以由模型分类器160设置。作为另一示例,阈值可以由用户或外部装置设置。阈值可以存储在用户配置寄存器116中。如果所选择的模型的可能性大于阈值,在操作s230中,则模型分类器160生成第一模型选择请求msr1。也就是说,在所选择的模型的基础上,模型分类器160维持先前模型或通过第一模型选择请求msr1请求选择新模型。例如,在维持先前模型的情况下,模型分类器160可以跳过第一模型选择请求msr1的生成。在一个实施例中,如果所选择的模型的可能性不大于阈值,则模型分类器160不生成第一模型选择请求msr1。也就是说,保持先前在存储装置200中选择并执行的模型。根据参考图4所描述的实施例,可以抑制存储装置200的模型频繁改变,因此可以减少由于模型改变引起的开销。图5是示出根据本发明概念的示例性实施例的存储装置200的方块图。例如,存储装置200可以对应于各种存储装置,诸如固态硬盘(ssd)、存储卡或嵌入式存储器。参照图1、3和5,存储装置200包括主机接口210、第一缓冲存储器220、控制器230、模型执行处理器240、第二缓冲存储器250、第三缓冲存储器260、存储器接口270和非易失性存储器装置280。主机接口210可以从装置接口170接收第二存取请求ar2和第二模型选择请求msr2。主机接口210可以将具有在主机装置100和存储装置200之间的通信中使用的格式的第二存取请求ar2和第二模型选择请求msr2分别转换为具有在存储装置200内使用的格式的第三存取请求ar3和第三模型选择请求msr3。主机接口210将第三存取请求ar3发送到第一缓冲存储器220。主机接口210可以将包括第三存取请求ar3的信号发送到第一缓冲存储器220。主机接口210将第三模型选择请求msr3发送到控制器230。主机接口210可以将包括第三模型选择请求msr3的信号发送到控制器230。当第三存取请求ar3是写入请求时,主机接口210将从装置接口170接收的数据存储在第三缓冲存储器260中。在取决于写入请求将数据存储在第三缓冲存储器260中之后,主机接口210将存储在第三缓冲存储器260中的数据发送到存储器接口270。第一缓冲存储器220从主机接口210接收第三存取请求ar3。例如,第一缓冲存储器220可以是存储第三存取请求的队列。第一缓冲存储器220可以在控制器230内提供、可以在模型执行处理器240内提供、或者可以与第二缓冲存储器250或第三缓冲存储器260组合。控制器230可以执行用于驱动存储装置200的固件。控制器230可以取决于固件控制存储装置200的组件。控制器230可以从主机接口210接收第三模型选择请求msr3。控制器230可以基于第三模型选择请求msr3选择模型,并且可以在模型执行处理器240上加载所选择的模型。控制器230包括装置信息搜集模块231和模型选择模块234。装置信息搜集模块231搜集存储装置200的环境信息,并将搜集的环境信息作为装置环境信息dei提供给模型执行处理器240。控制器230可以将包括装置环境信息dei的信号输出到模型执行处理器240。装置信息搜集模块231可以包括资源监测器232和事件监测器233。资源监测器232可以监视存储装置200的资源,并且可以包括关于装置环境信息dei中的资源的信息。下表6示出了资源监测器232提供的装置环境信息dei的示例。表6的单级单元空闲存储器区块参数可以指示存储装置200的存储器区块是空闲且其存储器单位被配置为仅存储一个位的百分比。表6的多级单元空闲存储器区块参数可以指示存储装置200的存储器区块是空闲且其存储器单位被配置为存储两个位的百分比。表6的三级单元空闲存储器区块参数可以指示存储装置200的存储器区块是空闲且其存储器单位被配置为三位或更多位的百分比并。表6的有效数据比率参数可以指示具有有效数据的特定类型的存储器单元的百分比。表6的最大/混合编程/抹除计数参数可以指示在某种类型的存储器单元中执行的编程/抹除操作的最大/最小数目。