一种基于眼睛注视数据和图像数据集的图像生成方法与流程
本发明涉及图像生成领域,尤其是涉及了一种基于眼睛注视数据和图像数据集的图像生成方法。
背景技术:
图像生成一直是计算机视觉领域的主要课题之一,由于缺乏源图像信息等多种限制,经常发生可用图像数据集数量不足或质量不佳的情况。因此,研究人员已经开发了各种图像合成方法来生成对于随后的图像处理任务更有用和有价值的图像。近年来,研究人员专注于使用超分辨率方法来生成更详细的图像,如基于口头描述、基于注视模式或眼球运动轨迹来生成图像。通过口头描述或眼球运动轨迹来生成图像的方法在日常生活中将会有广泛的应用前景,如当人们忘记阅读过的报刊或书籍的名称时,通过口头描述报刊或书籍的排版样式或某部分的内容,则可以利用图像生成系统来生成与描述相近的报刊或书籍图像,同样地,也可以利用眼球运动轨迹来生成图像,即在读者阅读报刊或书籍时收集读者的眼睛注视数据,从而生成大致的版面样式图像,进而利用生成的图像在数据库中进行搜索,帮助人们找到想要的报刊或书籍。然而,基于眼睛注视数据的图像生成技术却由于注视数据难以收集或图像质量不佳而一直未能实现。在过去的几年中,人们也探索了各种线性和非线性方法,通过插值法来提高图像质量,然而效果并不明显。
本发明提出了一种基于眼睛注视数据和图像数据集的图像生成方法,学习眼动数据到报刊图像的映射数据集,生成眼睛注视数据并将其作为模型的输入,同时构建眼动数据集,使用条件生成对抗网络的体系结构将注视热图馈送到神经网络的输入层,通过个性化网络训练和端到端设计生成报刊图像,发生器具有从眼动数据集创建的眼睛注视热图的输入,鉴别器接收眼睛注视热图和发生器输出的组合作为输入,最终生成与报刊相似的图像。本发明通过在相应的眼睛注视热图上进行调节来生成合成图像,进一步改善了生成图像的质量,并且能够生成更详细的图像。
技术实现要素:
针对注视数据难以收集或图像质量不佳的问题,本发明的目的在于提供一种基于眼睛注视数据和图像数据集的图像生成方法,学习眼动数据到报刊图像的映射数据集,生成眼睛注视数据并将其作为模型的输入,同时构建眼动数据集,使用条件生成对抗网络的体系结构将注视热图馈送到神经网络的输入层,通过个性化网络训练和端到端设计生成报刊图像,发生器具有从眼动数据集创建的眼睛注视热图的输入,鉴别器接收眼睛注视热图和发生器输出的组合作为输入,最终生成与报刊相似的图像。
为解决上述问题,本发明提供一种基于眼睛注视数据和图像数据集的图像生成方法,其主要内容包括:
(一)数据准备;
(二)网络训练;
(三)报刊图像生成;
(四)在眼动数据集上进行训练。
其中,所述的数据准备,为了训练网络,需要学习眼动数据到报刊图像的映射数据集,从而生成眼睛注视数据并将其作为模型的输入;使用生成的眼睛注视数据和提供的图像数据集训练模型,输出各种细节水平的报刊图像;将端到端的图像生成过程分为两个阶段:第一阶段的目标是生成报刊图像的语义分割,而第二阶段用于从分割中生成详细的报刊图像;
眼动数据集包含每个阅读环节中每个人眼睛注视的位置和持续时间的记录,可以直接使用参与者眼睛注视数据作为模型的输入;因此,能够生成对应于参与者阅读的小说的不同部分的眼睛注视热图。
进一步地,所述的模型的输入,当为眼动数据集生成灰度眼睛注视热图时,对于每个观察者以及每次在特定单词的特定位置进行注视时,在灰度热图中的对应于其记录的位置设置亮点注视位置;观察者完成的总试验时间之外,调整该点的亮度,记录在特定位置花费的时间百分比;此记录百分比值的最大值为0.17%,因此所有注视时间百分比小于此值的注视点将在热图中用较不亮的点表示;合成热图的最大像素值是255,对应于持续时间值为0.17%的注视点;如果注视占用了总测试时间的0.017%,则其像素值将变为25.5;在一个单词中可能会有多个注视点,在这种情况下,对应于不同注视位置的不同明亮点将被添加到热图中;但是,对于属于同一单词的注视点,选择使用该特定词的试用时间的总百分比来调节所有这些注视点的亮度,假定全局持续时间值比估计单词的重要性与阅读材料中的其他词更有用。
