一种基于容器化技术的分布式机器学习平台的搭建方法与流程
本发明涉及机器学习领域,更具体地,涉及一种基于容器化技术的分布式机器学习平台的搭建方法。
背景技术:
近年来,随着计算水平和算法的进步,机器学习特别是深度学习获得了极大的发展,俨然已经成为当前最火热的研究领域,并且在越来越多的领域,越来越多的问题中得到应用。而有很多复杂的问题都有更大的数据集,更高的计算量,更久的运算时间。这个时候单台的计算机的资源(cpu,gpu,内存,磁盘等)和性能很容易陷入瓶颈,无法满足机器学习任务的要求。分布式计算是当前大数据处理的核心技术,它可以将一个任务划分为可以并行执行的多个部分,然后分配到各个节点上,各个节点会并行的执行,之后再将执行的结果进行汇总。而机器学习的任务有大量可以并行执行的计算,而且最主流的几个机器学习框架都支持分布式下的运算。因此,将机器学习结合到分布式计算平台上是大势所趋。
以docker为代表的容器化技术日渐成熟,其使用镜像创建一个虚拟化的运行环境,运行环境中包含了所需的所有依赖,其轻量级,易管理的特点受到了广泛的欢迎。因此,使用docker来部署分布式平台的相关组件,来组合成最终的平台,可以减少很多工作。而以kubernetes为代表的容器编排工具,可以有效的对容器进行管理,可以保证容器的高可用,滚动升级,负载均衡等,对于平台的鲁棒性提供了很大的支撑。本技术以docker为基础,搭建一个分布式的机器学习平台,既能对机器学习有良好的支持,又可以保证简洁性和可用性,实现机器学习平台的定制化。
技术实现要素:
本发明提供一种基于容器化技术的分布式机器学习平台的搭建方法,该方法搭建的平台利用效率和计算效率高。
为了达到上述技术效果,本发明的技术方案如下:
一种基于容器化技术的分布式机器学习平台的搭建方法,包括以下步骤:
s1:准备docker仓库,本平台在部署和使用过程中都需要进行镜像的上传和拉去操作,必须要有一个docker仓库才可以,这个docker仓库可以是自建的,也可以是使用公共的docker仓库;
s2:填写集群描述文件,集群描述文件主要用于搭建kubernetes集群,里面需要包含kubernetes集群要运行的节点的信息,各个组件的配置信息,以及各个节点需要运行哪些服务;
s3:部署kubernetes集群,使用python脚本读取集群描述文件,并生成所需要的shell脚本和kubernetes描述文件,将这些文件通过ssh发送到各台主机执行,就可以完成kubernetes集群的部署;
s4:填写服务描述文件,服务描述文件主要用于机器学习平台的各种服务的启动和运行,里面需要包含各个服务的配置信息和每个服务需要运行在哪些节点之上;
s5:将机器学习平台的服务制作成docker镜像,使用python脚本读取服务描述文件中各个服务的描述信息,生成各个服务对应的dockerfile,使用这些dockerfile构造镜像后上传到远程的仓库中;
s6:部署机器学习平台的服务,使用python脚本读取步骤四中的服务描述文件来生成各个服务对应的kubernetes描述文件,然后调用kubernetes的命令行工具kubectl创建这些服务;
s7:等待各个服务完成协调同步,在部署完步骤s6的各个服务之后,各个组件需要一小段时间来完成同步,这期间可能会有若干服务数次重启,当所有服务都稳定运行之后,整个机器学习平台的搭建也就完成了。
进一步地,该平台的学习过程是:
步骤一:上传代码和数据到hdfs,在本平台的设计中,程序的代码和数据都是需要从hdfs上获取,因此在执行任务之前需要使用pai-fs将本次任务所需要数据和机器学习的代码传输到hdfs上。
步骤二:填写任务描述文件,运行任务所需要的任务描述文件是用于描述要运行的任务需要使用的cpu、gpu、内存和磁盘等计算资源,各个节点需要执行的命令,程序地址,数据地址,输出地址等,以及在发生错误的时候需要重试的次数等;
步骤三:通过webportal提交任务,在webportal的任务提交页面,点击提交任务按钮,选择在步骤二准备好的任务描述文件,在提交成功之后会提示任务已成功提交;
步骤四:restserver准备运行脚本和框架描述文件,restserver将用户上传上来的任务描述文件解析,准备其在使用frameworklauncher中所需要的脚本和框架描述文件,并通过接口通知frameworklauncher启动任务;
步骤五:通过frameworklauncher启动任务,通过接口获取到新的任务之后,frameworklauncher会将该任务添加到任务队列中,等待执行,当轮到该任务执行,并且该任务所要求的资源条件都能够满足的时候,frameworklauncher就可以通知hadoopyarn执行该任务;
步骤六:使用hadoopyarn启动容器来执行任务。hadoopyarn作为一个全局的资源管理器,可以同一调度全局的资源来执行机器学习任务,甚至可以跨机器调度,yarn会启动新的容器来运行要求执行的任务,并为这些容器赋予要求的资源;