缓冲存储器参数的剩余比率可以指示缓冲存储器是满的或空的。表6存储1位数据的存储器单元可以是单级单元。包括单级单元的存储器区块可以是单级单元存储器区块。包括未存储数据的单级单元的存储器区块可以是单级单元的空闲存储器区块。存储2位数据的存储器单元可以是多级单元。存储3位数据的存储器单元可以是三级单元。然而,本发明概念不限于单级单元、多级单元和三级单元。例如,本发明概念还可以应用于四个或更多个数据位存储在一个存储器单元中的情况。事件监测器233可以监测在存储装置200中发生的事件,并且可以包括关于装置环境信息dei中的事件的信息。下表7示出了事件监测器233搜集的装置环境信息dei的示例。表7主机装置100待处理的读取请求、写入请求或修整请求可包括存储在第一缓冲存储器220中的请求或由主机装置100发出的任务以及通过模型执行处理器240的分类在第二缓冲存储器250中调度的任务。模型选择模块234可以取决于第三模型选择请求msr3选择模型。模型选择模块234包括模型选择器235和模型下载器236。模型选择器235将请求由第三模型选择请求msr3选择的模型的第一模型请求mr1发送到存储器接口270。模型选择器235可以向存储器接口270发送包括第一模型请求mr1的信号。如果所选择的模型的模型数据mod存储在非易失性存储器装置280中,则存储器接口270可以从非易失性存储器装置280读取模型数据mod。如果从存储器接口270发送模型数据mod,则模型选择器235可以将模型数据mod发送(或加载)到模型执行处理器240。在未从存储器接口270发送所选择的模型的模型数据mod的情况下,例如,在所选择的模型的模型数据mod未存储在非易失性存储器装置280中的情况下,模型下载器236可以从主机装置100请求模型数据mod。模型数据mod可以通过第三缓冲存储器260存储在非易失性存储器装置280中作为数据的一部分。模型执行处理器240可以从控制器230接收并执行所选择的模型的模型数据mod。在一个实施例中,所选择的模型包括任务分类器241和政策分类器242。在一个实施例中,任务分类器241对装置环境信息dei执行基于机器学习的分类。下表8示出了由任务分类器241分类任务的示例。表8例如,任务分类器241可以选择可能性大于阈值的任务或参照图4选择两个或更多个任务。例如,在阈值是“30”的情况下,任务分类器241选择写入操作作为任务。在阈值是“25”的情况下,任务分类器241选择写入操作和读取操作作为任务。政策分类器242可以取决于装置环境信息dei和所选择的任务(例如,调度任务)对与所选择的任务相对应的政策进行分类。下表9示出了由政策分类器242分类的政策的示例。表9当所选择的任务与写入操作相关联时,可以选择政策“0”到“2”中的一个。当所选择的任务与数据转换相关联时,可以选择政策“3”到“5”中的一个。当所选择的任务与磨损均衡管理相关联时,可以选择政策“6”至“8”中的一个。当所选择的任务与垃圾搜集相关联时,可以选择政策“9”到“11”中的一个。当所选择的任务与数据清理相关联时,可以选择政策“12”到“14”中的一个。在一个实施例中,数据清理使用后台任务来周期性地检查存储装置200的错误,然后使用冗余数据来校正检测到的错误。也就是说,关于所选择的任务,可以选择单级单元存储器区块、多级单元存储器区块或三级单元存储器区块作为任务目标。例如,当选择两个或更多个任务时,可以选择与所选择的任务相对应的两个或更多个政策。模型执行处理器240可以在存储在第一缓冲存储器220中的请求中获取与所选择的任务相对应的请求。例如,模型执行处理器240可以以先进先出的方式或者取决于分配给请求221的优先级,从第一缓冲存储器220获取与所选择的任务相对应的请求。模型执行处理器240可以将所获取的请求调度为第二缓冲存储器250中的任务。模型执行处理器240可以在第二缓冲存储器250中调度所选择的政策。