进一步地,所述的眼动数据集,将阅读材料分成多个部分,生成包含印刷文本的RGB图像;每个文本图像是一个256×256大小的RGB图像,其红色通道编码一个不变的背景,绿色通道编码文本内容,蓝色通道设置为零;实验发现,与使用仅包含文本内容的单个通道相比,这种三通道布置提供更好的训练稳定性,降低了发散的可能性,并且允许更快的收敛;每个图像包含15个字,排列成3行,每行包含5个字;为了生成眼动数据集的眼睛注视热图,所有显著点的位置都适应于生成的文本嵌入图像的位置。
其中,所述的网络训练,选择基于条件生成对抗网络(GAN)的体系结构来构建本系统;输入数据是从上述数据准备步骤获得的注视热图,并且使用条件GAN的体系结构将这些热图馈送到神经网络的输入层。
其中,所述的报刊图像生成,报刊图像生成过程包括个性化网络训练和端到端设计;
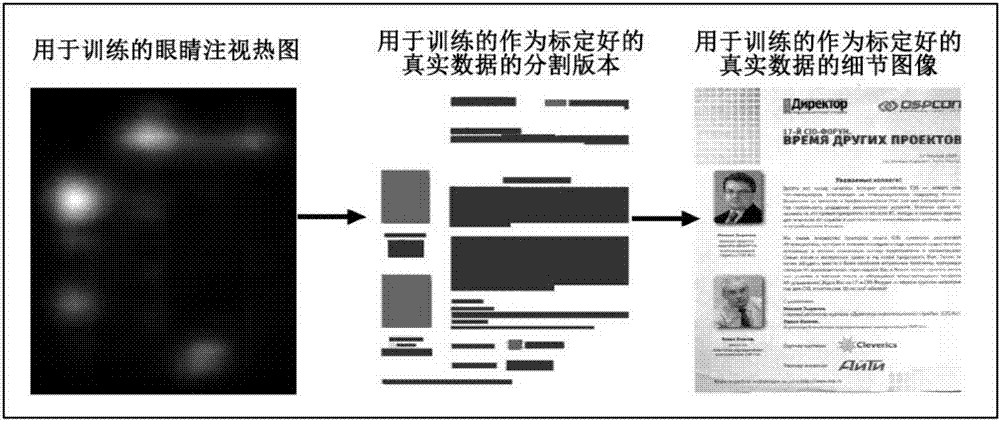
个性化网络训练过程具有两个阶段,第一阶段是进行眼动数据到分割的报刊图像合成,第二阶段是从图像分割中生成具有更高级别细节的报刊图像;
在第一阶段训练网络时,发生器会使用生成的眼睛注视热图;在训练期间,优化发生器以产生与标定好的真实分割报刊图像尽可能相似的输出;将图像块馈送到鉴别器,该图像块将输入的眼睛注视热图与从发生器产生的图像连接;当接收到补丁时开始训练鉴别器,从而识别为“假”图像;在“真实”图像情况下,鉴别器接收将眼睛注视热图与标定好的真实分割报刊图像连接的块;
对于第二阶段的训练网络,是以分割的报刊图像为基础合成详细的报刊图像;将数据集提供的分割图像馈送到生成器的输入层;然后优化发生器,产生与标定好的真实详细报刊图像尽可能相似的输出;在这种情况下,将分割图像和详细图像的图像块馈送并连接到鉴别器,将合成数据与标定好的真实数据进行区分。
进一步地,所述的端到端设计,首先将发生器的输入层加上眼睛注视热图,并利用分割报刊图像对系统进行训练以生成分割图像;在完成训练系统产生分割图像之后,重新初始化系统并且向发生器的输入层提供一种新的输入;此时,先前训练的发生器生成的分割图像与眼睛注视热图连接,形成一组新的输入RGB图像,然后输入到重新初始化的系统;发生器接收这些输入并被优化,输出与由数据集提供的详细的报刊图像尽可能相似的图像。
进一步地,所述的连接,新的红色通道是通过将眼睛注视热点的像素值加到生成的分割图像的红色通道的像素值上而形成的;新的蓝色通道是通过获取生成的分割图像的蓝色通道的像素值而形成的;新的绿色通道是通过将所有的值设置为0而形成的,除了生成的所有三个通道分割的位置等于255之外,在这种情况下,绿色通道像素保持255,以形成另外两个白色的通道;鉴别器接收图像补丁并区分它们是属于“真实图像对”还是“伪图像对”。
其中,所述的在眼动数据集上进行训练,发生器具有从眼动数据集创建的眼睛注视热图的输入;当发生器被训练产生类似文本的图像并且具有作为目标的真实文本嵌入图像时训练鉴别器,将发生器的输出区分为“假”图像;在“假图像”情况下,鉴别器接收眼睛注视热图和发生器输出的组合作为输入;在“真实图像”情况下,鉴别器接收与标定好的真实文本嵌入图像串联的注视热图作为输入;网络所使用的损失函数适用于研究中涉及的所有训练阶段和所有数据集。
进一步地,所述的损失函数,鉴别器的任务是在真实对和假对之间进行分类,使用下面的二进制交叉熵损失作为其损失函数:
LD=Ex,y[log D(x,y)]+Ex[1-log D(x,G(x))] (1)
其中,x表示发生器的输入,y表示发生器作为目标的所有标定好的真实图像;对于发生器,将GAN损失与欧式损失等其他标准内容损失混合可以改善深度神经网络的训练,因此选择使用L1距离作为附加损失,并将其组合与上述对抗性损失一起构造发生器的损失函数;L1距离表示发生器的输出与标定好的真实图像之间的差异;因此,发生器的整体损失函数定义为:
LG=LD+λL1(G) (2)
把λ的值设为0.01,当L1损失比GAN损失大100倍时,发生器将输出产生的伪像;网络的所有层都需要从头开始进行训练;权重在-0.05至0.05之间随机使用均匀分布进行初始化;总是保留20%的样本进行测试;通过交替更新发生器和鉴别器来训练网络;GAN交叉熵损失被反向传播给鉴别器,更新其权重;然后,通过保持鉴别器权重不变,将交叉熵损失与L1损失相结合,并反向传播该错误,更新发生器权重;优化发生器和鉴别器,学习率为0.001,衰减率为0.9,动量为0,∈为1×10-6;在网络中使用压差层和批量归一化来加速收敛。
附图说明
图1是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的系统框架图。
图2是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的数据准备过程。
图3是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的模型的输入。
图4是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的网络训练过程。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的系统框架图。主要包括数据准备、网络训练、报刊图像生成和在眼动数据集上进行训练。
报刊图像生成过程包括个性化网络训练和端到端设计;
个性化网络训练过程具有两个阶段,第一阶段是进行眼动数据到分割的报刊图像合成,第二阶段是从图像分割中生成具有更高级别细节的报刊图像;
在第一阶段训练网络时,发生器会使用生成的眼睛注视热图;在训练期间,优化发生器以产生与标定好的真实分割报刊图像尽可能相似的输出;将图像块馈送到鉴别器,该图像块将输入的眼睛注视热图与从发生器产生的图像连接;当接收到补丁时开始训练鉴别器,从而识别为“假”图像;在“真实”图像情况下,鉴别器接收将眼睛注视热图与标定好的真实分割报刊图像连接的块;
对于第二阶段的训练网络,是以分割的报刊图像为基础合成详细的报刊图像;将数据集提供的分割图像馈送到生成器的输入层;然后优化发生器,产生与标定好的真实详细报刊图像尽可能相似的输出;在这种情况下,将分割图像和详细图像的图像块馈送并连接到鉴别器,将合成数据与标定好的真实数据进行区分。
端到端设计,首先将发生器的输入层加上眼睛注视热图,并利用分割报刊图像对系统进行训练以生成分割图像;在完成训练系统产生分割图像之后,重新初始化系统并且向发生器的输入层提供一种新的输入;此时,先前训练的发生器生成的分割图像与眼睛注视热图连接,形成一组新的输入RGB图像,然后输入到重新初始化的系统;发生器接收这些输入并被优化,输出与由数据集提供的详细的报刊图像尽可能相似的图像。
新的红色通道是通过将眼睛注视热点的像素值加到生成的分割图像的红色通道的像素值上而形成的;新的蓝色通道是通过获取生成的分割图像的蓝色通道的像素值而形成的;新的绿色通道是通过将所有的值设置为0而形成的,除了生成的所有三个通道分割的位置等于255之外,在这种情况下,绿色通道像素保持255,以形成另外两个白色的通道;鉴别器接收图像补丁并区分它们是属于“真实图像对”还是“伪图像对”。
在眼动数据集上进行训练,发生器具有从眼动数据集创建的眼睛注视热图的输入;当发生器被训练产生类似文本的图像并且具有作为目标的真实文本嵌入图像时训练鉴别器,将发生器的输出区分为“假”图像;在“假图像”情况下,鉴别器接收眼睛注视热图和发生器输出的组合作为输入;在“真实图像”情况下,鉴别器接收与标定好的真实文本嵌入图像串联的注视热图作为输入;网络所使用的损失函数适用于研究中涉及的所有训练阶段和所有数据集。