步骤七:等待执行完成之后获取任务的执行结果,当任务执行完成之后,可以通过webportal来获取任务的执行结果,也可以直接从hdfs上下载运行过程中的输出数据。
与现有技术相比,本发明技术方案的有益效果是:
本发明的目的是为了构建一种通用且简洁的方式进行深度学习平台的搭建方法,利用该方法搭建的平台可提高资源的利用效率和计算效率,方便管理和提交任务,使用户可以更加专注于深度学习的研究中,而不用顾虑硬件及其他的问题。
附图说明
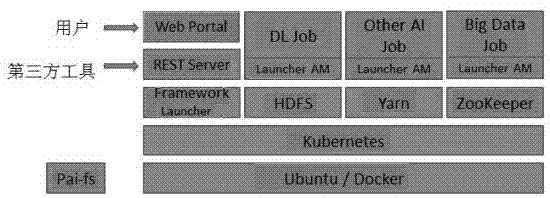
图1是整个平台的架构图;
图2是kubernetes的部署说明图,具有高可用和负载均衡的功能;
图3为机器学习任务的全部过程,从提交到结束到返回结果。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
一种基于容器化技术的分布式机器学习平台的搭建方法,包括以下步骤:
s1:准备docker仓库,本平台在部署和使用过程中都需要进行镜像的上传和拉去操作,必须要有一个docker仓库才可以,这个docker仓库可以是自建的,也可以是使用公共的docker仓库;
s2:填写集群描述文件,集群描述文件主要用于搭建kubernetes集群,里面需要包含kubernetes集群要运行的节点的信息,各个组件的配置信息,以及各个节点需要运行哪些服务;
s3:部署kubernetes集群,使用python脚本读取集群描述文件,并生成所需要的shell脚本和kubernetes描述文件,将这些文件通过ssh发送到各台主机执行,就可以完成kubernetes集群的部署;
s4:填写服务描述文件,服务描述文件主要用于机器学习平台的各种服务的启动和运行,里面需要包含各个服务的配置信息和每个服务需要运行在哪些节点之上;
s5:将机器学习平台的服务制作成docker镜像,使用python脚本读取服务描述文件中各个服务的描述信息,生成各个服务对应的dockerfile,使用这些dockerfile构造镜像后上传到远程的仓库中;
s6:部署机器学习平台的服务,使用python脚本读取步骤四中的服务描述文件来生成各个服务对应的kubernetes描述文件,然后调用kubernetes的命令行工具kubectl创建这些服务;
s7:等待各个服务完成协调同步,在部署完步骤s6的各个服务之后,各个组件需要一小段时间来完成同步,这期间可能会有若干服务数次重启,当所有服务都稳定运行之后,整个机器学习平台的搭建也就完成了。
进一步地,该平台的学习过程是:
步骤一:上传代码和数据到hdfs,在本平台的设计中,程序的代码和数据都是需要从hdfs上获取,因此在执行任务之前需要使用pai-fs将本次任务所需要数据和机器学习的代码传输到hdfs上。
步骤二:填写任务描述文件,运行任务所需要的任务描述文件是用于描述要运行的任务需要使用的cpu、gpu、内存和磁盘等计算资源,各个节点需要执行的命令,程序地址,数据地址,输出地址等,以及在发生错误的时候需要重试的次数等;
步骤三:通过webportal提交任务,在webportal的任务提交页面,点击提交任务按钮,选择在步骤二准备好的任务描述文件,在提交成功之后会提示任务已成功提交;
步骤四:restserver准备运行脚本和框架描述文件,restserver将用户上传上来的任务描述文件解析,准备其在使用frameworklauncher中所需要的脚本和框架描述文件,并通过接口通知frameworklauncher启动任务;
步骤五:通过frameworklauncher启动任务,通过接口获取到新的任务之后,frameworklauncher会将该任务添加到任务队列中,等待执行,当轮到该任务执行,并且该任务所要求的资源条件都能够满足的时候,frameworklauncher就可以通知hadoopyarn执行该任务;
步骤六:使用hadoopyarn启动容器来执行任务。hadoopyarn作为一个全局的资源管理器,可以同一调度全局的资源来执行机器学习任务,甚至可以跨机器调度,yarn会启动新的容器来运行要求执行的任务,并为这些容器赋予要求的资源;
步骤七:等待执行完成之后获取任务的执行结果,当任务执行完成之后,可以通过webportal来获取任务的执行结果,也可以直接从hdfs上下载运行过程中的输出数据。
在平台的最底层使用操作系统为ubuntu16.04lte的物理机或者虚拟机作为运行各个组件的主机,要求所有的主机都处在同一个子网之中,并且能够提供过ssh互相连通,用户需要拥有root的权限,并且worker节点中必须要安装有gpu。
使用docker作为容器化引擎,安装与每一台主机之上,凭借其轻量化、易管理、可移植性强的特点,可以大幅简化安装部署以及运行管理的复杂度。