例如,任务251可以分别具有对应的政策252。作为另一个示例,一些任务可以具有相应的政策,而其余任务没有相应的政策。模型执行处理器240可以用与控制器230分离的单独的半导体芯片来实现。例如,模型执行处理器240可以用半导体芯片实现,所述半导体芯片适合于执行基于机器学习的分类,例如现场可编程门阵列(fpga)、图形处理器(gpu)或神经形态芯片。第二缓冲存储器250可以存储由模型执行处理器240调度的任务251和政策252。例如,第二缓冲存储器250可以是用于存储任务251和政策252的队列。第二缓冲存储器250可以在控制器230内提供、可以在模型执行处理器240内提供、或者可以与第一缓冲存储器220或第三缓冲存储器260组合。第三缓冲存储器260可以是用于驱动控制器230的固件的系统存储器或主存储器。第三缓冲存储器260可以用于缓冲在主机装置100和非易失性存储器装置280之间传送的数据。第三缓冲存储器260可以包括在控制器230或模型执行处理器240内。第三缓冲存储器260可以与第一缓冲存储器220或第二缓冲存储器250组合。存储器接口270从控制器230接收第一模型请求mr1。存储器接口270可以将第一模型请求mr1转换为具有在存储器接口270和非易失性存储器装置280之间的通信中使用的格式的第二模型请求mr2。存储器接口270将第二模型请求mr2发送到非易失性存储器装置280。存储器接口270可以将包括第二模型请求mr2的信号发送到非易失性存储器装置280。非易失性存储器装置280可以响应于第二模型请求mr2输出模型数据mod。存储器接口270可以将模型数据mod发送到控制器230。作为另一示例,存储器接口270可以将模型数据mod存储在第三缓冲存储器260中。存储在第三缓冲存储器260中的模型数据mod可以被发送(或加载)到模型执行处理器240。存储器接口270可以从第二缓冲存储器250获取任务和政策作为第四存取请求ar4。例如,存储器接口270可以以先进先出的方式或基于分配的权重来获取任务和政策。存储器接口270可以将所获取的第四存取请求ar4转换为具有在存储器接口270和非易失性存储器装置280之间的通信中使用的格式的第五存取请求ar5。存储器接口270将第五存取请求ar5发送到非易失性存储器装置280。当第五存取请求ar5是写入请求时,存储器接口270将存储在第三缓冲存储器260中的数据发送到非易失性存储器装置280。当第五存取请求ar5是读取请求时,存储器接口270将从非易失性存储器装置280发送的数据存储在第三缓冲存储器260中。非易失性存储器装置280包括存储器区块281。每个存储器区块281包括存储器单元。存储器单元可以包括单级单元、多级单元和/或三级单元。模型数据库282可以存储在存储器区块281的第一部分中。模型数据库282可以包括任务模型283和政策模型284。用户数据可以存储在存储器区块281的另一部分中。例如,第一存储器区块可用于存储模型数据库282,第二其他存储器区块可用于存储用户数据。非易失性存储器装置280可以响应于第五存取请求ar5对存储器区块执行写入、读取或抹除操作。非易失性存储器装置280可以在写入或读取操作中与存储器接口270交换数据。响应于第二模型请求mr2,非易失性存储器装置280可以向存储器接口270提供存储在模型数据库282中的任务模型283中的一个或政策模型284中的一个作为模型数据mod。如上所述,存储装置200可以响应于主机装置100的请求来选择和执行模型。存储装置200可以取决于所选择的模型来调度从主机装置100、后台操作或前台操作发送的请求。由于基于机器学习执行任务的调度,并且由于根据用户的偏好和环境改变机器学习模型,因此根据用户的偏好来优化性能、功耗和可靠性。因此,本发明概念的实施例优于传统存储装置,传统存储装置基于导致次优性能、功耗和可靠性的默认政策调度任务。