鉴别器的任务是在真实对和假对之间进行分类,使用下面的二进制交叉熵损失作为其损失函数:
LD=Ex,y[log D(x,y)]+Ex[1-log D(x,G(x))] (1)
其中,x表示发生器的输入,y表示发生器作为目标的所有标定好的真实图像;对于发生器,将GAN损失与欧式损失等其他标准内容损失混合可以改善深度神经网络的训练,因此选择使用L1距离作为附加损失,并将其组合与上述对抗性损失一起构造发生器的损失函数;L1距离表示发生器的输出与标定好的真实图像之间的差异;因此,发生器的整体损失函数定义为:
LG=LD+λL1(G) (2)
把λ的值设为0.01,当L1损失比GAN损失大100倍时,发生器将输出产生的伪像;网络的所有层都需要从头开始进行训练;权重在-0.05至0.05之间随机使用均匀分布进行初始化;总是保留20%的样本进行测试;通过交替更新发生器和鉴别器来训练网络;GAN交叉熵损失被反向传播给鉴别器,更新其权重;然后,通过保持鉴别器权重不变,将交叉熵损失与L1损失相结合,并反向传播该错误,更新发生器权重;优化发生器和鉴别器,学习率为0.001,衰减率为0.9,动量为0,∈为1×10-6;在网络中使用压差层和批量归一化来加速收敛。
图2是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的数据准备过程。为了训练网络,需要学习眼动数据到报刊图像的映射数据集,从而生成眼睛注视数据并将其作为模型的输入;使用生成的眼睛注视数据和提供的图像数据集训练模型,输出各种细节水平的报刊图像;将端到端的图像生成过程分为两个阶段:第一阶段的目标是生成报刊图像的语义分割,而第二阶段用于从分割中生成详细的报刊图像;
眼动数据集包含每个阅读环节中每个人眼睛注视的位置和持续时间的记录,可以直接使用参与者眼睛注视数据作为模型的输入;因此,能够生成对应于参与者阅读的小说的不同部分的眼睛注视热图。将阅读材料分成多个部分,生成包含印刷文本的RGB图像;每个文本图像是一个256×256大小的RGB图像,其红色通道编码一个不变的背景,绿色通道编码文本内容,蓝色通道设置为零;实验发现,与使用仅包含文本内容的单个通道相比,这种三通道布置提供更好的训练稳定性,降低了发散的可能性,并且允许更快的收敛;每个图像包含15个字,排列成3行,每行包含5个字;为了生成眼动数据集的眼睛注视热图,所有显著点的位置都适应于生成的文本嵌入图像的位置。
图3是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的模型的输入。当为眼动数据集生成灰度眼睛注视热图时,对于每个观察者以及每次在特定单词的特定位置进行注视时,在灰度热图中的对应于其记录的位置设置亮点注视位置;观察者完成的总试验时间之外,调整该点的亮度,记录在特定位置花费的时间百分比;此记录百分比值的最大值为0.17%,因此所有注视时间百分比小于此值的注视点将在热图中用较不亮的点表示;合成热图的最大像素值是255,对应于持续时间值为0.17%的注视点;如果注视占用了总测试时间的0.017%,则其像素值将变为25.5;在一个单词中可能会有多个注视点,在这种情况下,对应于不同注视位置的不同明亮点将被添加到热图中;但是,对于属于同一单词的注视点,选择使用该特定词的试用时间的总百分比来调节所有这些注视点的亮度,假定全局持续时间值比估计单词的重要性与阅读材料中的其他词更有用。
图4是本发明一种基于眼睛注视数据和图像数据集的图像生成方法的网络训练过程。选择基于条件生成对抗网络(GAN)的体系结构来构建本系统;输入数据是从上述数据准备步骤获得的注视热图,并且使用条件GAN的体系结构将这些热图馈送到神经网络的输入层。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!