在docker之上使用kubernetes对docker容器进行统一管理,所有的平台组件都通过kubernetes进行安装。同样出于易于管理的考量,kubernetes的组件中除了docker以及kubectl之外,其他的组件都是以容器化的方式部署,其中kubelet是最基础的组件,需要通过docker来启动之外,其他的组件都是通过kubelet的静态的方式进行部署安装的。
hadoop是整个平台中最重要的服务组件之一,是进行并行计算、提高效率的基础,它的多个模块在平台的设计里都有重要的作用:hdfs用于存储机器学习任务所使用的数据和代码,在这里假定,所有的机器学习任务都是支持从hdfs作为输入源的,由于当前的大部分的机器学习框架都对hdfs有较好的支持,因此这点要求并不会造成太大的困扰,只需要熟悉这种编程方式即可;mapreduce是并行计算进行的主要方式,大部分在平台上运行的脚本最终都会被转化为mapreduce的方式来进行;yarn是hadoop的资源管理器,通过建立一个全局的资源管理器以及为每一个应用建立一个应用控制器,可以对各个节点的资源进行统一的管理和调度,提高资源的利用效率;zookeeper是用来自动管理节点的模块,当有节点宕掉或者服务意外终止时,它会去在新的节点去继续运行服务,来保证整个集群的稳定性与可用性。
在hadoop之外,封装了一层frameworklauncher,通过framewlauncher来对hadoop进行扩展和延伸,将一些基于hadoop的功能封装好,方便与其他组件进行对接,也减少了不同组件之间的耦合,简化了设计。
restserver对外部提供http连接服务,开放一些端口,供第三方的服务以及网页入口使用,便于服务的扩展以及产品化运行。
webportal是本平台的网页入口,通过入口可以可视化的对平台的集群和服务进行管理,提交和管理任务,获取任务的结果及统计等。
同时为了能够达到便捷性和高可用的目的,这里也采取了很多方式和策略:
自动生成脚本:本设计中只向用户提供单个配置文件,配置文件中需要提供每个节点的ip地址、用户名、密码、角色、每个节点上运行的服务等的节点配置信息以及每个服务组件所要求的信息如对接平台的地址、服务开放的端口等服务配置信息。在部署的时候会首先从配置文件中读取配置信息,然后使用python实现的脚本对预先准备的模板进行填充,主要包括部署平台使用的shell脚本、构建镜像所使用的dockerfile和部署服务所需要的yaml配置文件。然后通过ssh将生产的脚本和配置文件分发到所有的节点,并执行起始脚本,启动部署的过程。这个过程大概分了三个部分:部署kubernetes,构建镜像和部署服务。在没有出现异常导致部署终止的情况下,这三部分会依次执行,全自动化部署。
使用镜像进行部署:之前提到使用脚本自动的构建镜像,而之所以使用镜像的原因,就是它能够极大的方便我们的部署。在从配置文件读取服务的配置信息之后,使用这些信息补完dockerfile,再使用它制作镜像,并上传到远程的仓库(公共或私有的都可以)中。在部署的过程中,只需要在某个节点指定要拉取的镜像,就可以生成对应的服务的容器来运行,非常的高效快捷,特别是在规模比较大的时候,其优点更加的突出。
kubernetes的高可用:kubernetes作为底层容器编排的工具和服务部署平台,其作用非常大,一旦崩溃,会导致所有的组件都无法正常运行,所以必须要保证它的高可用,并且要确保其宕机恢复的时间要尽量的短。kubernetes集群的节点主要分为两种,一种是master节点,其负责整个平台的管理和控制,数据的存储和对外的交互,是集群的核心,另一种是worker节点,其主要负责任务的执行。对于worker节点来说,其宕机或者服务终止会造成该节点上运行的所有容器丢失或终止,但是master可以自动的从其他的节点处启动新的容器,继续执行任务,造成的风险比较小,而对于master节点来说,一旦宕机,其造成的影响和风险都非常大,因此,在这里设计了多个master节点,通过vip(虚拟ip地址)来实现一个主备结合的高可用模式,另外结合了负载均衡使得所有的主节点都能够得到利用,来分担流量的压力。
服务的高可用:平台运行的各种服务组件也需要保证高可用性,这个实现起来较为容易一些,这里使用kubernetes提供了daemonset功能和service功能,daemonset功能可以为单个节点上的服务提供守护进程,当运行服务的容器崩溃或者被杀死的时候,会自动启动新的容器,来继续进行服务。而service则是为一系列相同功能的容器提供负载均衡服务,它会定期发送心跳去检查各个容器的可用性,如果有失效的容器,则后来的请求就会被转发到其他容器中,如果service结合deployment功能,还可以实现当有容器或者节点失效之后,自动从其他节点启动容器来保证副本数目,并将新的容器加入到service中。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!