此外,当本发明概念的存储装置200配置在计算机内时,与使用传统存储装置200操作的计算机相比,其导致计算器的功能的改进。例如,包括存储装置200以及被修改为包括主机装置100的组件的计算机比传统计算机使用更少的功率、具有比传统计算器更高的操作性能、并且比传统计算器更可靠。在一个实施例中,模型选择模块234响应于第三模型选择请求msr3一起更新任务分类器241的模型和政策分类器242的模型。作为另一示例,模型选择模块234可以响应于第三模型选择请求msr3更新任务分类器241的模型和政策分类器242的模型中的一个。图6示出了可以在模型分类器160、任务分类器241或政策分类器242中使用的示例性基于机器学习的分类器cf1。在一个实施例中,分类器cf1是神经网络。参考图6,分类器cf1包括第一输入节点in1至第四输入节点in4、第一隐藏节点hn1至第十隐藏节点hn10、以及第一输出节点on1至第四输出节点on4。输入节点的数目、隐藏节点的数目和输出节点的数目不限于此。例如,可以根据输入到分类器cf1的主机环境信息hei或装置环境信息dei中包括的信息的数量或数目来确定输入节点的数目。可以根据模型的数目、任务的数目或政策的数目来确定输出节点的数目。可以在构造神经网络时预先确定输入节点的数目、隐藏节点的数目和输出节点的数目。第一输入节点in1至第四输入节点in4形成输入层。第一隐藏节点hn1至第五隐藏节点hn1至hn5形成第一隐藏层。第六隐藏节点hn6至第十隐藏节点hn10形成第二隐藏层。第一输出节点on1至第四输出节点on4形成输出层。可以在构造神经网络时预先确定隐藏层的数目或每个隐藏层的隐藏节点的数目。主机环境信息hei或装置环境信息dei可以输入到第一输入节点in1至第四输入节点in4。可以将不同种类的环境信息输入到不同的输入节点。将每个输入节点的环境信息发送到第一隐藏层的第一隐藏节点hn1至第五隐藏节点hn1至hn5,并将权重应用于其环境信息。将第一隐藏节点hn1至第五隐藏节点hn5中的每一个的信息发送至第二隐藏层的第六隐藏节点hn6至第十隐藏节点hn10,并将权重应用于其信息。将第六隐藏节点hn6至第十隐藏节点hn10中的每一个的信息发送至第一输出节点on1至第四输出节点on4,并将权重应用于其信息。第一输出节点on1至第四输出节点on4中的每一个的信息可以指示参考表5、表8或表9所描述的可能性或比率。图7示出了根据另一示例的基于机器学习的分类器cf2,其可以在模型分类器160、任务分类器241或政策分类器242中使用。在一个实施例中,分类器cf2是决策树。参考图7,分类器cf2包括根节点rn、第一分支节点bn1至第四分支节点bn4、以及第一叶节点ln1至第六叶节点ln6。根节点rn、第一分支节点bn1至第四分支节点bn4以及第一叶节点ln1至第六叶节点ln6可以通过分支连接。在根节点rn和第一分支节点bn1至第四分支节点bn4中的每一个中,可以对关于主机环境信息hei或装置环境信息dei中包括的多个信息的一个进行比较。可以根据比较结果将数值分别发送到与每个节点连接的多个分支。可以关于所有分支节点执行数值的比较和传输。传输到第一叶节点ln1至第六叶节点ln6的数值可以指示参考表5、表8或表9所描述的可能性或比率。作为另一示例,可以根据比较结果选择连接到每个节点的多个分支中的一个。在已经将另一分支节点连接到所选择的分支的情况下,可以关于分支节点处的主机环境信息hei或装置环境信息dei中包括的多个信息的其他信息进行比较。在叶节点已连接到所选择的分支的情况下,可获得叶值的数值作为分类结果cr。分支节点bn1至bn4的数目以及叶节点ln1至ln6的数目不限于此。例如,可以根据输入到分类器cf2的主机环境信息hei或装置环境信息dei中包括的信息的数量或数目来确定分支节点bn1到bn4的数目。可以根据模型的数目、任务的数目或政策的数目来确定叶节点的数目。图8是示出根据本发明概念的应用的主机装置100a的方块图。参照图1和图8,主机装置100a包括处理器110a、电源模块120、调制解调器130、存储器140、输入和输出模式数据库150、模型分类器160和装置接口170。处理器110a可以包括应用模块111和信息搜集模块114a。应用模块111可以执行使用存储装置200的各种应用程序112和进程113。信息搜集模块114a包括电源监测器115、用户配置寄存器116、输入和输出监测器117、应用程序和进程监测器118、以及评估器119。与图3的主机装置100相比,主机装置100a的处理器110a的信息搜集模块114a还包括评估器119。评估器119可以评估所选择的模型的适合性。例如,评估器119可以评估基于所选择的模型执行的存取操作。例如,评估器119可以评估诸如存取操作的延迟之类的性能。评估器119可以将评估结果作为第五主机环境信息hei5发送到模型分类器160。例如,评估器119可以在选择模型并且经过特定时间之后或者在选择模型并且执行特定数目的存取操作之后执行评估,并且可以提供第五主机环境信息hei5。例如,评估器119可以在选择模型且执行读取操作、写入操作和抹除操作中的至少一个或者执行读取操作、写入操作和抹除操作中的每一个多达至少具体的次数之后执行评估,并且可以提供第五主机环境信息hei5。模型分类器160还可以接收第五主机环境信息hei5作为主机环境信息hei。模型分类器160还可以基于第五主机环境信息hei5执行分类。在第五主机环境信息hei5的基础上,模型分类器160可以维护当前模型或者可以请求用新模型替换当前模型。例如,模型分类器160可以在选择模型并且经过特定时间之后或者在选择模型并且执行特定数目的存取操作之后应用第五主机环境信息hei5。例如,模型分类器160可以在选择模型且执行读取操作、写入操作和抹除操作中的至少一个或者执行读取操作、写入操作和抹除操作中的每一个至少特定次数之后应用第五主机环境信息hei5。图9是示出根据本发明概念的示例性实施例的计算系统10的操作方法的流程图。参照图1和图9,在操作s310中,主机装置100的模型分类器160可以对主机环境信息hei执行基于机器学习的分类,并且基于分类结果确定模型。在操作s320中,主机装置100的模型分类器160将指示所选择的模型的模型选择请求msr发送到存储装置200。在操作s330中,存储装置200的模型选择模块234在模型执行处理器240上加载所选择的模型的模型数据mod。如果完全选择(改变)模型,则在操作s340中,主机装置100可以向存储装置200发送存取请求。在操作s350中,存储装置200的模型执行处理器240取决于所选择的模型执行存取请求。在取决于存取请求在存储装置200中执行存取操作之后,执行操作s350。例如,可以在选择模型并且经过特定时间之后或者在执行读取操作、写入操作和抹除操作中的至少一个或者执行读取操作、写入操作和抹除操作中的每一个多达至少特定次数之后执行操作s360。在操作s360中,主机装置100评估性能并重新选择模型。例如,模型分类器160可以基于作为评估器119的评估结果的第五主机环境信息hei5再次执行模型的选择(或分类)。在操作s370中,模型分类器160依赖于从而再次执行的选择(或分类)的结果将指示重新选择的模型的模型选择请求msr发送到存储装置200。例如,如果重新选择的模型与先前模型相同,则模型分类器160不将模型选择请求msr发送到存储装置200。如果重新选择的模型与先前模型不同,则模型分类器160将模型选择请求msr发送到存储装置200。存储装置200可以取决于模型选择请求msr替换模型。例如,可以持续地执行评估和基于评估的选择。例如,在重新选择模型并且经过特定时间之后或者在重新选择模型之后以及执行读取操作、写入操作和抹除操作中的至少一个或执行读取操作、写入操作和抹除操作中的每一个多达至少特定次数之后,可以基于评估器119的第五主机环境信息hei5再次执行选择。例如,如果评估性能的结果低于阈值,则模型分类器160选择与先前模型不同的模型。如果评估性能的结果不小于阈值,则模型分类器160维持先前的模型。阈值可以取决于用户配置寄存器116的设置而变化。阈值可以由用户或外部装置设置。图10是示出根据本发明概念的示例性实施例的计算系统10a的方块图。参考图10,计算系统10a包括主机装置100b和存储装置200a。主机装置100b将存取请求ar发送到存储装置200a以在存储装置200a中写入数据或从存储装置200a读取数据。与参考图1描述的计算系统10不同,主机装置100b仅发送存取请求ar到存储装置200a而不发送模型选择请求msr。例如,主机装置100b不包括信息搜集模块114和模型分类器160。存储装置200a可以包括模型执行处理器240、非易失性存储器装置280、装置信息搜集模块231a和模型分类器290。与图1的存储装置200相比,存储装置200a不包括模型选择模块234,并且包括装置信息搜集模块231a和模型分类器290。装置信息搜集模块231a搜集存储装置200a的环境信息,并将搜集的环境信息作为装置环境信息dei提供给模型执行处理器240。模型分类器290基于装置环境信息dei选择存储装置200a处理主机装置100b的存取请求ar的模型。例如,模型分类器290可以关于装置环境信息dei选择通过使用基于机器学习的分类器预先确定的模型中的一个。模型分类器290将所选择的模型的模型数据mod发送到模型执行处理器240。与图1的计算系统10相比较,计算系统10a包括存储装置200a,存储装置200a被配置为在没有主机装置100b介入的情况下选择模型。因此,即使在主机装置100b不支持模型选择的情况下,存储装置200a也可以自动选择并执行模型。图11是示出根据本发明概念的应用的存储装置200a的方块图。参考图11,存储装置200a包括主机接口210、第一缓冲存储器220、控制器230a、模型执行处理器240、第二缓冲存储器250、第三缓冲存储器260、存储器接口270、非易失性存储器装置280以及模型分类器290。与图5的存储装置200相比,控制器230a具有与图5的控制器230的配置不同的配置,并且以与控制器230不同的方式操作。与图5的存储装置200相比,存储装置200还可以包括模型分类器290。控制器230a可以包括装置信息搜集模块231和模型下载器236。装置信息搜集模块231可以搜集存储装置200a的环境信息,并且可以将所搜集的环境信息的一部分或全部提供给模型分类器290作为第一装置环境信息dei1。装置信息搜集模块231可以将所搜集的环境信息的一部分或全部提供给模型执行处理器240作为第二装置环境信息dei2。例如,第一装置环境信息dei1和第二装置环境信息dei2可以具有重叠信息。例如,第一装置环境信息dei1和第二装置环境信息dei2彼此不一致。作为另一示例,第一装置环境信息dei1和第二装置环境信息dei2彼此一致。当模型数据mod没有存储在非易失性存储器装置280中时,模型下载器236可以从主机装置100b请求模型数据mod。模型数据mod可以通过第三缓冲存储器260存储在非易失性存储器装置280中作为数据的一部分。在一个实施例中,使用机器学习来创建模型分类器290。模型分类器290可以接收第一装置环境信息dei1,并且可以基于第一装置环境信息dei1对适合于存储装置200a的模型进行分类(或选择)。模型分类器290可以将用于请求分类模型的第一模型请求mr1发送到存储器接口270。模型分类器290可以响应于第一模型请求mr1将从存储器接口270接收的模型数据mod发送到模型执行处理器240。模型分类器290可以用与控制器230a分离的单独的半导体芯片来实现。例如,模型分类器290可以用半导体芯片实现,所述半导体芯片适合于执行基于机器学习的分类,例如现场可编程门阵列(fpga)、图形处理器(gpu)或神经形态芯片。主机接口210、第一缓冲存储器220、模型执行处理器240、第二缓冲存储器250、第三缓冲存储器260、存储器接口270和非易失性存储器装置280可以被配置成和操作为与参照图4所描述的那些相同,除了主机接口210和控制器230a不发送模型选择请求msr2或msr3并且模型执行处理器240基于第二装置环境信息dei2执行任务和政策分类(或选择)之外。如上所述,存储装置200a包括模型分类器290。模型分类器290可以基于第二装置环境信息dei2对适合于存储装置200a的模型进行分类(或选择)。模型执行处理器240可以执行所选择的模型以调度任务251和政策252。因此,提供了被优化为基于机器学习使用用户的模式的存储装置200a。在一个实施例中,如参考图3所述,装置信息搜集模块231a可以包括用户配置寄存器116。装置信息搜集模块231a可以在用户或外部装置的控制下设置用户配置寄存器116。装置信息搜集模块231a可以将用户配置寄存器116的信息发送到模型分类器290。图12是示出根据本发明概念的另一应用的存储装置200b的方块图。参照图10和12,存储装置200b包括主机接口210、第一缓冲存储器220、控制器230b、模型执行处理器240、第二缓冲存储器250、第三缓冲存储器260、存储器接口270、非易失性存储器装置280和模型分类器290。与图11的存储装置200a相比,控制器230b具有与图11的控制器230a的配置不同的配置,以与控制器230a不同的方式操作。例如,控制器230b还可以包括评估器237。评估器237可以评估基于所选择的模型执行的存取操作。例如,评估器237可以评估诸如存取操作的延迟之类的性能。在将评估结果包括在第一装置环境信息dei1中之后,评估器237可以将评估结果发送到模型分类器290。评估器237可以在将第二装置环境信息dei2发送到模型执行处理器240之前将评估结果包括在第二装置环境信息dei2中。例如,评估器237可以在选择模型并且经过特定时间之后或者在选择模型并且执行特定数目的存取操作之后执行评估,并且将评估结果包括在装置环境信息dei中。例如,评估器237可以在选择模型且执行读取操作、写入操作和抹除操作中的至少一个或者执行读取操作、写入操作和抹除操作中的每一个多达至少特定次数之后执行评估并且可以提供评估结果。模型分类器290还可以基于评估结果执行分类。在评估结果的基础上,模型分类器290可以维护当前模型或者可以请求用新模型替换当前模型。模型执行处理器240可以基于评估结果来调度之后的任务或政策。例如,在维持当前模型的情况下,模型执行处理器240可以应用评估结果。在将当前模型改变为新模型的情况下,评估结果不与新模型相关联。因此,在当前模型改变为新模型的情况下,模型执行处理器240不应用评估结果。例如,模型分类器290可以在选择模型并且经过特定时间之后或者在选择模型并且执行特定数目的存取操作之后应用评估结果。例如,模型分类器290可以在选择模型且执行读取操作、写入操作和抹除操作中的至少一个或者执行读取操作、写入操作和抹除操作中的每一个多达至少特定次数之后应用评估结果。如上所述,存储装置200b可以在没有主机装置100b介入的情况下选择并执行模型。此外,存储装置200b可以在没有主机装置100b介入的情况下评估模型,并且可以取决于评估结果替换或维护模型。因此,提供了基于机器学习针对用户的使用模式优化的存储装置200b。根据本发明概念的至少一个实施例,根据机器学习调整控制器存取非易失性存储器装置的方法。因此,提供了为每个用户提供最佳操作性能的存储装置、包括所述存储装置的计算系统、以及所述存储装置的操作方法。虽然已经参考本发明的示例性实施例描述了本发明概念,但是对于本领域普通技术人员显而易见的是,在不脱离本发明概念的精神和范围的情况下,可以对其进行各种改变和修改。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1